 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning of Factored Multi-agent Reactive Models
Mar 12, 2019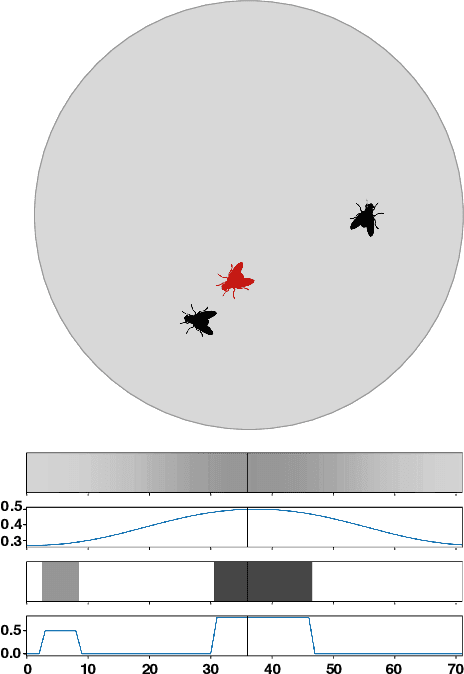

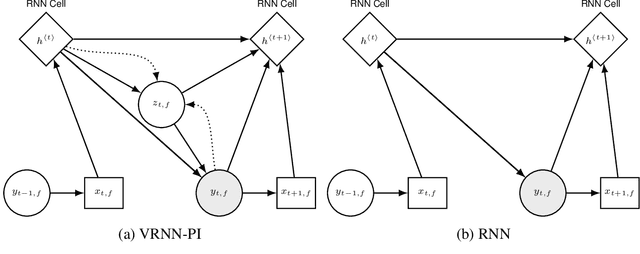
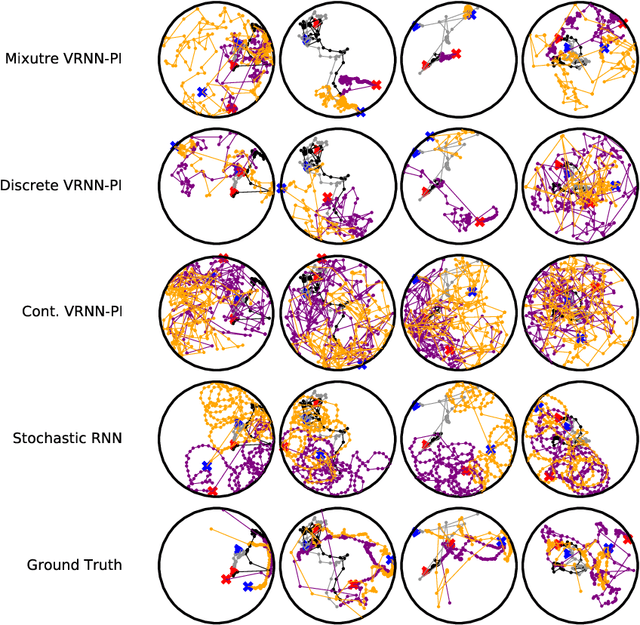
We apply recent advances in deep generative modeling to the task of imitation learning from biological agents. Specifically, we apply variations of the variational recurrent neural network model to a multi-agent setting where we learn policies of individual uncoordinated agents acting based on their perceptual inputs and their hidden belief state. We learn stochastic policies for these agents directly from observational data, without constructing a reward function. An inference network learned jointly with the policy allows for efficient inference over the agent's belief state given a sequence of its current perceptual inputs and the prior actions it performed, which lets us extrapolate observed sequences of behavior into the future while maintaining uncertainty estimates over future trajectories. We test our approach on a dataset of flies interacting in a 2D environment, where we demonstrate better predictive performance than existing approaches which learn deterministic policies with recurrent neural networks. We further show that the uncertainty estimates over future trajectories we obtain are well calibrated, which makes them useful for a variety of downstream processing tasks.
LF-PPL: A Low-Level First Order Probabilistic Programming Language for Non-Differentiable Models
Mar 06, 2019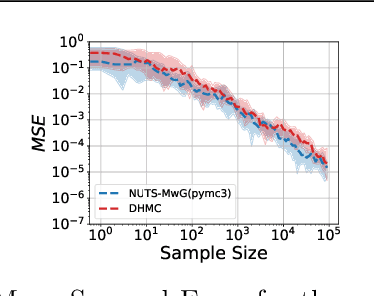
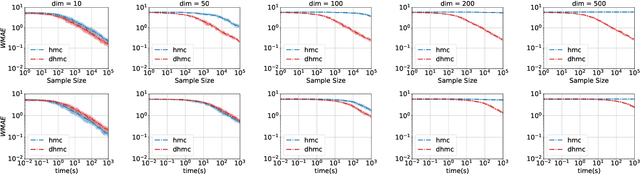

We develop a new Low-level, First-order Probabilistic Programming Language (LF-PPL) suited for models containing a mix of continuous, discrete, and/or piecewise-continuous variables. The key success of this language and its compilation scheme is in its ability to automatically distinguish parameters the density function is discontinuous with respect to, while further providing runtime checks for boundary crossings. This enables the introduction of new inference engines that are able to exploit gradient information, while remaining efficient for models which are not everywhere differentiable. We demonstrate this ability by incorporating a discontinuous Hamiltonian Monte Carlo (DHMC) inference engine that is able to deliver automated and efficient inference for non-differentiable models. Our system is backed up by a mathematical formalism that ensures that any model expressed in this language has a density with measure zero discontinuities to maintain the validity of the inference engine.
Faithful Inversion of Generative Models for Effective Amortized Inference
Oct 24, 2018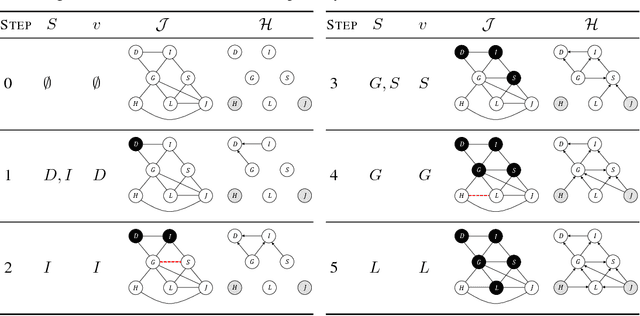
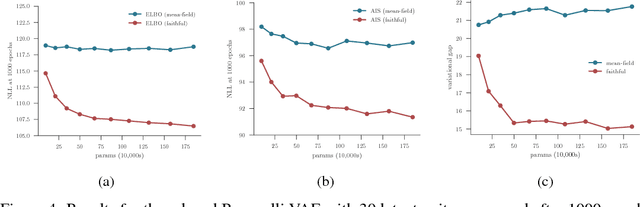

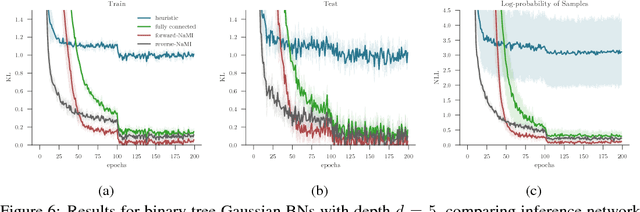
Inference amortization methods share information across multiple posterior-inference problems, allowing each to be carried out more efficiently. Generally, they require the inversion of the dependency structure in the generative model, as the modeller must learn a mapping from observations to distributions approximating the posterior. Previous approaches have involved inverting the dependency structure in a heuristic way that fails to capture these dependencies correctly, thereby limiting the achievable accuracy of the resulting approximations. We introduce an algorithm for faithfully, and minimally, inverting the graphical model structure of any generative model. Such inverses have two crucial properties: (a) they do not encode any independence assertions that are absent from the model and; (b) they are local maxima for the number of true independencies encoded. We prove the correctness of our approach and empirically show that the resulting minimally faithful inverses lead to better inference amortization than existing heuristic approaches.
An Introduction to Probabilistic Programming
Sep 27, 2018
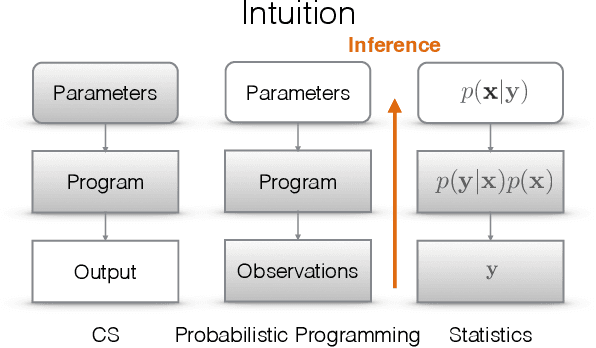


This document is designed to be a first-year graduate-level introduction to probabilistic programming. It not only provides a thorough background for anyone wishing to use a probabilistic programming system, but also introduces the techniques needed to design and build these systems. It is aimed at people who have an undergraduate-level understanding of either or, ideally, both probabilistic machine learning and programming languages. We start with a discussion of model-based reasoning and explain why conditioning as a foundational computation is central to the fields of probabilistic machine learning and artificial intelligence. We then introduce a simple first-order probabilistic programming language (PPL) whose programs define static-computation-graph, finite-variable-cardinality models. In the context of this restricted PPL we introduce fundamental inference algorithms and describe how they can be implemented in the context of models denoted by probabilistic programs. In the second part of this document, we introduce a higher-order probabilistic programming language, with a functionality analogous to that of established programming languages. This affords the opportunity to define models with dynamic computation graphs, at the cost of requiring inference methods that generate samples by repeatedly executing the program. Foundational inference algorithms for this kind of probabilistic programming language are explained in the context of an interface between program executions and an inference controller. This document closes with a chapter on advanced topics which we believe to be, at the time of writing, interesting directions for probabilistic programming research; directions that point towards a tight integration with deep neural network research and the development of systems for next-generation artificial intelligence applications.
Efficient Probabilistic Inference in the Quest for Physics Beyond the Standard Model
Sep 01, 2018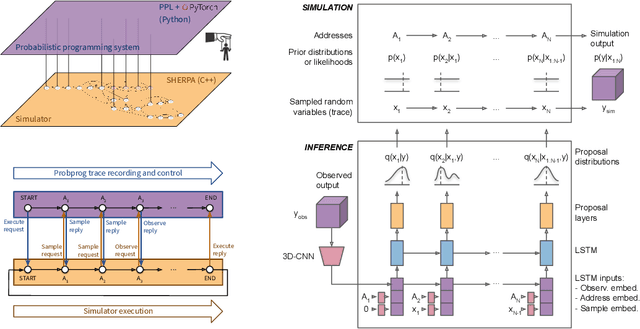
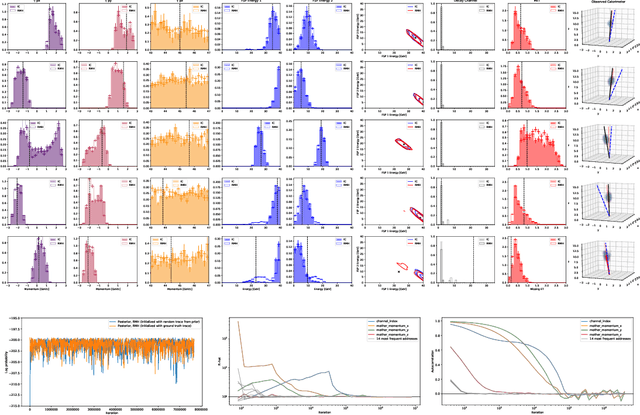


We present a novel framework that enables efficient probabilistic inference in large-scale scientific models by allowing the execution of existing domain-specific simulators as probabilistic programs, resulting in highly interpretable posterior inference. Our framework is general purpose and scalable, and is based on a cross-platform probabilistic execution protocol through which an inference engine can control simulators in a language-agnostic way. We demonstrate the technique in particle physics, on a scientifically accurate simulation of the tau lepton decay, which is a key ingredient in establishing the properties of the Higgs boson. High-energy physics has a rich set of simulators based on quantum field theory and the interaction of particles in matter. We show how to use probabilistic programming to perform Bayesian inference in these existing simulator codebases directly, in particular conditioning on observable outputs from a simulated particle detector to directly produce an interpretable posterior distribution over decay pathways. Inference efficiency is achieved via inference compilation where a deep recurrent neural network is trained to parameterize proposal distributions and control the stochastic simulator in a sequential importance sampling scheme, at a fraction of the computational cost of Markov chain Monte Carlo sampling.
Tighter Variational Bounds are Not Necessarily Better
Jun 25, 2018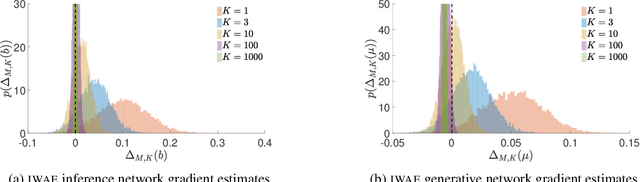

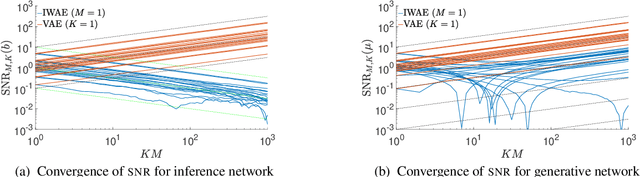
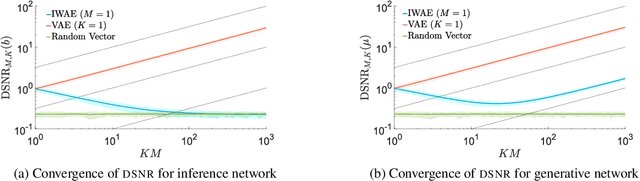
We provide theoretical and empirical evidence that using tighter evidence lower bounds (ELBOs) can be detrimental to the process of learning an inference network by reducing the signal-to-noise ratio of the gradient estimator. Our results call into question common implicit assumptions that tighter ELBOs are better variational objectives for simultaneous model learning and inference amortization schemes. Based on our insights, we introduce three new algorithms: the partially importance weighted auto-encoder (PIWAE), the multiply importance weighted auto-encoder (MIWAE), and the combination importance weighted auto-encoder (CIWAE), each of which includes the standard importance weighted auto-encoder (IWAE) as a special case. We show that each can deliver improvements over IWAE, even when performance is measured by the IWAE target itself. Furthermore, our results suggest that PIWAE may be able to deliver simultaneous improvements in the training of both the inference and generative networks.
Inference Trees: Adaptive Inference with Exploration
Jun 25, 2018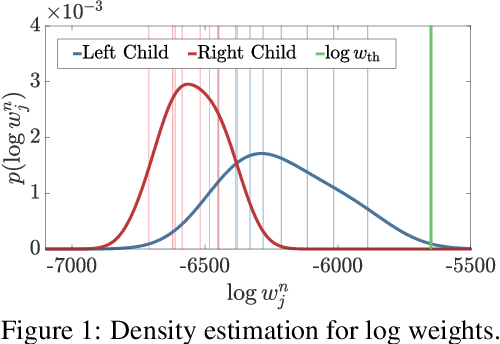
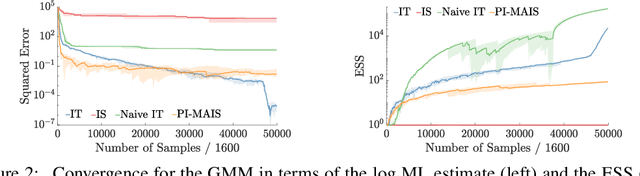
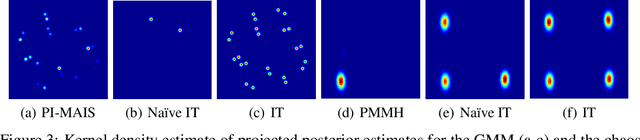
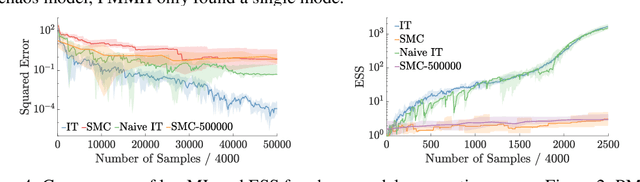
We introduce inference trees (ITs), a new class of inference methods that build on ideas from Monte Carlo tree search to perform adaptive sampling in a manner that balances exploration with exploitation, ensures consistency, and alleviates pathologies in existing adaptive methods. ITs adaptively sample from hierarchical partitions of the parameter space, while simultaneously learning these partitions in an online manner. This enables ITs to not only identify regions of high posterior mass, but also maintain uncertainty estimates to track regions where significant posterior mass may have been missed. ITs can be based on any inference method that provides a consistent estimate of the marginal likelihood. They are particularly effective when combined with sequential Monte Carlo, where they capture long-range dependencies and yield improvements beyond proposal adaptation alone.
Deep Variational Reinforcement Learning for POMDPs
Jun 06, 2018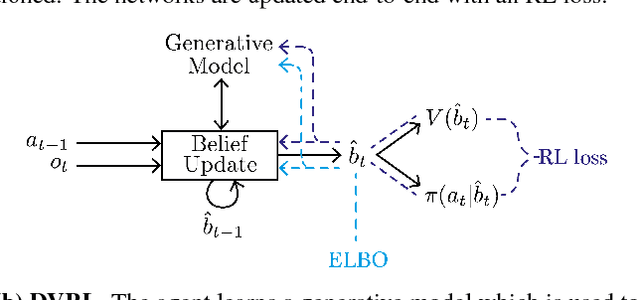
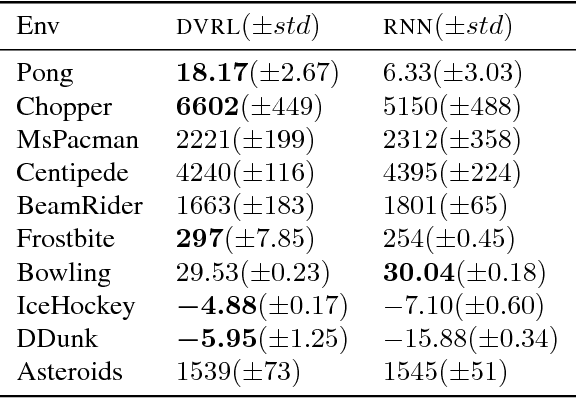
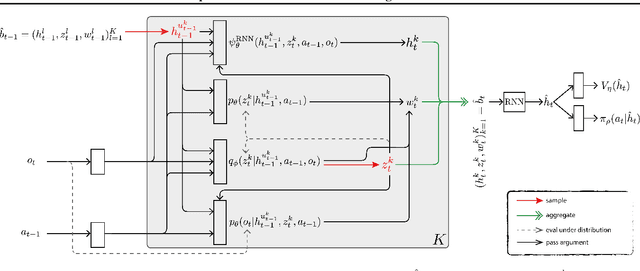
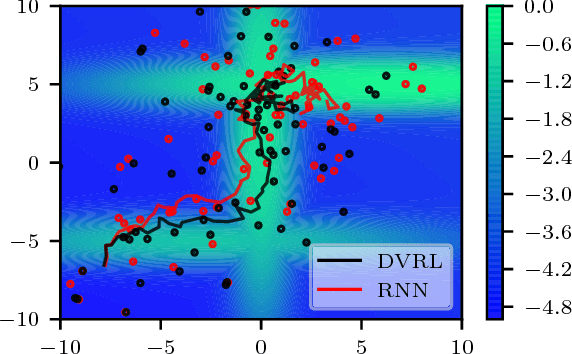
Many real-world sequential decision making problems are partially observable by nature, and the environment model is typically unknown. Consequently, there is great need for reinforcement learning methods that can tackle such problems given only a stream of incomplete and noisy observations. In this paper, we propose deep variational reinforcement learning (DVRL), which introduces an inductive bias that allows an agent to learn a generative model of the environment and perform inference in that model to effectively aggregate the available information. We develop an n-step approximation to the evidence lower bound (ELBO), allowing the model to be trained jointly with the policy. This ensures that the latent state representation is suitable for the control task. In experiments on Mountain Hike and flickering Atari we show that our method outperforms previous approaches relying on recurrent neural networks to encode the past.
Revisiting Reweighted Wake-Sleep
May 26, 2018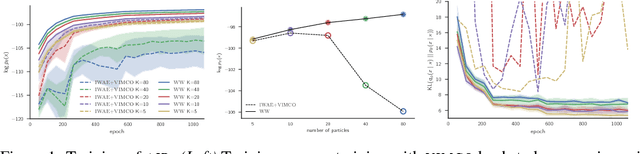
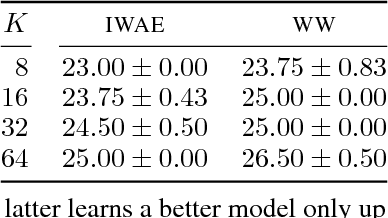
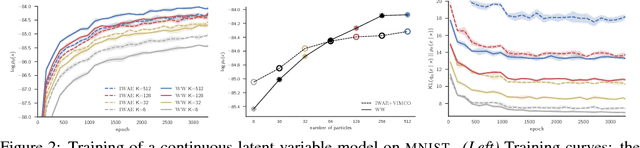
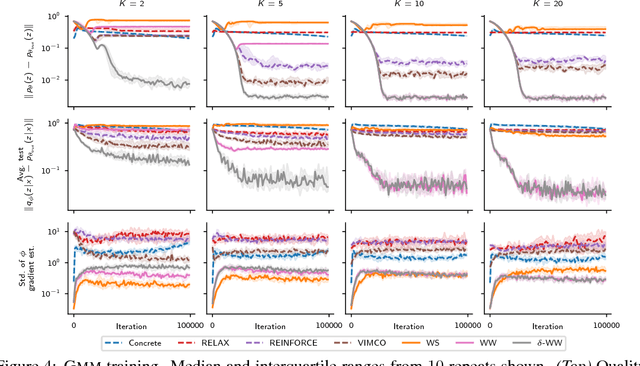
Discrete latent-variable models, while applicable in a variety of settings, can often be difficult to learn. Sampling discrete latent variables can result in high-variance gradient estimators for two primary reasons: 1. branching on the samples within the model, and 2. the lack of a pathwise derivative for the samples. While current state-of-the-art methods employ control-variate schemes for the former and continuous-relaxation methods for the latter, their utility is limited by the complexities of implementing and training effective control-variate schemes and the necessity of evaluating (potentially exponentially) many branch paths in the model. Here, we revisit the reweighted wake-sleep (RWS) (Bornschein and Bengio, 2015) algorithm, and through extensive evaluations, show that it circumvents both these issues, outperforming current state-of-the-art methods in learning discrete latent-variable models. Moreover, we observe that, unlike the importance weighted autoencoder, RWS learns better models and inference networks with increasing numbers of particles, and that its benefits extend to continuous latent-variable models as well. Our results suggest that RWS is a competitive, often preferable, alternative for learning deep generative models.
On Nesting Monte Carlo Estimators
May 23, 2018
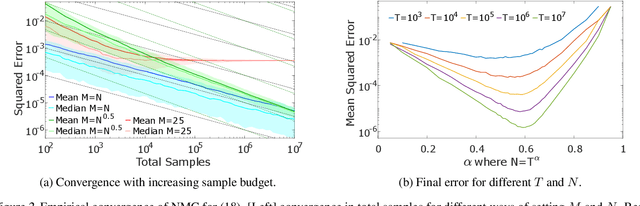
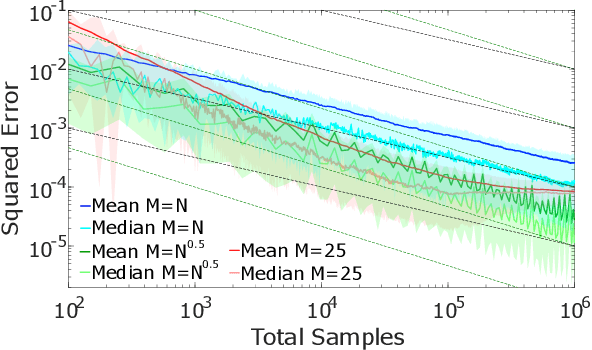
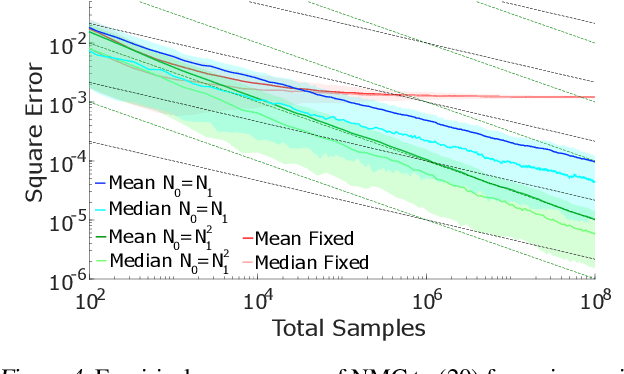
Many problems in machine learning and statistics involve nested expectations and thus do not permit conventional Monte Carlo (MC) estimation. For such problems, one must nest estimators, such that terms in an outer estimator themselves involve calculation of a separate, nested, estimation. We investigate the statistical implications of nesting MC estimators, including cases of multiple levels of nesting, and establish the conditions under which they converge. We derive corresponding rates of convergence and provide empirical evidence that these rates are observed in practice. We further establish a number of pitfalls that can arise from naive nesting of MC estimators, provide guidelines about how these can be avoided, and lay out novel methods for reformulating certain classes of nested expectation problems into single expectations, leading to improved convergence rates. We demonstrate the applicability of our work by using our results to develop a new estimator for discrete Bayesian experimental design problems and derive error bounds for a class of variational objectives.