 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of Large ASR Models in the Real World
Aug 19, 2024Federated learning (FL) has shown promising results on training machine learning models with privacy preservation. However, for large models with over 100 million parameters, the training resource requirement becomes an obstacle for FL because common devices do not have enough memory and computation power to finish the FL tasks. Although efficient training methods have been proposed, it is still a challenge to train the large models like Conformer based ASR. This paper presents a systematic solution to train the full-size ASR models of 130M parameters with FL. To our knowledge, this is the first real-world FL application of the Conformer model, which is also the largest model ever trained with FL so far. And this is the first paper showing FL can improve the ASR model quality with a set of proposed methods to refine the quality of data and labels of clients. We demonstrate both the training efficiency and the model quality improvement in real-world experiments.
Mixture-of-Expert Conformer for Streaming Multilingual ASR
May 25, 2023End-to-end models with large capacity have significantly improved multilingual automatic speech recognition, but their computation cost poses challenges for on-device applications. We propose a streaming truly multilingual Conformer incorporating mixture-of-expert (MoE) layers that learn to only activate a subset of parameters in training and inference. The MoE layer consists of a softmax gate which chooses the best two experts among many in forward propagation. The proposed MoE layer offers efficient inference by activating a fixed number of parameters as the number of experts increases. We evaluate the proposed model on a set of 12 languages, and achieve an average 11.9% relative improvement in WER over the baseline. Compared to an adapter model using ground truth information, our MoE model achieves similar WER and activates similar number of parameters but without any language information. We further show around 3% relative WER improvement by multilingual shallow fusion.
Efficient Domain Adaptation for Speech Foundation Models
Feb 03, 2023Foundation models (FMs), that are trained on broad data at scale and are adaptable to a wide range of downstream tasks, have brought large interest in the research community. Benefiting from the diverse data sources such as different modalities, languages and application domains, foundation models have demonstrated strong generalization and knowledge transfer capabilities. In this paper, we present a pioneering study towards building an efficient solution for FM-based speech recognition systems. We adopt the recently developed self-supervised BEST-RQ for pretraining, and propose the joint finetuning with both source and unsupervised target domain data using JUST Hydra. The FM encoder adapter and decoder are then finetuned to the target domain with a small amount of supervised in-domain data. On a large-scale YouTube and Voice Search task, our method is shown to be both data and model parameter efficient. It achieves the same quality with only 21.6M supervised in-domain data and 130.8M finetuned parameters, compared to the 731.1M model trained from scratch on additional 300M supervised in-domain data.
Enabling On-Device Training of Speech Recognition Models with Federated Dropout
Oct 07, 2021
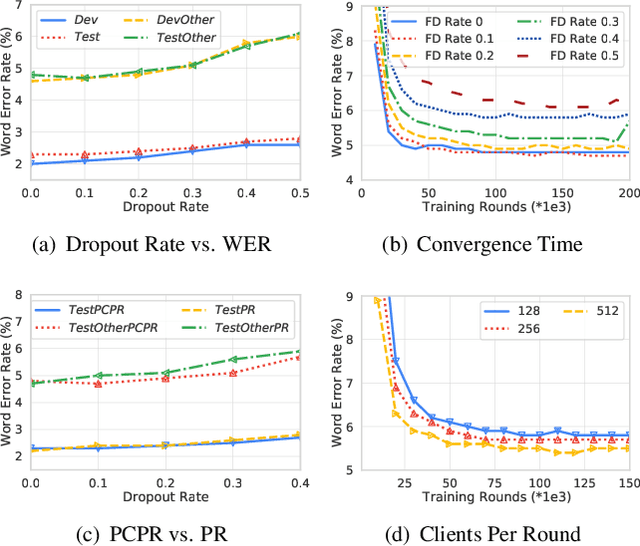

Federated learning can be used to train machine learning models on the edge on local data that never leave devices, providing privacy by default. This presents a challenge pertaining to the communication and computation costs associated with clients' devices. These costs are strongly correlated with the size of the model being trained, and are significant for state-of-the-art automatic speech recognition models. We propose using federated dropout to reduce the size of client models while training a full-size model server-side. We provide empirical evidence of the effectiveness of federated dropout, and propose a novel approach to vary the dropout rate applied at each layer. Furthermore, we find that federated dropout enables a set of smaller sub-models within the larger model to independently have low word error rates, making it easier to dynamically adjust the size of the model deployed for inference.
Training Speech Recognition Models with Federated Learning: A Quality/Cost Framework
Oct 29, 2020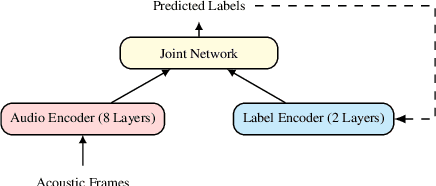
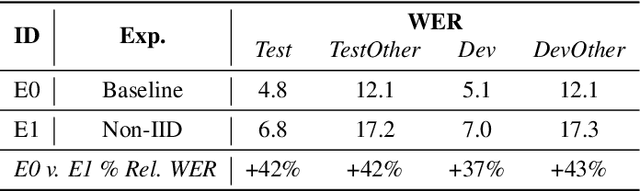
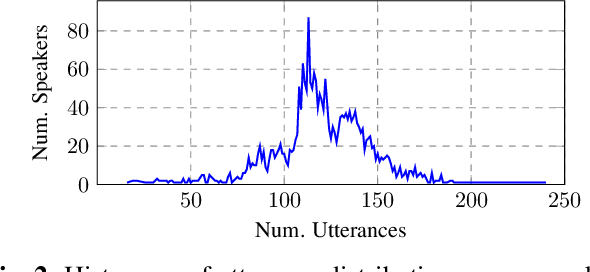
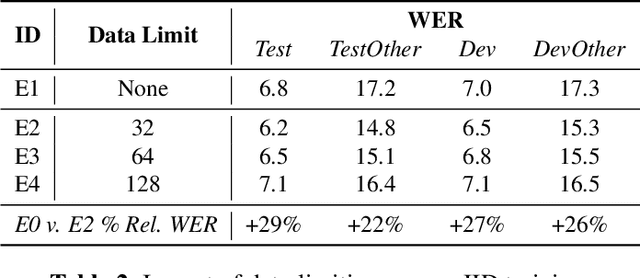
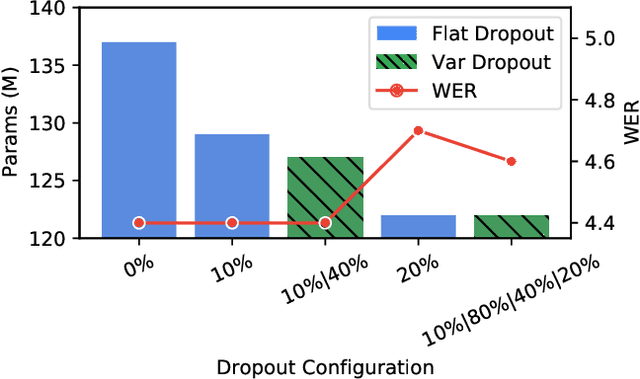
We propose using federated learning, a decentralized on-device learning paradigm, to train speech recognition models. By performing epochs of training on a per-user basis, federated learning must incur the cost of dealing with non-IID data distributions, which are expected to negatively affect the quality of the trained model. We propose a framework by which the degree of non-IID-ness can be varied, consequently illustrating a trade-off between model quality and the computational cost of federated training, which we capture through a novel metric. Finally, we demonstrate that hyper-parameter optimization and appropriate use of variational noise are sufficient to compensate for the quality impact of non-IID distributions, while decreasing the cost.
Analyzing the Quality and Stability of a Streaming End-to-End On-Device Speech Recognizer
Jun 02, 2020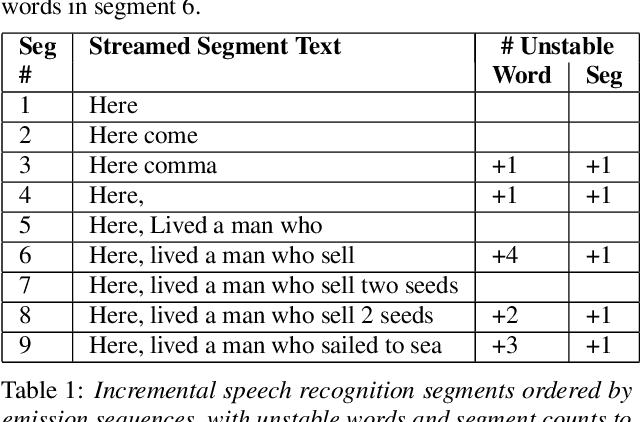
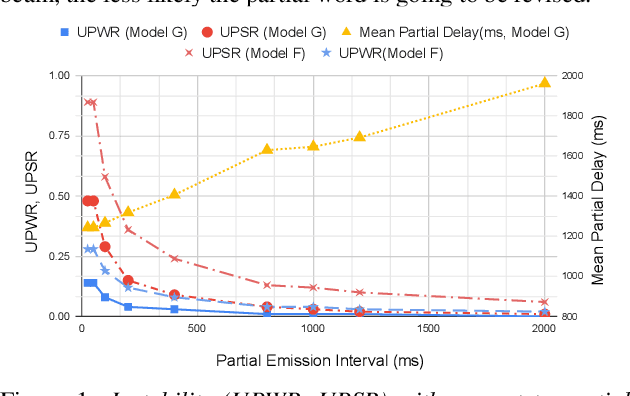
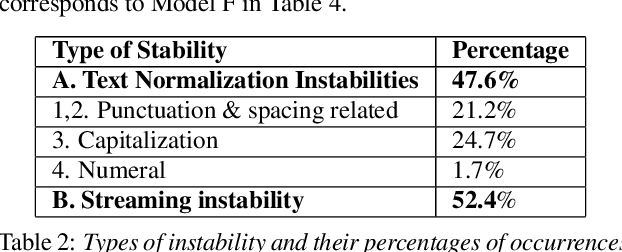
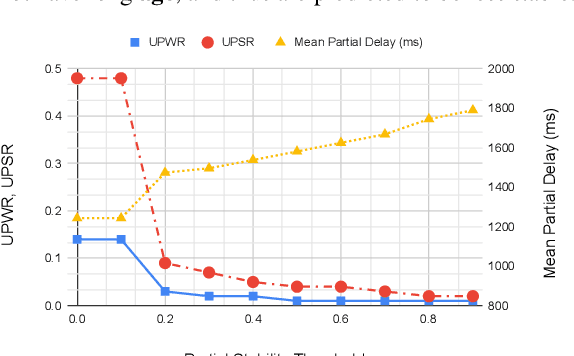
The demand for fast and accurate incremental speech recognition increases as the applications of automatic speech recognition (ASR) proliferate. Incremental speech recognizers output chunks of partially recognized words while the user is still talking. Partial results can be revised before the ASR finalizes its hypothesis, causing instability issues. We analyze the quality and stability of on-device streaming end-to-end (E2E) ASR models. We first introduce a novel set of metrics that quantify the instability at word and segment levels. We study the impact of several model training techniques that improve E2E model qualities but degrade model stability. We categorize the causes of instability and explore various solutions to mitigate them in a streaming E2E ASR system. Index Terms: ASR, stability, end-to-end, text normalization,on-device, RNN-T
Personalized Speech recognition on mobile devices
Mar 11, 2016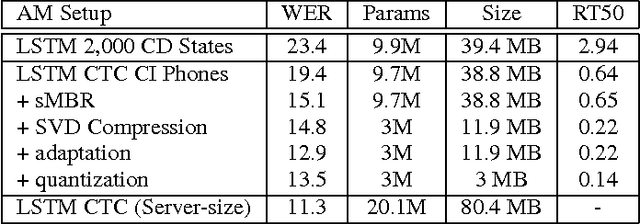
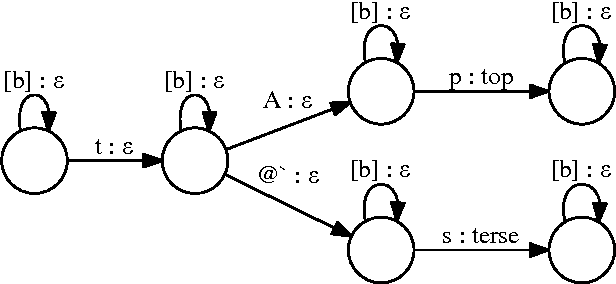

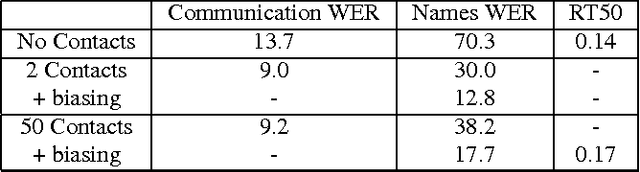
We describe a large vocabulary speech recognition system that is accurate, has low latency, and yet has a small enough memory and computational footprint to run faster than real-time on a Nexus 5 Android smartphone. We employ a quantized Long Short-Term Memory (LSTM) acoustic model trained with connectionist temporal classification (CTC) to directly predict phoneme targets, and further reduce its memory footprint using an SVD-based compression scheme. Additionally, we minimize our memory footprint by using a single language model for both dictation and voice command domains, constructed using Bayesian interpolation. Finally, in order to properly handle device-specific information, such as proper names and other context-dependent information, we inject vocabulary items into the decoder graph and bias the language model on-the-fly. Our system achieves 13.5% word error rate on an open-ended dictation task, running with a median speed that is seven times faster than real-time.