 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Event Recognition through the lens of Adversary
Nov 15, 2020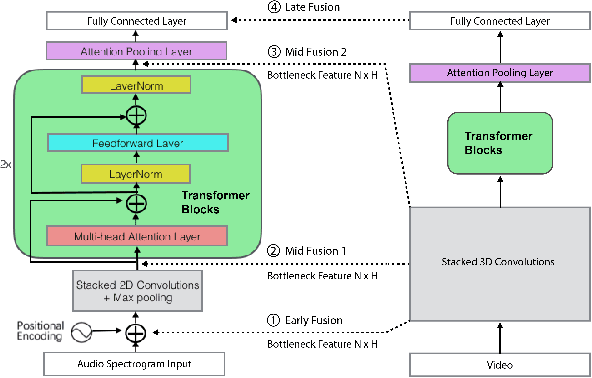
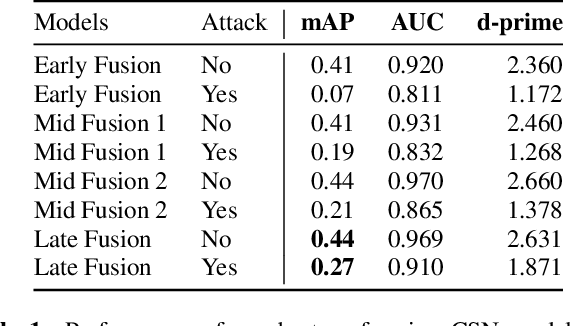
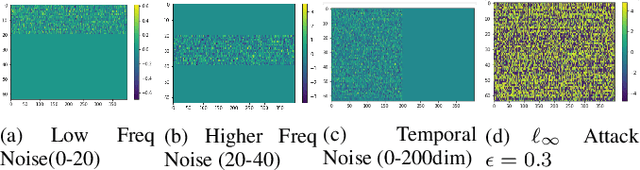
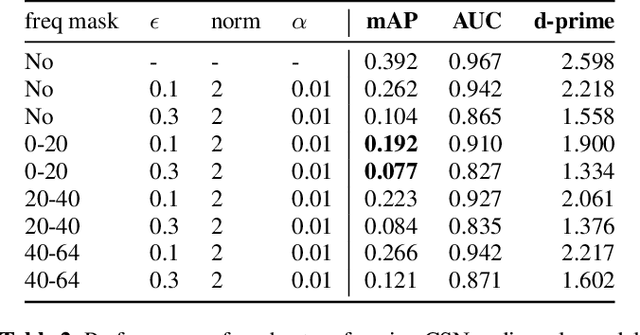
As audio/visual classification models are widely deployed for sensitive tasks like content filtering at scale, it is critical to understand their robustness along with improving the accuracy. This work aims to study several key questions related to multimodal learning through the lens of adversarial noises: 1) The trade-off between early/middle/late fusion affecting its robustness and accuracy 2) How do different frequency/time domain features contribute to the robustness? 3) How do different neural modules contribute to the adversarial noise? In our experiment, we construct adversarial examples to attack state-of-the-art neural models trained on Google AudioSet. We compare how much attack potency in terms of adversarial perturbation of size $\epsilon$ using different $L_p$ norms we would need to "deactivate" the victim model. Using adversarial noise to ablate multimodal models, we are able to provide insights into what is the best potential fusion strategy to balance the model parameters/accuracy and robustness trade-off and distinguish the robust features versus the non-robust features that various neural networks model tend to learn.
Multimodal Speech Recognition with Unstructured Audio Masking
Oct 16, 2020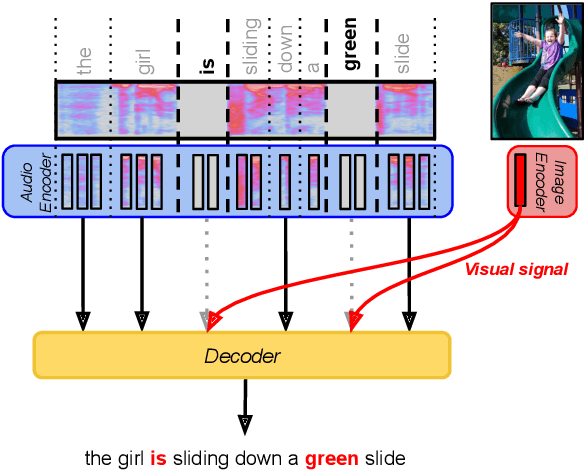
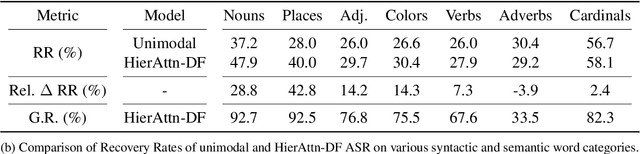
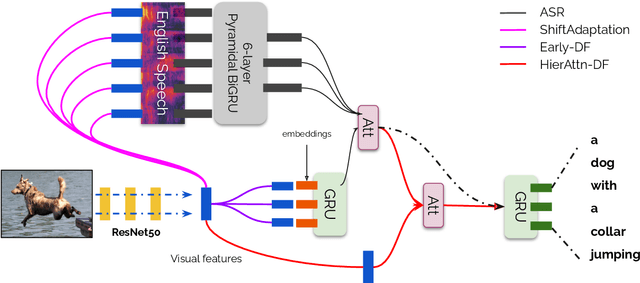
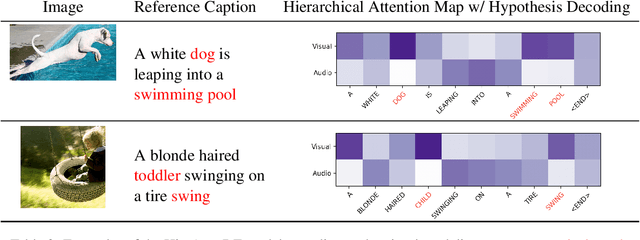
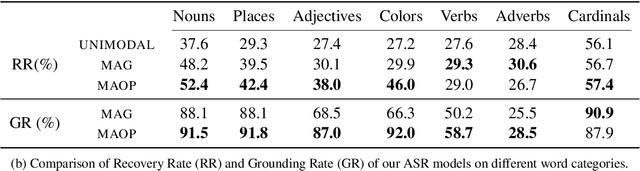
Visual context has been shown to be useful for automatic speech recognition (ASR) systems when the speech signal is noisy or corrupted. Previous work, however, has only demonstrated the utility of visual context in an unrealistic setting, where a fixed set of words are systematically masked in the audio. In this paper, we simulate a more realistic masking scenario during model training, called RandWordMask, where the masking can occur for any word segment. Our experiments on the Flickr 8K Audio Captions Corpus show that multimodal ASR can generalize to recover different types of masked words in this unstructured masking setting. Moreover, our analysis shows that our models are capable of attending to the visual signal when the audio signal is corrupted. These results show that multimodal ASR systems can leverage the visual signal in more generalized noisy scenarios.
On Long-Tailed Phenomena in Neural Machine Translation
Oct 10, 2020
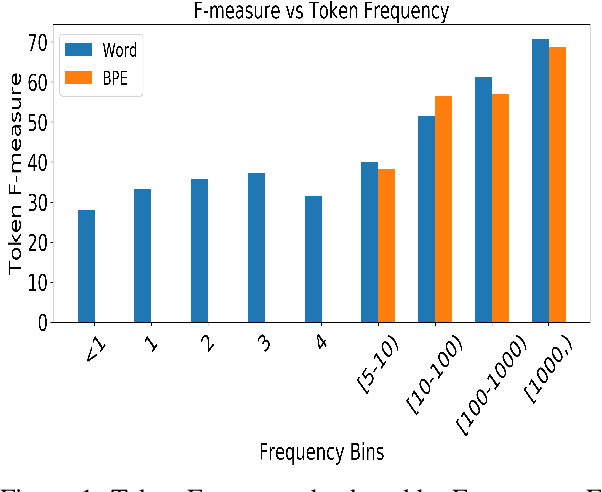
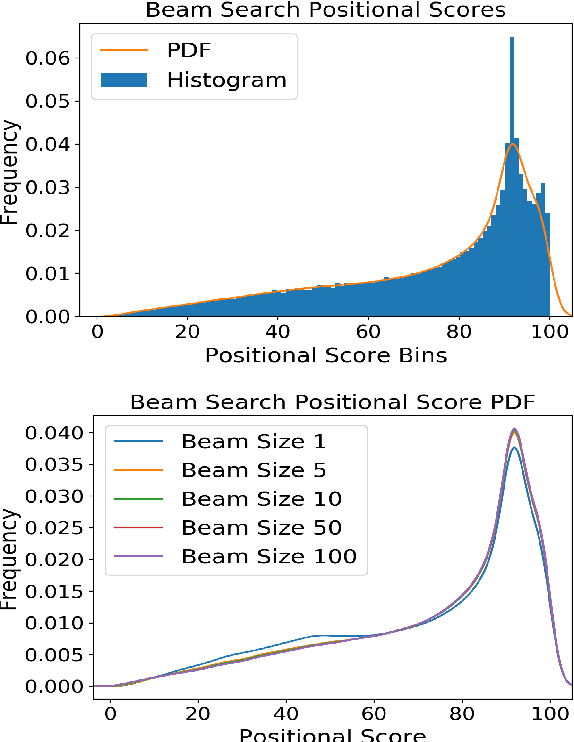
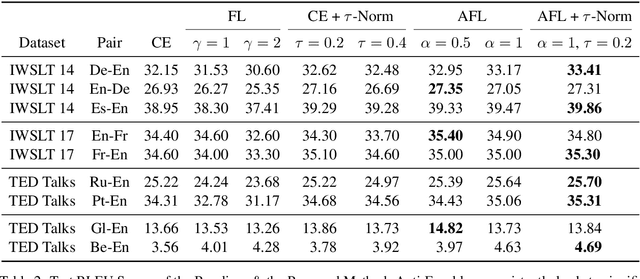
State-of-the-art Neural Machine Translation (NMT) models struggle with generating low-frequency tokens, tackling which remains a major challenge. The analysis of long-tailed phenomena in the context of structured prediction tasks is further hindered by the added complexities of search during inference. In this work, we quantitatively characterize such long-tailed phenomena at two levels of abstraction, namely, token classification and sequence generation. We propose a new loss function, the Anti-Focal loss, to better adapt model training to the structural dependencies of conditional text generation by incorporating the inductive biases of beam search in the training process. We show the efficacy of the proposed technique on a number of Machine Translation (MT) datasets, demonstrating that it leads to significant gains over cross-entropy across different language pairs, especially on the generation of low-frequency words. We have released the code to reproduce our results.
Support-set bottlenecks for video-text representation learning
Oct 06, 2020
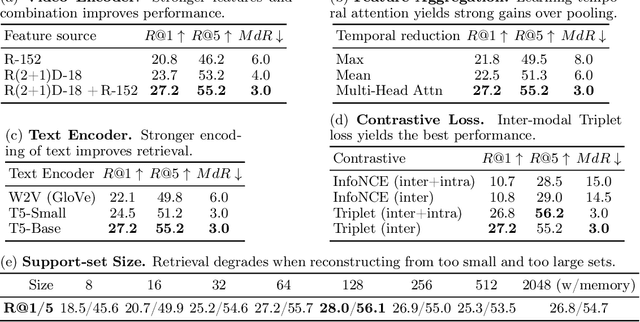
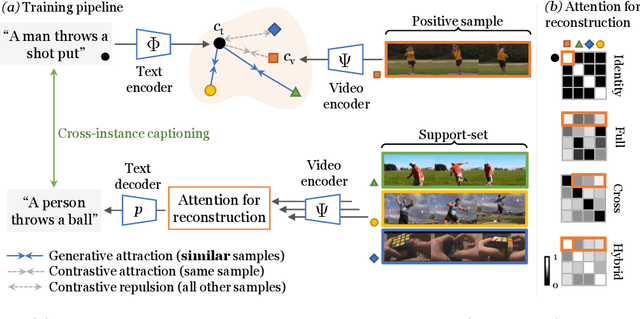
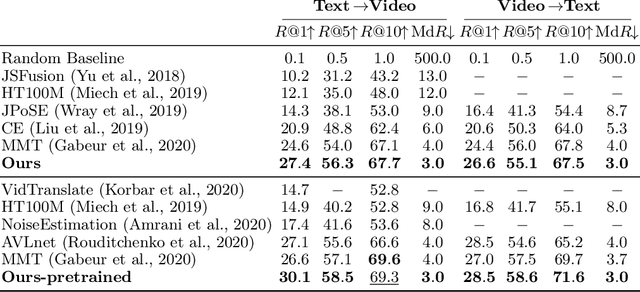
The dominant paradigm for learning video-text representations -- noise contrastive learning -- increases the similarity of the representations of pairs of samples that are known to be related, such as text and video from the same sample, and pushes away the representations of all other pairs. We posit that this last behaviour is too strict, enforcing dissimilar representations even for samples that are semantically-related -- for example, visually similar videos or ones that share the same depicted action. In this paper, we propose a novel method that alleviates this by leveraging a generative model to naturally push these related samples together: each sample's caption must be reconstructed as a weighted combination of other support samples' visual representations. This simple idea ensures that representations are not overly-specialized to individual samples, are reusable across the dataset, and results in representations that explicitly encode semantics shared between samples, unlike noise contrastive learning. Our proposed method outperforms others by a large margin on MSR-VTT, VATEX and ActivityNet, for video-to-text and text-to-video retrieval.
Fine-Grained Grounding for Multimodal Speech Recognition
Oct 05, 2020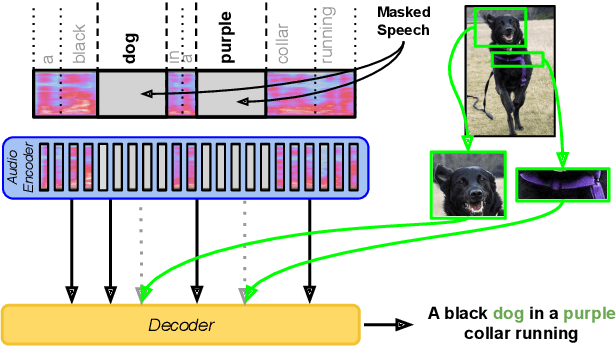
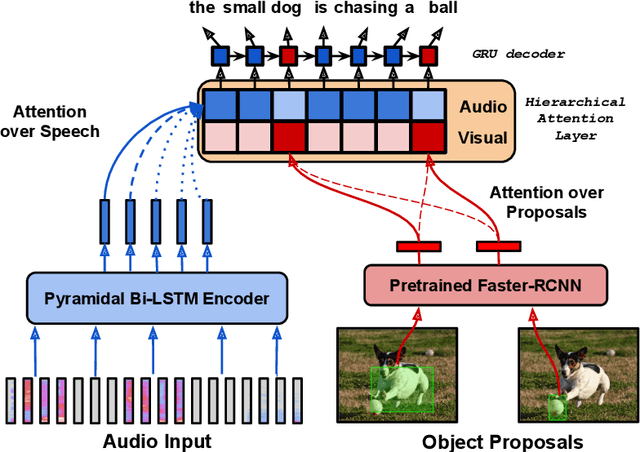
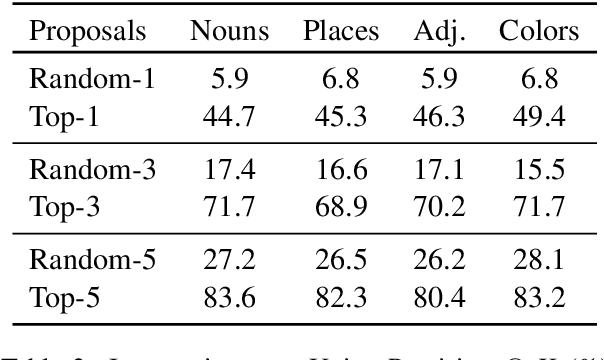
Multimodal automatic speech recognition systems integrate information from images to improve speech recognition quality, by grounding the speech in the visual context. While visual signals have been shown to be useful for recovering entities that have been masked in the audio, these models should be capable of recovering a broader range of word types. Existing systems rely on global visual features that represent the entire image, but localizing the relevant regions of the image will make it possible to recover a larger set of words, such as adjectives and verbs. In this paper, we propose a model that uses finer-grained visual information from different parts of the image, using automatic object proposals. In experiments on the Flickr8K Audio Captions Corpus, we find that our model improves over approaches that use global visual features, that the proposals enable the model to recover entities and other related words, such as adjectives, and that improvements are due to the model's ability to localize the correct proposals.
Revisiting Factorizing Aggregated Posterior in Learning Disentangled Representations
Sep 12, 2020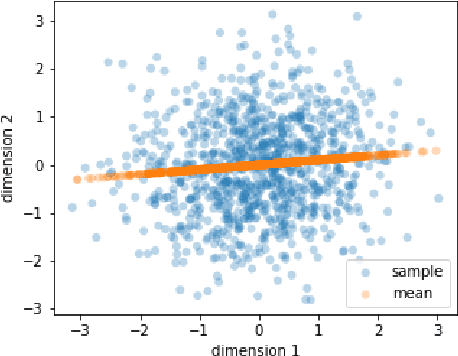



In the problem of learning disentangled representations, one of the promising methods is to factorize aggregated posterior by penalizing the total correlation of sampled latent variables. However, this well-motivated strategy has a blind spot: there is a disparity between the sampled latent representation and its corresponding mean representation. In this paper, we provide a theoretical explanation that low total correlation of sampled representation cannot guarantee low total correlation of the mean representation. Indeed, we prove that for the multivariate normal distributions, the mean representation with arbitrarily high total correlation can have a corresponding sampled representation with bounded total correlation. We also propose a method to eliminate this disparity. Experiments show that our model can learn a mean representation with much lower total correlation, hence a factorized mean representation. Moreover, we offer a detailed explanation of the limitations of factorizing aggregated posterior -- factor disintegration. Our work indicates a potential direction for future research of disentangled learning.
How2Sign: A Large-scale Multimodal Dataset for Continuous American Sign Language
Aug 18, 2020
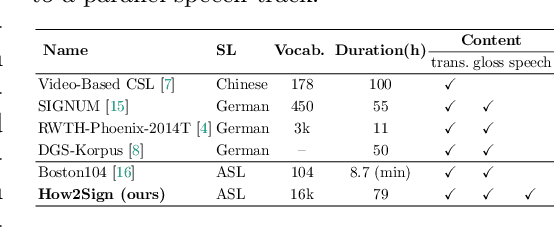
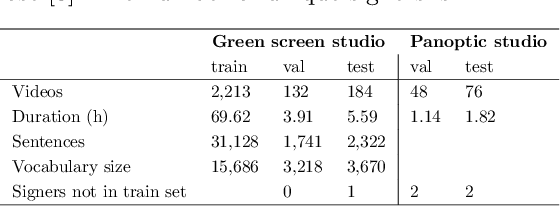
Sign Language is the primary means of communication for the majority of the Deaf community. One of the factors that has hindered the progress in the areas of automatic sign language recognition, generation, and translation is the absence of large annotated datasets, especially continuous sign language datasets, i.e. datasets that are annotated and segmented at the sentence or utterance level. Towards this end, in this work we introduce How2Sign, a work-in-progress dataset collection. How2Sign consists of a parallel corpus of 80 hours of sign language videos (collected with multi-view RGB and depth sensor data) with corresponding speech transcriptions and gloss annotations. In addition, a three-hour subset was further recorded in a geodesic dome setup using hundreds of cameras and sensors, which enables detailed 3D reconstruction and pose estimation and paves the way for vision systems to understand the 3D geometry of sign language.
AlloVera: A Multilingual Allophone Database
Apr 17, 2020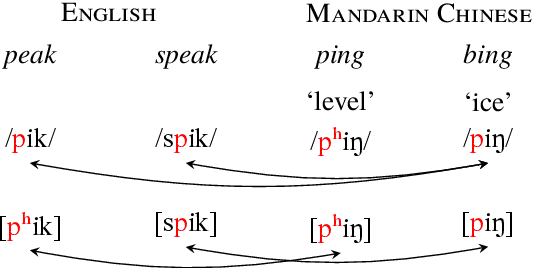
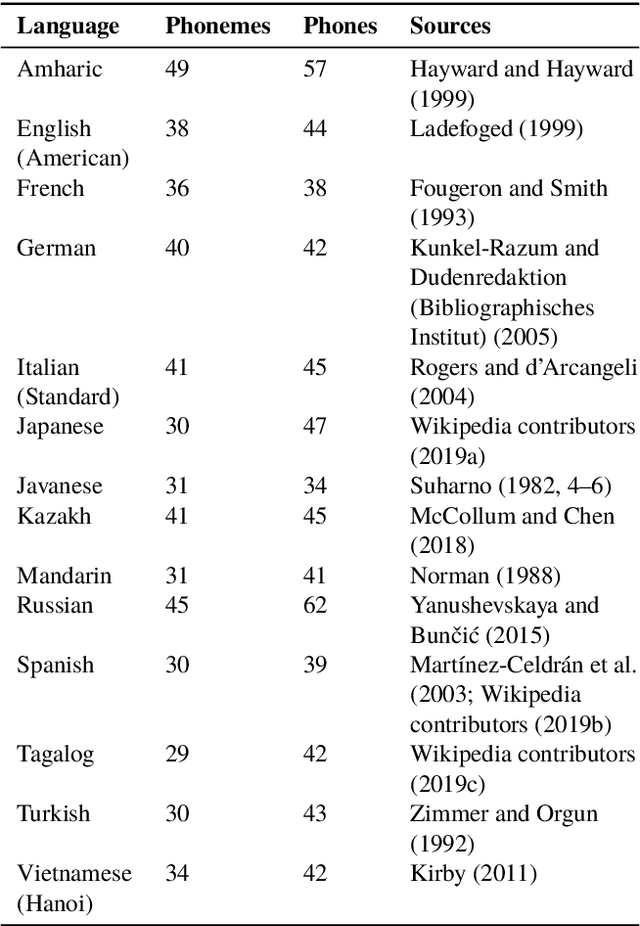


We introduce a new resource, AlloVera, which provides mappings from 218 allophones to phonemes for 14 languages. Phonemes are contrastive phonological units, and allophones are their various concrete realizations, which are predictable from phonological context. While phonemic representations are language specific, phonetic representations (stated in terms of (allo)phones) are much closer to a universal (language-independent) transcription. AlloVera allows the training of speech recognition models that output phonetic transcriptions in the International Phonetic Alphabet (IPA), regardless of the input language. We show that a "universal" allophone model, Allosaurus, built with AlloVera, outperforms "universal" phonemic models and language-specific models on a speech-transcription task. We explore the implications of this technology (and related technologies) for the documentation of endangered and minority languages. We further explore other applications for which AlloVera will be suitable as it grows, including phonological typology.
ASR Error Correction and Domain Adaptation Using Machine Translation
Mar 13, 2020
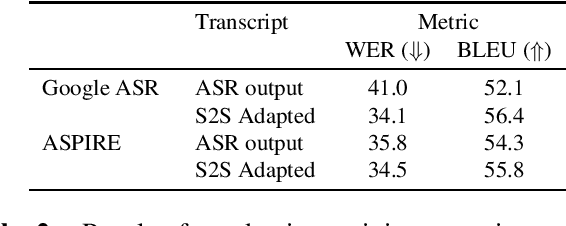
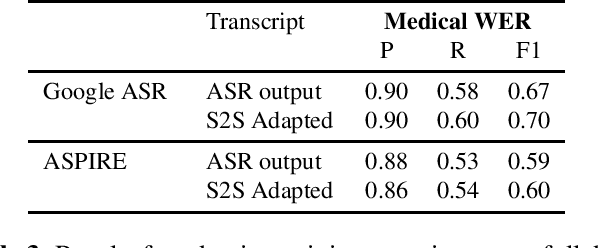
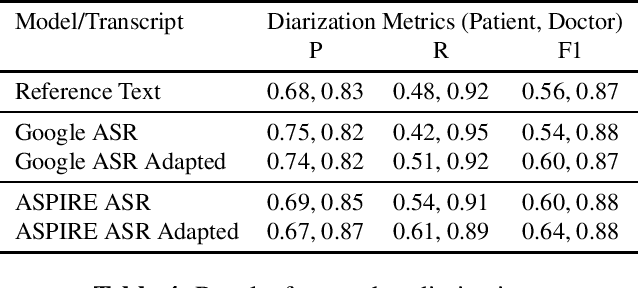
Off-the-shelf pre-trained Automatic Speech Recognition (ASR) systems are an increasingly viable service for companies of any size building speech-based products. While these ASR systems are trained on large amounts of data, domain mismatch is still an issue for many such parties that want to use this service as-is leading to not so optimal results for their task. We propose a simple technique to perform domain adaptation for ASR error correction via machine translation. The machine translation model is a strong candidate to learn a mapping from out-of-domain ASR errors to in-domain terms in the corresponding reference files. We use two off-the-shelf ASR systems in this work: Google ASR (commercial) and the ASPIRE model (open-source). We observe 7% absolute improvement in word error rate and 4 point absolute improvement in BLEU score in Google ASR output via our proposed method. We also evaluate ASR error correction via a downstream task of Speaker Diarization that captures speaker style, syntax, structure and semantic improvements we obtain via ASR correction.
Universal Phone Recognition with a Multilingual Allophone System
Feb 26, 2020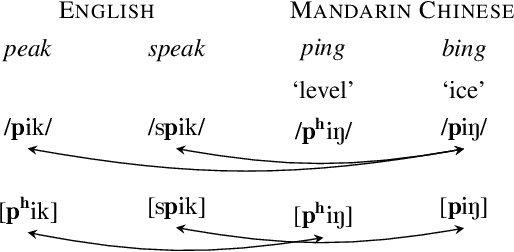

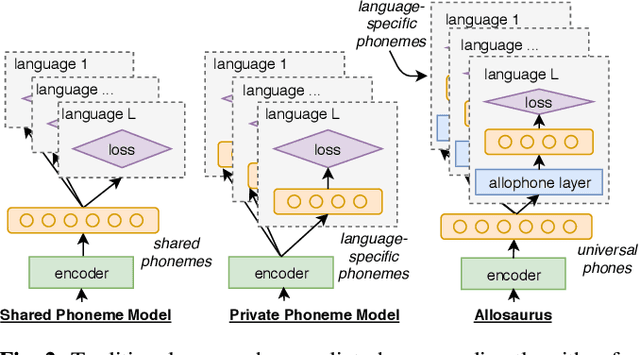

Multilingual models can improve language processing, particularly for low resource situations, by sharing parameters across languages. Multilingual acoustic models, however, generally ignore the difference between phonemes (sounds that can support lexical contrasts in a particular language) and their corresponding phones (the sounds that are actually spoken, which are language independent). This can lead to performance degradation when combining a variety of training languages, as identically annotated phonemes can actually correspond to several different underlying phonetic realizations. In this work, we propose a joint model of both language-independent phone and language-dependent phoneme distributions. In multilingual ASR experiments over 11 languages, we find that this model improves testing performance by 2% phoneme error rate absolute in low-resource conditions. Additionally, because we are explicitly modeling language-independent phones, we can build a (nearly-)universal phone recognizer that, when combined with the PHOIBLE large, manually curated database of phone inventories, can be customized into 2,000 language dependent recognizers. Experiments on two low-resourced indigenous languages, Inuktitut and Tusom, show that our recognizer achieves phone accuracy improvements of more than 17%, moving a step closer to speech recognition for all languages in the world.