 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutput-Constrained Bayesian Neural Networks
May 15, 2019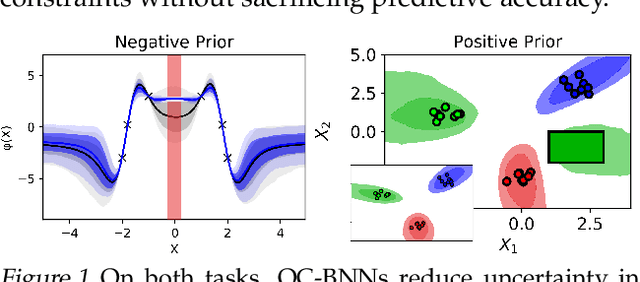
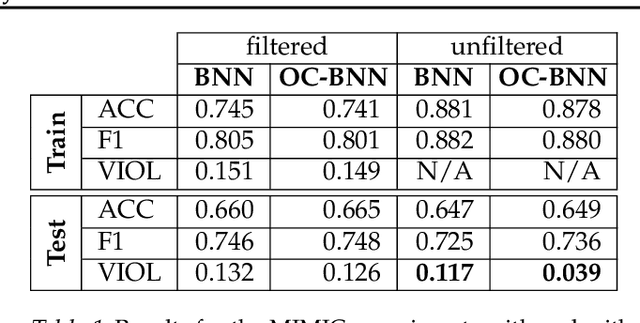
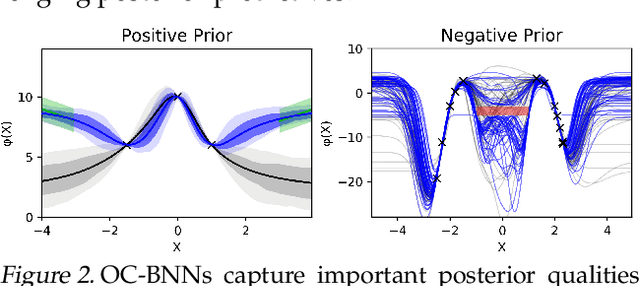
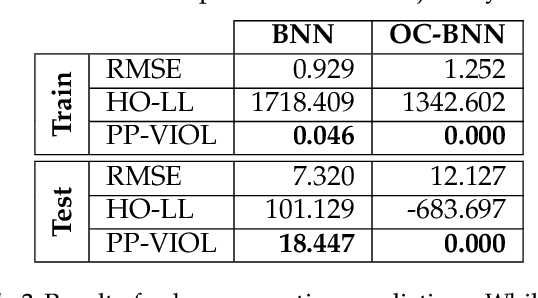
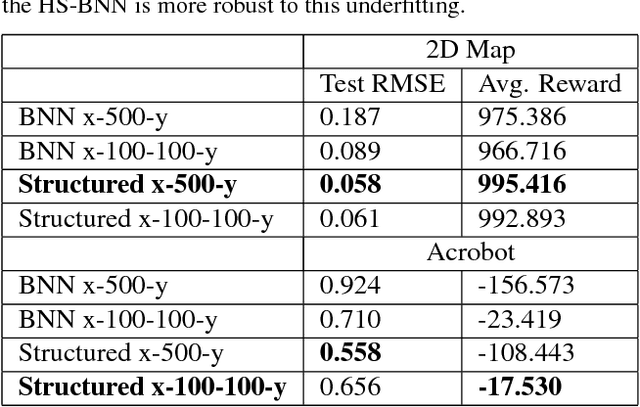
Bayesian neural network (BNN) priors are defined in parameter space, making it hard to encode prior knowledge expressed in function space. We formulate a prior that incorporates functional constraints about what the output can or cannot be in regions of the input space. Output-Constrained BNNs (OC-BNN) represent an interpretable approach of enforcing a range of constraints, fully consistent with the Bayesian framework and amenable to black-box inference. We demonstrate how OC-BNNs improve model robustness and prevent the prediction of infeasible outputs in two real-world applications of healthcare and robotics.
Truly Batch Apprenticeship Learning with Deep Successor Features
Mar 24, 2019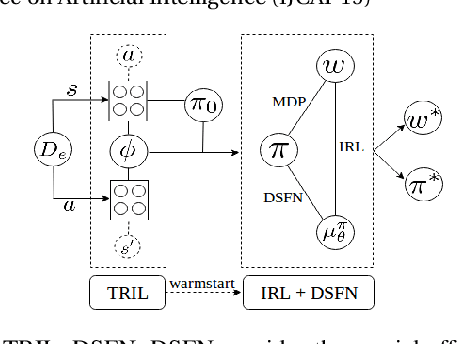
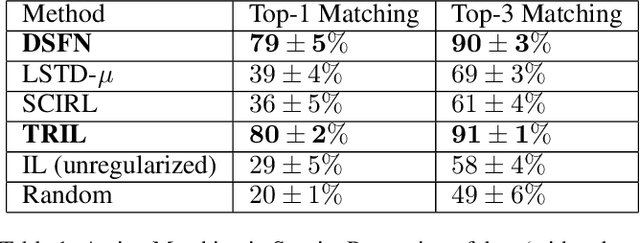
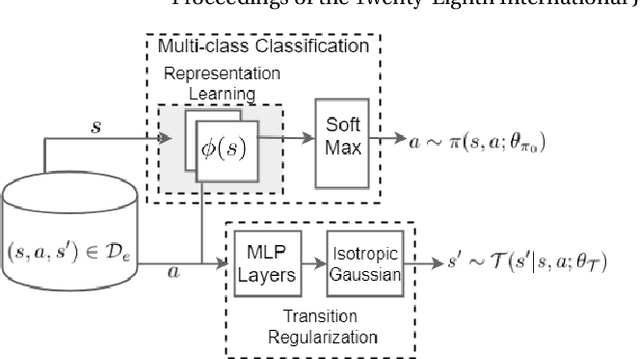
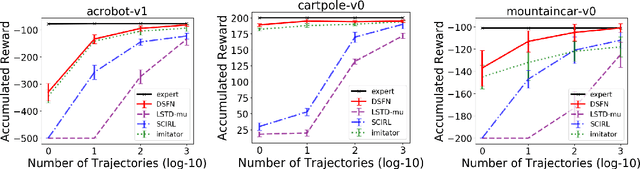
We introduce a novel apprenticeship learning algorithm to learn an expert's underlying reward structure in off-policy model-free \emph{batch} settings. Unlike existing methods that require a dynamics model or additional data acquisition for on-policy evaluation, our algorithm requires only the batch data of observed expert behavior. Such settings are common in real-world tasks---health care, finance or industrial processes ---where accurate simulators do not exist or data acquisition is costly. To address challenges in batch settings, we introduce Deep Successor Feature Networks(DSFN) that estimate feature expectations in an off-policy setting and a transition-regularized imitation network that produces a near-expert initial policy and an efficient feature representation. Our algorithm achieves superior results in batch settings on both control benchmarks and a vital clinical task of sepsis management in the Intensive Care Unit.
An Evaluation of the Human-Interpretability of Explanation
Jan 31, 2019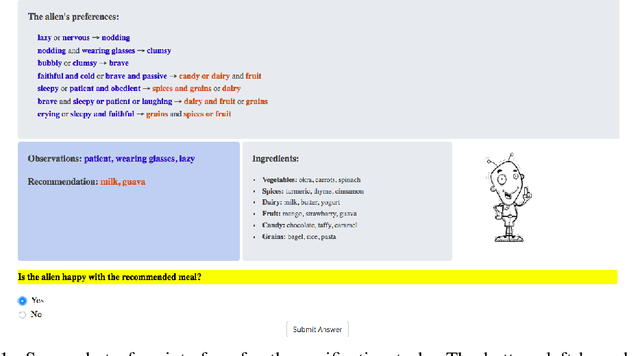
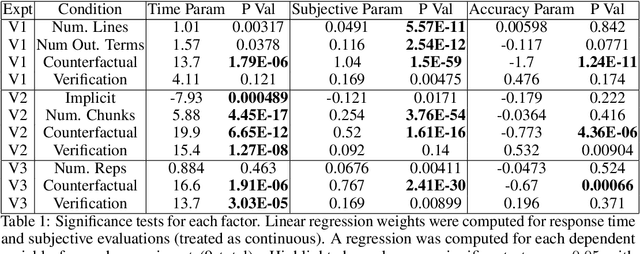
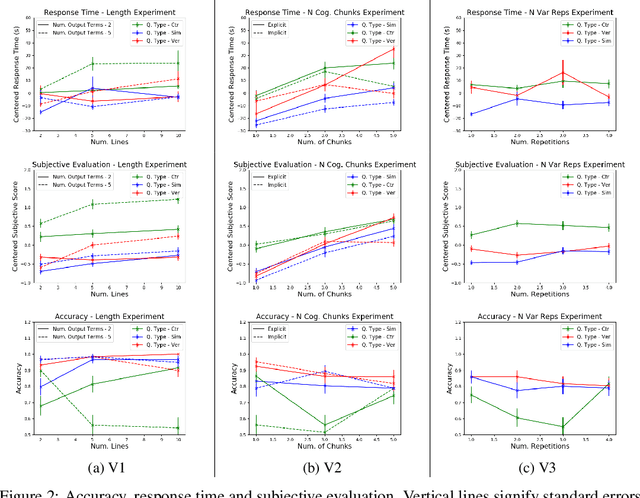
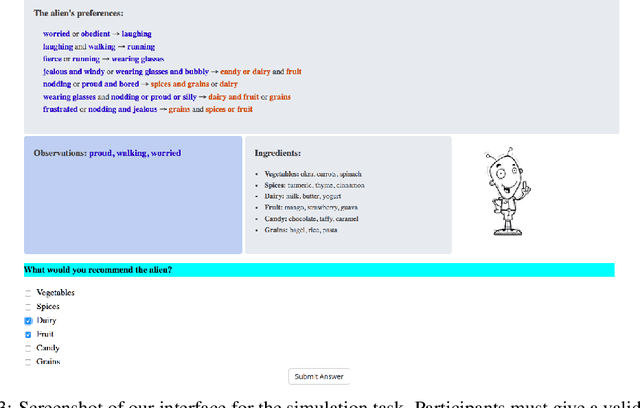
Recent years have seen a boom in interest in machine learning systems that can provide a human-understandable rationale for their predictions or decisions. However, exactly what kinds of explanation are truly human-interpretable remains poorly understood. This work advances our understanding of what makes explanations interpretable under three specific tasks that users may perform with machine learning systems: simulation of the response, verification of a suggested response, and determining whether the correctness of a suggested response changes under a change to the inputs. Through carefully controlled human-subject experiments, we identify regularizers that can be used to optimize for the interpretability of machine learning systems. Our results show that the type of complexity matters: cognitive chunks (newly defined concepts) affect performance more than variable repetitions, and these trends are consistent across tasks and domains. This suggests that there may exist some common design principles for explanation systems.
Improving Sepsis Treatment Strategies by Combining Deep and Kernel-Based Reinforcement Learning
Jan 15, 2019
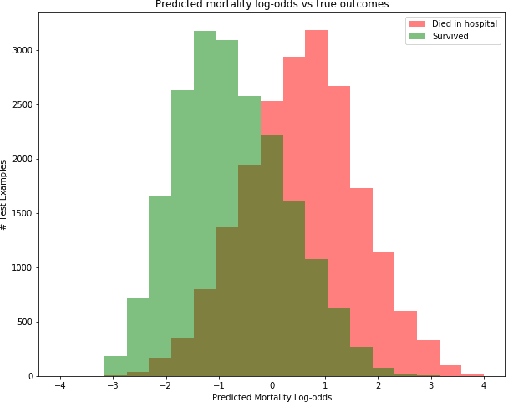


Sepsis is the leading cause of mortality in the ICU. It is challenging to manage because individual patients respond differently to treatment. Thus, tailoring treatment to the individual patient is essential for the best outcomes. In this paper, we take steps toward this goal by applying a mixture-of-experts framework to personalize sepsis treatment. The mixture model selectively alternates between neighbor-based (kernel) and deep reinforcement learning (DRL) experts depending on patient's current history. On a large retrospective cohort, this mixture-based approach outperforms physician, kernel only, and DRL-only experts.
Representation Balancing MDPs for Off-Policy Policy Evaluation
Oct 31, 2018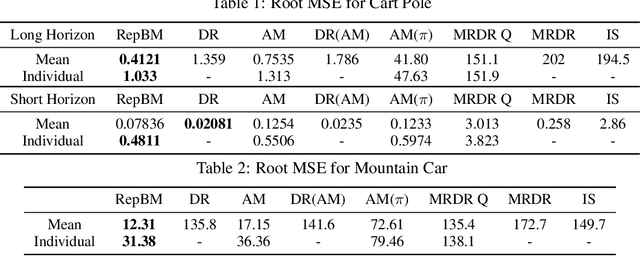

We study the problem of off-policy policy evaluation (OPPE) in RL. In contrast to prior work, we consider how to estimate both the individual policy value and average policy value accurately. We draw inspiration from recent work in causal reasoning, and propose a new finite sample generalization error bound for value estimates from MDP models. Using this upper bound as an objective, we develop a learning algorithm of an MDP model with a balanced representation, and show that our approach can yield substantially lower MSE in common synthetic benchmarks and a HIV treatment simulation domain.
Human-in-the-Loop Interpretability Prior
Oct 30, 2018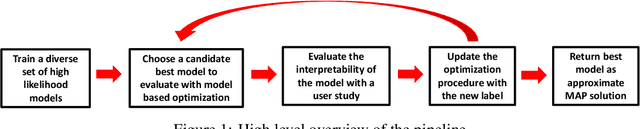
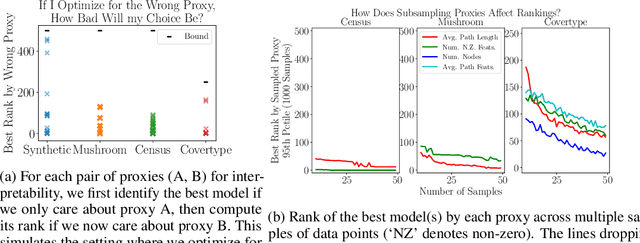
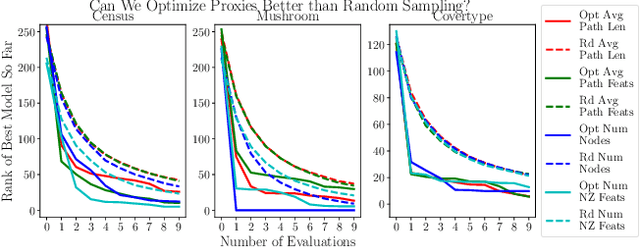
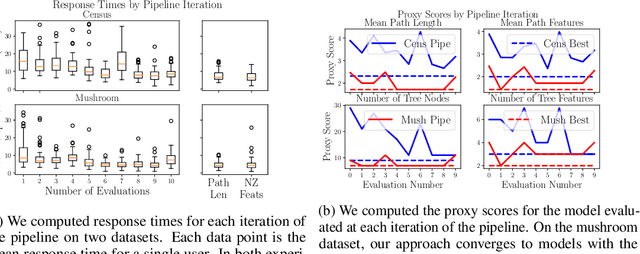
We often desire our models to be interpretable as well as accurate. Prior work on optimizing models for interpretability has relied on easy-to-quantify proxies for interpretability, such as sparsity or the number of operations required. In this work, we optimize for interpretability by directly including humans in the optimization loop. We develop an algorithm that minimizes the number of user studies to find models that are both predictive and interpretable and demonstrate our approach on several data sets. Our human subjects results show trends towards different proxy notions of interpretability on different datasets, which suggests that different proxies are preferred on different tasks.
Depth-bounding is effective: Improvements and evaluation of unsupervised PCFG induction
Sep 10, 2018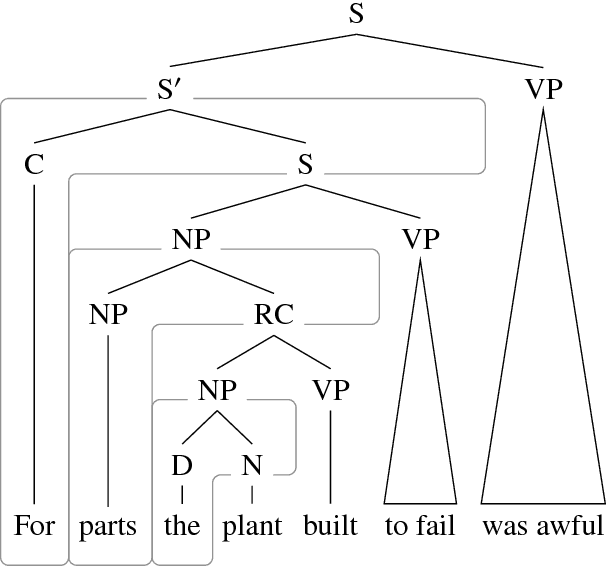
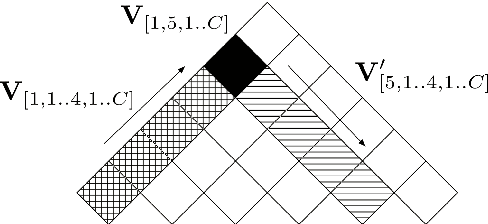
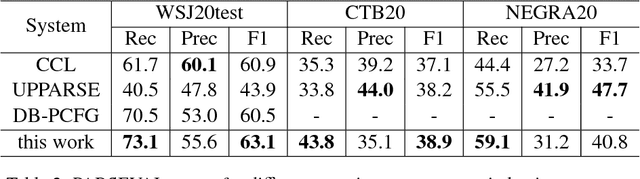
There have been several recent attempts to improve the accuracy of grammar induction systems by bounding the recursive complexity of the induction model (Ponvert et al., 2011; Noji and Johnson, 2016; Shain et al., 2016; Jin et al., 2018). Modern depth-bounded grammar inducers have been shown to be more accurate than early unbounded PCFG inducers, but this technique has never been compared against unbounded induction within the same system, in part because most previous depth-bounding models are built around sequence models, the complexity of which grows exponentially with the maximum allowed depth. The present work instead applies depth bounds within a chart-based Bayesian PCFG inducer (Johnson et al., 2007b), where bounding can be switched on and off, and then samples trees with and without bounding. Results show that depth-bounding is indeed significantly effective in limiting the search space of the inducer and thereby increasing the accuracy of the resulting parsing model. Moreover, parsing results on English, Chinese and German show that this bounded model with a new inference technique is able to produce parse trees more accurately than or competitively with state-of-the-art constituency-based grammar induction models.
Structured Variational Learning of Bayesian Neural Networks with Horseshoe Priors
Jul 31, 2018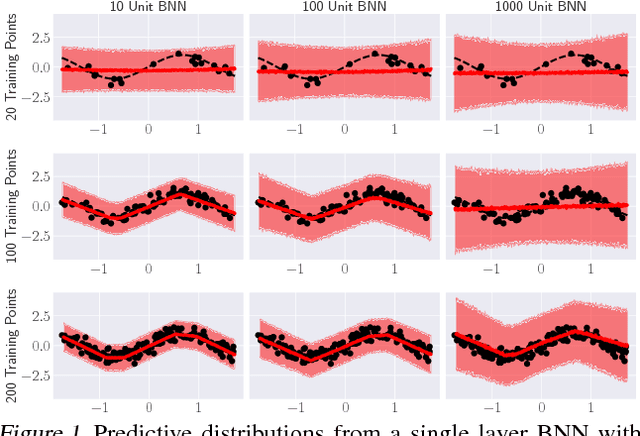
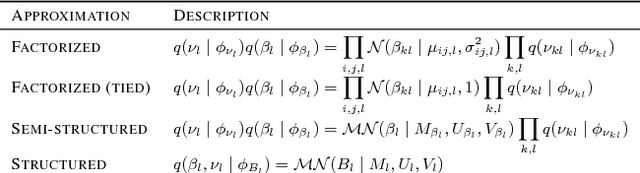
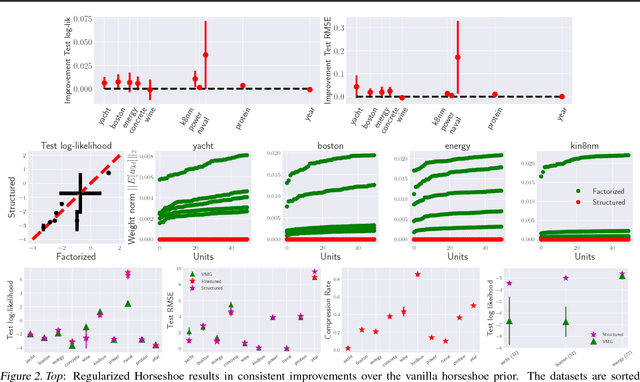
Bayesian Neural Networks (BNNs) have recently received increasing attention for their ability to provide well-calibrated posterior uncertainties. However, model selection---even choosing the number of nodes---remains an open question. Recent work has proposed the use of a horseshoe prior over node pre-activations of a Bayesian neural network, which effectively turns off nodes that do not help explain the data. In this work, we propose several modeling and inference advances that consistently improve the compactness of the model learned while maintaining predictive performance, especially in smaller-sample settings including reinforcement learning.
Learning Qualitatively Diverse and Interpretable Rules for Classification
Jul 19, 2018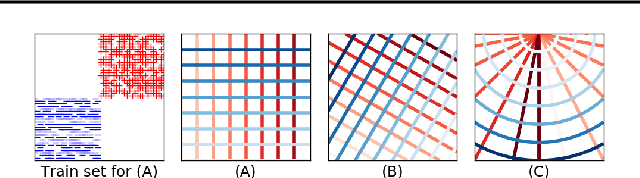
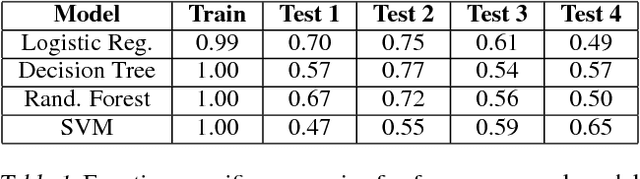
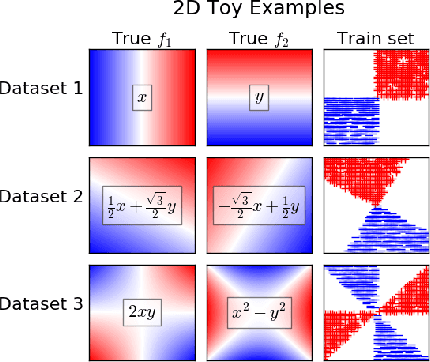
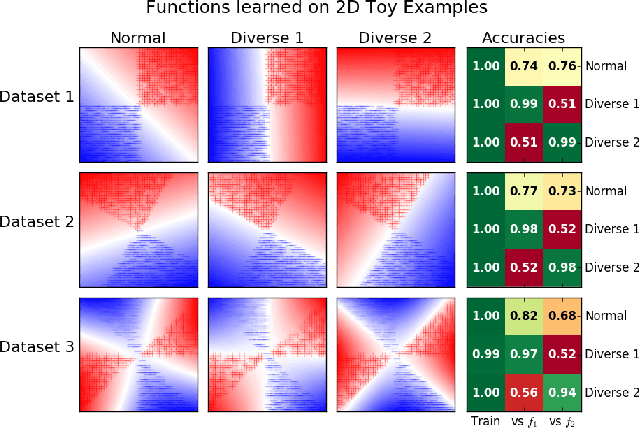
There has been growing interest in developing accurate models that can also be explained to humans. Unfortunately, if there exist multiple distinct but accurate models for some dataset, current machine learning methods are unlikely to find them: standard techniques will likely recover a complex model that combines them. In this work, we introduce a way to identify a maximal set of distinct but accurate models for a dataset. We demonstrate empirically that, in situations where the data supports multiple accurate classifiers, we tend to recover simpler, more interpretable classifiers rather than more complex ones.
Behaviour Policy Estimation in Off-Policy Policy Evaluation: Calibration Matters
Jul 10, 2018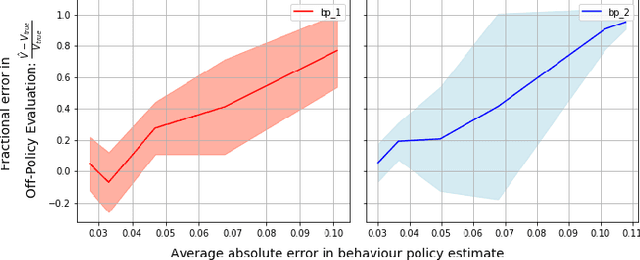
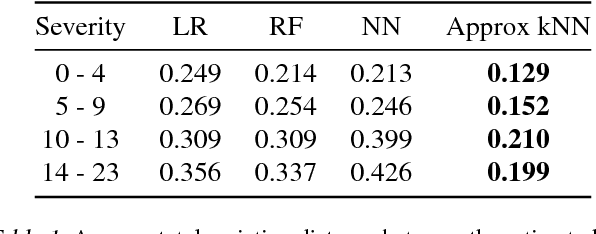
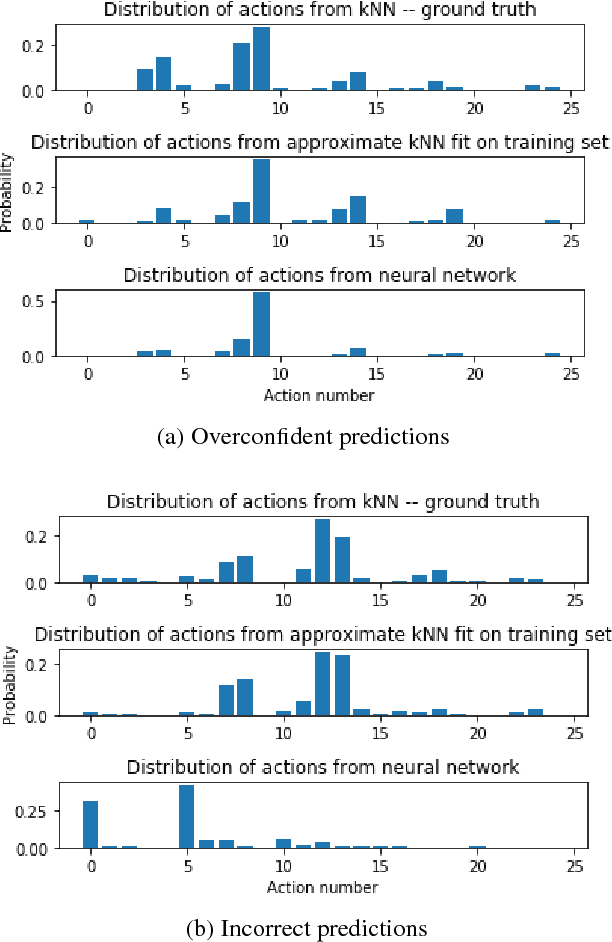

In this work, we consider the problem of estimating a behaviour policy for use in Off-Policy Policy Evaluation (OPE) when the true behaviour policy is unknown. Via a series of empirical studies, we demonstrate how accurate OPE is strongly dependent on the calibration of estimated behaviour policy models: how precisely the behaviour policy is estimated from data. We show how powerful parametric models such as neural networks can result in highly uncalibrated behaviour policy models on a real-world medical dataset, and illustrate how a simple, non-parametric, k-nearest neighbours model produces better calibrated behaviour policy estimates and can be used to obtain superior importance sampling-based OPE estimates.