 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Classical Data to Quantum Advantage -- Quantum Policy Evaluation on Quantum Hardware
Sep 09, 2025Quantum policy evaluation (QPE) is a reinforcement learning (RL) algorithm which is quadratically more efficient than an analogous classical Monte Carlo estimation. It makes use of a direct quantum mechanical realization of a finite Markov decision process, in which the agent and the environment are modeled by unitary operators and exchange states, actions, and rewards in superposition. Previously, the quantum environment has been implemented and parametrized manually for an illustrative benchmark using a quantum simulator. In this paper, we demonstrate how these environment parameters can be learned from a batch of classical observational data through quantum machine learning (QML) on quantum hardware. The learned quantum environment is then applied in QPE to also compute policy evaluations on quantum hardware. Our experiments reveal that, despite challenges such as noise and short coherence times, the integration of QML and QPE shows promising potential for achieving quantum advantage in RL.
Variational Quantum Circuits in Offline Contextual Bandit Problems
Sep 09, 2025This paper explores the application of variational quantum circuits (VQCs) for solving offline contextual bandit problems in industrial optimization tasks. Using the Industrial Benchmark (IB) environment, we evaluate the performance of quantum regression models against classical models. Our findings demonstrate that quantum models can effectively fit complex reward functions, identify optimal configurations via particle swarm optimization (PSO), and generalize well in noisy and sparse datasets. These results provide a proof of concept for utilizing VQCs in offline contextual bandit problems and highlight their potential in industrial optimization tasks.
Is Q-learning an Ill-posed Problem?
Feb 21, 2025This paper investigates the instability of Q-learning in continuous environments, a challenge frequently encountered by practitioners. Traditionally, this instability is attributed to bootstrapping and regression model errors. Using a representative reinforcement learning benchmark, we systematically examine the effects of bootstrapping and model inaccuracies by incrementally eliminating these potential error sources. Our findings reveal that even in relatively simple benchmarks, the fundamental task of Q-learning - iteratively learning a Q-function from policy-specific target values - can be inherently ill-posed and prone to failure. These insights cast doubt on the reliability of Q-learning as a universal solution for reinforcement learning problems.
TEA: Trajectory Encoding Augmentation for Robust and Transferable Policies in Offline Reinforcement Learning
Nov 28, 2024



In this paper, we investigate offline reinforcement learning (RL) with the goal of training a single robust policy that generalizes effectively across environments with unseen dynamics. We propose a novel approach, Trajectory Encoding Augmentation (TEA), which extends the state space by integrating latent representations of environmental dynamics obtained from sequence encoders, such as AutoEncoders. Our findings show that incorporating these encodings with TEA improves the transferability of a single policy to novel environments with new dynamics, surpassing methods that rely solely on unmodified states. These results indicate that TEA captures critical, environment-specific characteristics, enabling RL agents to generalize effectively across dynamic conditions.
Neural-ANOVA: Model Decomposition for Interpretable Machine Learning
Aug 22, 2024



The analysis of variance (ANOVA) decomposition offers a systematic method to understand the interaction effects that contribute to a specific decision output. In this paper we introduce Neural-ANOVA, an approach to decompose neural networks into glassbox models using the ANOVA decomposition. Our approach formulates a learning problem, which enables rapid and closed-form evaluation of integrals over subspaces that appear in the calculation of the ANOVA decomposition. Finally, we conduct numerical experiments to illustrate the advantages of enhanced interpretability and model validation by a decomposition of the learned interaction effects.
Why long model-based rollouts are no reason for bad Q-value estimates
Jul 16, 2024This paper explores the use of model-based offline reinforcement learning with long model rollouts. While some literature criticizes this approach due to compounding errors, many practitioners have found success in real-world applications. The paper aims to demonstrate that long rollouts do not necessarily result in exponentially growing errors and can actually produce better Q-value estimates than model-free methods. These findings can potentially enhance reinforcement learning techniques.
Model-based Offline Quantum Reinforcement Learning
Apr 14, 2024



This paper presents the first algorithm for model-based offline quantum reinforcement learning and demonstrates its functionality on the cart-pole benchmark. The model and the policy to be optimized are each implemented as variational quantum circuits. The model is trained by gradient descent to fit a pre-recorded data set. The policy is optimized with a gradient-free optimization scheme using the return estimate given by the model as the fitness function. This model-based approach allows, in principle, full realization on a quantum computer during the optimization phase and gives hope that a quantum advantage can be achieved as soon as sufficiently powerful quantum computers are available.
Learning Control Policies for Variable Objectives from Offline Data
Aug 11, 2023



Offline reinforcement learning provides a viable approach to obtain advanced control strategies for dynamical systems, in particular when direct interaction with the environment is not available. In this paper, we introduce a conceptual extension for model-based policy search methods, called variable objective policy (VOP). With this approach, policies are trained to generalize efficiently over a variety of objectives, which parameterize the reward function. We demonstrate that by altering the objectives passed as input to the policy, users gain the freedom to adjust its behavior or re-balance optimization targets at runtime, without need for collecting additional observation batches or re-training.
Automatic Trade-off Adaptation in Offline RL
Jun 16, 2023Recently, offline RL algorithms have been proposed that remain adaptive at runtime. For example, the LION algorithm \cite{lion} provides the user with an interface to set the trade-off between behavior cloning and optimality w.r.t. the estimated return at runtime. Experts can then use this interface to adapt the policy behavior according to their preferences and find a good trade-off between conservatism and performance optimization. Since expert time is precious, we extend the methodology with an autopilot that automatically finds the correct parameterization of the trade-off, yielding a new algorithm which we term AutoLION.
Safe Policy Improvement Approaches and their Limitations
Aug 01, 2022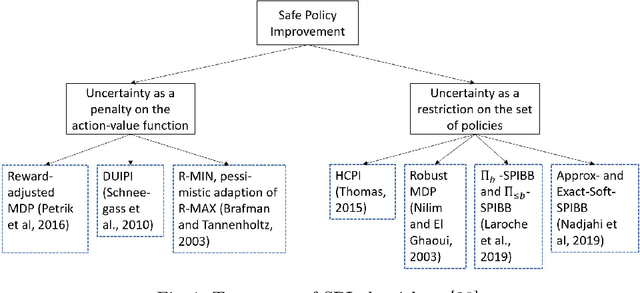

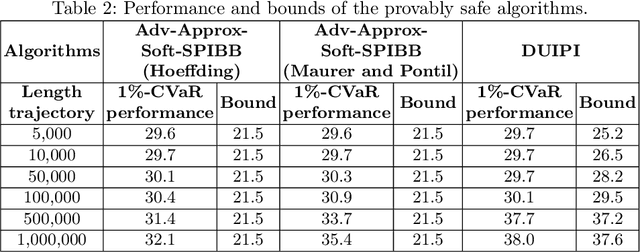
Safe Policy Improvement (SPI) is an important technique for offline reinforcement learning in safety critical applications as it improves the behavior policy with a high probability. We classify various SPI approaches from the literature into two groups, based on how they utilize the uncertainty of state-action pairs. Focusing on the Soft-SPIBB (Safe Policy Improvement with Soft Baseline Bootstrapping) algorithms, we show that their claim of being provably safe does not hold. Based on this finding, we develop adaptations, the Adv-Soft-SPIBB algorithms, and show that they are provably safe. A heuristic adaptation, Lower-Approx-Soft-SPIBB, yields the best performance among all SPIBB algorithms in extensive experiments on two benchmarks. We also check the safety guarantees of the provably safe algorithms and show that huge amounts of data are necessary such that the safety bounds become useful in practice.