 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Integrating Personal Knowledge into Test-Time Predictions
Jun 12, 2024



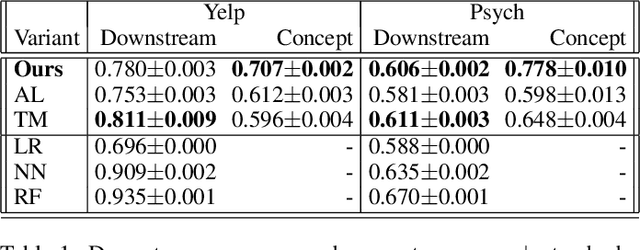
Machine learning (ML) models can make decisions based on large amounts of data, but they can be missing personal knowledge available to human users about whom predictions are made. For example, a model trained to predict psychiatric outcomes may know nothing about a patient's social support system, and social support may look different for different patients. In this work, we introduce the problem of human feature integration, which provides a way to incorporate important personal-knowledge from users without domain expertise into ML predictions. We characterize this problem through illustrative user stories and comparisons to existing approaches; we formally describe this problem in a way that paves the ground for future technical solutions; and we provide a proof-of-concept study of a simple version of a solution to this problem in a semi-realistic setting.
(When) Are Contrastive Explanations of Reinforcement Learning Helpful?
Nov 14, 2022


Global explanations of a reinforcement learning (RL) agent's expected behavior can make it safer to deploy. However, such explanations are often difficult to understand because of the complicated nature of many RL policies. Effective human explanations are often contrastive, referencing a known contrast (policy) to reduce redundancy. At the same time, these explanations also require the additional effort of referencing that contrast when evaluating an explanation. We conduct a user study to understand whether and when contrastive explanations might be preferable to complete explanations that do not require referencing a contrast. We find that complete explanations are generally more effective when they are the same size or smaller than a contrastive explanation of the same policy, and no worse when they are larger. This suggests that contrastive explanations are not sufficient to solve the problem of effectively explaining reinforcement learning policies, and require additional careful study for use in this context.
Promises and Pitfalls of Black-Box Concept Learning Models
Jun 24, 2021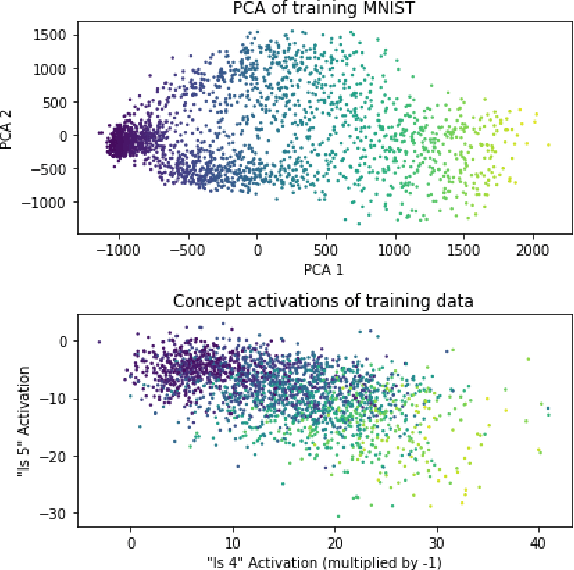
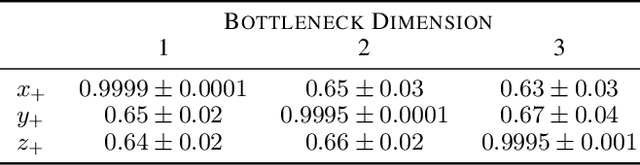

Machine learning models that incorporate concept learning as an intermediate step in their decision making process can match the performance of black-box predictive models while retaining the ability to explain outcomes in human understandable terms. However, we demonstrate that the concept representations learned by these models encode information beyond the pre-defined concepts, and that natural mitigation strategies do not fully work, rendering the interpretation of the downstream prediction misleading. We describe the mechanism underlying the information leakage and suggest recourse for mitigating its effects.
Learning Interpretable Concept-Based Models with Human Feedback
Dec 04, 2020
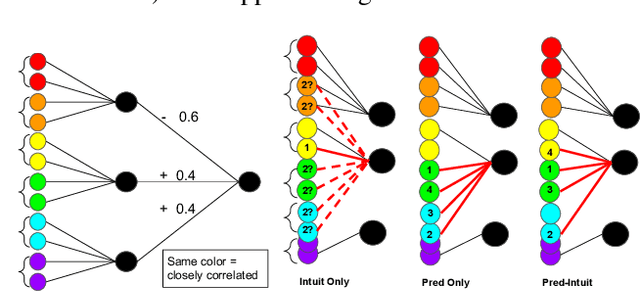

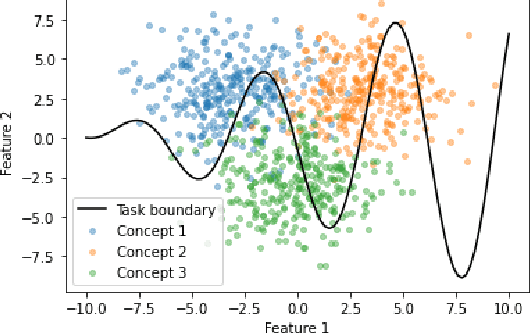
Machine learning models that first learn a representation of a domain in terms of human-understandable concepts, then use it to make predictions, have been proposed to facilitate interpretation and interaction with models trained on high-dimensional data. However these methods have important limitations: the way they define concepts are not inherently interpretable, and they assume that concept labels either exist for individual instances or can easily be acquired from users. These limitations are particularly acute for high-dimensional tabular features. We propose an approach for learning a set of transparent concept definitions in high-dimensional tabular data that relies on users labeling concept features instead of individual instances. Our method produces concepts that both align with users' intuitive sense of what a concept means, and facilitate prediction of the downstream label by a transparent machine learning model. This ensures that the full model is transparent and intuitive, and as predictive as possible given this constraint. We demonstrate with simulated user feedback on real prediction problems, including one in a clinical domain, that this kind of direct feedback is much more efficient at learning solutions that align with ground truth concept definitions than alternative transparent approaches that rely on labeling instances or other existing interaction mechanisms, while maintaining similar predictive performance.
When Does Uncertainty Matter?: Understanding the Impact of Predictive Uncertainty in ML Assisted Decision Making
Nov 13, 2020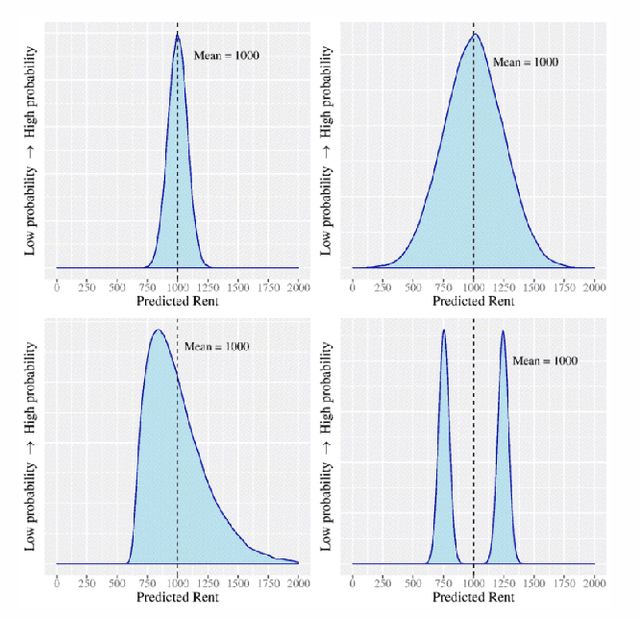

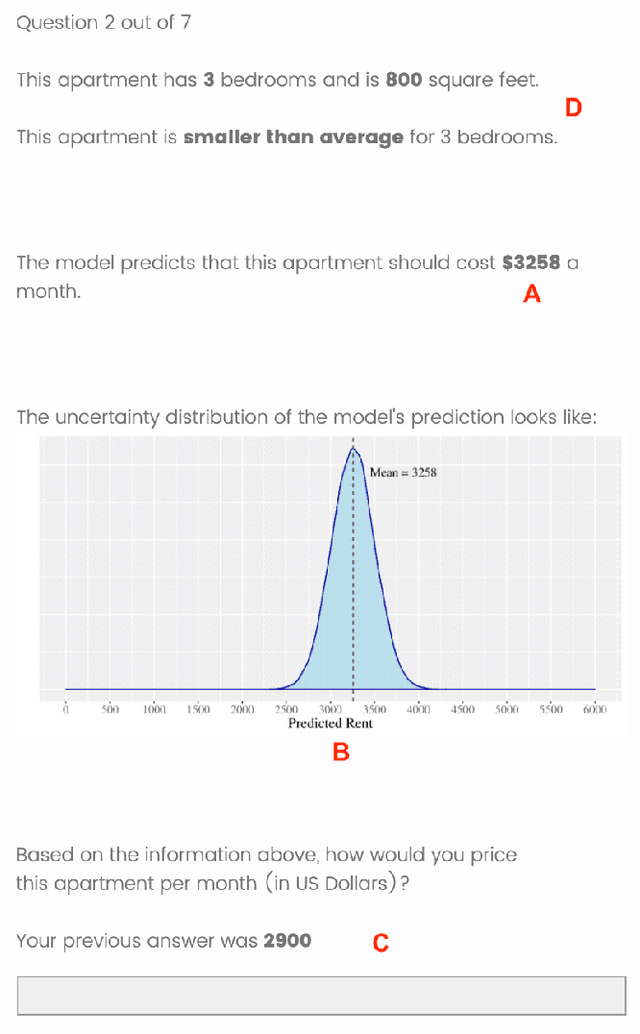
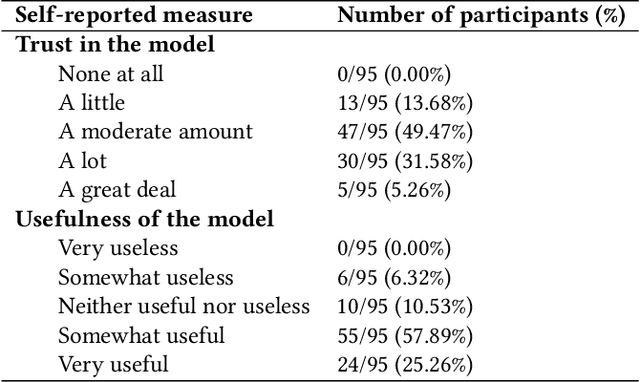
As machine learning (ML) models are increasingly being employed to assist human decision makers, it becomes critical to provide these decision makers with relevant inputs which can help them decide if and how to incorporate model predictions into their decision making. For instance, communicating the uncertainty associated with model predictions could potentially be helpful in this regard. However, there is little to no research that systematically explores if and how conveying predictive uncertainty impacts decision making. In this work, we carry out user studies to systematically assess how people respond to different types of predictive uncertainty i.e., posterior predictive distributions with different shapes and variances, in the context of ML assisted decision making. To the best of our knowledge, this work marks one of the first attempts at studying this question. Our results demonstrate that people are more likely to agree with a model prediction when they observe the corresponding uncertainty associated with the prediction. This finding holds regardless of the properties (shape or variance) of predictive uncertainty (posterior predictive distribution), suggesting that uncertainty is an effective tool for persuading humans to agree with model predictions. Furthermore, we also find that other factors such as domain expertise and familiarity with ML also play a role in determining how someone interprets and incorporates predictive uncertainty into their decision making.
Exploring Computational User Models for Agent Policy Summarization
May 30, 2019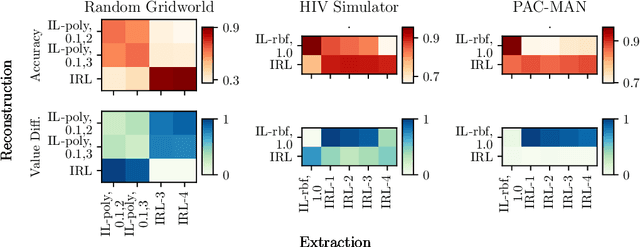

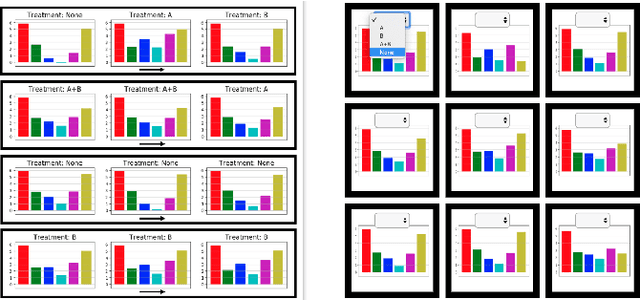

AI agents are being developed to support high stakes decision-making processes from driving cars to prescribing drugs, making it increasingly important for human users to understand their behavior. Policy summarization methods aim to convey strengths and weaknesses of such agents by demonstrating their behavior in a subset of informative states. Some policy summarization methods extract a summary that optimizes the ability to reconstruct the agent's policy under the assumption that users will deploy inverse reinforcement learning. In this paper, we explore the use of different models for extracting summaries. We introduce an imitation learning-based approach to policy summarization; we demonstrate through computational simulations that a mismatch between the model used to extract a summary and the model used to reconstruct the policy results in worse reconstruction quality; and we demonstrate through a human-subject study that people use different models to reconstruct policies in different contexts, and that matching the summary extraction model to these can improve performance. Together, our results suggest that it is important to carefully consider user models in policy summarization.
An Evaluation of the Human-Interpretability of Explanation
Jan 31, 2019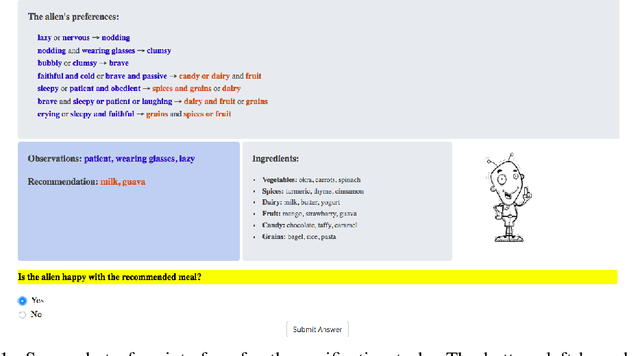
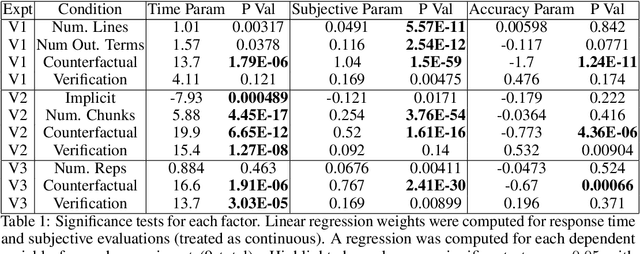
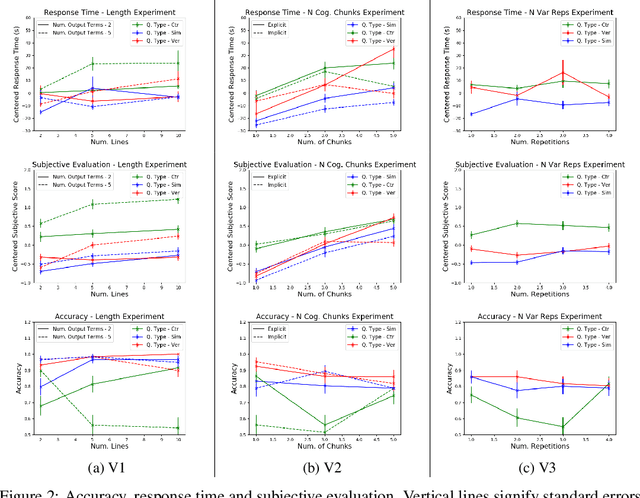
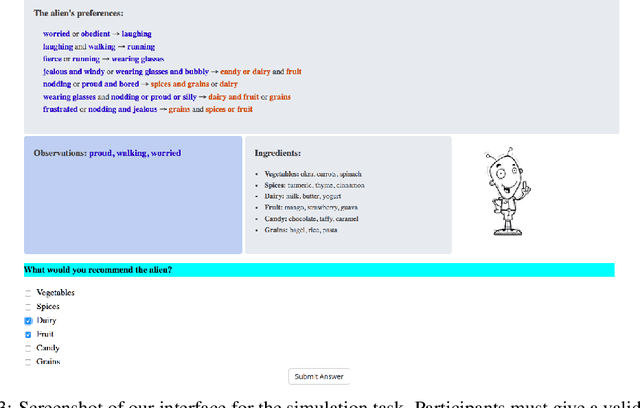
Recent years have seen a boom in interest in machine learning systems that can provide a human-understandable rationale for their predictions or decisions. However, exactly what kinds of explanation are truly human-interpretable remains poorly understood. This work advances our understanding of what makes explanations interpretable under three specific tasks that users may perform with machine learning systems: simulation of the response, verification of a suggested response, and determining whether the correctness of a suggested response changes under a change to the inputs. Through carefully controlled human-subject experiments, we identify regularizers that can be used to optimize for the interpretability of machine learning systems. Our results show that the type of complexity matters: cognitive chunks (newly defined concepts) affect performance more than variable repetitions, and these trends are consistent across tasks and domains. This suggests that there may exist some common design principles for explanation systems.
Human-in-the-Loop Interpretability Prior
Oct 30, 2018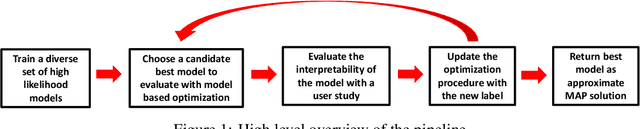
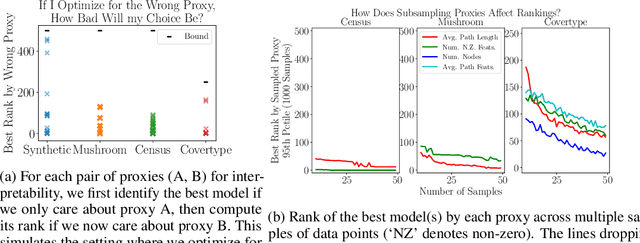
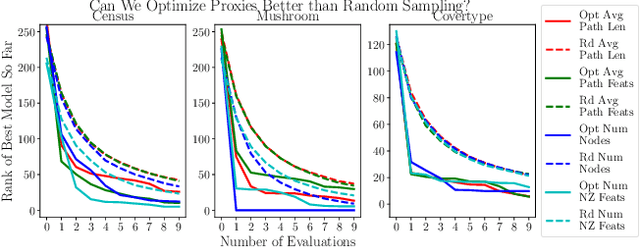
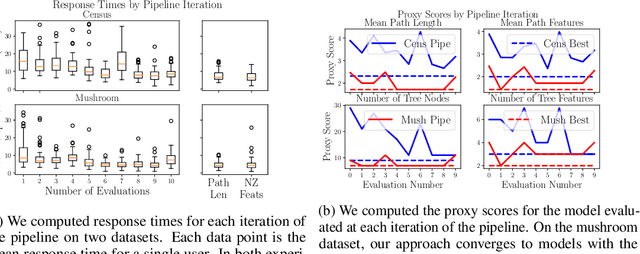
We often desire our models to be interpretable as well as accurate. Prior work on optimizing models for interpretability has relied on easy-to-quantify proxies for interpretability, such as sparsity or the number of operations required. In this work, we optimize for interpretability by directly including humans in the optimization loop. We develop an algorithm that minimizes the number of user studies to find models that are both predictive and interpretable and demonstrate our approach on several data sets. Our human subjects results show trends towards different proxy notions of interpretability on different datasets, which suggests that different proxies are preferred on different tasks.
Evaluating Reinforcement Learning Algorithms in Observational Health Settings
May 31, 2018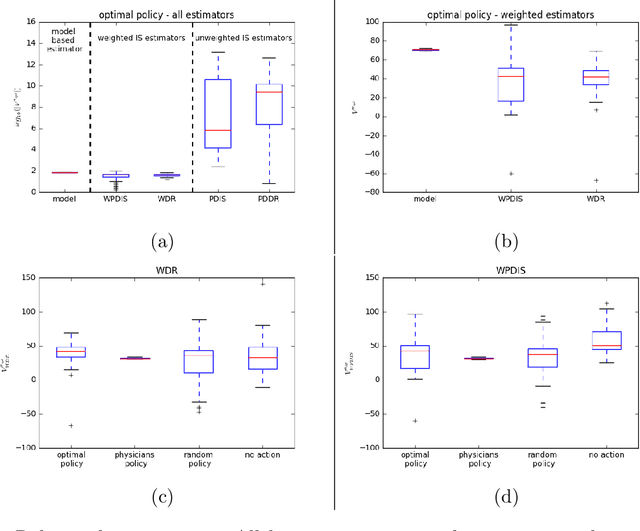
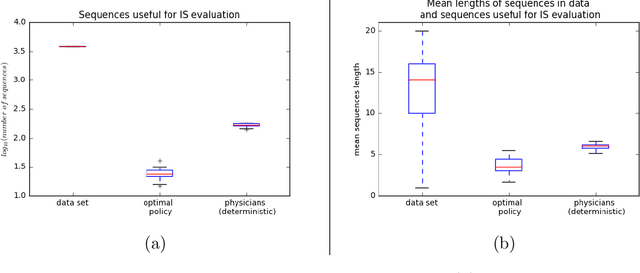
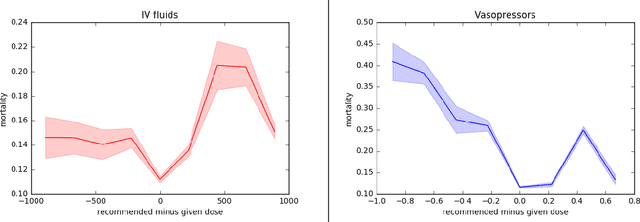
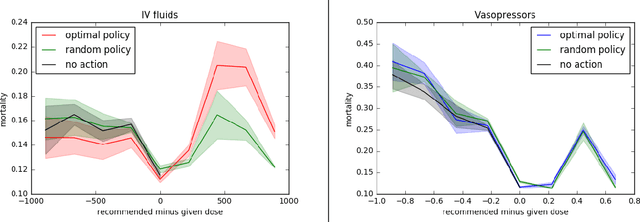
Much attention has been devoted recently to the development of machine learning algorithms with the goal of improving treatment policies in healthcare. Reinforcement learning (RL) is a sub-field within machine learning that is concerned with learning how to make sequences of decisions so as to optimize long-term effects. Already, RL algorithms have been proposed to identify decision-making strategies for mechanical ventilation, sepsis management and treatment of schizophrenia. However, before implementing treatment policies learned by black-box algorithms in high-stakes clinical decision problems, special care must be taken in the evaluation of these policies. In this document, our goal is to expose some of the subtleties associated with evaluating RL algorithms in healthcare. We aim to provide a conceptual starting point for clinical and computational researchers to ask the right questions when designing and evaluating algorithms for new ways of treating patients. In the following, we describe how choices about how to summarize a history, variance of statistical estimators, and confounders in more ad-hoc measures can result in unreliable, even misleading estimates of the quality of a treatment policy. We also provide suggestions for mitigating these effects---for while there is much promise for mining observational health data to uncover better treatment policies, evaluation must be performed thoughtfully.