 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazePrior: Zero-Shot AR/VR Eye Tracking via Learned 3D Gaze Reconstruction
May 21, 2026Eye tracking (ET) is a foundational technology for advanced AR/VR applications. However, training ET models for every new ET device is challenging: real data collection is costly and time-consuming, while existing synthetic data generation methods lack realism. To remove the need for additional data collection while maintaining data quality, we introduce a data-driven 3D prior that models the distribution of human eyes across diverse identities, gaze directions, and light settings. This model, which we coin GazePrior, then enables sparse-input 3D reconstruction of annotated data collected with previous ET devices, which can in turn be rendered from the cameras of any target ET device. Our approach synthesizes data with the realism, diversity and ground-truth accuracy of real data collection without its prohibitive costs. Our experiments demonstrate that ET models trained with our synthesized data outperform previous zero-shot methods, achieving higher accuracy and robustness.
Rapidly deploying on-device eye tracking by distilling visual foundation models
Apr 02, 2026Eye tracking (ET) plays a critical role in augmented and virtual reality applications. However, rapidly deploying high-accuracy, on-device gaze estimation for new products remains challenging because hardware configurations (e.g., camera placement, camera pose, and illumination) often change across device generations. Visual foundation models (VFMs) are a promising direction for rapid training and deployment, and they excel on natural-image benchmarks; yet we find that off-the-shelf VFMs still struggle to achieve high accuracy on specialized near-eye infrared imagery. To address this gap, we introduce DistillGaze, a framework that distills a foundation model by leveraging labeled synthetic data and unlabeled real data for rapid and high-performance on-device gaze estimation. DistillGaze proceeds in two stages. First, we adapt a VFM into a domain-specialized teacher using self-supervised learning on labeled synthetic and unlabeled real images. Synthetic data provides scalable, high-quality gaze supervision, while unlabeled real data helps bridge the synthetic-to-real domain gap. Second, we train an on-device student using both teacher guidance and self-training. Evaluated on a large-scale, crowd-sourced dataset spanning over 2,000 participants, DistillGaze reduces median gaze error by 58.62% relative to synthetic-only baselines while maintaining a lightweight 256K-parameter model suitable for real-time on-device deployment. Overall, DistillGaze provides an efficient pathway for training and deploying ET models that adapt to hardware changes, and offers a recipe for combining synthetic supervision with unlabeled real data in on-device regression tasks.
MonoPlace3D: Learning 3D-Aware Object Placement for 3D Monocular Detection
Apr 10, 2025Current monocular 3D detectors are held back by the limited diversity and scale of real-world datasets. While data augmentation certainly helps, it's particularly difficult to generate realistic scene-aware augmented data for outdoor settings. Most current approaches to synthetic data generation focus on realistic object appearance through improved rendering techniques. However, we show that where and how objects are positioned is just as crucial for training effective 3D monocular detectors. The key obstacle lies in automatically determining realistic object placement parameters - including position, dimensions, and directional alignment when introducing synthetic objects into actual scenes. To address this, we introduce MonoPlace3D, a novel system that considers the 3D scene content to create realistic augmentations. Specifically, given a background scene, MonoPlace3D learns a distribution over plausible 3D bounding boxes. Subsequently, we render realistic objects and place them according to the locations sampled from the learned distribution. Our comprehensive evaluation on two standard datasets KITTI and NuScenes, demonstrates that MonoPlace3D significantly improves the accuracy of multiple existing monocular 3D detectors while being highly data efficient.
Digitally Prototype Your Eye Tracker: Simulating Hardware Performance using 3D Synthetic Data
Mar 20, 2025



Eye tracking (ET) is a key enabler for Augmented and Virtual Reality (AR/VR). Prototyping new ET hardware requires assessing the impact of hardware choices on eye tracking performance. This task is compounded by the high cost of obtaining data from sufficiently many variations of real hardware, especially for machine learning, which requires large training datasets. We propose a method for end-to-end evaluation of how hardware changes impact machine learning-based ET performance using only synthetic data. We utilize a dataset of real 3D eyes, reconstructed from light dome data using neural radiance fields (NeRF), to synthesize captured eyes from novel viewpoints and camera parameters. Using this framework, we demonstrate that we can predict the relative performance across various hardware configurations, accounting for variations in sensor noise, illumination brightness, and optical blur. We also compare our simulator with the publicly available eye tracking dataset from the Project Aria glasses, demonstrating a strong correlation with real-world performance. Finally, we present a first-of-its-kind analysis in which we vary ET camera positions, evaluating ET performance ranging from on-axis direct views of the eye to peripheral views on the frame. Such an analysis would have previously required manufacturing physical devices to capture evaluation data. In short, our method enables faster prototyping of ET hardware.
Enabling My Robot To Play Pictionary : Recurrent Neural Networks For Sketch Recognition
Aug 11, 2016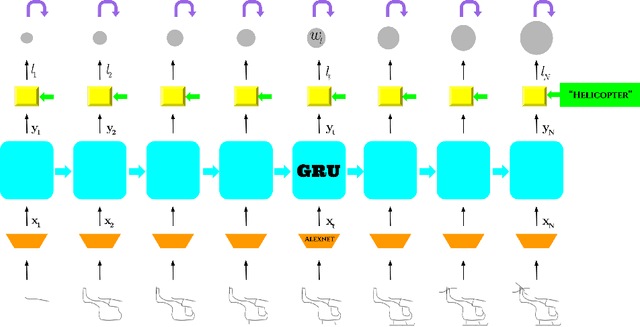

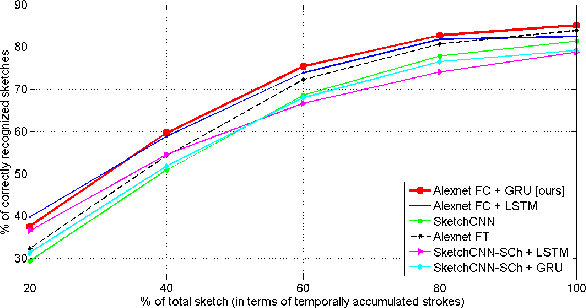
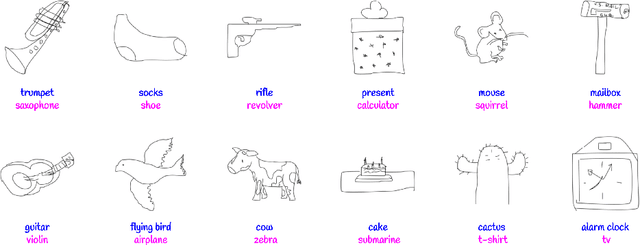
Freehand sketching is an inherently sequential process. Yet, most approaches for hand-drawn sketch recognition either ignore this sequential aspect or exploit it in an ad-hoc manner. In our work, we propose a recurrent neural network architecture for sketch object recognition which exploits the long-term sequential and structural regularities in stroke data in a scalable manner. Specifically, we introduce a Gated Recurrent Unit based framework which leverages deep sketch features and weighted per-timestep loss to achieve state-of-the-art results on a large database of freehand object sketches across a large number of object categories. The inherently online nature of our framework is especially suited for on-the-fly recognition of objects as they are being drawn. Thus, our framework can enable interesting applications such as camera-equipped robots playing the popular party game Pictionary with human players and generating sparsified yet recognizable sketches of objects.