 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Singer: Fast Multi-Singer Singing Voice Vocoder With A Large-Scale Corpus
Dec 20, 2021
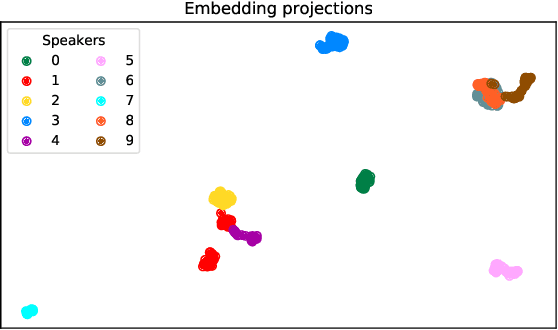
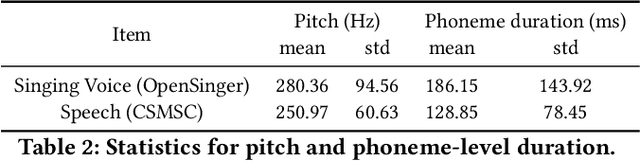
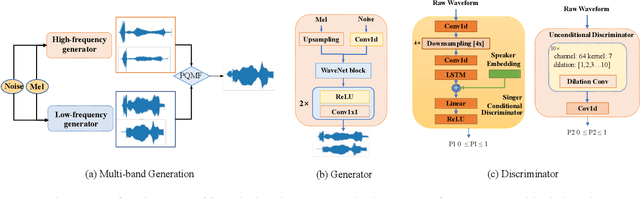
High-fidelity multi-singer singing voice synthesis is challenging for neural vocoder due to the singing voice data shortage, limited singer generalization, and large computational cost. Existing open corpora could not meet requirements for high-fidelity singing voice synthesis because of the scale and quality weaknesses. Previous vocoders have difficulty in multi-singer modeling, and a distinct degradation emerges when conducting unseen singer singing voice generation. To accelerate singing voice researches in the community, we release a large-scale, multi-singer Chinese singing voice dataset OpenSinger. To tackle the difficulty in unseen singer modeling, we propose Multi-Singer, a fast multi-singer vocoder with generative adversarial networks. Specifically, 1) Multi-Singer uses a multi-band generator to speed up both training and inference procedure. 2) to capture and rebuild singer identity from the acoustic feature (i.e., mel-spectrogram), Multi-Singer adopts a singer conditional discriminator and conditional adversarial training objective. 3) to supervise the reconstruction of singer identity in the spectrum envelopes in frequency domain, we propose an auxiliary singer perceptual loss. The joint training approach effectively works in GANs for multi-singer voices modeling. Experimental results verify the effectiveness of OpenSinger and show that Multi-Singer improves unseen singer singing voices modeling in both speed and quality over previous methods. The further experiment proves that combined with FastSpeech 2 as the acoustic model, Multi-Singer achieves strong robustness in the multi-singer singing voice synthesis pipeline. Samples are available at https://Multi-Singer.github.io/
SingGAN: Generative Adversarial Network For High-Fidelity Singing Voice Generation
Oct 26, 2021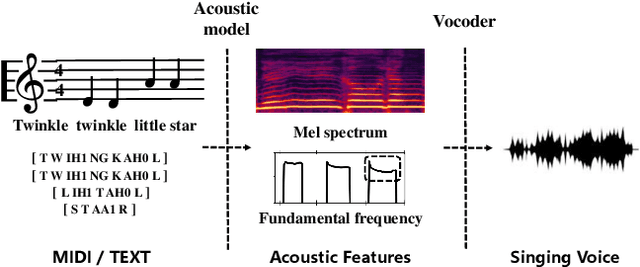
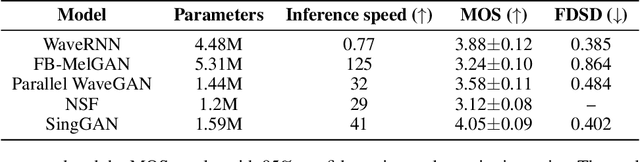
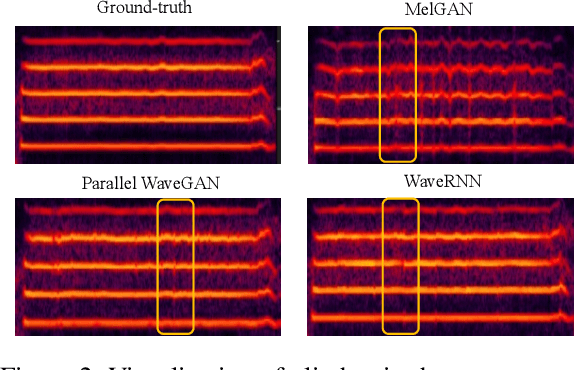

High-fidelity singing voice synthesis is challenging for neural vocoders due to extremely long continuous pronunciation, high sampling rate and strong expressiveness. Existing neural vocoders designed for text-to-speech cannot directly be applied to singing voice synthesis because they result in glitches in the generated spectrogram and poor high-frequency reconstruction. To tackle the difficulty of singing modeling, in this paper, we propose SingGAN, a singing voice vocoder with generative adversarial network. Specifically, 1) SingGAN uses source excitation to alleviate the glitch problem in the spectrogram; and 2) SingGAN adopts multi-band discriminators and introduces frequency-domain loss and sub-band feature matching loss to supervise high-frequency reconstruction. To our knowledge, SingGAN is the first vocoder designed towards high-fidelity multi-speaker singing voice synthesis. Experimental results show that SingGAN synthesizes singing voices with much higher quality (0.41 MOS gains) over the previous method. Further experiments show that combined with FastSpeech~2 as an acoustic model, SingGAN achieves high robustness in the singing voice synthesis pipeline and also performs well in speech synthesis.
EMOVIE: A Mandarin Emotion Speech Dataset with a Simple Emotional Text-to-Speech Model
Jun 17, 2021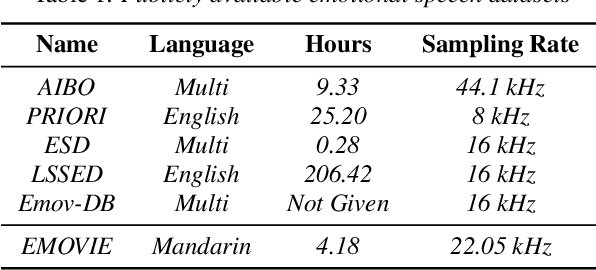
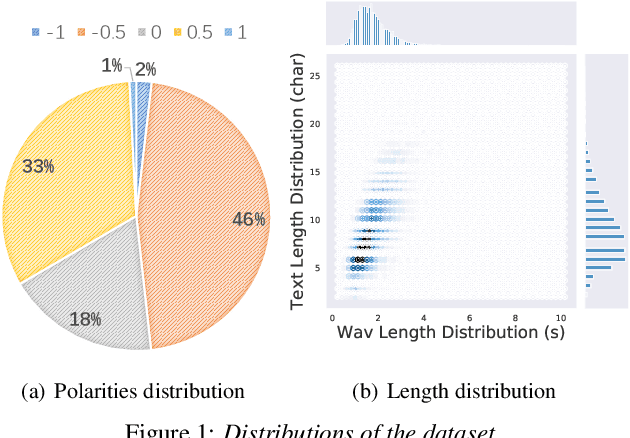

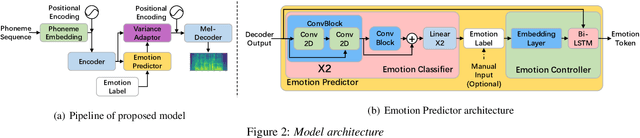
Recently, there has been an increasing interest in neural speech synthesis. While the deep neural network achieves the state-of-the-art result in text-to-speech (TTS) tasks, how to generate a more emotional and more expressive speech is becoming a new challenge to researchers due to the scarcity of high-quality emotion speech dataset and the lack of advanced emotional TTS model. In this paper, we first briefly introduce and publicly release a Mandarin emotion speech dataset including 9,724 samples with audio files and its emotion human-labeled annotation. After that, we propose a simple but efficient architecture for emotional speech synthesis called EMSpeech. Unlike those models which need additional reference audio as input, our model could predict emotion labels just from the input text and generate more expressive speech conditioned on the emotion embedding. In the experiment phase, we first validate the effectiveness of our dataset by an emotion classification task. Then we train our model on the proposed dataset and conduct a series of subjective evaluations. Finally, by showing a comparable performance in the emotional speech synthesis task, we successfully demonstrate the ability of the proposed model.
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
May 30, 2021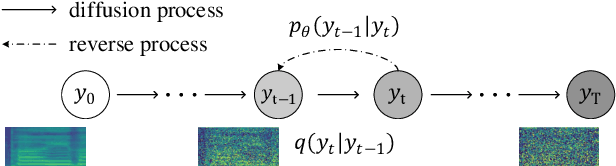
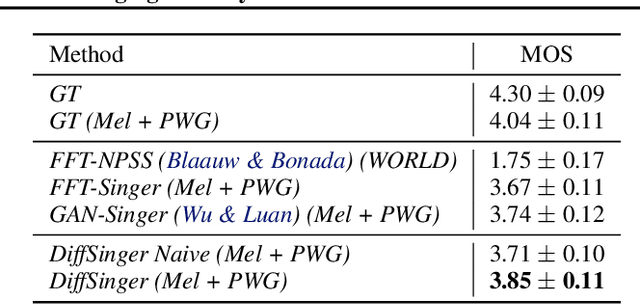
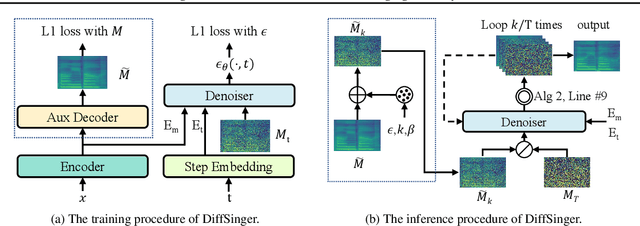
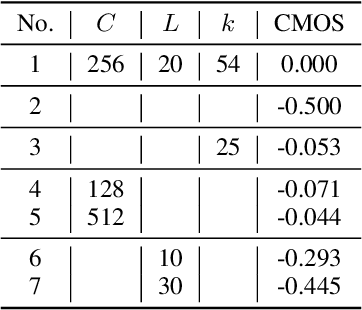
Singing voice synthesis (SVS) system is built to synthesize high-quality and expressive singing voice, in which the acoustic model generates the acoustic features (e.g., mel-spectrogram) given a music score. Previous singing acoustic models adopt simple loss (e.g., L1 and L2) or generative adversarial network (GAN) to reconstruct the acoustic features, while they suffer from over-smoothing and unstable training issues respectively, which hinder the naturalness of synthesized singing. In this work, we propose DiffSinger, an acoustic model for SVS based on the diffusion probabilistic model. DiffSinger is a parameterized Markov chain which iteratively converts the noise into mel-spectrogram conditioned on the music score. By implicitly optimizing variational bound, DiffSinger can be stably trained and generates realistic outputs. To further improve the voice quality and speed up inference, we introduce a shallow diffusion mechanism to make better use of the prior knowledge learned by the simple loss. Specifically, DiffSinger starts generation at a shallow step smaller than the total number of diffusion steps, according to the intersection of the diffusion trajectories of the ground-truth mel-spectrogram and the one predicted by a simple mel-spectrogram decoder. Besides, we train a boundary prediction network to locate the intersection and determine the shallow step adaptively. The evaluations conducted on the Chinese singing dataset demonstrate that DiffSinger outperforms state-of-the-art SVS work. Our extensional experiments also prove the generalization of DiffSinger on text-to-speech task.
BridgeDPI: A Novel Graph Neural Network for Predicting Drug-Protein Interactions
Jan 29, 2021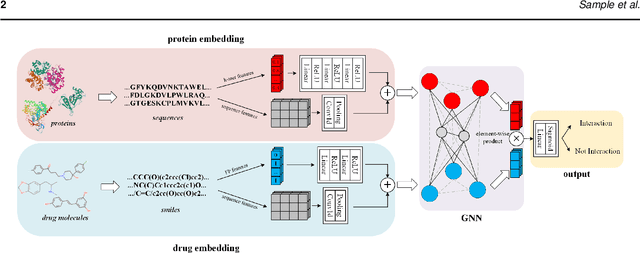
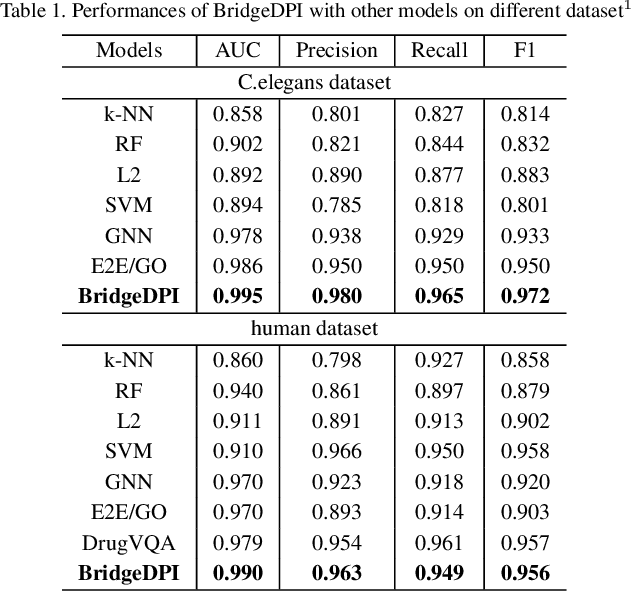
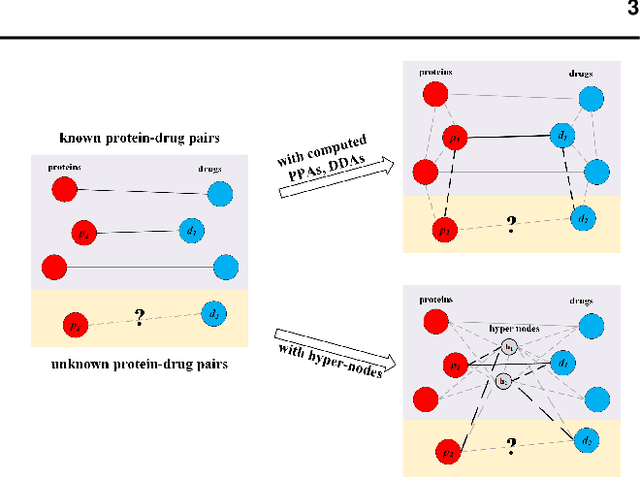
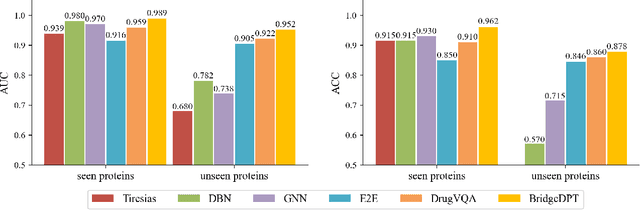
Motivation: Exploring drug-protein interactions (DPIs) work as a pivotal step in drug discovery. The fast expansion of available biological data enables computational methods effectively assist in experimental methods. Among them, deep learning methods extract features only from basic characteristics, such as protein sequences, molecule structures. Others achieve significant improvement by learning from not only sequences/molecules but the protein-protein and drug-drug associations (PPAs and DDAs). The PPAs and DDAs are generally obtained by using computational methods. However, existing computational methods have some limitations, resulting in low-quality PPAs and DDAs that hamper the prediction performance. Therefore, we hope to develop a novel supervised learning method to learn the PPAs and DDAs effectively and thereby improve the prediction performance of the specific task of DPI. Results: In this research, we propose a novel deep learning framework, namely BridgeDPI. BridgeDPI introduces a class of nodes named hyper-nodes, which bridge different proteins/drugs to work as PPAs and DDAs. The hyper-nodes can be supervised learned for the specific task of DPI since the whole process is an end-to-end learning. Consequently, such a model would improve prediction performance of DPI. In three real-world datasets, we further demonstrate that BridgeDPI outperforms state-of-the-art methods. Moreover, ablation studies verify the effectiveness of the hyper-nodes. Last, in an independent verification, BridgeDPI explores the candidate bindings among COVID-19's proteins and various antiviral drugs. And the predictive results accord with the statement of the World Health Organization and Food and Drug Administration, showing the validity and reliability of BridgeDPI.
Sentiment Analysis using Deep Robust Complementary Fusion of Multi-Features and Multi-Modalities
Apr 25, 2019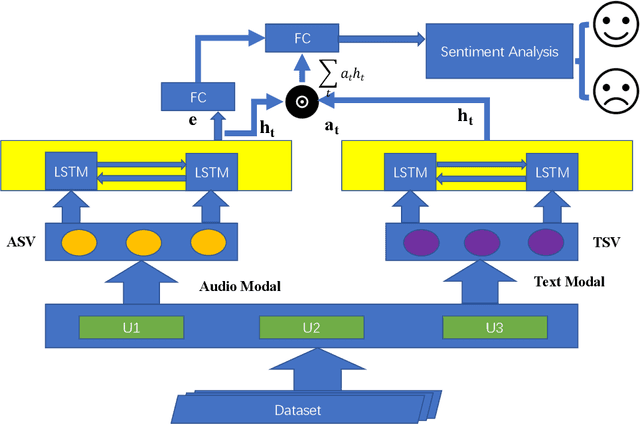

Sentiment analysis research has been rapidly developing in the last decade and has attracted widespread attention from academia and industry, most of which is based on text. However, the information in the real world usually comes as different modalities. In this paper, we consider the task of Multimodal Sentiment Analysis, using Audio and Text Modalities, proposed a novel fusion strategy including Multi-Feature Fusion and Multi-Modality Fusion to improve the accuracy of Audio-Text Sentiment Analysis. We call this the Deep Feature Fusion-Audio and Text Modal Fusion (DFF-ATMF) model, and the features learned from it are complementary to each other and robust. Experiments with the CMU-MOSI corpus and the recently released CMU-MOSEI corpus for Youtube video sentiment analysis show the very competitive results of our proposed model. Surprisingly, our method also achieved the state-of-the-art results in the IEMOCAP dataset, indicating that our proposed fusion strategy is also extremely generalization ability to Multimodal Emotion Recognition.
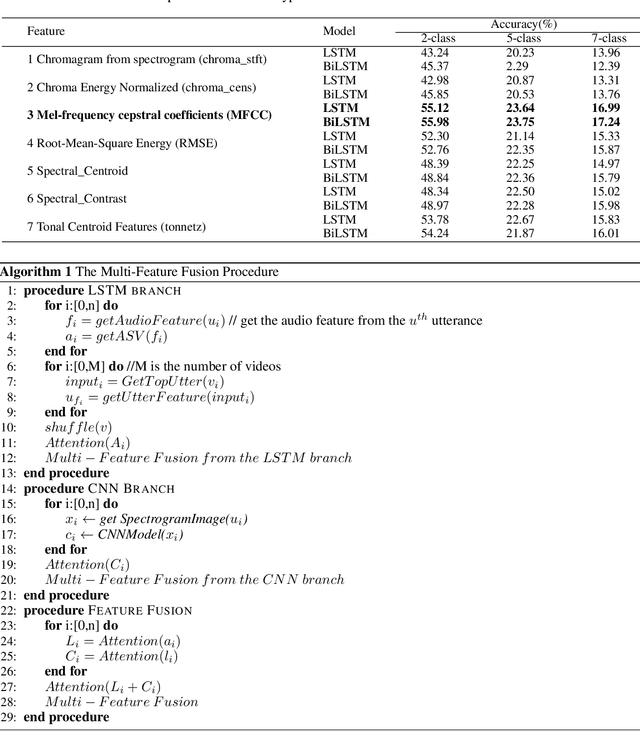
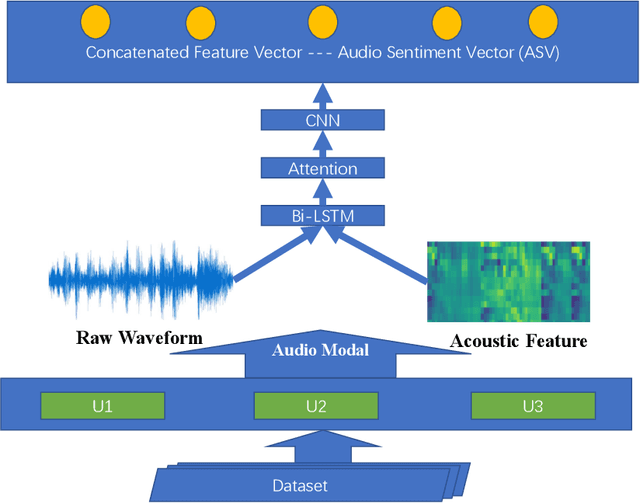
Utterance-Based Audio Sentiment Analysis Learned by a Parallel Combination of CNN and LSTM
Nov 20, 2018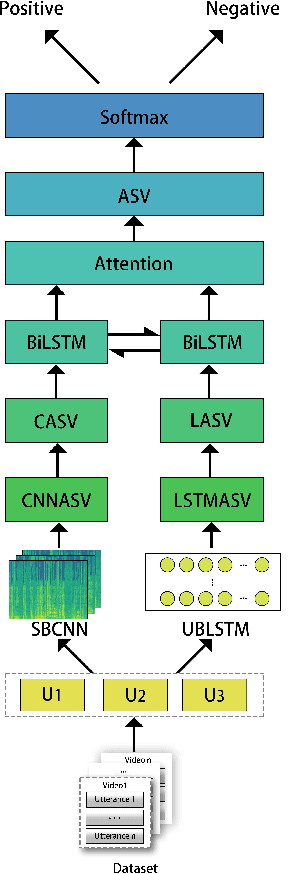

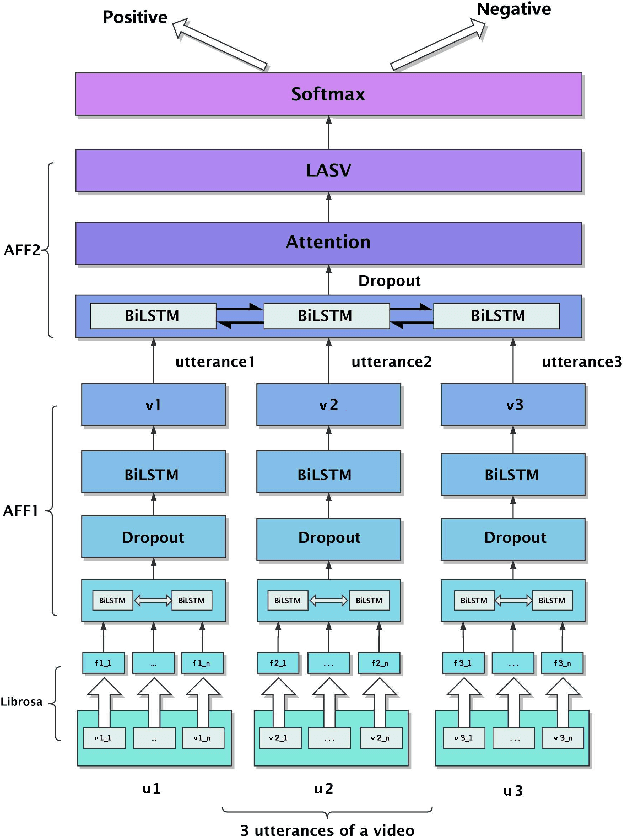
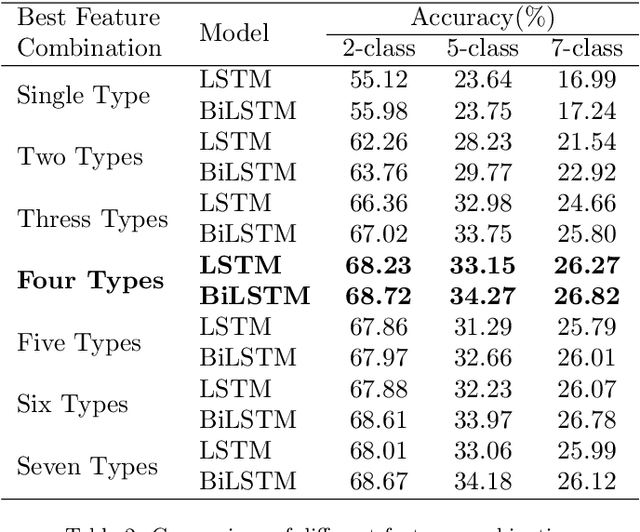
Audio Sentiment Analysis is a popular research area which extends the conventional text-based sentiment analysis to depend on the effectiveness of acoustic features extracted from speech. However, current progress on audio sentiment analysis mainly focuses on extracting homogeneous acoustic features or doesn't fuse heterogeneous features effectively. In this paper, we propose an utterance-based deep neural network model, which has a parallel combination of Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) based network, to obtain representative features termed Audio Sentiment Vector (ASV), that can maximally reflect sentiment information in an audio. Specifically, our model is trained by utterance-level labels and ASV can be extracted and fused creatively from two branches. In the CNN model branch, spectrum graphs produced by signals are fed as inputs while in the LSTM model branch, inputs include spectral features and cepstrum coefficient extracted from dependent utterances in an audio. Besides, Bidirectional Long Short-Term Memory (BiLSTM) with attention mechanism is used for feature fusion. Extensive experiments have been conducted to show our model can recognize audio sentiment precisely and quickly, and demonstrate our ASV are better than traditional acoustic features or vectors extracted from other deep learning models. Furthermore, experimental results indicate that the proposed model outperforms the state-of-the-art approach by 9.33% on Multimodal Opinion-level Sentiment Intensity dataset (MOSI) dataset.
Assessing four Neural Networks on Handwritten Digit Recognition Dataset (MNIST)
Nov 16, 2018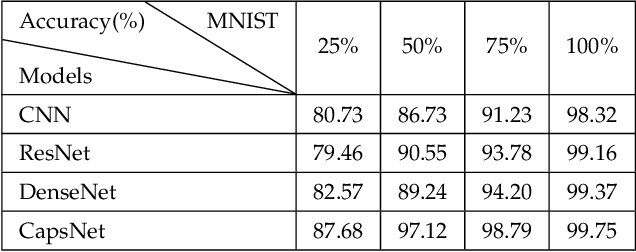
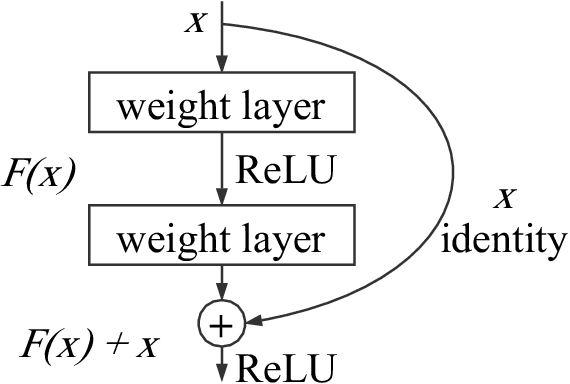
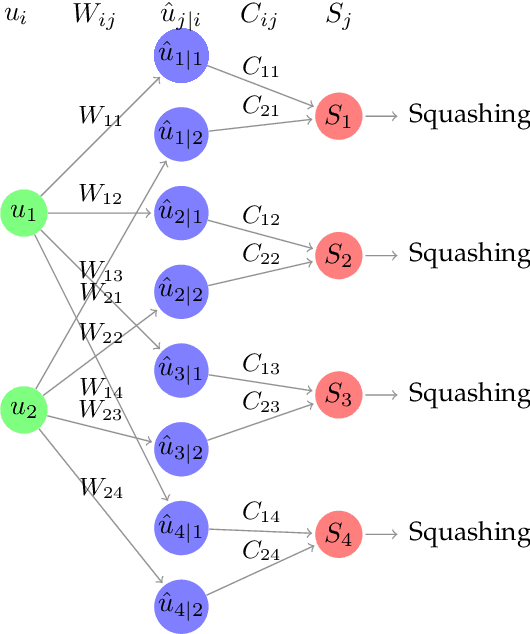
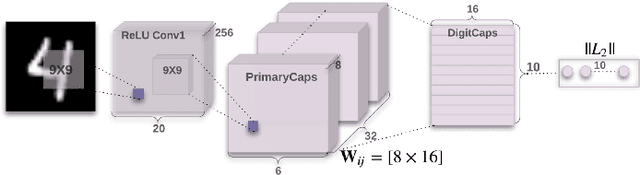
Although the image recognition has been a research topic for many years, many researchers still have a keen interest in it. In some papers, however, there is a tendency to compare models only on one or two datasets, either because of time restraints or because the model is tailored to a specific task. Accordingly, it is hard to understand how well a certain model generalizes across image recognition field. In this paper, we compare four neural networks on MNIST dataset with different division. Among of them, three are Convolutional Neural Networks (CNN), Deep Residual Network (ResNet) and Dense Convolutional Network (DenseNet) respectively, and the other is our improvement on CNN baseline through introducing Capsule Network (CapsNet) to image recognition area. We show that the previous models despite do a quite good job in this area, our retrofitting can be applied to get a better performance. The result obtained by CapsNet is an accuracy rate of 99.75\%, and it is the best result published so far. Another inspiring result is that CapsNet only needs a small amount of data to get the excellent performance. Finally, we will apply CapsNet's ability to generalize in other image recognition field in the future.