 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Thought Textual Reasoning for Few-shot Temporal Action Localization
Apr 18, 2025



Traditional temporal action localization (TAL) methods rely on large amounts of detailed annotated data, whereas few-shot TAL reduces this dependence by using only a few training samples to identify unseen action categories. However, existing few-shot TAL methods typically focus solely on video-level information, neglecting textual information, which can provide valuable semantic support for the localization task. Therefore, we propose a new few-shot temporal action localization method by Chain-of-Thought textual reasoning to improve localization performance. Specifically, we design a novel few-shot learning framework that leverages textual semantic information to enhance the model's ability to capture action commonalities and variations, which includes a semantic-aware text-visual alignment module designed to align the query and support videos at different levels. Meanwhile, to better express the temporal dependencies and causal relationships between actions at the textual level to assist action localization, we design a Chain of Thought (CoT)-like reasoning method that progressively guides the Vision Language Model (VLM) and Large Language Model (LLM) to generate CoT-like text descriptions for videos. The generated texts can capture more variance of action than visual features. We conduct extensive experiments on the publicly available ActivityNet1.3 and THUMOS14 datasets. We introduce the first dataset named Human-related Anomaly Localization and explore the application of the TAL task in human anomaly detection. The experimental results demonstrate that our proposed method significantly outperforms existing methods in single-instance and multi-instance scenarios. We will release our code, data and benchmark.
A New Teacher-Reviewer-Student Framework for Semi-supervised 2D Human Pose Estimation
Jan 16, 2025



Conventional 2D human pose estimation methods typically require extensive labeled annotations, which are both labor-intensive and expensive. In contrast, semi-supervised 2D human pose estimation can alleviate the above problems by leveraging a large amount of unlabeled data along with a small portion of labeled data. Existing semi-supervised 2D human pose estimation methods update the network through backpropagation, ignoring crucial historical information from the previous training process. Therefore, we propose a novel semi-supervised 2D human pose estimation method by utilizing a newly designed Teacher-Reviewer-Student framework. Specifically, we first mimic the phenomenon that human beings constantly review previous knowledge for consolidation to design our framework, in which the teacher predicts results to guide the student's learning and the reviewer stores important historical parameters to provide additional supervision signals. Secondly, we introduce a Multi-level Feature Learning strategy, which utilizes the outputs from different stages of the backbone to estimate the heatmap to guide network training, enriching the supervisory information while effectively capturing keypoint relationships. Finally, we design a data augmentation strategy, i.e., Keypoint-Mix, to perturb pose information by mixing different keypoints, thus enhancing the network's ability to discern keypoints. Extensive experiments on publicly available datasets, demonstrate our method achieves significant improvements compared to the existing methods.
Semi-Supervised Teacher-Reference-Student Architecture for Action Quality Assessment
Jul 29, 2024



Existing action quality assessment (AQA) methods often require a large number of label annotations for fully supervised learning, which are laborious and expensive. In practice, the labeled data are difficult to obtain because the AQA annotation process requires domain-specific expertise. In this paper, we propose a novel semi-supervised method, which can be utilized for better assessment of the AQA task by exploiting a large amount of unlabeled data and a small portion of labeled data. Differing from the traditional teacher-student network, we propose a teacher-reference-student architecture to learn both unlabeled and labeled data, where the teacher network and the reference network are used to generate pseudo-labels for unlabeled data to supervise the student network. Specifically, the teacher predicts pseudo-labels by capturing high-level features of unlabeled data. The reference network provides adequate supervision of the student network by referring to additional action information. Moreover, we introduce confidence memory to improve the reliability of pseudo-labels by storing the most accurate ever output of the teacher network and reference network. To validate our method, we conduct extensive experiments on three AQA benchmark datasets. Experimental results show that our method achieves significant improvements and outperforms existing semi-supervised AQA methods.
Weakly-Supervised Temporal Action Localization by Inferring Snippet-Feature Affinity
Mar 22, 2023



Weakly-supervised temporal action localization aims to locate action regions and identify action categories in untrimmed videos, only taking video-level labels as the supervised information. Pseudo label generation is a promising strategy to solve the challenging problem, but most existing methods are limited to employing snippet-wise classification results to guide the generation, and they ignore that the natural temporal structure of the video can also provide rich information to assist such a generation process. In this paper, we propose a novel weakly-supervised temporal action localization method by inferring snippet-feature affinity. First, we design an affinity inference module that exploits the affinity relationship between temporal neighbor snippets to generate initial coarse pseudo labels. Then, we introduce an information interaction module that refines the coarse labels by enhancing the discriminative nature of snippet-features through exploring intra- and inter-video relationships. Finally, the high-fidelity pseudo labels generated from the information interaction module are used to supervise the training of the action localization network. Extensive experiments on two publicly available datasets, i.e., THUMOS14 and ActivityNet v1.3, demonstrate our proposed method achieves significant improvements compared to the state-of-the-art methods.
Coarse-to-Fine Video Denoising with Dual-Stage Spatial-Channel Transformer
Apr 30, 2022
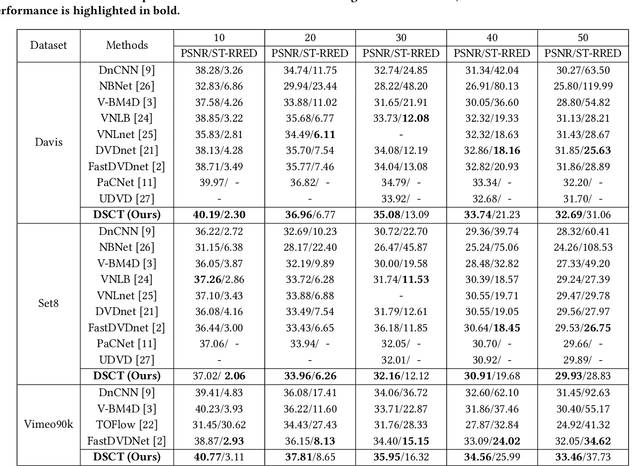
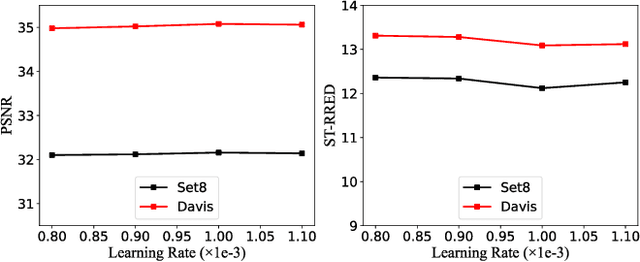
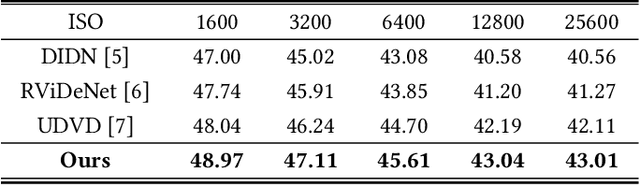
Video denoising aims to recover high-quality frames from the noisy video. While most existing approaches adopt convolutional neural networks(CNNs) to separate the noise from the original visual content, however, CNNs focus on local information and ignore the interactions between long-range regions. Furthermore, most related works directly take the output after spatio-temporal denoising as the final result, neglecting the fine-grained denoising process. In this paper, we propose a Dual-stage Spatial-Channel Transformer (DSCT) for coarse-to-fine video denoising, which inherits the advantages of both Transformer and CNNs. Specifically, DSCT is proposed based on a progressive dual-stage architecture, namely a coarse-level and a fine-level to extract dynamic feature and static feature, respectively. At both stages, a Spatial-Channel Encoding Module(SCEM) is designed to model the long-range contextual dependencies at spatial and channel levels. Meanwhile, we design a Multi-scale Residual Structure to preserve multiple aspects of information at different stages, which contains a Temporal Features Aggregation Module(TFAM) to summarize the dynamic representation. Extensive experiments on four publicly available datasets demonstrate our proposed DSCT achieves significant improvements compared to the state-of-the-art methods.