 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Grasp Ability Enhancement through Deep Shape Generation
Jun 19, 2022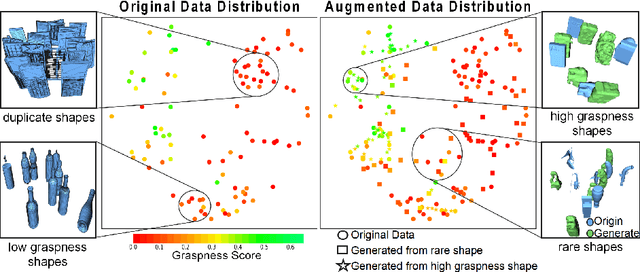
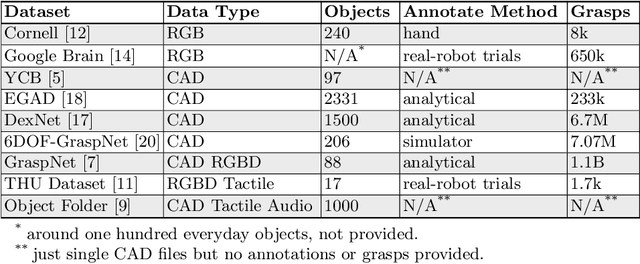
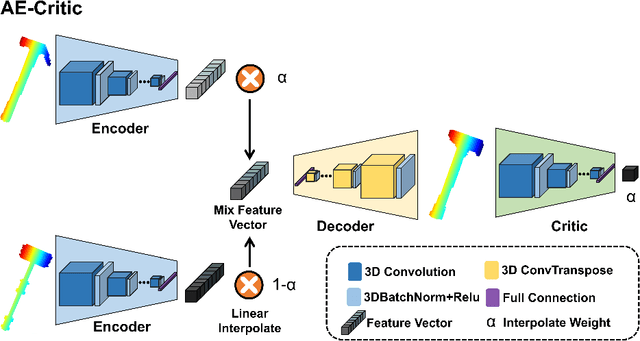
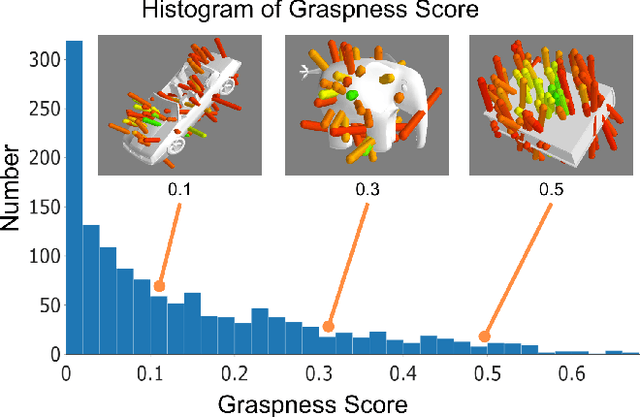
Data-driven especially deep learning-based approaches have become a dominant paradigm for robotic grasp planning during the past decade. However, the performance of these methods is greatly influenced by the quality of the training dataset available. In this paper, we propose a framework to generate object shapes to augment the grasping dataset and thus can improve the grasp ability of a pre-designed deep neural network. First, the object shapes are embedded into a low dimensional feature space using an encoder-decoder structure network. Then, the rarity and graspness scores are computed for each object shape using outlier detection and grasp quality criteria. Finally, new objects are generated in feature space leveraging the original high rarity and graspness score objects' feature. Experimental results show that the grasp ability of a deep-learning-based grasp planning network can be effectively improved with the generated object shapes.
Manifold Graph Signal Restoration using Gradient Graph Laplacian Regularizer
Jun 09, 2022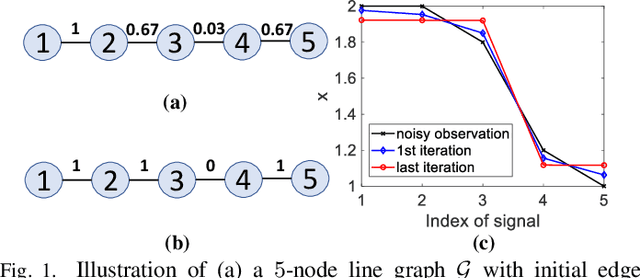
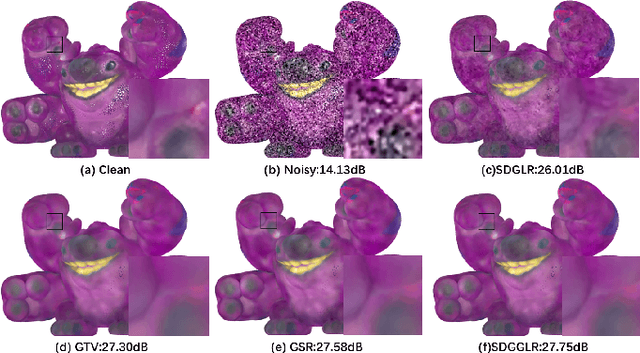
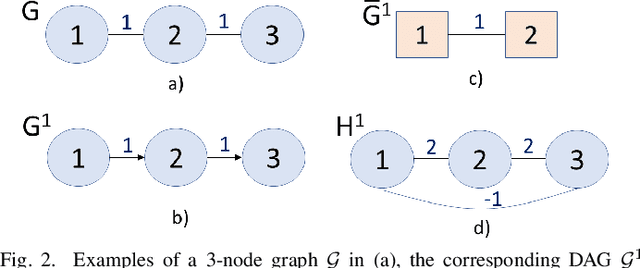
In the graph signal processing (GSP) literature, graph Laplacian regularizer (GLR) was used for signal restoration to promote smooth reconstructions with respect to the underlying graph -- typically signals that are (piecewise) constant. However, for graph signals that are (piecewise) planar, GLR may suffer from the well-known "staircase" effect. In this paper, focusing on manifold graphs -- sets of uniform discrete samples on low-dimensional continuous manifolds -- we generalize GLR to gradient graph Laplacian regularizer (GGLR) that provably promotes piecewise planar (PWP) signal reconstruction. Specifically, for a graph endowed with latent space coordinates (e.g., 2D images, 3D point clouds), we first define a gradient operator, using which we construct a higher-order gradient graph for the computed gradients in each latent dimension. This maps to a gradient-induced nodal graph (GNG) and a Laplacian matrix for a signed graph that is provably positive semi-definite (PSD), thus suitable for quadratic regularization. For manifold graphs without explicit latent coordinates, we propose a fast parameter-free spectral method to first compute latent space coordinates for graph nodes based on generalized eigenvectors. We derive the means-square-error minimizing weight parameter for GGLR efficiently, trading off bias and variance of the signal estimate. Experimental results show that GGLR outperformed previous graph signal priors like GLR and graph total variation (GTV) in a range of graph signal restoration tasks.
XBound-Former: Toward Cross-scale Boundary Modeling in Transformers
Jun 02, 2022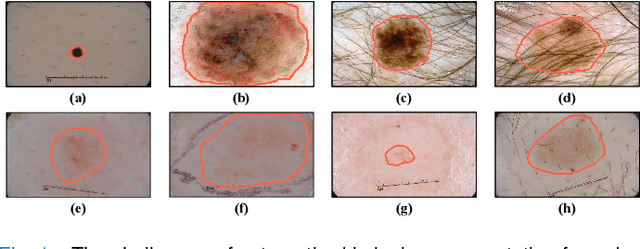
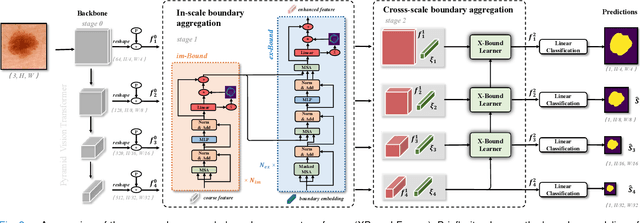
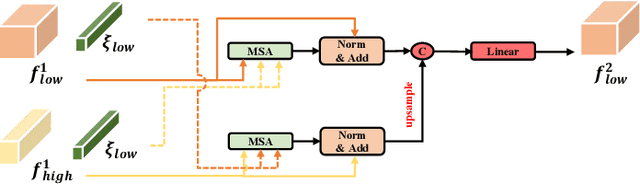
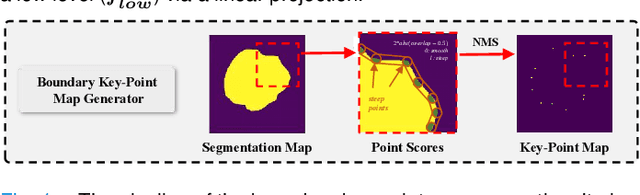
Skin lesion segmentation from dermoscopy images is of great significance in the quantitative analysis of skin cancers, which is yet challenging even for dermatologists due to the inherent issues, i.e., considerable size, shape and color variation, and ambiguous boundaries. Recent vision transformers have shown promising performance in handling the variation through global context modeling. Still, they have not thoroughly solved the problem of ambiguous boundaries as they ignore the complementary usage of the boundary knowledge and global contexts. In this paper, we propose a novel cross-scale boundary-aware transformer, \textbf{XBound-Former}, to simultaneously address the variation and boundary problems of skin lesion segmentation. XBound-Former is a purely attention-based network and catches boundary knowledge via three specially designed learners. We evaluate the model on two skin lesion datasets, ISIC-2016\&PH$^2$ and ISIC-2018, where our model consistently outperforms other convolution- and transformer-based models, especially on the boundary-wise metrics. We extensively verify the generalization ability of polyp lesion segmentation that has similar characteristics, and our model can also yield significant improvement compared to the latest models.
Robot Cooking with Stir-fry: Bimanual Non-prehensile Manipulation of Semi-fluid Objects
May 12, 2022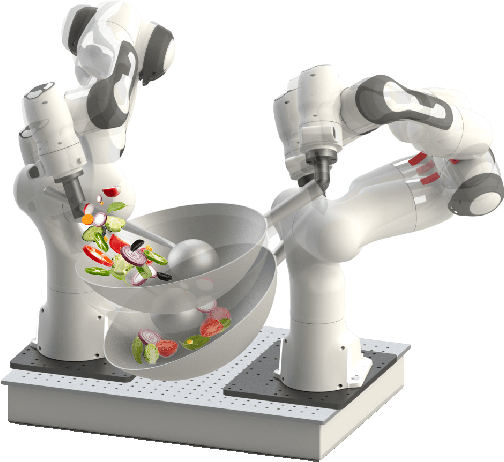
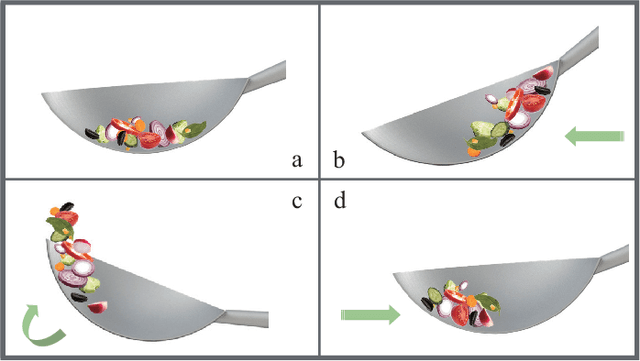
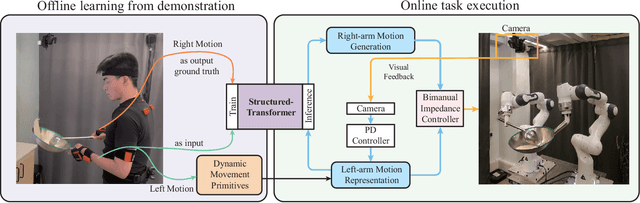
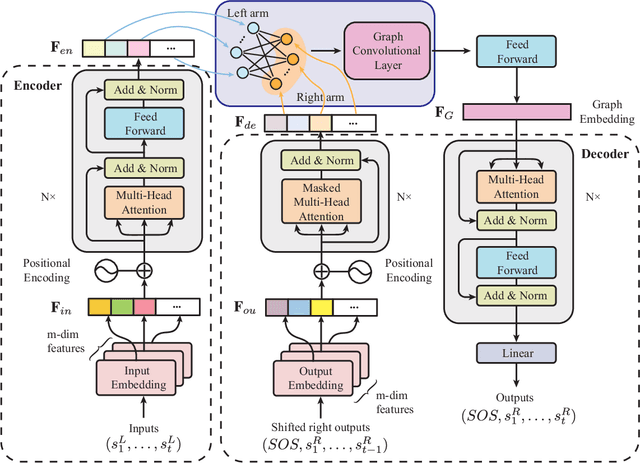
This letter describes an approach to achieve well-known Chinese cooking art stir-fry on a bimanual robot system. Stir-fry requires a sequence of highly dynamic coordinated movements, which is usually difficult to learn for a chef, let alone transfer to robots. In this letter, we define a canonical stir-fry movement, and then propose a decoupled framework for learning this deformable object manipulation from human demonstration. First, the dual arms of the robot are decoupled into different roles (a leader and follower) and learned with classical and neural network-based methods separately, then the bimanual task is transformed into a coordination problem. To obtain general bimanual coordination, we secondly propose a Graph and Transformer based model -- Structured-Transformer, to capture the spatio-temporal relationship between dual-arm movements. Finally, by adding visual feedback of content deformation, our framework can adjust the movements automatically to achieve the desired stir-fry effect. We verify the framework by a simulator and deploy it on a real bimanual Panda robot system. The experimental results validate our framework can realize the bimanual robot stir-fry motion and have the potential to extend to other deformable objects with bimanual coordination.
* 8 pages, 8 figures, published to RA-L
MTI-Net: A Multi-Target Speech Intelligibility Prediction Model
Apr 07, 2022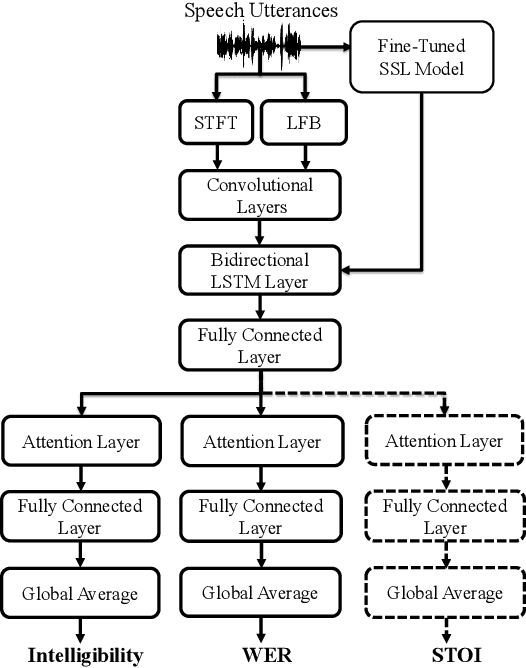
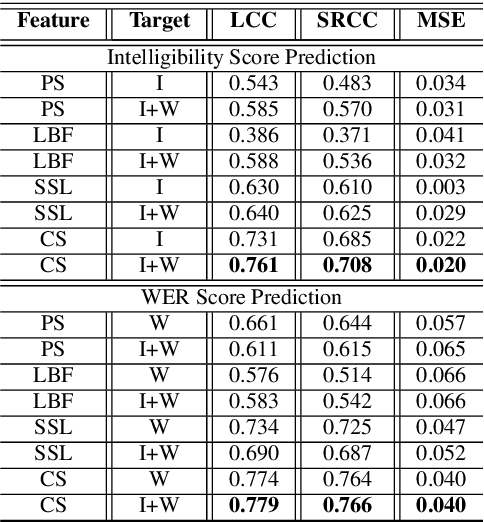
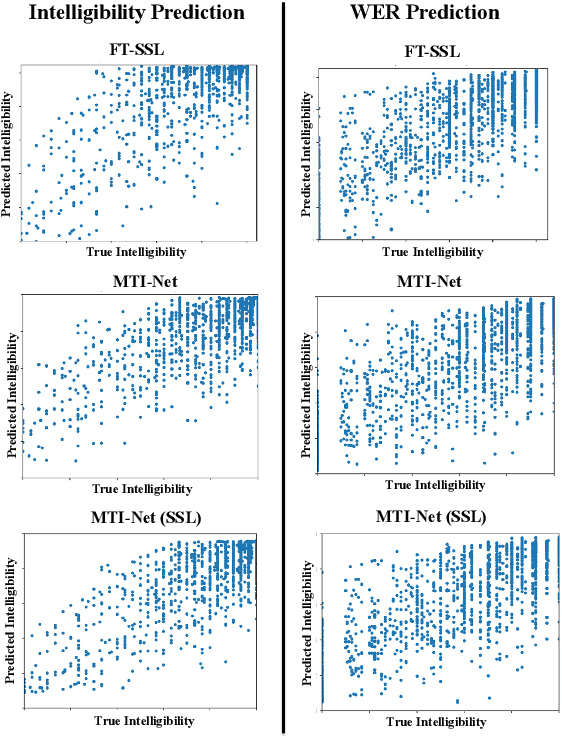
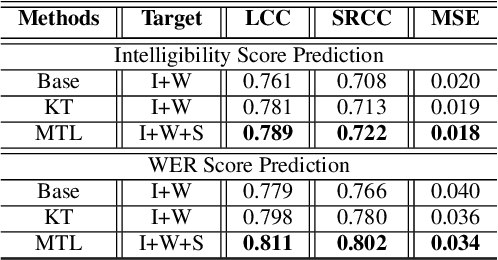
Recently, deep learning (DL)-based non-intrusive speech assessment models have attracted great attention. Many studies report that these DL-based models yield satisfactory assessment performance and good flexibility, but their performance in unseen environments remains a challenge. Furthermore, compared to quality scores, fewer studies elaborate deep learning models to estimate intelligibility scores. This study proposes a multi-task speech intelligibility prediction model, called MTI-Net, for simultaneously predicting human and machine intelligibility measures. Specifically, given a speech utterance, MTI-Net is designed to predict subjective listening test results and word error rate (WER) scores. We also investigate several methods that can improve the prediction performance of MTI-Net. First, we compare different features (including low-level features and embeddings from self-supervised learning (SSL) models) and prediction targets of MTI-Net. Second, we explore the effect of transfer learning and multi-tasking learning on training MTI-Net. Finally, we examine the potential advantages of fine-tuning SSL embeddings. Experimental results demonstrate the effectiveness of using cross-domain features, multi-task learning, and fine-tuning SSL embeddings. Furthermore, it is confirmed that the intelligibility and WER scores predicted by MTI-Net are highly correlated with the ground-truth scores.
MBI-Net: A Non-Intrusive Multi-Branched Speech Intelligibility Prediction Model for Hearing Aids
Apr 07, 2022
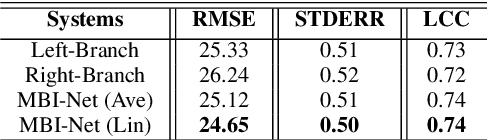
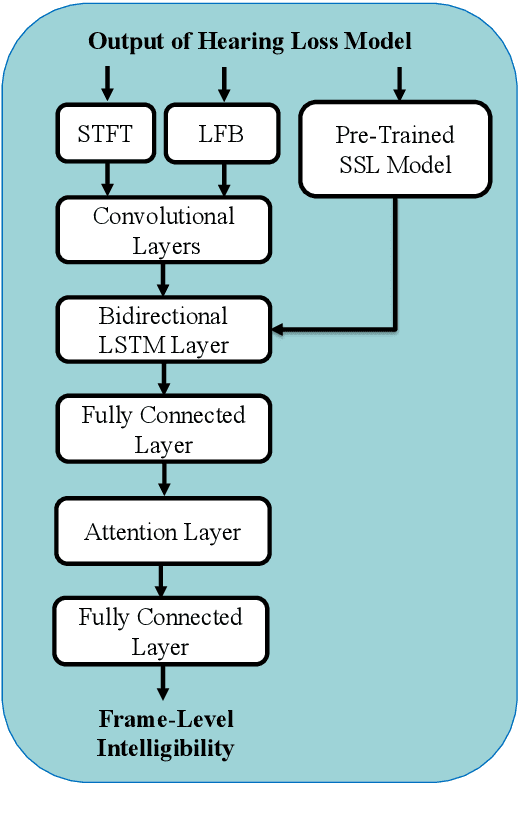
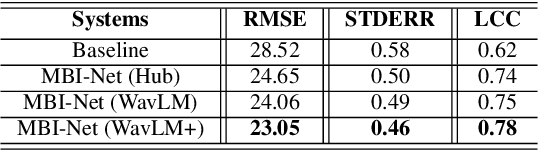
Improving the user's hearing ability to understand speech in noisy environments is critical to the development of hearing aid (HA) devices. For this, it is important to derive a metric that can fairly predict speech intelligibility for HA users. A straightforward approach is to conduct a subjective listening test and use the test results as an evaluation metric. However, conducting large-scale listening tests is time-consuming and expensive. Therefore, several evaluation metrics were derived as surrogates for subjective listening test results. In this study, we propose a multi-branched speech intelligibility prediction model (MBI-Net), for predicting the subjective intelligibility scores of HA users. MBI-Net consists of two branches of models, with each branch consisting of a hearing loss model, a cross-domain feature extraction module, and a speech intelligibility prediction model, to process speech signals from one channel. The outputs of the two branches are fused through a linear layer to obtain predicted speech intelligibility scores. Experimental results confirm the effectiveness of MBI-Net, which produces higher prediction scores than the baseline system in Track 1 and Track 2 on the Clarity Prediction Challenge 2022 dataset.
ConferencingSpeech 2022 Challenge: Non-intrusive Objective Speech Quality Assessment (NISQA) Challenge for Online Conferencing Applications
Apr 01, 2022
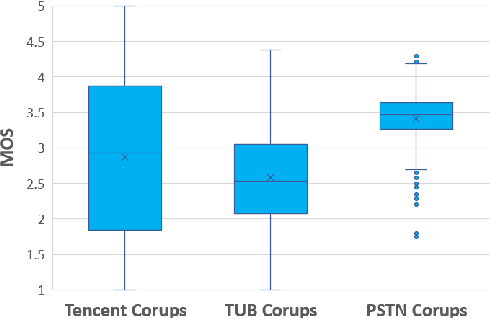

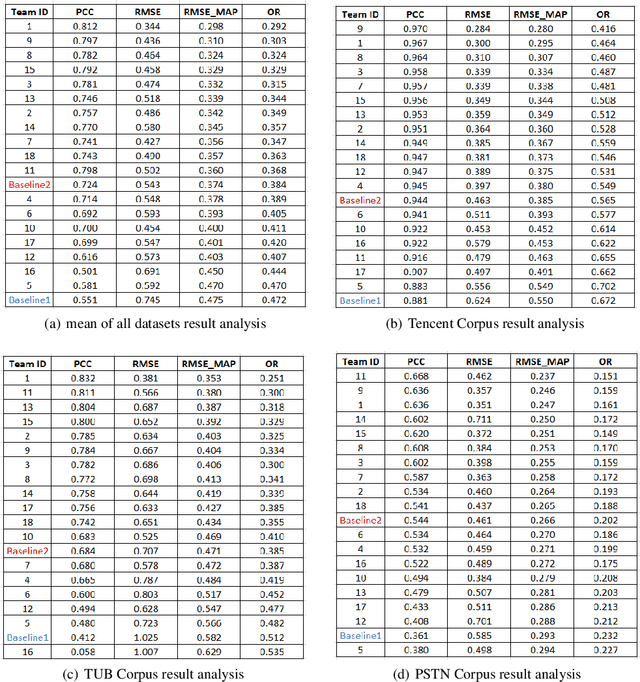
With the advances in speech communication systems such as online conferencing applications, we can seamlessly work with people regardless of where they are. However, during online meetings, speech quality can be significantly affected by background noise, reverberation, packet loss, network jitter, etc. Because of its nature, speech quality is traditionally assessed in subjective tests in laboratories and lately also in crowdsourcing following the international standards from ITU-T Rec. P.800 series. However, those approaches are costly and cannot be applied to customer data. Therefore, an effective objective assessment approach is needed to evaluate or monitor the speech quality of the ongoing conversation. The ConferencingSpeech 2022 challenge targets the non-intrusive deep neural network models for the speech quality assessment task. We open-sourced a training corpus with more than 86K speech clips in different languages, with a wide range of synthesized and live degradations and their corresponding subjective quality scores through crowdsourcing. 18 teams submitted their models for evaluation in this challenge. The blind test sets included about 4300 clips from wide ranges of degradations. This paper describes the challenge, the datasets, and the evaluation methods and reports the final results.
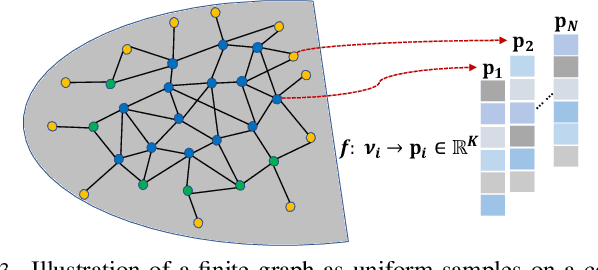
Fast Computation of Generalized Eigenvectors for Manifold Graph Embedding
Dec 15, 2021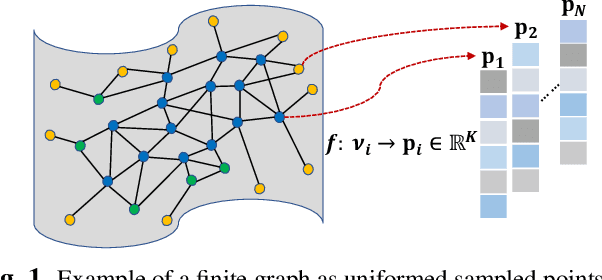

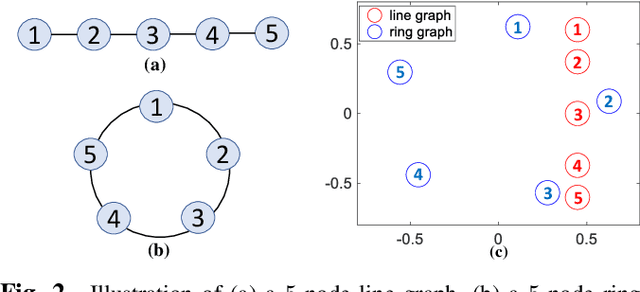
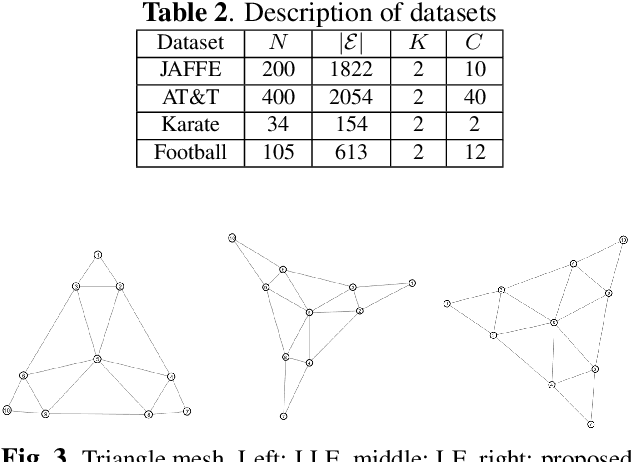
Our goal is to efficiently compute low-dimensional latent coordinates for nodes in an input graph -- known as graph embedding -- for subsequent data processing such as clustering. Focusing on finite graphs that are interpreted as uniformly samples on continuous manifolds (called manifold graphs), we leverage existing fast extreme eigenvector computation algorithms for speedy execution. We first pose a generalized eigenvalue problem for sparse matrix pair $(\A,\B)$, where $\A = \L - \mu \Q + \epsilon \I$ is a sum of graph Laplacian $\L$ and disconnected two-hop difference matrix $\Q$. Eigenvector $\v$ minimizing Rayleigh quotient $\frac{\v^{\top} \A \v}{\v^{\top} \v}$ thus minimizes $1$-hop neighbor distances while maximizing distances between disconnected $2$-hop neighbors, preserving graph structure. Matrix $\B = \text{diag}(\{\b_i\})$ that defines eigenvector orthogonality is then chosen so that boundary / interior nodes in the sampling domain have the same generalized degrees. $K$-dimensional latent vectors for the $N$ graph nodes are the first $K$ generalized eigenvectors for $(\A,\B)$, computed in $\cO(N)$ using LOBPCG, where $K \ll N$. Experiments show that our embedding is among the fastest in the literature, while producing the best clustering performance for manifold graphs.
Deep Learning-based Non-Intrusive Multi-Objective Speech Assessment Model with Cross-Domain Features
Dec 01, 2021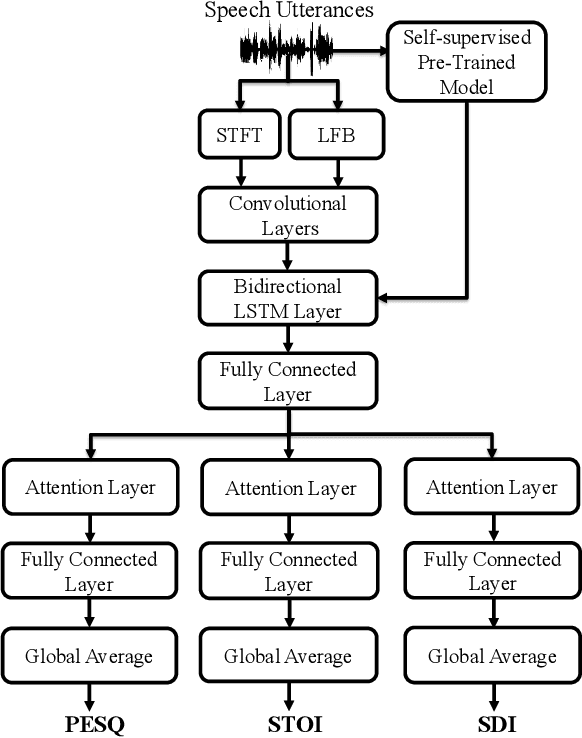
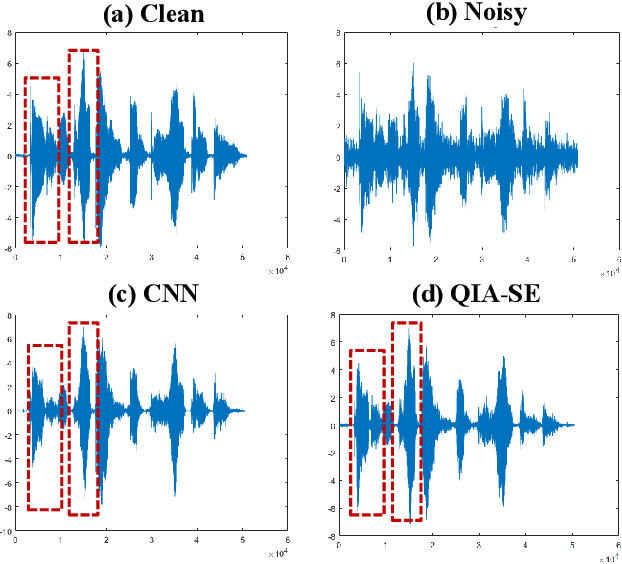
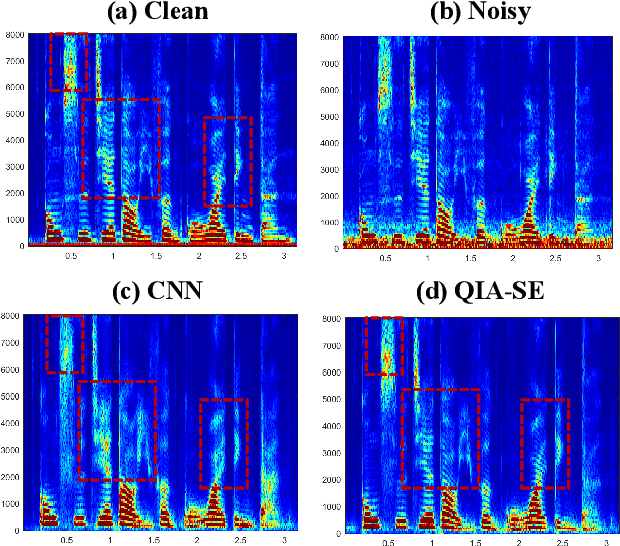
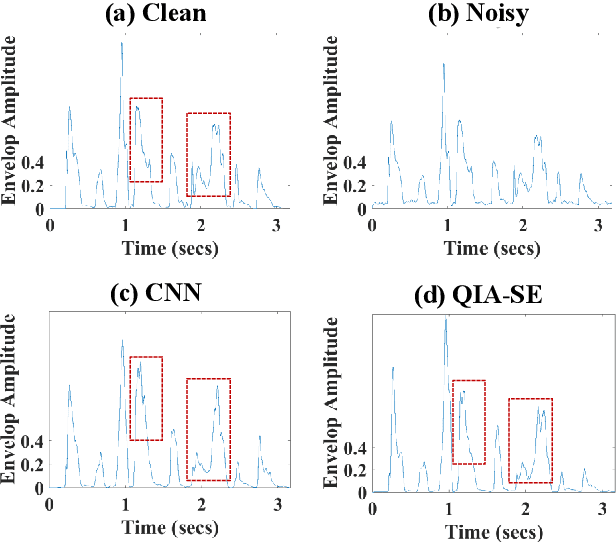
In this study, we propose a cross-domain multi-objective speech assessment model called MOSA-Net, which can estimate multiple speech assessment metrics simultaneously. More specifically, MOSA-Net is designed to estimate the speech quality, intelligibility, and distortion assessment scores of an input test speech signal. It comprises a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture for representation extraction, and a multiplicative attention layer and a fully-connected layer for each assessment metric. In addition, cross-domain features (spectral and time-domain features) and latent representations from self-supervised learned models are used as inputs to combine rich acoustic information from different speech representations to obtain more accurate assessments. Experimental results show that MOSA-Net can precisely predict perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI) scores when tested on noisy and enhanced speech utterances under either seen test conditions or unseen test conditions. Moreover, MOSA-Net, originally trained to assess objective scores, can be used as a pre-trained model to be effectively adapted to an assessment model for predicting subjective quality and intelligibility scores with a limited amount of training data. In light of the confirmed prediction capability, we further adopt the latent representations of MOSA-Net to guide the speech enhancement (SE) process and derive a quality-intelligibility (QI)-aware SE (QIA-SE) approach accordingly. Experimental results show that QIA-SE provides superior enhancement performance compared with the baseline SE system in terms of objective evaluation metrics and qualitative evaluation test.
Learning Robotic Ultrasound Scanning Skills via Human Demonstrations and Guided Explorations
Nov 02, 2021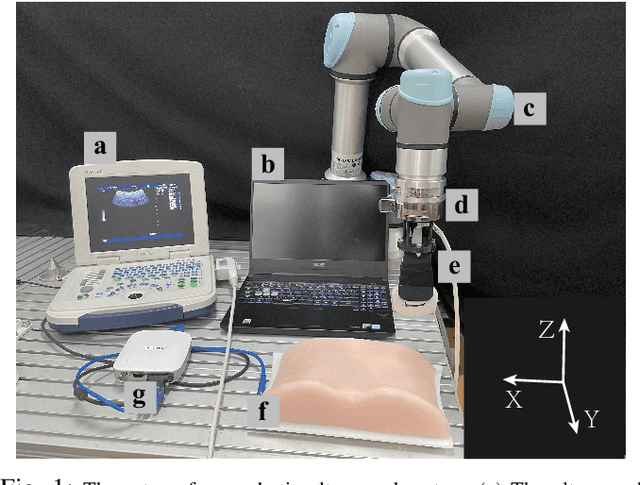
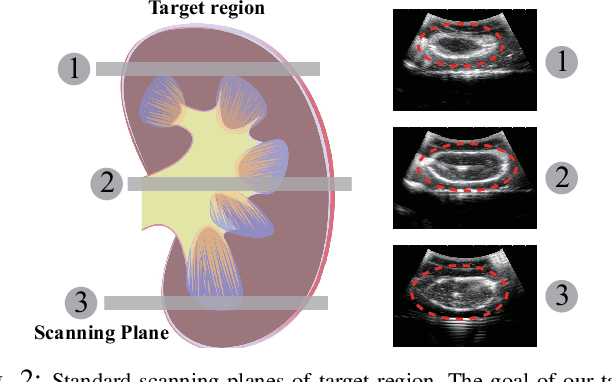
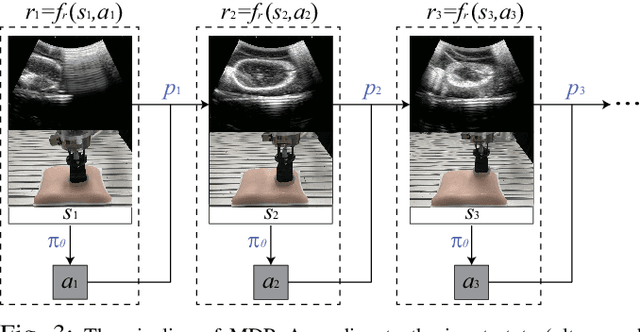
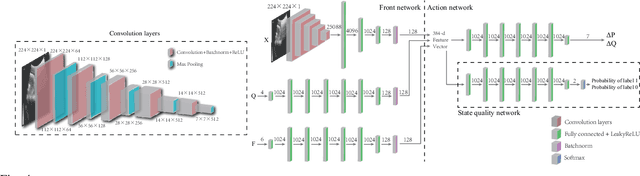
Medical ultrasound has become a routine examination approach nowadays and is widely adopted for different medical applications, so it is desired to have a robotic ultrasound system to perform the ultrasound scanning autonomously. However, the ultrasound scanning skill is considerably complex, which highly depends on the experience of the ultrasound physician. In this paper, we propose a learning-based approach to learn the robotic ultrasound scanning skills from human demonstrations. First, the robotic ultrasound scanning skill is encapsulated into a high-dimensional multi-modal model, which takes the ultrasound images, the pose/position of the probe and the contact force into account. Second, we leverage the power of imitation learning to train the multi-modal model with the training data collected from the demonstrations of experienced ultrasound physicians. Finally, a post-optimization procedure with guided explorations is proposed to further improve the performance of the learned model. Robotic experiments are conducted to validate the advantages of our proposed framework and the learned models.