 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImposing Consistency for Optical Flow Estimation
Apr 14, 2022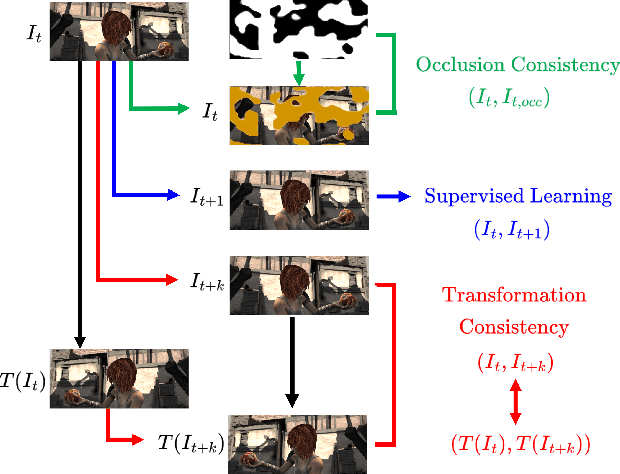
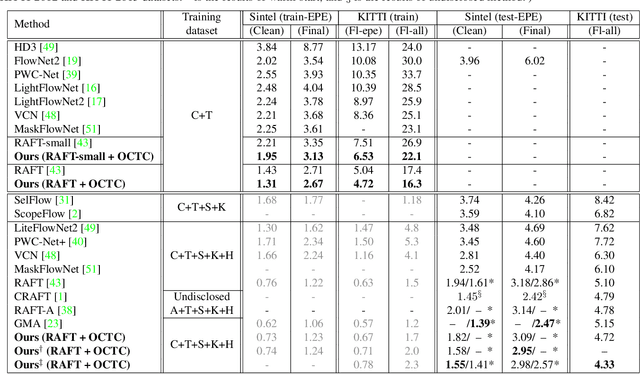

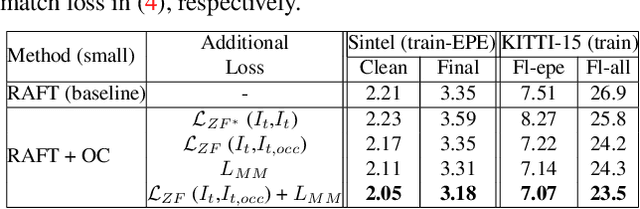
Imposing consistency through proxy tasks has been shown to enhance data-driven learning and enable self-supervision in various tasks. This paper introduces novel and effective consistency strategies for optical flow estimation, a problem where labels from real-world data are very challenging to derive. More specifically, we propose occlusion consistency and zero forcing in the forms of self-supervised learning and transformation consistency in the form of semi-supervised learning. We apply these consistency techniques in a way that the network model learns to describe pixel-level motions better while requiring no additional annotations. We demonstrate that our consistency strategies applied to a strong baseline network model using the original datasets and labels provide further improvements, attaining the state-of-the-art results on the KITTI-2015 scene flow benchmark in the non-stereo category. Our method achieves the best foreground accuracy (4.33% in Fl-all) over both the stereo and non-stereo categories, even though using only monocular image inputs.
Panoptic, Instance and Semantic Relations: A Relational Context Encoder to Enhance Panoptic Segmentation
Apr 11, 2022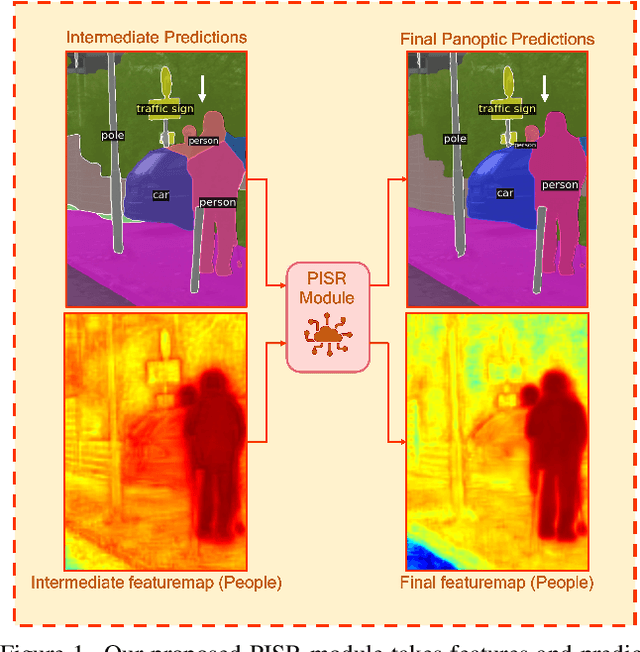
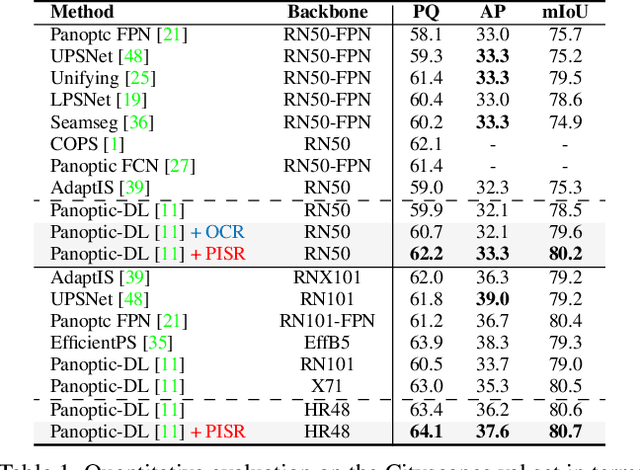
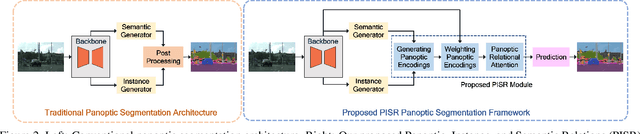
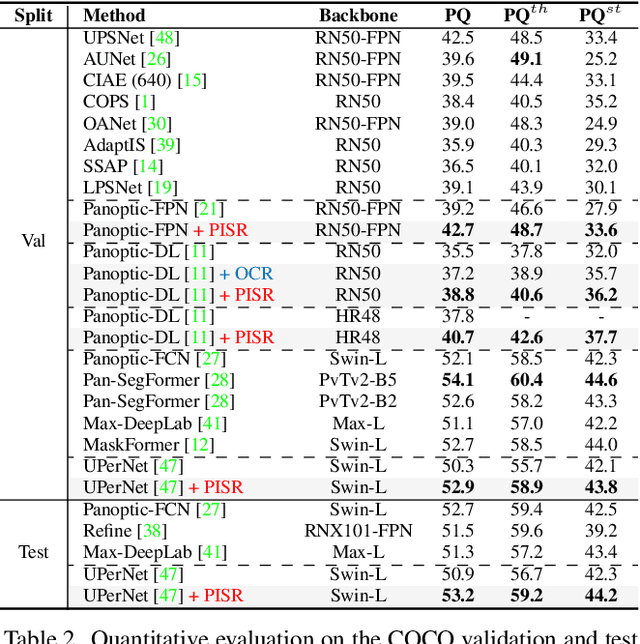
This paper presents a novel framework to integrate both semantic and instance contexts for panoptic segmentation. In existing works, it is common to use a shared backbone to extract features for both things (countable classes such as vehicles) and stuff (uncountable classes such as roads). This, however, fails to capture the rich relations among them, which can be utilized to enhance visual understanding and segmentation performance. To address this shortcoming, we propose a novel Panoptic, Instance, and Semantic Relations (PISR) module to exploit such contexts. First, we generate panoptic encodings to summarize key features of the semantic classes and predicted instances. A Panoptic Relational Attention (PRA) module is then applied to the encodings and the global feature map from the backbone. It produces a feature map that captures 1) the relations across semantic classes and instances and 2) the relations between these panoptic categories and spatial features. PISR also automatically learns to focus on the more important instances, making it robust to the number of instances used in the relational attention module. Moreover, PISR is a general module that can be applied to any existing panoptic segmentation architecture. Through extensive evaluations on panoptic segmentation benchmarks like Cityscapes, COCO, and ADE20K, we show that PISR attains considerable improvements over existing approaches.
SALISA: Saliency-based Input Sampling for Efficient Video Object Detection
Apr 05, 2022
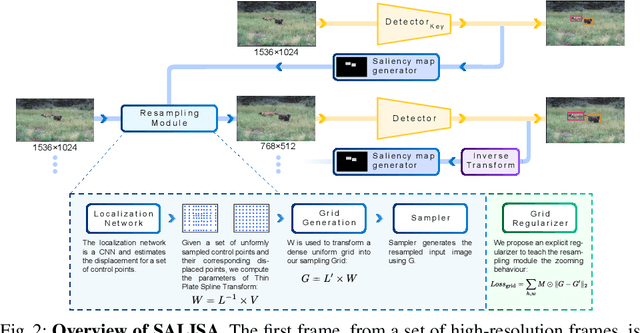
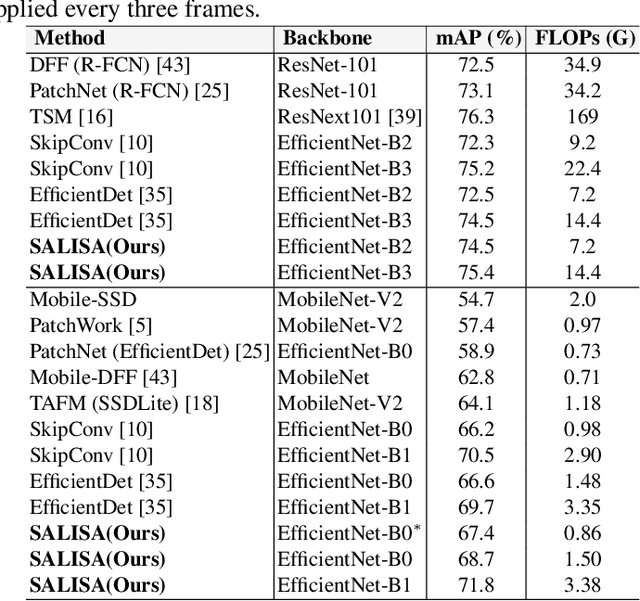

High-resolution images are widely adopted for high-performance object detection in videos. However, processing high-resolution inputs comes with high computation costs, and naive down-sampling of the input to reduce the computation costs quickly degrades the detection performance. In this paper, we propose SALISA, a novel non-uniform SALiency-based Input SAmpling technique for video object detection that allows for heavy down-sampling of unimportant background regions while preserving the fine-grained details of a high-resolution image. The resulting image is spatially smaller, leading to reduced computational costs while enabling a performance comparable to a high-resolution input. To achieve this, we propose a differentiable resampling module based on a thin plate spline spatial transformer network (TPS-STN). This module is regularized by a novel loss to provide an explicit supervision signal to learn to "magnify" salient regions. We report state-of-the-art results in the low compute regime on the ImageNet-VID and UA-DETRAC video object detection datasets. We demonstrate that on both datasets, the mAP of an EfficientDet-D1 (EfficientDet-D2) gets on par with EfficientDet-D2 (EfficientDet-D3) at a much lower computational cost. We also show that SALISA significantly improves the detection of small objects. In particular, SALISA with an EfficientDet-D1 detector improves the detection of small objects by $77\%$, and remarkably also outperforms EfficientDetD3 baseline.
Delta Distillation for Efficient Video Processing
Mar 17, 2022
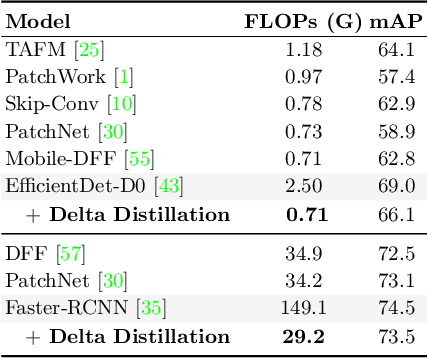

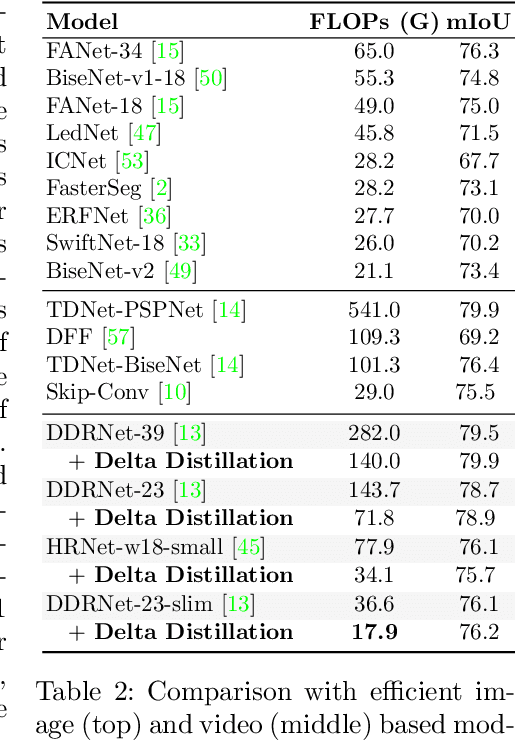
This paper aims to accelerate video stream processing, such as object detection and semantic segmentation, by leveraging the temporal redundancies that exist between video frames. Instead of propagating and warping features using motion alignment, such as optical flow, we propose a novel knowledge distillation schema coined as Delta Distillation. In our proposal, the student learns the variations in the teacher's intermediate features over time. We demonstrate that these temporal variations can be effectively distilled due to the temporal redundancies within video frames. During inference, both teacher and student cooperate for providing predictions: the former by providing initial representations extracted only on the key-frame, and the latter by iteratively estimating and applying deltas for the successive frames. Moreover, we consider various design choices to learn optimal student architectures including an end-to-end learnable architecture search. By extensive experiments on a wide range of architectures, including the most efficient ones, we demonstrate that delta distillation sets a new state of the art in terms of accuracy vs. efficiency trade-off for semantic segmentation and object detection in videos. Finally, we show that, as a by-product, delta distillation improves the temporal consistency of the teacher model.
Consistency and Diversity induced Human Motion Segmentation
Feb 10, 2022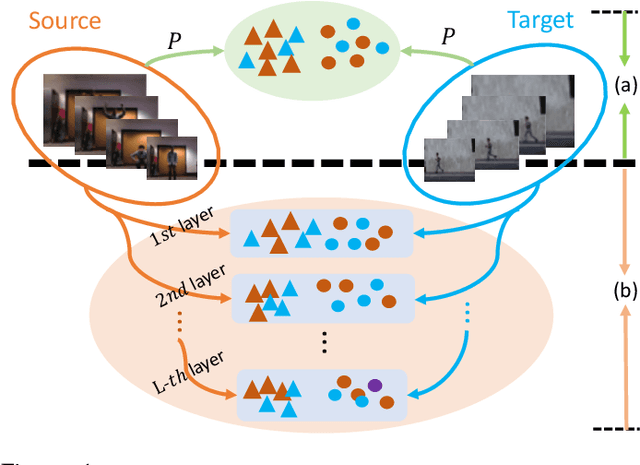

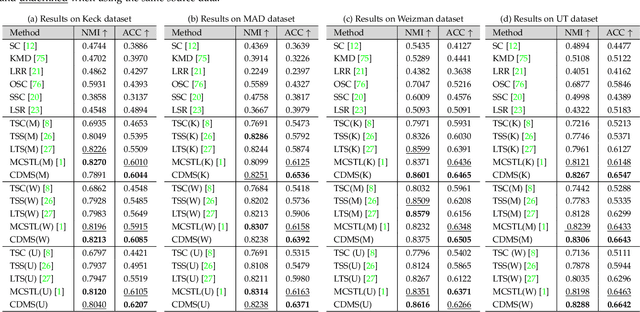
Subspace clustering is a classical technique that has been widely used for human motion segmentation and other related tasks. However, existing segmentation methods often cluster data without guidance from prior knowledge, resulting in unsatisfactory segmentation results. To this end, we propose a novel Consistency and Diversity induced human Motion Segmentation (CDMS) algorithm. Specifically, our model factorizes the source and target data into distinct multi-layer feature spaces, in which transfer subspace learning is conducted on different layers to capture multi-level information. A multi-mutual consistency learning strategy is carried out to reduce the domain gap between the source and target data. In this way, the domain-specific knowledge and domain-invariant properties can be explored simultaneously. Besides, a novel constraint based on the Hilbert Schmidt Independence Criterion (HSIC) is introduced to ensure the diversity of multi-level subspace representations, which enables the complementarity of multi-level representations to be explored to boost the transfer learning performance. Moreover, to preserve the temporal correlations, an enhanced graph regularizer is imposed on the learned representation coefficients and the multi-level representations of the source data. The proposed model can be efficiently solved using the Alternating Direction Method of Multipliers (ADMM) algorithm. Extensive experimental results on public human motion datasets demonstrate the effectiveness of our method against several state-of-the-art approaches.
Distribution Estimation to Automate Transformation Policies for Self-Supervision
Nov 24, 2021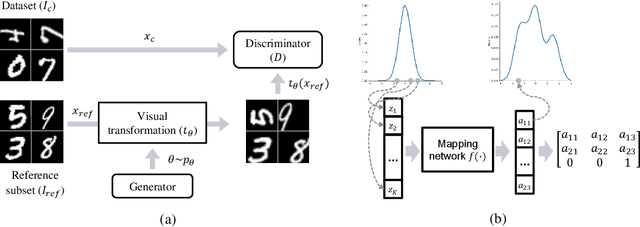
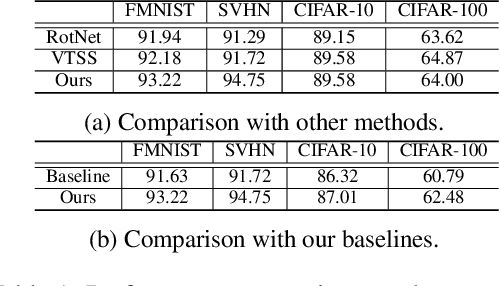
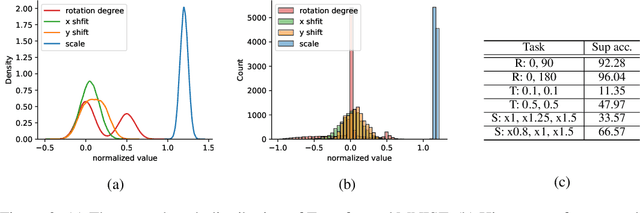
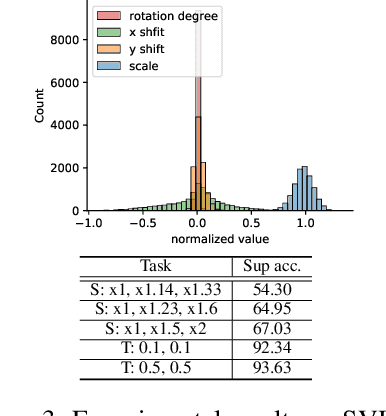
In recent visual self-supervision works, an imitated classification objective, called pretext task, is established by assigning labels to transformed or augmented input images. The goal of pretext can be predicting what transformations are applied to the image. However, it is observed that image transformations already present in the dataset might be less effective in learning such self-supervised representations. Building on this observation, we propose a framework based on generative adversarial network to automatically find the transformations which are not present in the input dataset and thus effective for the self-supervised learning. This automated policy allows to estimate the transformation distribution of a dataset and also construct its complementary distribution from which training pairs are sampled for the pretext task. We evaluated our framework using several visual recognition datasets to show the efficacy of our automated transformation policy.
Dynamic Iterative Refinement for Efficient 3D Hand Pose Estimation
Nov 11, 2021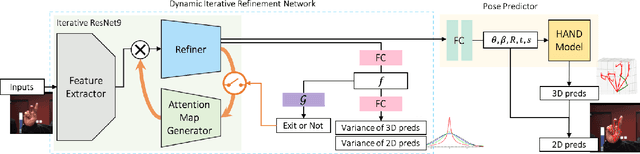
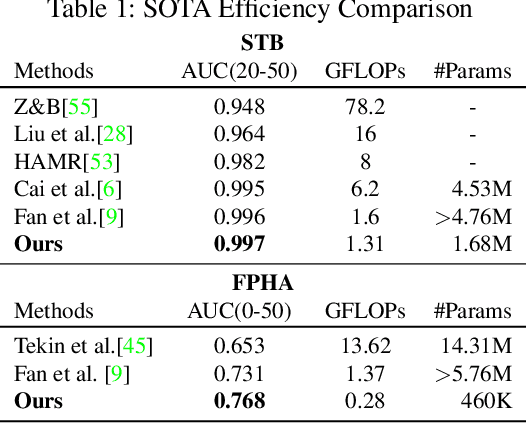
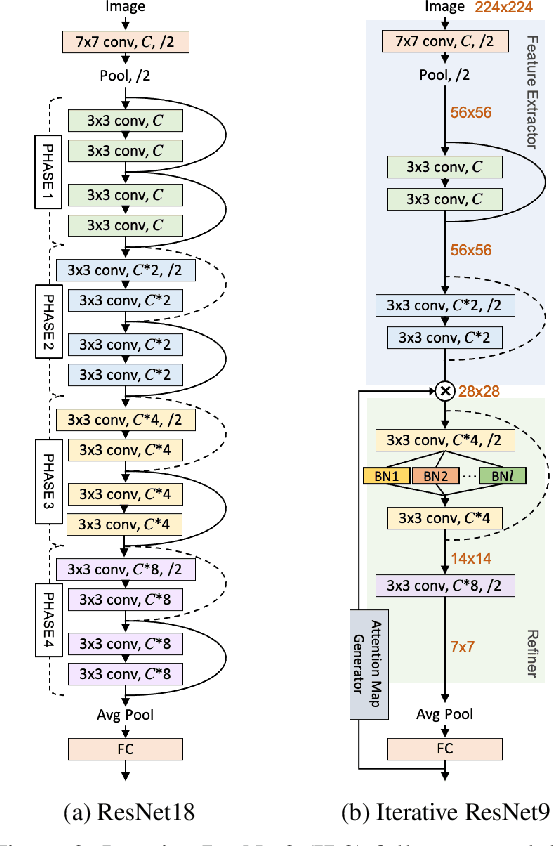
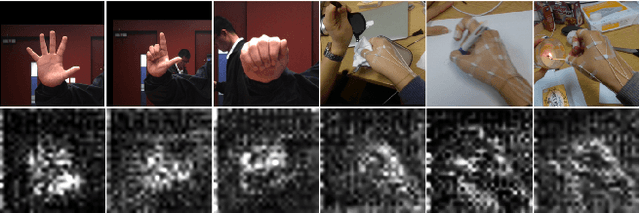
While hand pose estimation is a critical component of most interactive extended reality and gesture recognition systems, contemporary approaches are not optimized for computational and memory efficiency. In this paper, we propose a tiny deep neural network of which partial layers are recursively exploited for refining its previous estimations. During its iterative refinements, we employ learned gating criteria to decide whether to exit from the weight-sharing loop, allowing per-sample adaptation in our model. Our network is trained to be aware of the uncertainty in its current predictions to efficiently gate at each iteration, estimating variances after each loop for its keypoint estimates. Additionally, we investigate the effectiveness of end-to-end and progressive training protocols for our recursive structure on maximizing the model capacity. With the proposed setting, our method consistently outperforms state-of-the-art 2D/3D hand pose estimation approaches in terms of both accuracy and efficiency for widely used benchmarks.
HS3: Learning with Proper Task Complexity in Hierarchically Supervised Semantic Segmentation
Nov 03, 2021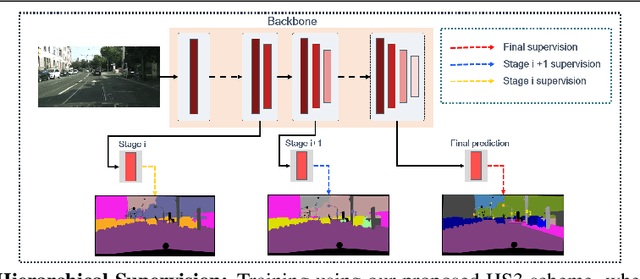
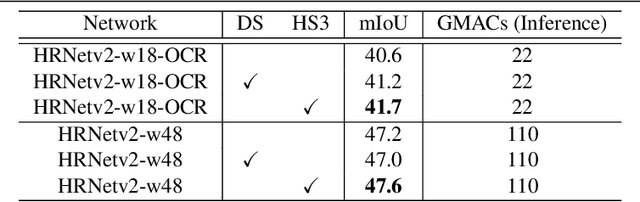
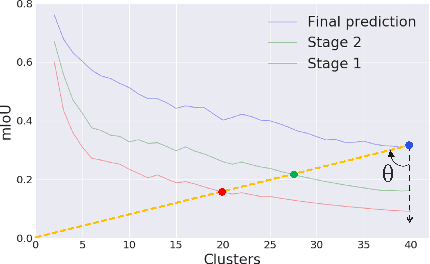

While deeply supervised networks are common in recent literature, they typically impose the same learning objective on all transitional layers despite their varying representation powers. In this paper, we propose Hierarchically Supervised Semantic Segmentation (HS3), a training scheme that supervises intermediate layers in a segmentation network to learn meaningful representations by varying task complexity. To enforce a consistent performance vs. complexity trade-off throughout the network, we derive various sets of class clusters to supervise each transitional layer of the network. Furthermore, we devise a fusion framework, HS3-Fuse, to aggregate the hierarchical features generated by these layers, which can provide rich semantic contexts and further enhance the final segmentation. Extensive experiments show that our proposed HS3 scheme considerably outperforms vanilla deep supervision with no added inference cost. Our proposed HS3-Fuse framework further improves segmentation predictions and achieves state-of-the-art results on two large segmentation benchmarks: NYUD-v2 and Cityscapes.
X-Distill: Improving Self-Supervised Monocular Depth via Cross-Task Distillation
Oct 24, 2021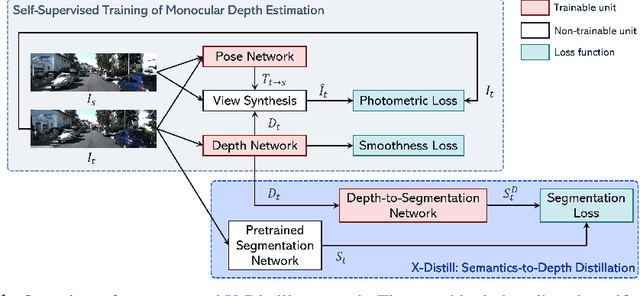
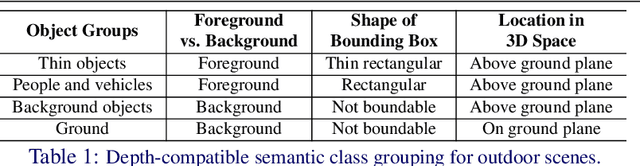

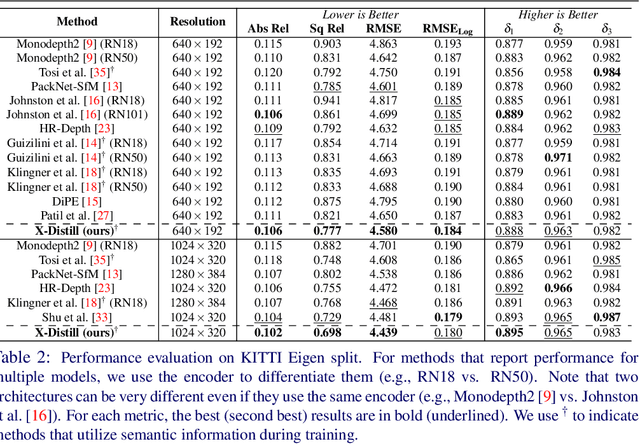
In this paper, we propose a novel method, X-Distill, to improve the self-supervised training of monocular depth via cross-task knowledge distillation from semantic segmentation to depth estimation. More specifically, during training, we utilize a pretrained semantic segmentation teacher network and transfer its semantic knowledge to the depth network. In order to enable such knowledge distillation across two different visual tasks, we introduce a small, trainable network that translates the predicted depth map to a semantic segmentation map, which can then be supervised by the teacher network. In this way, this small network enables the backpropagation from the semantic segmentation teacher's supervision to the depth network during training. In addition, since the commonly used object classes in semantic segmentation are not directly transferable to depth, we study the visual and geometric characteristics of the objects and design a new way of grouping them that can be shared by both tasks. It is noteworthy that our approach only modifies the training process and does not incur additional computation during inference. We extensively evaluate the efficacy of our proposed approach on the standard KITTI benchmark and compare it with the latest state of the art. We further test the generalizability of our approach on Make3D. Overall, the results show that our approach significantly improves the depth estimation accuracy and outperforms the state of the art.
Perceptual Consistency in Video Segmentation
Oct 24, 2021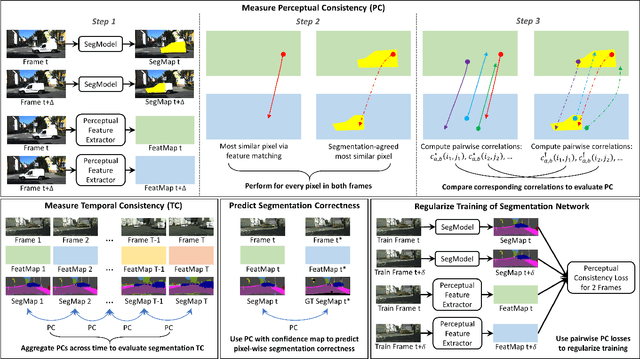

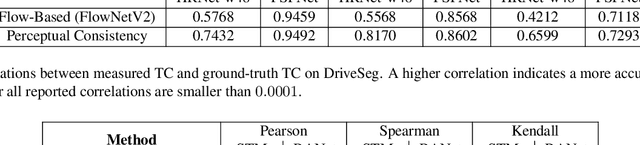
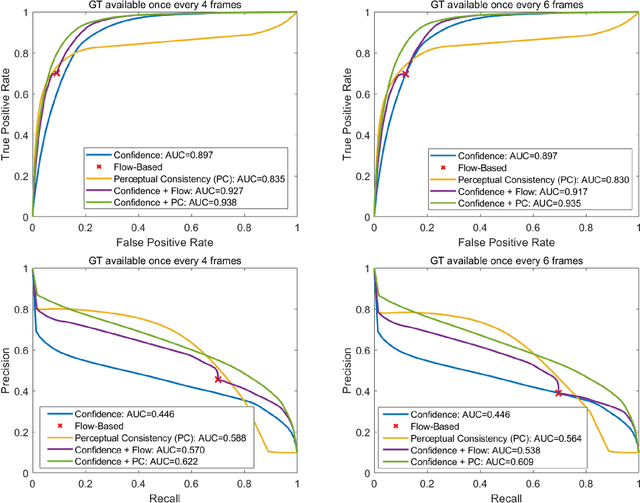
In this paper, we present a novel perceptual consistency perspective on video semantic segmentation, which can capture both temporal consistency and pixel-wise correctness. Given two nearby video frames, perceptual consistency measures how much the segmentation decisions agree with the pixel correspondences obtained via matching general perceptual features. More specifically, for each pixel in one frame, we find the most perceptually correlated pixel in the other frame. Our intuition is that such a pair of pixels are highly likely to belong to the same class. Next, we assess how much the segmentation agrees with such perceptual correspondences, based on which we derive the perceptual consistency of the segmentation maps across these two frames. Utilizing perceptual consistency, we can evaluate the temporal consistency of video segmentation by measuring the perceptual consistency over consecutive pairs of segmentation maps in a video. Furthermore, given a sparsely labeled test video, perceptual consistency can be utilized to aid with predicting the pixel-wise correctness of the segmentation on an unlabeled frame. More specifically, by measuring the perceptual consistency between the predicted segmentation and the available ground truth on a nearby frame and combining it with the segmentation confidence, we can accurately assess the classification correctness on each pixel. Our experiments show that the proposed perceptual consistency can more accurately evaluate the temporal consistency of video segmentation as compared to flow-based measures. Furthermore, it can help more confidently predict segmentation accuracy on unlabeled test frames, as compared to using classification confidence alone. Finally, our proposed measure can be used as a regularizer during the training of segmentation models, which leads to more temporally consistent video segmentation while maintaining accuracy.