 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrepancy-based Active Learning for Weakly Supervised Bleeding Segmentation in Wireless Capsule Endoscopy Images
Aug 09, 2023Weakly supervised methods, such as class activation maps (CAM) based, have been applied to achieve bleeding segmentation with low annotation efforts in Wireless Capsule Endoscopy (WCE) images. However, the CAM labels tend to be extremely noisy, and there is an irreparable gap between CAM labels and ground truths for medical images. This paper proposes a new Discrepancy-basEd Active Learning (DEAL) approach to bridge the gap between CAMs and ground truths with a few annotations. Specifically, to liberate labor, we design a novel discrepancy decoder model and a CAMPUS (CAM, Pseudo-label and groUnd-truth Selection) criterion to replace the noisy CAMs with accurate model predictions and a few human labels. The discrepancy decoder model is trained with a unique scheme to generate standard, coarse and fine predictions. And the CAMPUS criterion is proposed to predict the gaps between CAMs and ground truths based on model divergence and CAM divergence. We evaluate our method on the WCE dataset and results show that our method outperforms the state-of-the-art active learning methods and reaches comparable performance to those trained with full annotated datasets with only 10% of the training data labeled.
SLPT: Selective Labeling Meets Prompt Tuning on Label-Limited Lesion Segmentation
Aug 09, 2023


Medical image analysis using deep learning is often challenged by limited labeled data and high annotation costs. Fine-tuning the entire network in label-limited scenarios can lead to overfitting and suboptimal performance. Recently, prompt tuning has emerged as a more promising technique that introduces a few additional tunable parameters as prompts to a task-agnostic pre-trained model, and updates only these parameters using supervision from limited labeled data while keeping the pre-trained model unchanged. However, previous work has overlooked the importance of selective labeling in downstream tasks, which aims to select the most valuable downstream samples for annotation to achieve the best performance with minimum annotation cost. To address this, we propose a framework that combines selective labeling with prompt tuning (SLPT) to boost performance in limited labels. Specifically, we introduce a feature-aware prompt updater to guide prompt tuning and a TandEm Selective LAbeling (TESLA) strategy. TESLA includes unsupervised diversity selection and supervised selection using prompt-based uncertainty. In addition, we propose a diversified visual prompt tuning strategy to provide multi-prompt-based discrepant predictions for TESLA. We evaluate our method on liver tumor segmentation and achieve state-of-the-art performance, outperforming traditional fine-tuning with only 6% of tunable parameters, also achieving 94% of full-data performance by labeling only 5% of the data.
Matching in the Wild: Learning Anatomical Embeddings for Multi-Modality Images
Jul 07, 2023



Radiotherapists require accurate registration of MR/CT images to effectively use information from both modalities. In a typical registration pipeline, rigid or affine transformations are applied to roughly align the fixed and moving images before proceeding with the deformation step. While recent learning-based methods have shown promising results in the rigid/affine step, these methods often require images with similar field-of-view (FOV) for successful alignment. As a result, aligning images with different FOVs remains a challenging task. Self-supervised landmark detection methods like self-supervised Anatomical eMbedding (SAM) have emerged as a useful tool for mapping and cropping images to similar FOVs. However, these methods are currently limited to intra-modality use only. To address this limitation and enable cross-modality matching, we propose a new approach called Cross-SAM. Our approach utilizes a novel iterative process that alternates between embedding learning and CT-MRI registration. We start by applying aggressive contrast augmentation on both CT and MRI images to train a SAM model. We then use this SAM to identify corresponding regions on paired images using robust grid-points matching, followed by a point-set based affine/rigid registration, and a deformable fine-tuning step to produce registered paired images. We use these registered pairs to enhance the matching ability of SAM, which is then processed iteratively. We use the final model for cross-modality matching tasks. We evaluated our approach on two CT-MRI affine registration datasets and found that Cross-SAM achieved robust affine registration on both datasets, significantly outperforming other methods and achieving state-of-the-art performance.
Schema-Driven Information Extraction from Heterogeneous Tables
May 23, 2023In this paper, we explore the question of whether language models (LLMs) can support cost-efficient information extraction from complex tables. We introduce schema-driven information extraction, a new task that uses LLMs to transform tabular data into structured records following a human-authored schema. To assess various LLM's capabilities on this task, we develop a benchmark composed of tables from three diverse domains: machine learning papers, chemistry tables, and webpages. Accompanying the benchmark, we present InstrucTE, a table extraction method based on instruction-tuned LLMs. This method necessitates only a human-constructed extraction schema, and incorporates an error-recovery strategy. Notably, InstrucTE demonstrates competitive performance without task-specific labels, achieving an F1 score ranging from 72.3 to 95.7. Moreover, we validate the feasibility of distilling more compact table extraction models to minimize extraction costs and reduce API reliance. This study paves the way for the future development of instruction-following models for cost-efficient table extraction.
Frustratingly Simple Entity Tracking with Effective Use of Multi-Task Learning Models
Oct 12, 2022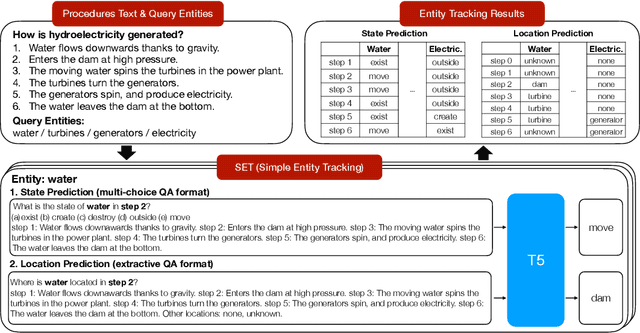
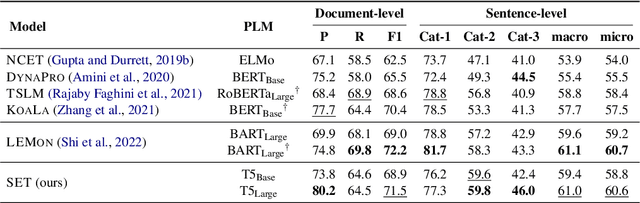
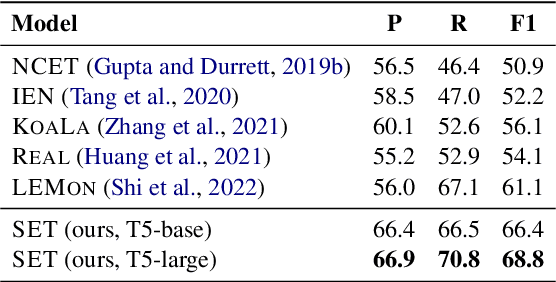
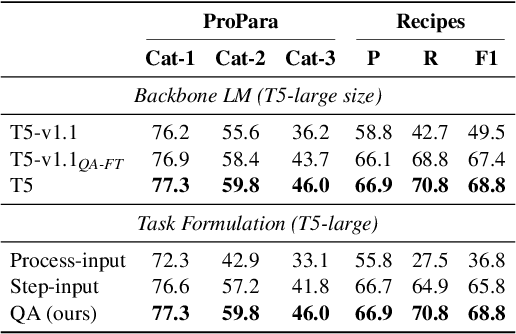
We present SET, a frustratingly Simple-yet-effective approach for Entity Tracking in procedural text. Compared with state-of-the-art entity tracking models that require domain-specific pre-training, SET simply fine-tunes off-the-shelf T5 with customized formats and gets comparable or even better performance on multiple datasets. Concretely, SET tackles the state and location prediction in entity tracking independently and formulates them as multi-choice and extractive QA problems, respectively. Through a series of careful analyses, we show that T5's supervised multi-task learning plays an important role in the success of SET. In addition, we reveal that SET has a strong capability of understanding implicit entity transformations, suggesting that multi-task transfer learning should be further explored in future entity tracking research.
Few-Shot Anaphora Resolution in Scientific Protocols via Mixtures of In-Context Experts
Oct 07, 2022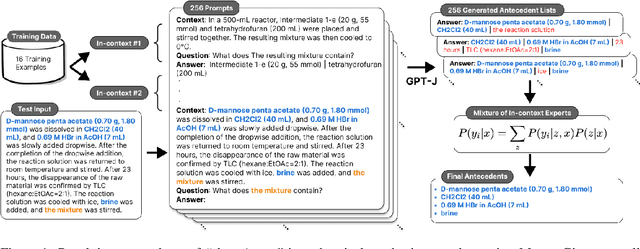
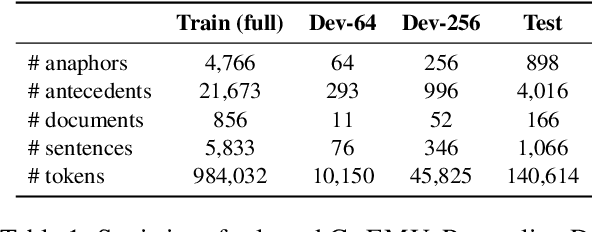
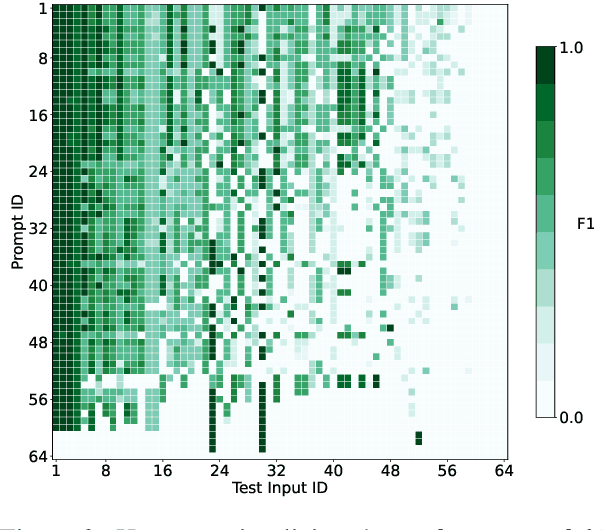
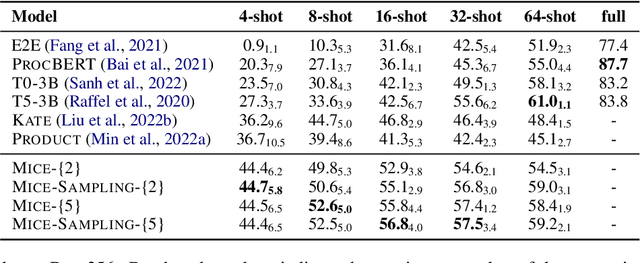
Anaphora resolution is an important task for information extraction across a range of languages, text genres, and domains, motivating the need for methods that do not require large annotated datasets. In-context learning has emerged as a promising approach, yet there are a number of challenges in applying in-context learning to resolve anaphora. For example, encoding a single in-context demonstration that consists of: an anaphor, a paragraph-length context, and a list of corresponding antecedents, requires conditioning a language model on a long sequence of tokens, limiting the number of demonstrations per prompt. In this paper, we present MICE (Mixtures of In-Context Experts), which we demonstrate is effective for few-shot anaphora resolution in scientific protocols (Tamari et al., 2021). Given only a handful of training examples, MICE combines the predictions of hundreds of in-context experts, yielding a 30% increase in F1 score over a competitive prompt retrieval baseline. Furthermore, we show MICE can be used to train compact student models without sacrificing performance. As far as we are aware, this is the first work to present experimental results demonstrating the effectiveness of in-context learning on the task of few-shot anaphora resolution in scientific protocols.
SynKB: Semantic Search for Synthetic Procedures
Aug 15, 2022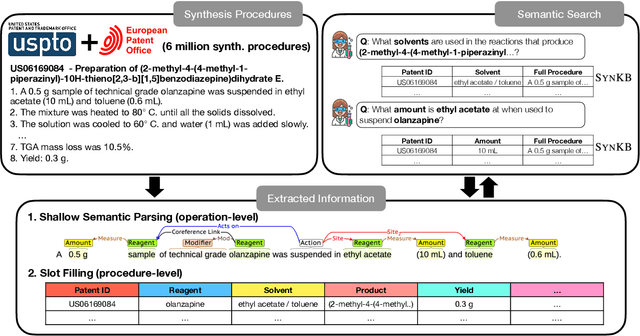


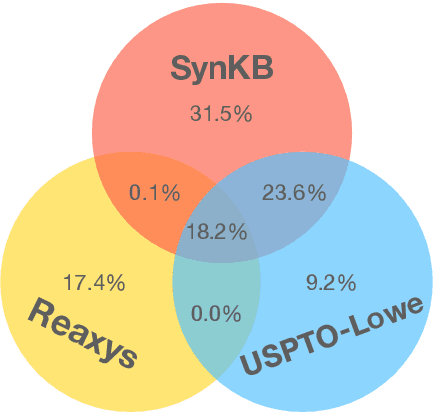
In this paper we present SynKB, an open-source, automatically extracted knowledge base of chemical synthesis protocols. Similar to proprietary chemistry databases such as Reaxsys, SynKB allows chemists to retrieve structured knowledge about synthetic procedures. By taking advantage of recent advances in natural language processing for procedural texts, SynKB supports more flexible queries about reaction conditions, and thus has the potential to help chemists search the literature for conditions used in relevant reactions as they design new synthetic routes. Using customized Transformer models to automatically extract information from 6 million synthesis procedures described in U.S. and EU patents, we show that for many queries, SynKB has higher recall than Reaxsys, while maintaining high precision. We plan to make SynKB available as an open-source tool; in contrast, proprietary chemistry databases require costly subscriptions.
C3-STISR: Scene Text Image Super-resolution with Triple Clues
Apr 29, 2022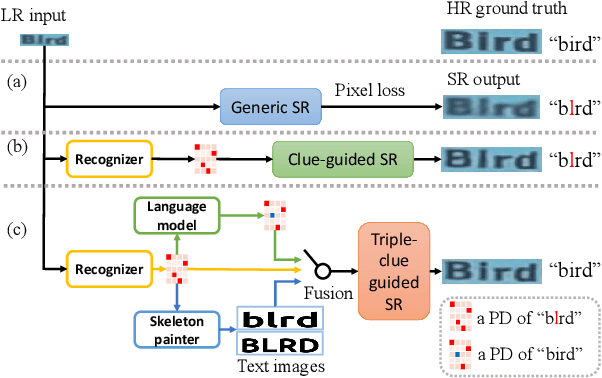
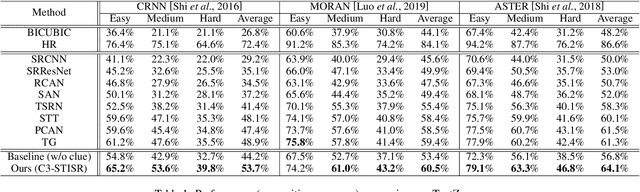
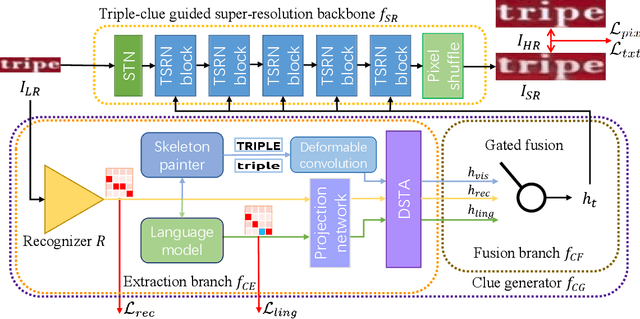
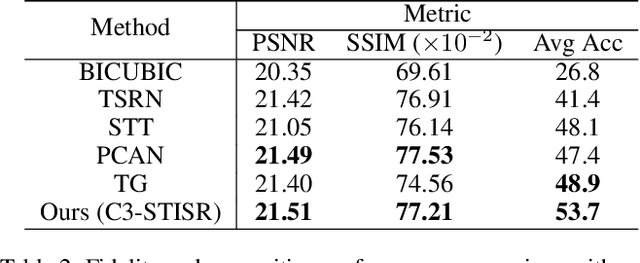
Scene text image super-resolution (STISR) has been regarded as an important pre-processing task for text recognition from low-resolution scene text images. Most recent approaches use the recognizer's feedback as clues to guide super-resolution. However, directly using recognition clue has two problems: 1) Compatibility. It is in the form of probability distribution, has an obvious modal gap with STISR - a pixel-level task; 2) Inaccuracy. it usually contains wrong information, thus will mislead the main task and degrade super-resolution performance. In this paper, we present a novel method C3-STISR that jointly exploits the recognizer's feedback, visual and linguistical information as clues to guide super-resolution. Here, visual clue is from the images of texts predicted by the recognizer, which is informative and more compatible with the STISR task; while linguistical clue is generated by a pre-trained character-level language model, which is able to correct the predicted texts. We design effective extraction and fusion mechanisms for the triple cross-modal clues to generate a comprehensive and unified guidance for super-resolution. Extensive experiments on TextZoom show that C3-STISR outperforms the SOTA methods in fidelity and recognition performance. Code is available in https://github.com/zhaominyiz/C3-STISR.
RASEC: Rescaling Acquisition Strategy with Energy Constraints under SE-OU Fusion Kernel for Active Trachea Palpation and Incision Recommendation in Laryngeal Region
Nov 12, 2021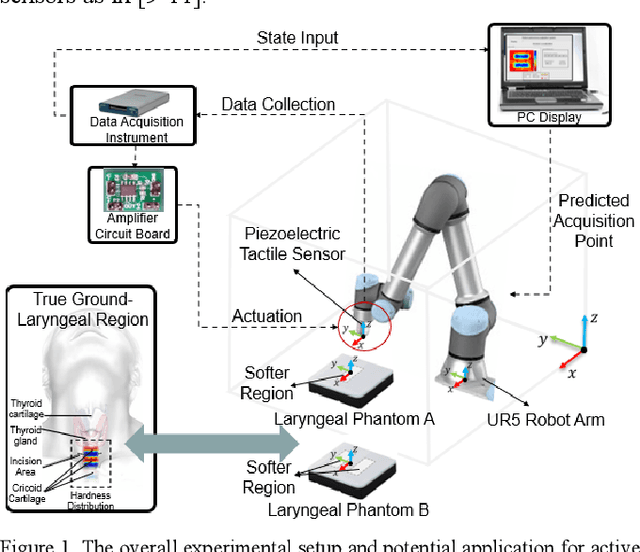
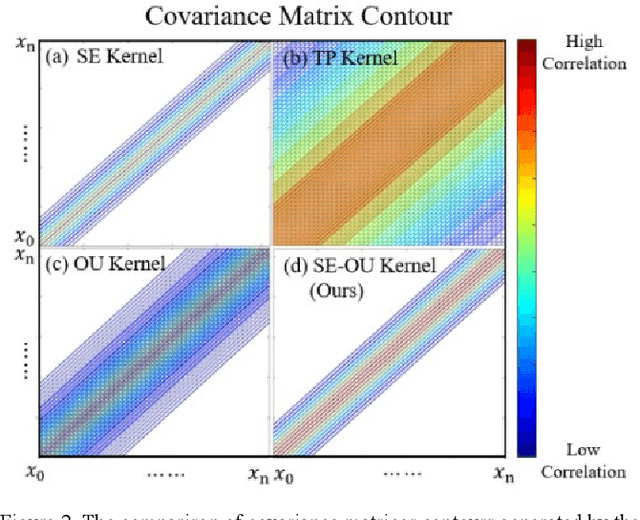
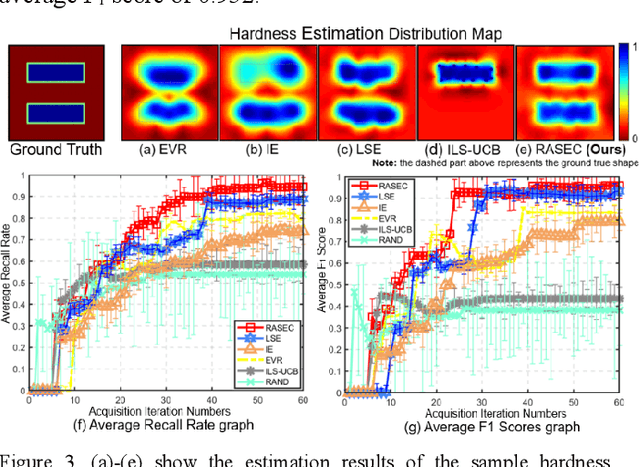
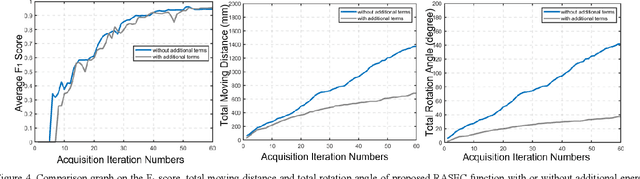
A novel palpation-based incision detection strategy in the laryngeal region, potentially for robotic tracheotomy, is proposed in this letter. A tactile sensor is introduced to measure tissue hardness in the specific laryngeal region by gentle contact. The kernel fusion method is proposed to combine the Squared Exponential (SE) kernel with Ornstein-Uhlenbeck (OU) kernel to figure out the drawbacks that the existing kernel functions are not sufficiently optimal in this scenario. Moreover, we further regularize exploration factor and greed factor, and the tactile sensor's moving distance and the robotic base link's rotation angle during the incision localization process are considered as new factors in the acquisition strategy. We conducted simulation and physical experiments to compare the newly proposed algorithm - Rescaling Acquisition Strategy with Energy Constraints (RASEC) in trachea detection with current palpation-based acquisition strategies. The result indicates that the proposed acquisition strategy with fusion kernel can successfully localize the incision with the highest algorithm performance (Average Precision 0.932, Average Recall 0.973, Average F1 score 0.952). During the robotic palpation process, the cumulative moving distance is reduced by 50%, and the cumulative rotation angle is reduced by 71.4% with no sacrifice in the comprehensive performance capabilities. Therefore, it proves that RASEC can efficiently suggest the incision zone in the laryngeal region and greatly reduced the energy loss.
Hierarchical Policy for Non-prehensile Multi-object Rearrangement with Deep Reinforcement Learning and Monte Carlo Tree Search
Sep 18, 2021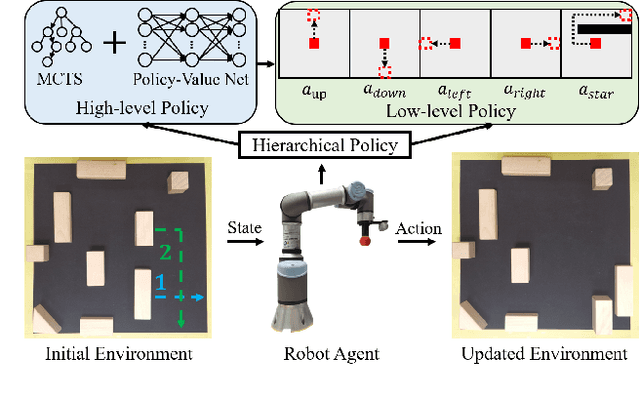
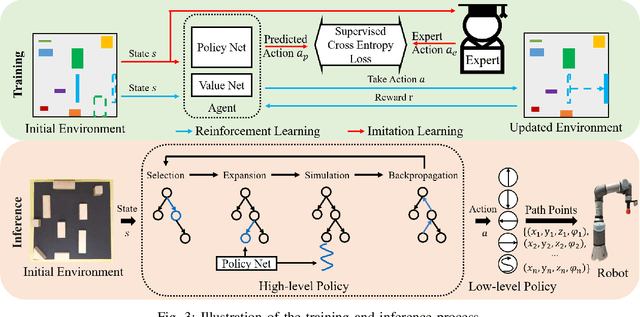
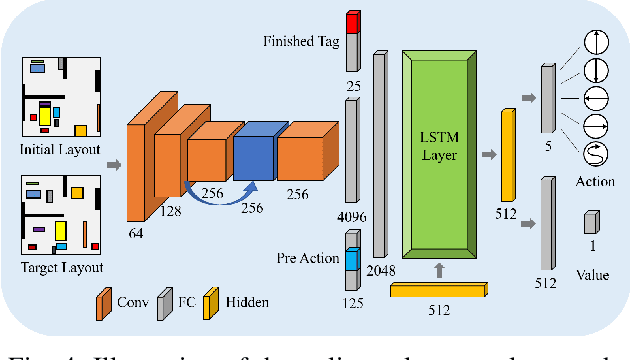
Non-prehensile multi-object rearrangement is a robotic task of planning feasible paths and transferring multiple objects to their predefined target poses without grasping. It needs to consider how each object reaches the target and the order of object movement, which significantly deepens the complexity of the problem. To address these challenges, we propose a hierarchical policy to divide and conquer for non-prehensile multi-object rearrangement. In the high-level policy, guided by a designed policy network, the Monte Carlo Tree Search efficiently searches for the optimal rearrangement sequence among multiple objects, which benefits from imitation and reinforcement. In the low-level policy, the robot plans the paths according to the order of path primitives and manipulates the objects to approach the goal poses one by one. We verify through experiments that the proposed method can achieve a higher success rate, fewer steps, and shorter path length compared with the state-of-the-art.