 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Jumpy Predictions for Videos and Scenes
Oct 02, 2018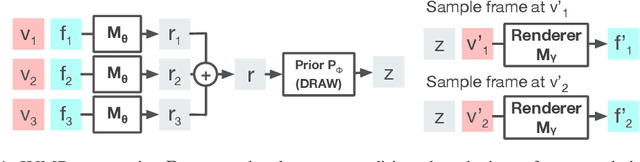
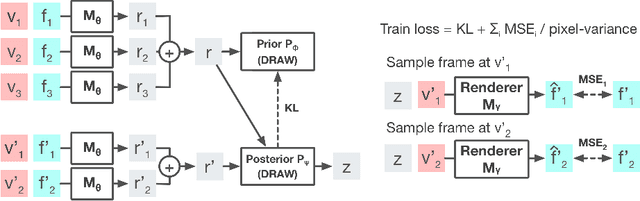


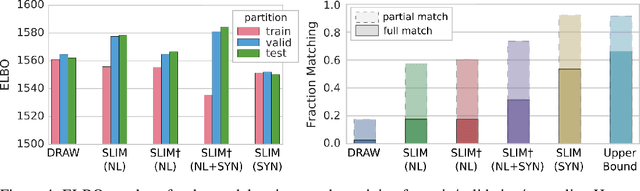
Stochastic video prediction models take in a sequence of image frames, and generate a sequence of consecutive future image frames. These models typically generate future frames in an autoregressive fashion, which is slow and requires the input and output frames to be consecutive. We introduce a model that overcomes these drawbacks by generating a latent representation from an arbitrary set of frames that can then be used to simultaneously and efficiently sample temporally consistent frames at arbitrary time-points. For example, our model can "jump" and directly sample frames at the end of the video, without sampling intermediate frames. Synthetic video evaluations confirm substantial gains in speed and functionality without loss in fidelity. We also apply our framework to a 3D scene reconstruction dataset. Here, our model is conditioned on camera location and can sample consistent sets of images for what an occluded region of a 3D scene might look like, even if there are multiple possibilities for what that region might contain. Reconstructions and videos are available at https://bit.ly/2O4Pc4R.
Taming VAEs
Oct 01, 2018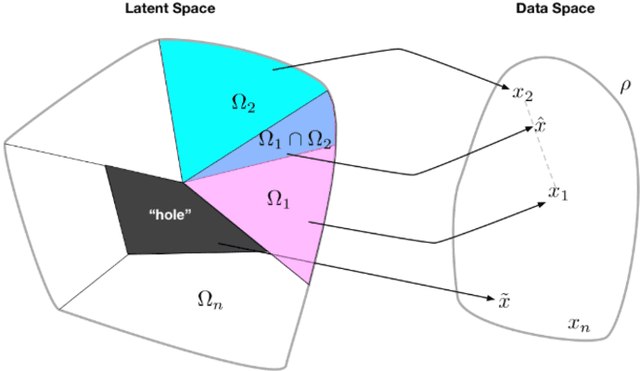

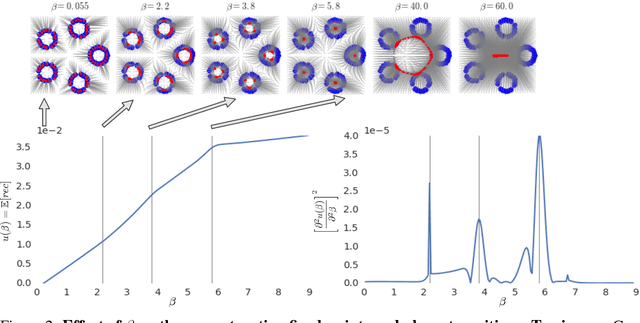

In spite of remarkable progress in deep latent variable generative modeling, training still remains a challenge due to a combination of optimization and generalization issues. In practice, a combination of heuristic algorithms (such as hand-crafted annealing of KL-terms) is often used in order to achieve the desired results, but such solutions are not robust to changes in model architecture or dataset. The best settings can often vary dramatically from one problem to another, which requires doing expensive parameter sweeps for each new case. Here we develop on the idea of training VAEs with additional constraints as a way to control their behaviour. We first present a detailed theoretical analysis of constrained VAEs, expanding our understanding of how these models work. We then introduce and analyze a practical algorithm termed Generalized ELBO with Constrained Optimization, GECO. The main advantage of GECO for the machine learning practitioner is a more intuitive, yet principled, process of tuning the loss. This involves defining of a set of constraints, which typically have an explicit relation to the desired model performance, in contrast to tweaking abstract hyper-parameters which implicitly affect the model behavior. Encouraging experimental results in several standard datasets indicate that GECO is a very robust and effective tool to balance reconstruction and compression constraints.
Generative Temporal Models with Spatial Memory for Partially Observed Environments
Jul 19, 2018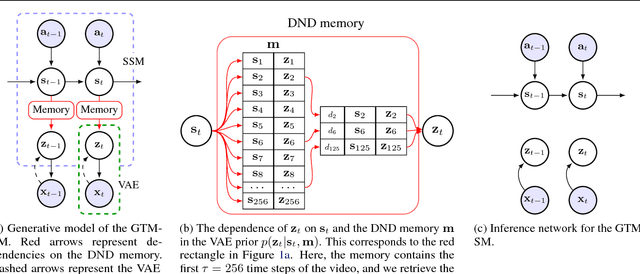

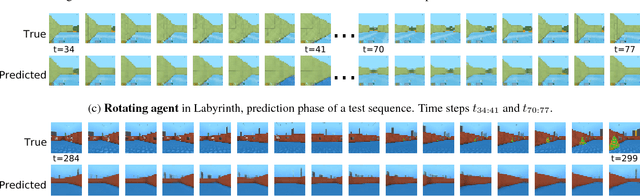

In model-based reinforcement learning, generative and temporal models of environments can be leveraged to boost agent performance, either by tuning the agent's representations during training or via use as part of an explicit planning mechanism. However, their application in practice has been limited to simplistic environments, due to the difficulty of training such models in larger, potentially partially-observed and 3D environments. In this work we introduce a novel action-conditioned generative model of such challenging environments. The model features a non-parametric spatial memory system in which we store learned, disentangled representations of the environment. Low-dimensional spatial updates are computed using a state-space model that makes use of knowledge on the prior dynamics of the moving agent, and high-dimensional visual observations are modelled with a Variational Auto-Encoder. The result is a scalable architecture capable of performing coherent predictions over hundreds of time steps across a range of partially observed 2D and 3D environments.
Encoding Spatial Relations from Natural Language
Jul 05, 2018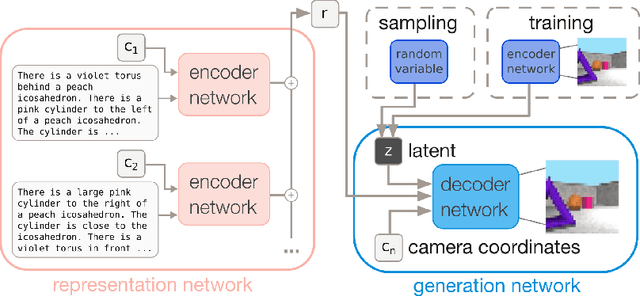

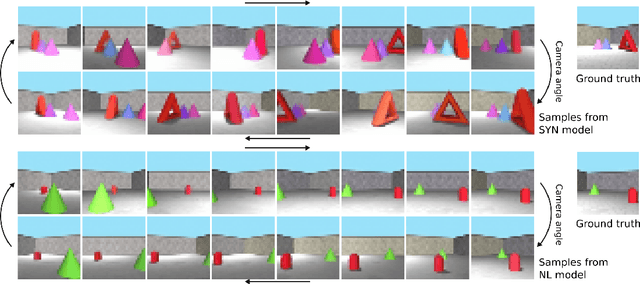
Natural language processing has made significant inroads into learning the semantics of words through distributional approaches, however representations learnt via these methods fail to capture certain kinds of information implicit in the real world. In particular, spatial relations are encoded in a way that is inconsistent with human spatial reasoning and lacking invariance to viewpoint changes. We present a system capable of capturing the semantics of spatial relations such as behind, left of, etc from natural language. Our key contributions are a novel multi-modal objective based on generating images of scenes from their textual descriptions, and a new dataset on which to train it. We demonstrate that internal representations are robust to meaning preserving transformations of descriptions (paraphrase invariance), while viewpoint invariance is an emergent property of the system.
Learning models for visual 3D localization with implicit mapping
Jul 04, 2018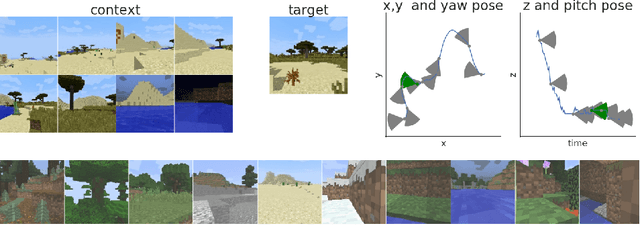
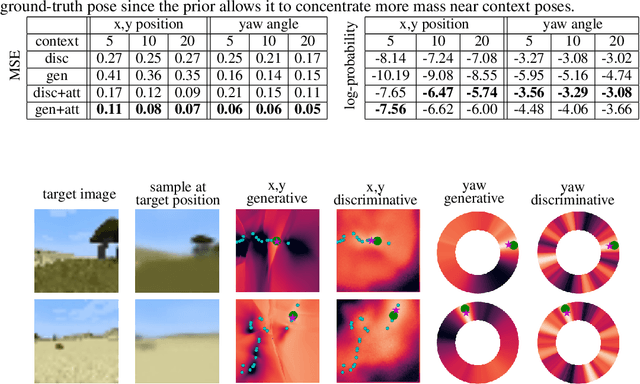
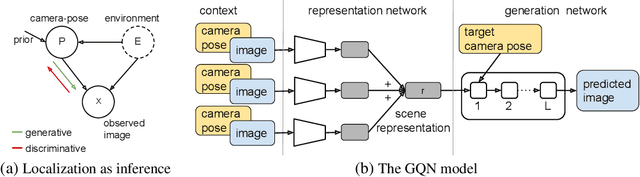
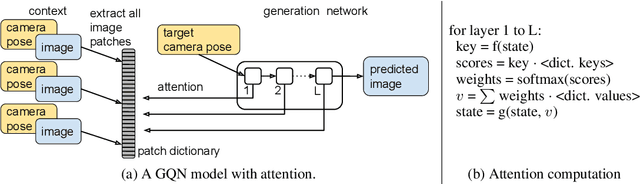
We propose a formulation of visual localization that does not require construction of explicit maps in the form of point clouds or voxels. The goal is to learn an implicit representation of the environment at a higher, more abstract level, for instance that of objects. To study this approach we consider procedurally generated Minecraft worlds, for which we can generate visually rich images along with camera pose coordinates. We first show that Generative Query Networks (GQNs) enhanced with a novel attention mechanism can capture the visual structure of 3D scenes in Minecraft, as evidenced by their samples. We then apply the models to the localization problem, investigating both generative and discriminative approaches, and compare the different ways in which they each capture task uncertainty. Our results show that models with implicit mapping are able to capture the underlying 3D structure of visually complex scenes, and use this to accurately localize new observations, paving the way towards future applications in sequential localization. Supplementary video available at https://youtu.be/iHEXX5wXbCI.
Neural Processes
Jul 04, 2018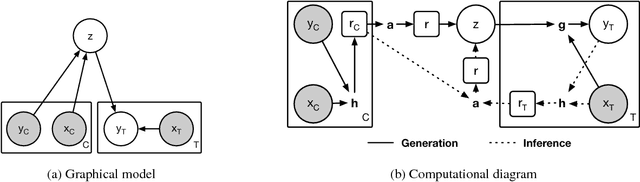

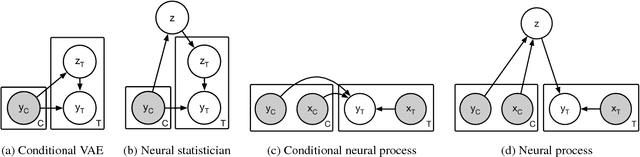
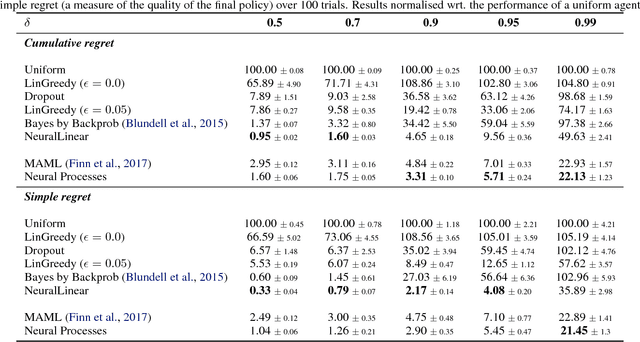
A neural network (NN) is a parameterised function that can be tuned via gradient descent to approximate a labelled collection of data with high precision. A Gaussian process (GP), on the other hand, is a probabilistic model that defines a distribution over possible functions, and is updated in light of data via the rules of probabilistic inference. GPs are probabilistic, data-efficient and flexible, however they are also computationally intensive and thus limited in their applicability. We introduce a class of neural latent variable models which we call Neural Processes (NPs), combining the best of both worlds. Like GPs, NPs define distributions over functions, are capable of rapid adaptation to new observations, and can estimate the uncertainty in their predictions. Like NNs, NPs are computationally efficient during training and evaluation but also learn to adapt their priors to data. We demonstrate the performance of NPs on a range of learning tasks, including regression and optimisation, and compare and contrast with related models in the literature.
Learning and Querying Fast Generative Models for Reinforcement Learning
Feb 08, 2018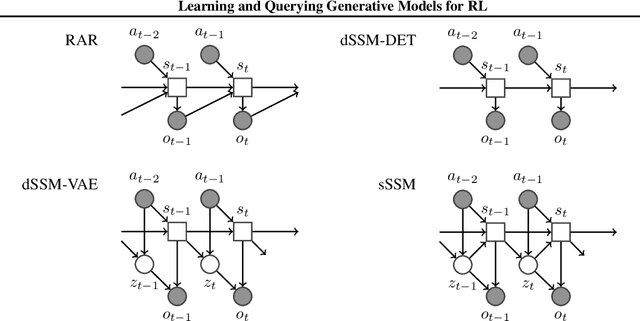

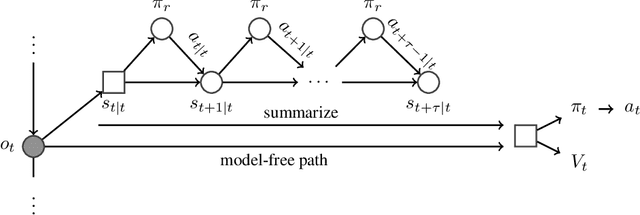
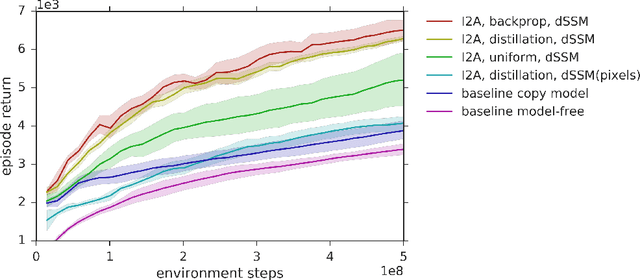
A key challenge in model-based reinforcement learning (RL) is to synthesize computationally efficient and accurate environment models. We show that carefully designed generative models that learn and operate on compact state representations, so-called state-space models, substantially reduce the computational costs for predicting outcomes of sequences of actions. Extensive experiments establish that state-space models accurately capture the dynamics of Atari games from the Arcade Learning Environment from raw pixels. The computational speed-up of state-space models while maintaining high accuracy makes their application in RL feasible: We demonstrate that agents which query these models for decision making outperform strong model-free baselines on the game MSPACMAN, demonstrating the potential of using learned environment models for planning.
The Kinetics Human Action Video Dataset
May 19, 2017
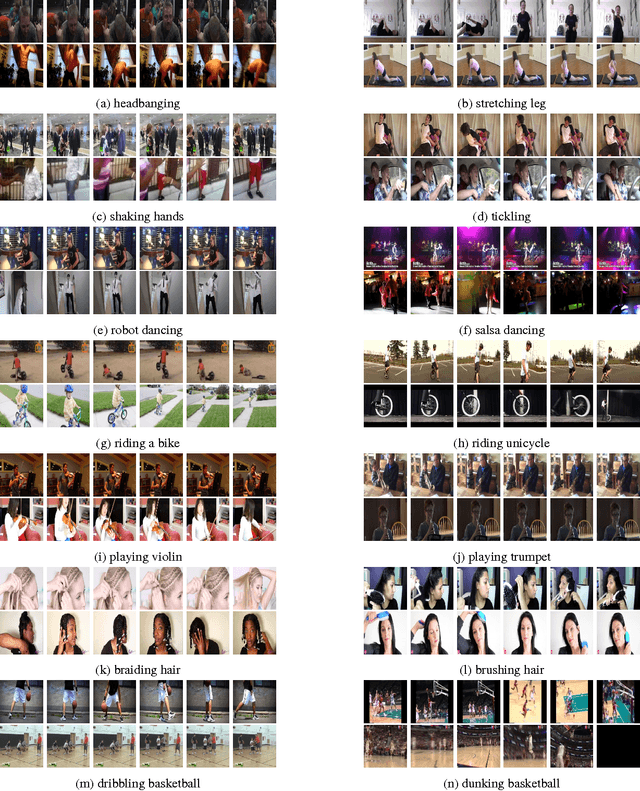
We describe the DeepMind Kinetics human action video dataset. The dataset contains 400 human action classes, with at least 400 video clips for each action. Each clip lasts around 10s and is taken from a different YouTube video. The actions are human focussed and cover a broad range of classes including human-object interactions such as playing instruments, as well as human-human interactions such as shaking hands. We describe the statistics of the dataset, how it was collected, and give some baseline performance figures for neural network architectures trained and tested for human action classification on this dataset. We also carry out a preliminary analysis of whether imbalance in the dataset leads to bias in the classifiers.
Learning to Navigate in Complex Environments
Jan 13, 2017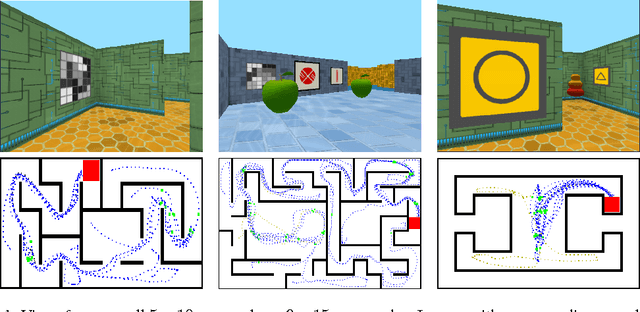
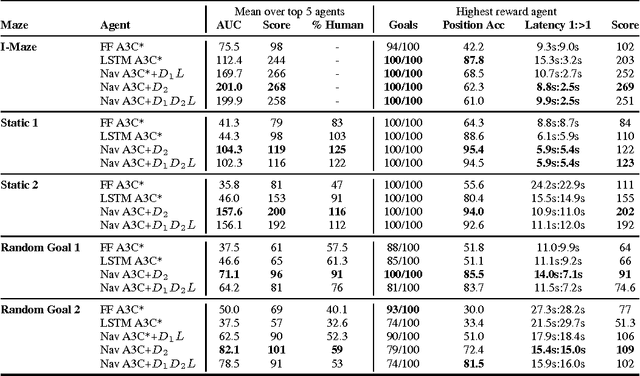
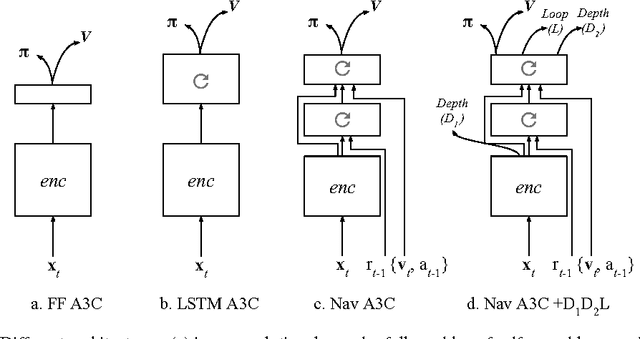
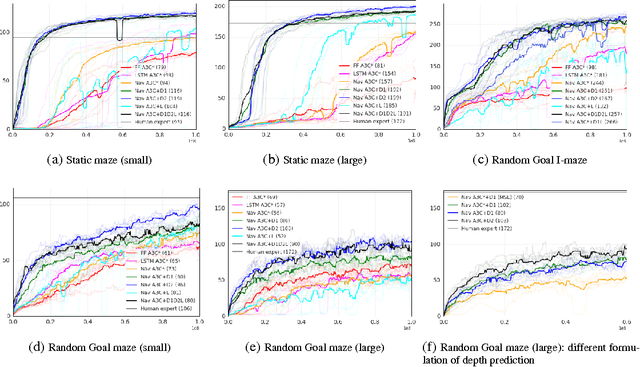
Learning to navigate in complex environments with dynamic elements is an important milestone in developing AI agents. In this work we formulate the navigation question as a reinforcement learning problem and show that data efficiency and task performance can be dramatically improved by relying on additional auxiliary tasks leveraging multimodal sensory inputs. In particular we consider jointly learning the goal-driven reinforcement learning problem with auxiliary depth prediction and loop closure classification tasks. This approach can learn to navigate from raw sensory input in complicated 3D mazes, approaching human-level performance even under conditions where the goal location changes frequently. We provide detailed analysis of the agent behaviour, its ability to localise, and its network activity dynamics, showing that the agent implicitly learns key navigation abilities.