 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Strategies for More Efficient and Accurate Agentic RAG
Mar 12, 2026Retrieval-Augmented Generation (RAG) systems face challenges with complex, multihop questions, and agentic frameworks such as Search-R1 (Jin et al., 2025), which operates iteratively, have been proposed to address these complexities. However, such approaches can introduce inefficiencies, including repetitive retrieval of previously processed information and challenges in contextualizing retrieved results effectively within the current generation prompt. Such issues can lead to unnecessary retrieval turns, suboptimal reasoning, inaccurate answers, and increased token consumption. In this paper, we investigate test-time modifications to the Search-R1 pipeline to mitigate these identified shortcomings. Specifically, we explore the integration of two components and their combination: a contextualization module to better integrate relevant information from retrieved documents into reasoning, and a de-duplication module that replaces previously retrieved documents with the next most relevant ones. We evaluate our approaches using the HotpotQA (Yang et al., 2018) and the Natural Questions (Kwiatkowski et al., 2019) datasets, reporting the exact match (EM) score, an LLM-as-a-Judge assessment of answer correctness, and the average number of turns. Our best-performing variant, utilizing GPT-4.1-mini for contextualization, achieves a 5.6% increase in EM score and reduces the number of turns by 10.5% compared to the Search-R1 baseline, demonstrating improved answer accuracy and retrieval efficiency.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
TrajFlow: Multi-modal Motion Prediction via Flow Matching
Jun 10, 2025Efficient and accurate motion prediction is crucial for ensuring safety and informed decision-making in autonomous driving, particularly under dynamic real-world conditions that necessitate multi-modal forecasts. We introduce TrajFlow, a novel flow matching-based motion prediction framework that addresses the scalability and efficiency challenges of existing generative trajectory prediction methods. Unlike conventional generative approaches that employ i.i.d. sampling and require multiple inference passes to capture diverse outcomes, TrajFlow predicts multiple plausible future trajectories in a single pass, significantly reducing computational overhead while maintaining coherence across predictions. Moreover, we propose a ranking loss based on the Plackett-Luce distribution to improve uncertainty estimation of predicted trajectories. Additionally, we design a self-conditioning training technique that reuses the model's own predictions to construct noisy inputs during a second forward pass, thereby improving generalization and accelerating inference. Extensive experiments on the large-scale Waymo Open Motion Dataset (WOMD) demonstrate that TrajFlow achieves state-of-the-art performance across various key metrics, underscoring its effectiveness for safety-critical autonomous driving applications. The code and other details are available on the project website https://traj-flow.github.io/.
LithOS: An Operating System for Efficient Machine Learning on GPUs
Apr 21, 2025The surging demand for GPUs in datacenters for machine learning (ML) has made efficient GPU utilization crucial. However, meeting the diverse needs of ML models while optimizing resource usage is challenging. To enable transparent, fine-grained GPU management that maximizes utilization and energy efficiency while maintaining strong isolation, an operating system (OS) approach is needed. This paper introduces LithOS, a first step toward a GPU OS. LithOS includes the following new abstractions and mechanisms for efficient GPU resource management: (i) a novel TPC Scheduler that supports spatial scheduling at the granularity of individual TPCs, unlocking efficient TPC stealing between workloads; (ii) transparent kernel atomization to reduce head-of-line blocking and enable dynamic resource reallocation mid-execution; (iii) a lightweight hardware right-sizing mechanism that determines the minimal TPC resources needed per atom; and (iv) a transparent power management mechanism that reduces power consumption based on in-flight work behavior. We implement LithOS in Rust and evaluate its performance across extensive ML environments, comparing it to state-of-the-art solutions from NVIDIA and prior research. For inference stacking, LithOS reduces tail latencies by 13x compared to MPS; compared to the best SotA, it reduces tail latencies by 3x while improving aggregate throughput by 1.6x. In hybrid inference-training stacking, LithOS reduces tail latencies by 4.7x compared to MPS; compared to the best SotA, it reduces tail latencies 1.18x while improving aggregate throughput by 1.35x. Finally, for a modest performance hit under 4%, LithOS's right-sizing provides a quarter of GPU capacity savings on average, while for a 7% hit, its power management yields a quarter of a GPU's energy savings. Overall, LithOS increases GPU efficiency, establishing a foundation for future OS research on GPUs.
Optimal Correlated Equilibria in General-Sum Extensive-Form Games: Fixed-Parameter Algorithms, Hardness, and Two-Sided Column-Generation
Mar 14, 2022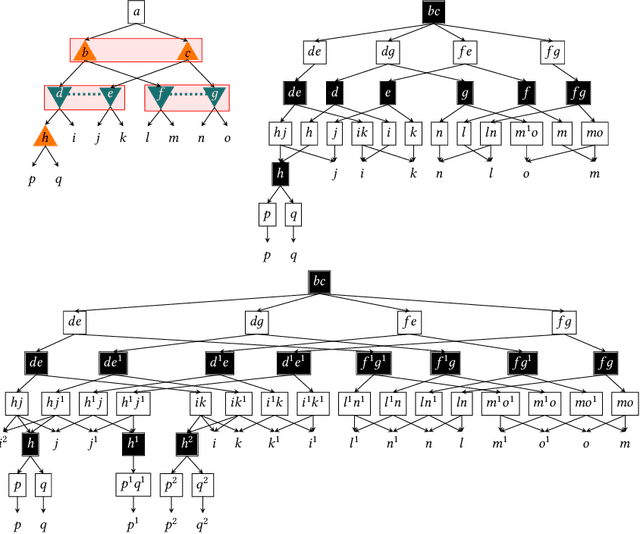
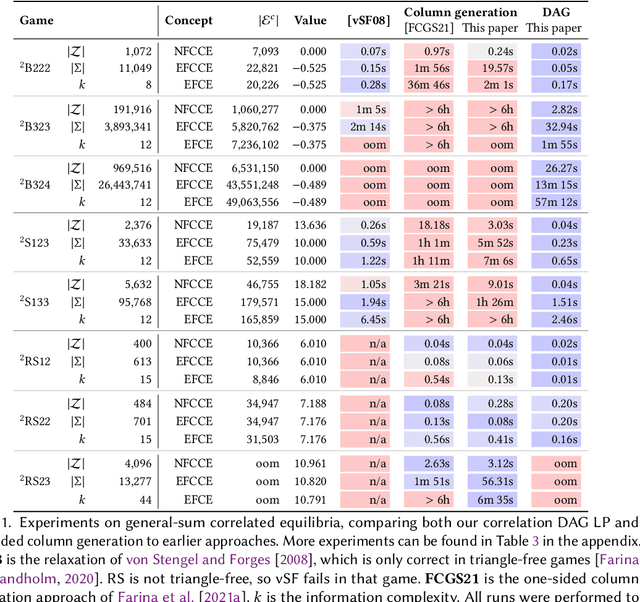
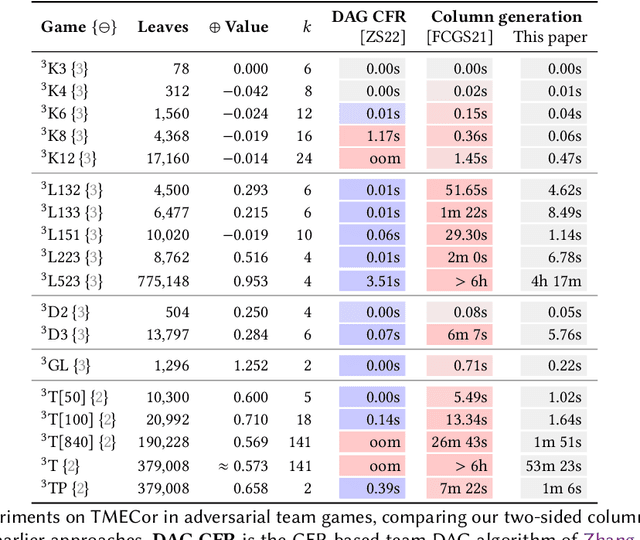
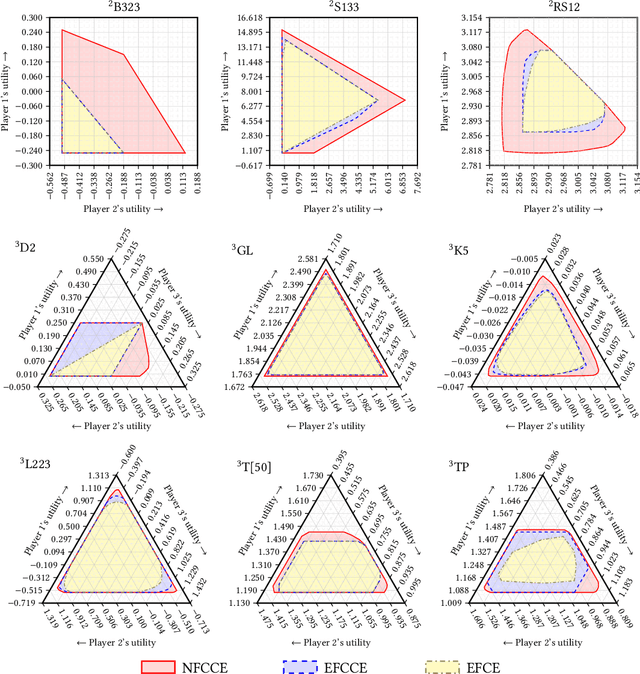
We study the problem of finding optimal correlated equilibria of various sorts: normal-form coarse correlated equilibrium (NFCCE), extensive-form coarse correlated equilibrium (EFCCE), and extensive-form correlated equilibrium (EFCE). This is NP-hard in the general case and has been studied in special cases, most notably triangle-free games, which include all two-player games with public chance moves. However, the general case is not well understood, and algorithms usually scale poorly. First, we introduce the correlation DAG, a representation of the space of correlated strategies whose size is dependent on the specific solution concept. It extends the team belief DAG of Zhang et al. to general-sum games. For each of the three solution concepts, its size depends exponentially only on a parameter related to the game's information structure. We also prove a fundamental complexity gap: while our size bounds for NFCCE are similar to those achieved in the case of team games by Zhang et al., this is impossible to achieve for the other two concepts under standard complexity assumptions. Second, we propose a two-sided column generation approach to compute optimal correlated strategies. Our algorithm improves upon the one-sided approach of Farina et al. by means of a new decomposition of correlated strategies which allows players to re-optimize their sequence-form strategies with respect to correlation plans which were previously added to the support. Our techniques outperform the prior state of the art for computing optimal general-sum correlated equilibria. For team games, the two-sided column generation approach vastly outperforms standard column generation approaches, making it the state of the art algorithm when the parameter is large. Along the way we also introduce two new benchmark games: a trick-taking game that emulates the endgame phase of the card game bridge, and a ride-sharing game.
Zap: Making Predictions Based on Online User Behavior
Jul 16, 2018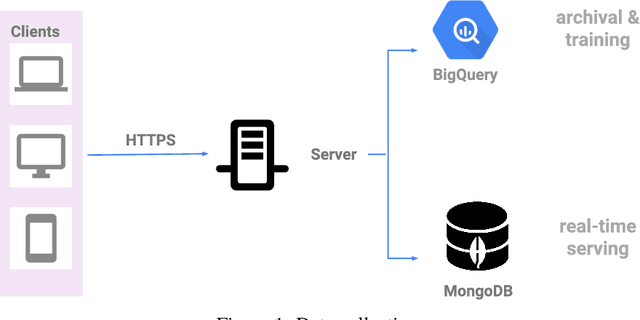
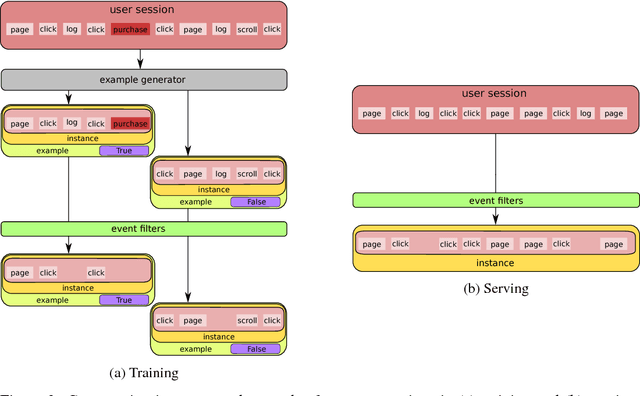
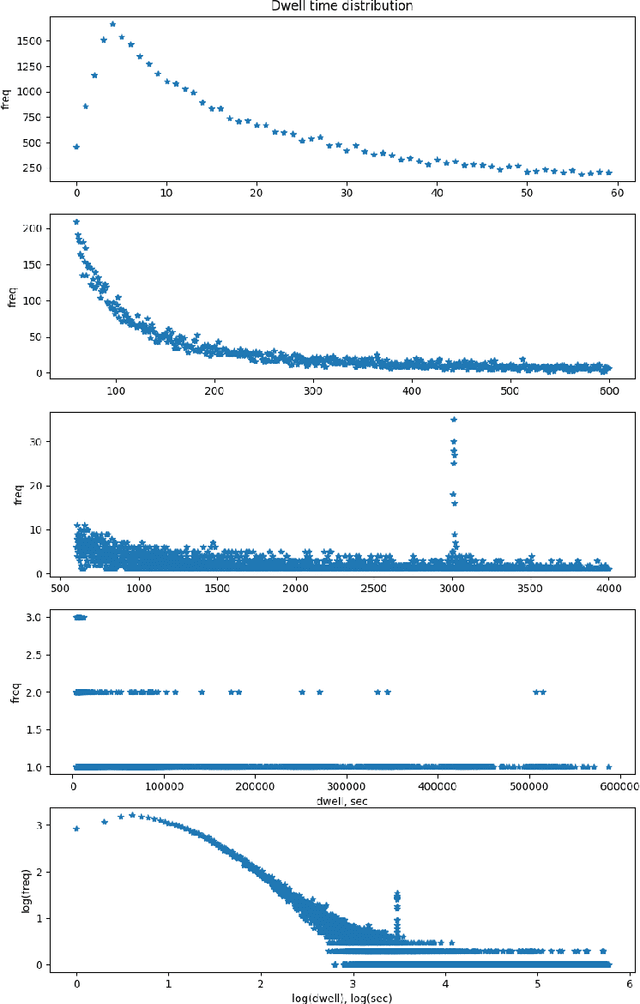
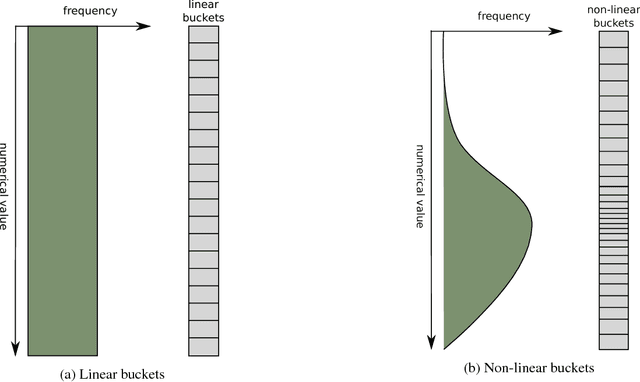
This paper introduces Zap, a generic machine learning pipeline for making predictions based on online user behavior. Zap combines well known techniques for processing sequential data with more obscure techniques such as Bloom filters, bucketing, and model calibration into an end-to-end solution. The pipeline creates website- and task-specific models without knowing anything about the structure of the website. It is designed to minimize the amount of website-specific code, which is realized by factoring all website-specific logic into example generators. New example generators can typically be written up in a few lines of code.
The Kinetics Human Action Video Dataset
May 19, 2017
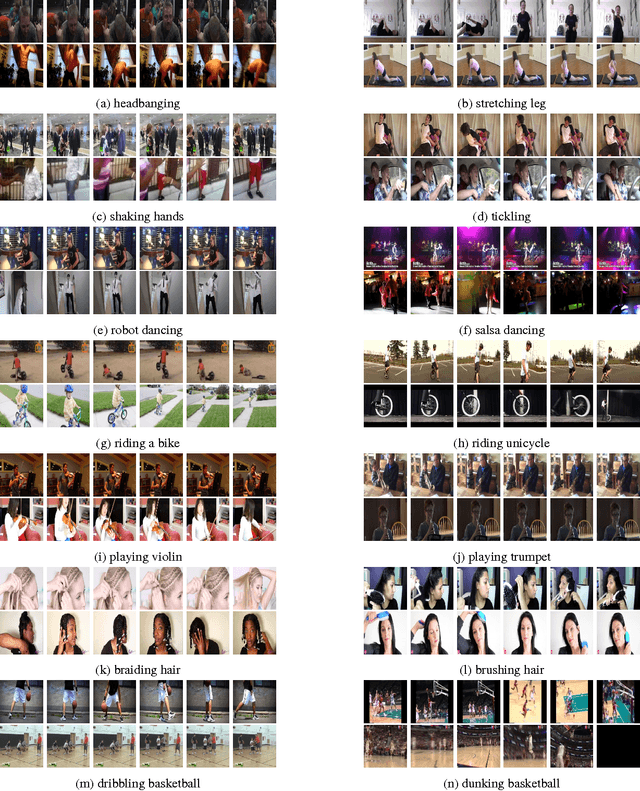
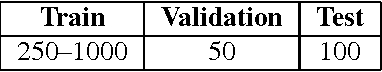
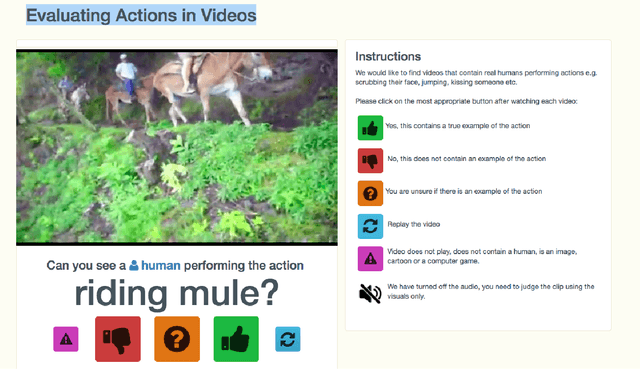
We describe the DeepMind Kinetics human action video dataset. The dataset contains 400 human action classes, with at least 400 video clips for each action. Each clip lasts around 10s and is taken from a different YouTube video. The actions are human focussed and cover a broad range of classes including human-object interactions such as playing instruments, as well as human-human interactions such as shaking hands. We describe the statistics of the dataset, how it was collected, and give some baseline performance figures for neural network architectures trained and tested for human action classification on this dataset. We also carry out a preliminary analysis of whether imbalance in the dataset leads to bias in the classifiers.