 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Training and Prompting for Few-Shot Node Classification on Text-Attributed Graphs
Jul 22, 2024



The text-attributed graph (TAG) is one kind of important real-world graph-structured data with each node associated with raw texts. For TAGs, traditional few-shot node classification methods directly conduct training on the pre-processed node features and do not consider the raw texts. The performance is highly dependent on the choice of the feature pre-processing method. In this paper, we propose P2TAG, a framework designed for few-shot node classification on TAGs with graph pre-training and prompting. P2TAG first pre-trains the language model (LM) and graph neural network (GNN) on TAGs with self-supervised loss. To fully utilize the ability of language models, we adapt the masked language modeling objective for our framework. The pre-trained model is then used for the few-shot node classification with a mixed prompt method, which simultaneously considers both text and graph information. We conduct experiments on six real-world TAGs, including paper citation networks and product co-purchasing networks. Experimental results demonstrate that our proposed framework outperforms existing graph few-shot learning methods on these datasets with +18.98% ~ +35.98% improvements.
Approximating Probabilistic Inference in Statistical EL with Knowledge Graph Embeddings
Jul 16, 2024Statistical information is ubiquitous but drawing valid conclusions from it is prohibitively hard. We explain how knowledge graph embeddings can be used to approximate probabilistic inference efficiently using the example of Statistical EL (SEL), a statistical extension of the lightweight Description Logic EL. We provide proofs for runtime and soundness guarantees, and empirically evaluate the runtime and approximation quality of our approach.
Generating SROI^{-} Ontologies via Knowledge Graph Query Embedding Learning
Jul 12, 2024Query embedding approaches answer complex logical queries over incomplete knowledge graphs (KGs) by computing and operating on low-dimensional vector representations of entities, relations, and queries. However, current query embedding models heavily rely on excessively parameterized neural networks and cannot explain the knowledge learned from the graph. We propose a novel query embedding method, AConE, which explains the knowledge learned from the graph in the form of SROI^{-} description logic axioms while being more parameter-efficient than most existing approaches. AConE associates queries to a SROI^{-} description logic concept. Every SROI^{-} concept is embedded as a cone in complex vector space, and each SROI^{-} relation is embedded as a transformation that rotates and scales cones. We show theoretically that AConE can learn SROI^{-} axioms, and defines an algebra whose operations correspond one to one to SROI^{-} description logic concept constructs. Our empirical study on multiple query datasets shows that AConE achieves superior results over previous baselines with fewer parameters. Notably on the WN18RR dataset, AConE achieves significant improvement over baseline models. We provide comprehensive analyses showing that the capability to represent axioms positively impacts the results of query answering.
Robust Knowledge Extraction from Large Language Models using Social Choice Theory
Dec 22, 2023Large-language models (LLMs) have the potential to support a wide range of applications like conversational agents, creative writing, text improvement, and general query answering. However, they are ill-suited for query answering in high-stake domains like medicine because they generate answers at random and their answers are typically not robust - even the same query can result in different answers when prompted multiple times. In order to improve the robustness of LLM queries, we propose using ranking queries repeatedly and to aggregate the queries using methods from social choice theory. We study ranking queries in diagnostic settings like medical and fault diagnosis and discuss how the Partial Borda Choice function from the literature can be applied to merge multiple query results. We discuss some additional interesting properties in our setting and evaluate the robustness of our approach empirically.
Literal-Aware Knowledge Graph Embedding for Welding Quality Monitoring: A Bosch Case
Aug 02, 2023



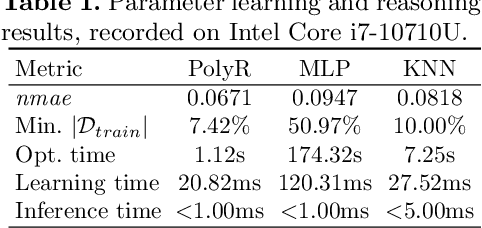
Recently there has been a series of studies in knowledge graph embedding (KGE), which attempts to learn the embeddings of the entities and relations as numerical vectors and mathematical mappings via machine learning (ML). However, there has been limited research that applies KGE for industrial problems in manufacturing. This paper investigates whether and to what extent KGE can be used for an important problem: quality monitoring for welding in manufacturing industry, which is an impactful process accounting for production of millions of cars annually. The work is in line with Bosch research of data-driven solutions that intends to replace the traditional way of destroying cars, which is extremely costly and produces waste. The paper tackles two very challenging questions simultaneously: how large the welding spot diameter is; and to which car body the welded spot belongs to. The problem setting is difficult for traditional ML because there exist a high number of car bodies that should be assigned as class labels. We formulate the problem as link prediction, and experimented popular KGE methods on real industry data, with consideration of literals. Our results reveal both limitations and promising aspects of adapted KGE methods.
Scaling Data Science Solutions with Semantics and Machine Learning: Bosch Case
Aug 02, 2023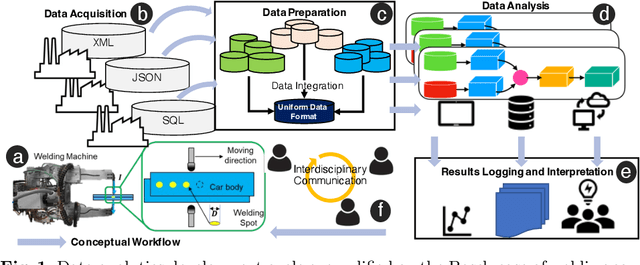
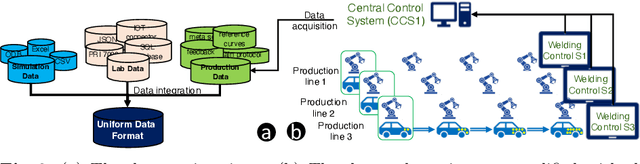
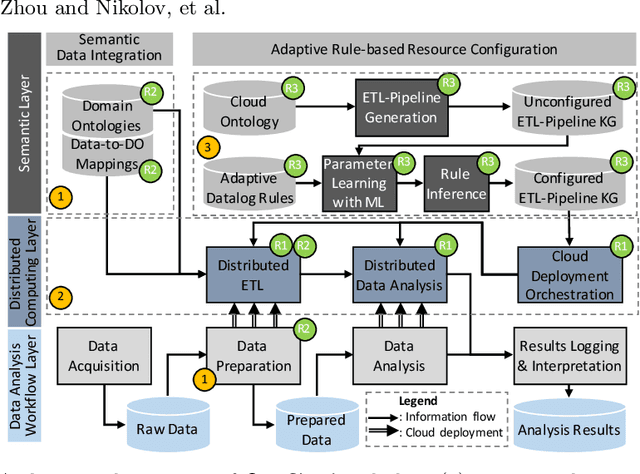
Industry 4.0 and Internet of Things (IoT) technologies unlock unprecedented amount of data from factory production, posing big data challenges in volume and variety. In that context, distributed computing solutions such as cloud systems are leveraged to parallelise the data processing and reduce computation time. As the cloud systems become increasingly popular, there is increased demand that more users that were originally not cloud experts (such as data scientists, domain experts) deploy their solutions on the cloud systems. However, it is non-trivial to address both the high demand for cloud system users and the excessive time required to train them. To this end, we propose SemCloud, a semantics-enhanced cloud system, that couples cloud system with semantic technologies and machine learning. SemCloud relies on domain ontologies and mappings for data integration, and parallelises the semantic data integration and data analysis on distributed computing nodes. Furthermore, SemCloud adopts adaptive Datalog rules and machine learning for automated resource configuration, allowing non-cloud experts to use the cloud system. The system has been evaluated in industrial use case with millions of data, thousands of repeated runs, and domain users, showing promising results.
ExeKGLib: Knowledge Graphs-Empowered Machine Learning Analytics
May 04, 2023


Many machine learning (ML) libraries are accessible online for ML practitioners. Typical ML pipelines are complex and consist of a series of steps, each of them invoking several ML libraries. In this demo paper, we present ExeKGLib, a Python library that allows users with coding skills and minimal ML knowledge to build ML pipelines. ExeKGLib relies on knowledge graphs to improve the transparency and reusability of the built ML workflows, and to ensure that they are executable. We demonstrate the usage of ExeKGLib and compare it with conventional ML code to show its benefits.
GraphMAE2: A Decoding-Enhanced Masked Self-Supervised Graph Learner
Apr 10, 2023



Graph self-supervised learning (SSL), including contrastive and generative approaches, offers great potential to address the fundamental challenge of label scarcity in real-world graph data. Among both sets of graph SSL techniques, the masked graph autoencoders (e.g., GraphMAE)--one type of generative method--have recently produced promising results. The idea behind this is to reconstruct the node features (or structures)--that are randomly masked from the input--with the autoencoder architecture. However, the performance of masked feature reconstruction naturally relies on the discriminability of the input features and is usually vulnerable to disturbance in the features. In this paper, we present a masked self-supervised learning framework GraphMAE2 with the goal of overcoming this issue. The idea is to impose regularization on feature reconstruction for graph SSL. Specifically, we design the strategies of multi-view random re-mask decoding and latent representation prediction to regularize the feature reconstruction. The multi-view random re-mask decoding is to introduce randomness into reconstruction in the feature space, while the latent representation prediction is to enforce the reconstruction in the embedding space. Extensive experiments show that GraphMAE2 can consistently generate top results on various public datasets, including at least 2.45% improvements over state-of-the-art baselines on ogbn-Papers100M with 111M nodes and 1.6B edges.
Modeling Relational Patterns for Logical Query Answering over Knowledge Graphs
Mar 21, 2023Answering first-order logical (FOL) queries over knowledge graphs (KG) remains a challenging task mainly due to KG incompleteness. Query embedding approaches this problem by computing the low-dimensional vector representations of entities, relations, and logical queries. KGs exhibit relational patterns such as symmetry and composition and modeling the patterns can further enhance the performance of query embedding models. However, the role of such patterns in answering FOL queries by query embedding models has not been yet studied in the literature. In this paper, we fill in this research gap and empower FOL queries reasoning with pattern inference by introducing an inductive bias that allows for learning relation patterns. To this end, we develop a novel query embedding method, RoConE, that defines query regions as geometric cones and algebraic query operators by rotations in complex space. RoConE combines the advantages of Cone as a well-specified geometric representation for query embedding, and also the rotation operator as a powerful algebraic operation for pattern inference. Our experimental results on several benchmark datasets confirm the advantage of relational patterns for enhancing logical query answering task.
Towards Ontology Reshaping for KG Generation with User-in-the-Loop: Applied to Bosch Welding
Sep 22, 2022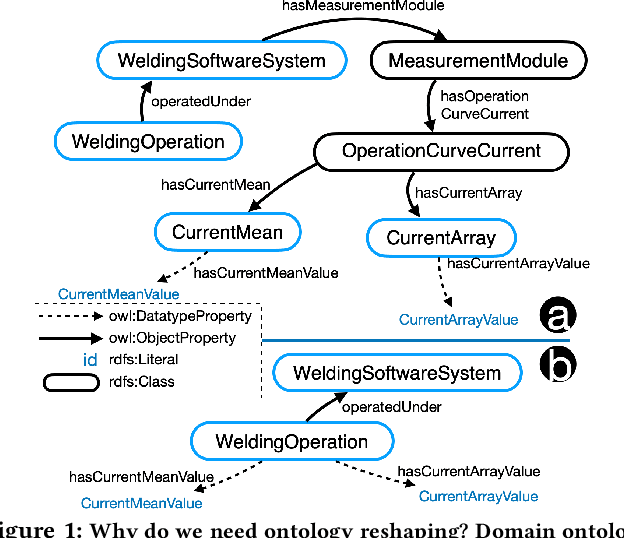
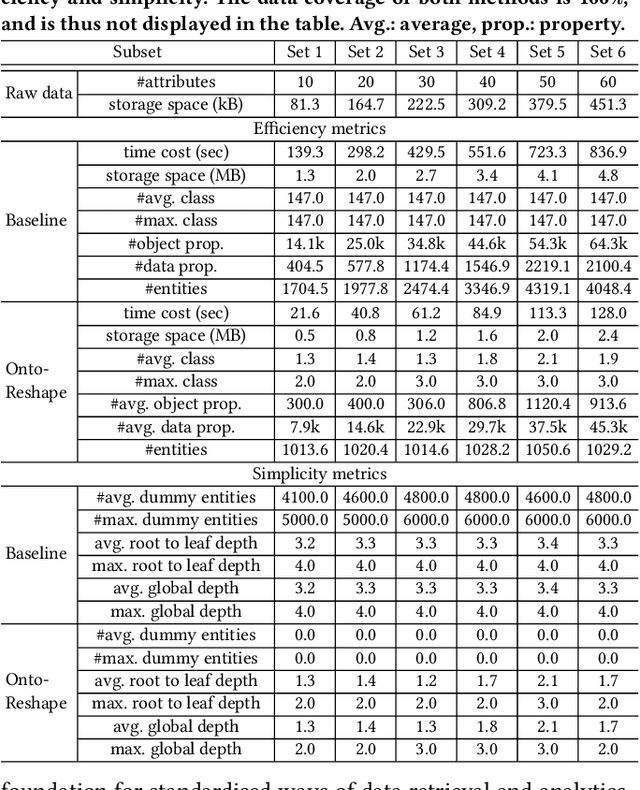
Knowledge graphs (KG) are used in a wide range of applications. The automation of KG generation is very desired due to the data volume and variety in industries. One important approach of KG generation is to map the raw data to a given KG schema, namely a domain ontology, and construct the entities and properties according to the ontology. However, the automatic generation of such ontology is demanding and existing solutions are often not satisfactory. An important challenge is a trade-off between two principles of ontology engineering: knowledge-orientation and data-orientation. The former one prescribes that an ontology should model the general knowledge of a domain, while the latter one emphasises on reflecting the data specificities to ensure good usability. We address this challenge by our method of ontology reshaping, which automates the process of converting a given domain ontology to a smaller ontology that serves as the KG schema. The domain ontology can be designed to be knowledge-oriented and the KG schema covers the data specificities. In addition, our approach allows the option of including user preferences in the loop. We demonstrate our on-going research on ontology reshaping and present an evaluation using real industrial data, with promising results.