 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Part Boundaries from 3D Point Clouds
Jul 15, 2020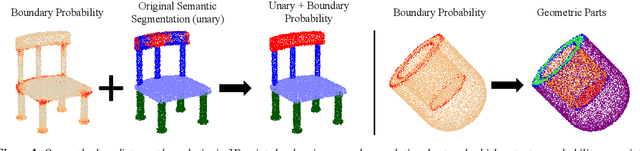
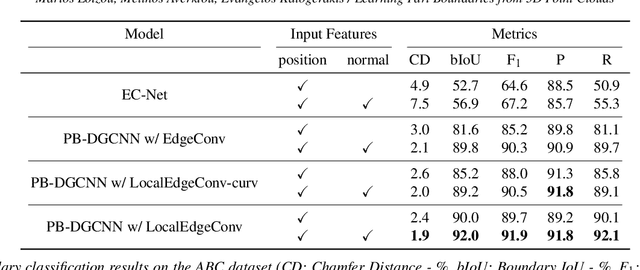
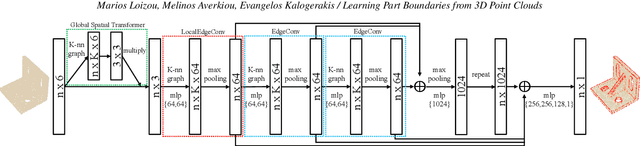
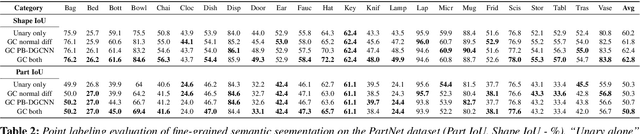
We present a method that detects boundaries of parts in 3D shapes represented as point clouds. Our method is based on a graph convolutional network architecture that outputs a probability for a point to lie in an area that separates two or more parts in a 3D shape. Our boundary detector is quite generic: it can be trained to localize boundaries of semantic parts or geometric primitives commonly used in 3D modeling. Our experiments demonstrate that our method can extract more accurate boundaries that are closer to ground-truth ones compared to alternatives. We also demonstrate an application of our network to fine-grained semantic shape segmentation, where we also show improvements in terms of part labeling performance.
RigNet: Neural Rigging for Articulated Characters
May 01, 2020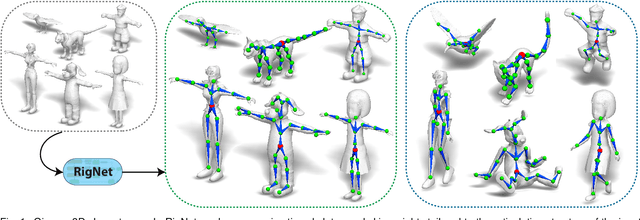
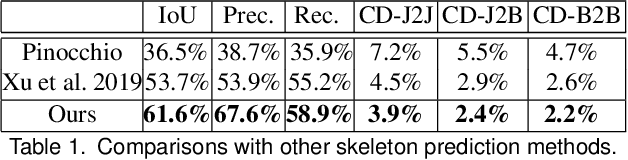
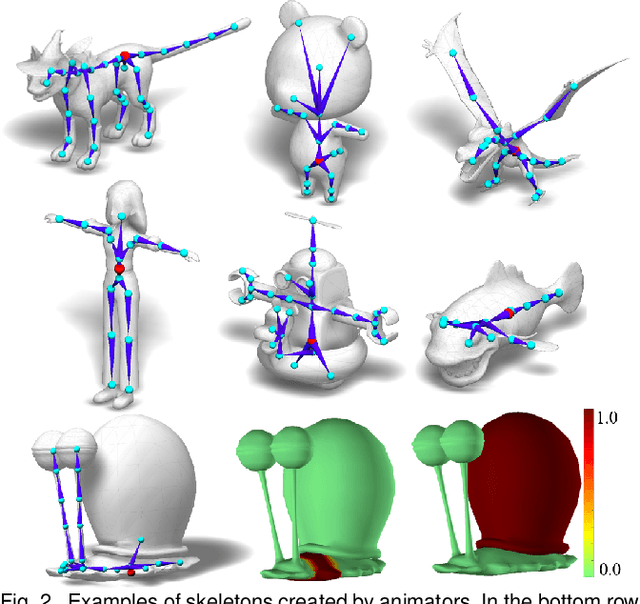
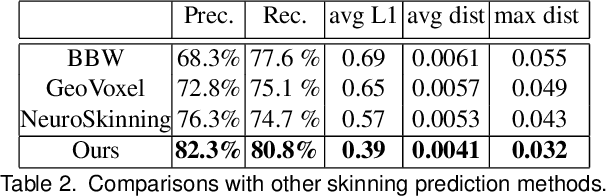
We present RigNet, an end-to-end automated method for producing animation rigs from input character models. Given an input 3D model representing an articulated character, RigNet predicts a skeleton that matches the animator expectations in joint placement and topology. It also estimates surface skin weights based on the predicted skeleton. Our method is based on a deep architecture that directly operates on the mesh representation without making assumptions on shape class and structure. The architecture is trained on a large and diverse collection of rigged models, including their mesh, skeletons and corresponding skin weights. Our evaluation is three-fold: we show better results than prior art when quantitatively compared to animator rigs; qualitatively we show that our rigs can be expressively posed and animated at multiple levels of detail; and finally, we evaluate the impact of various algorithm choices on our output rigs.
MakeItTalk: Speaker-Aware Talking-Head Animation
Apr 27, 2020



We present a method that generates expressive talking heads from a single facial image with audio as the only input. In contrast to previous approaches that attempt to learn direct mappings from audio to raw pixels or points for creating talking faces, our method first disentangles the content and speaker information in the input audio signal. The audio content robustly controls the motion of lips and nearby facial regions, while the speaker information determines the specifics of facial expressions and the rest of the talking head dynamics. Another key component of our method is the prediction of facial landmarks reflecting speaker-aware dynamics. Based on this intermediate representation, our method is able to synthesize photorealistic videos of entire talking heads with full range of motion and also animate artistic paintings, sketches, 2D cartoon characters, Japanese mangas, stylized caricatures in a single unified framework. We present extensive quantitative and qualitative evaluation of our method, in addition to user studies, demonstrating generated talking heads of significantly higher quality compared to prior state-of-the-art.
ParSeNet: A Parametric Surface Fitting Network for 3D Point Clouds
Apr 07, 2020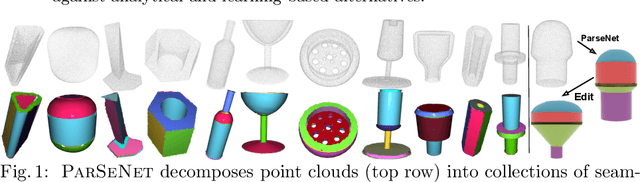
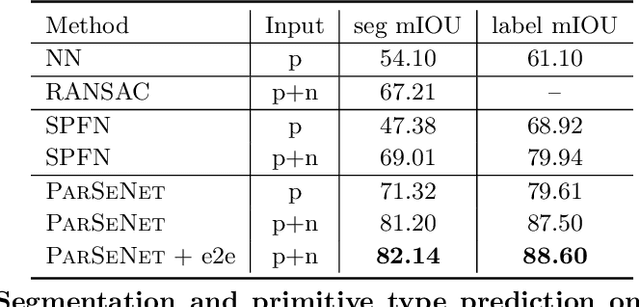
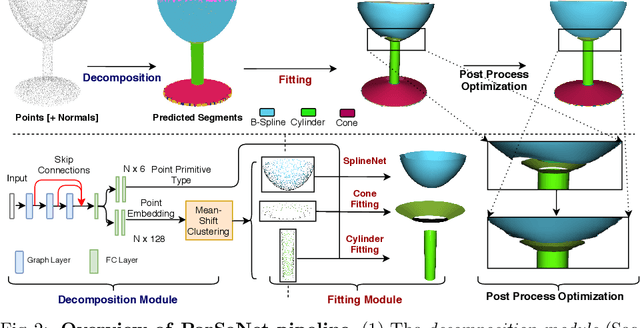
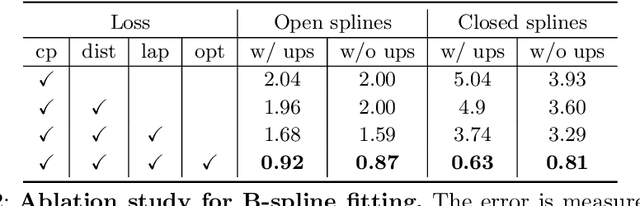
We propose a novel, end-to-end trainable, deep network called ParSeNet that decomposes a 3D point cloud into parametric surface patches, including B-spline patches as well as basic geometric primitives. ParSeNet is trained on a large-scale dataset of man-made 3D shapes and captures high-level semantic priors for shape decomposition. It handles a much richer class of primitives than prior work, and allows us to represent surfaces with higher fidelity. It also produces repeatable and robust parametrizations of a surface compared to purely geometric approaches. We present extensive experiments to validate our approach against analytical and learning-based alternatives.
Cross-Shape Graph Convolutional Networks
Apr 06, 2020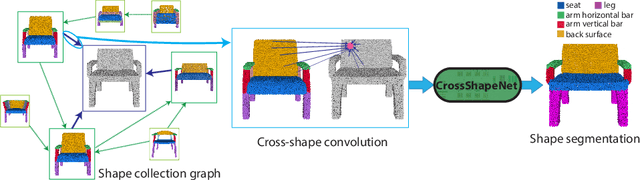



We present a method that processes 3D point clouds by performing graph convolution operations across shapes. In this manner, point descriptors are learned by allowing interaction and propagation of feature representations within a shape collection. To enable this form of non-local, cross-shape graph convolution, our method learns a pairwise point attention mechanism indicating the degree of interaction between points on different shapes. Our method also learns to create a graph over shapes of an input collection whose edges connect shapes deemed as useful for performing cross-shape convolution. The edges are also equipped with learned weights indicating the compatibility of each shape pair for cross-shape convolution. Our experiments demonstrate that this interaction and propagation of point representations across shapes make them more discriminative. In particular, our results show significantly improved performance for 3D point cloud semantic segmentation compared to conventional approaches, especially in cases with the limited number of training examples.
Neural Contours: Learning to Draw Lines from 3D Shapes
Apr 05, 2020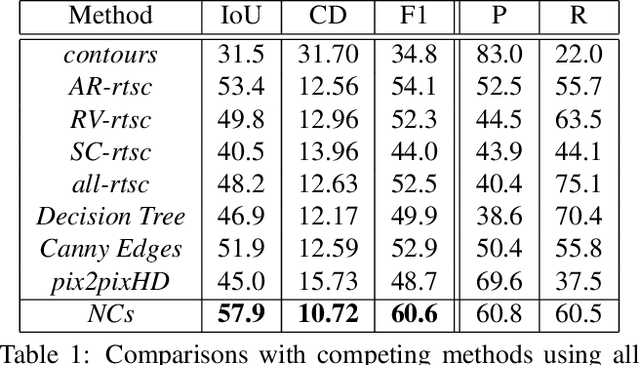
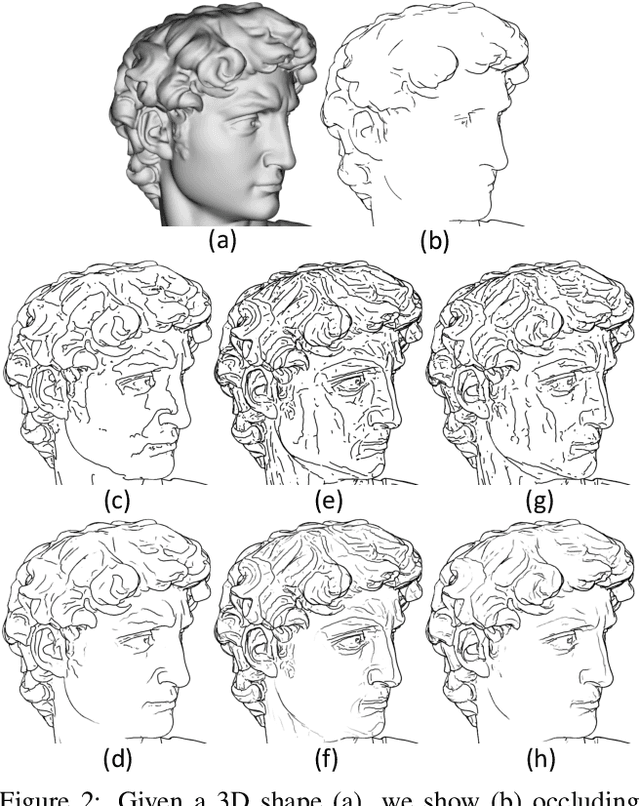
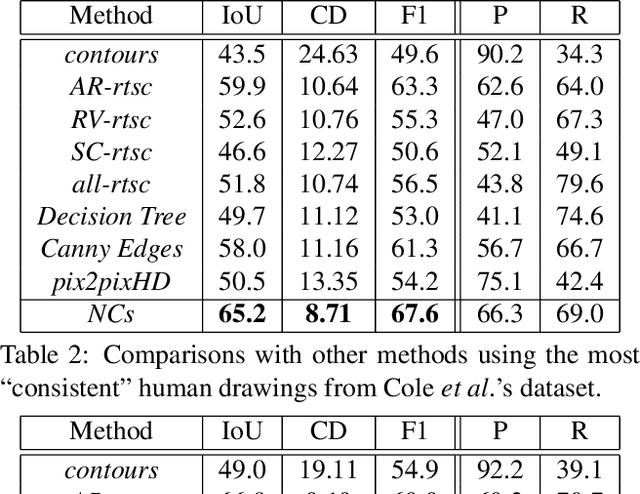
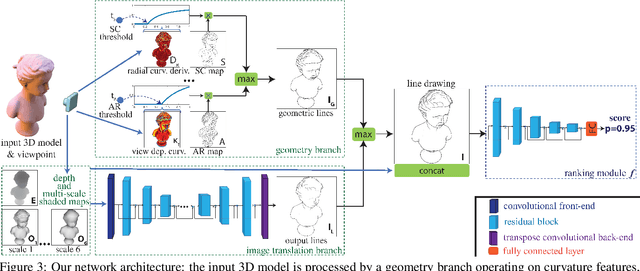
This paper introduces a method for learning to generate line drawings from 3D models. Our architecture incorporates a differentiable module operating on geometric features of the 3D model, and an image-based module operating on view-based shape representations. At test time, geometric and view-based reasoning are combined with the help of a neural module to create a line drawing. The model is trained on a large number of crowdsourced comparisons of line drawings. Experiments demonstrate that our method achieves significant improvements in line drawing over the state-of-the-art when evaluated on standard benchmarks, resulting in drawings that are comparable to those produced by experienced human artists.
Label-Efficient Learning on Point Clouds using Approximate Convex Decompositions
Mar 30, 2020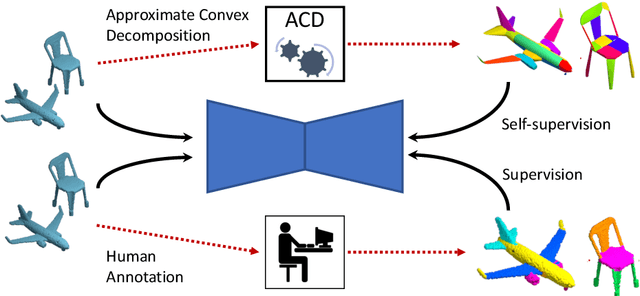
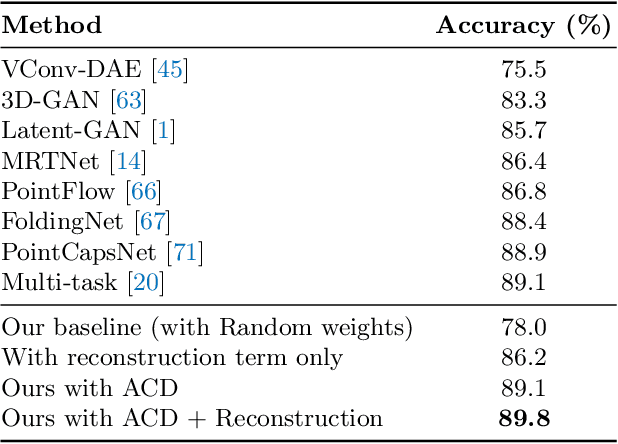


The problems of shape classification and part segmentation from 3D point clouds have garnered increasing attention in the last few years. But both of these problems suffer from relatively small training sets, creating the need for statistically efficient methods to learn 3D shape representations. In this work, we investigate the use of Approximate Convex Decompositions (ACD) as a self-supervisory signal for label-efficient learning of point cloud representations. Decomposing a 3D shape into simpler constituent parts or primitives is a fundamental problem in geometrical shape processing. There has been extensive work on such decompositions, where the criterion for simplicity of a constituent shape is often defined in terms of convexity for solid primitives. In this paper, we show that using the results of ACD to approximate a ground truth segmentation provides excellent self-supervision for learning 3D point cloud representations that are highly effective on downstream tasks. We report improvements over the state-of-theart in unsupervised representation learning on the ModelNet40 shape classification dataset and significant gains in few-shot part segmentation on the ShapeNetPart dataset. Code available at https://github.com/matheusgadelha/PointCloudLearningACD
Neural Shape Parsers for Constructive Solid Geometry
Dec 22, 2019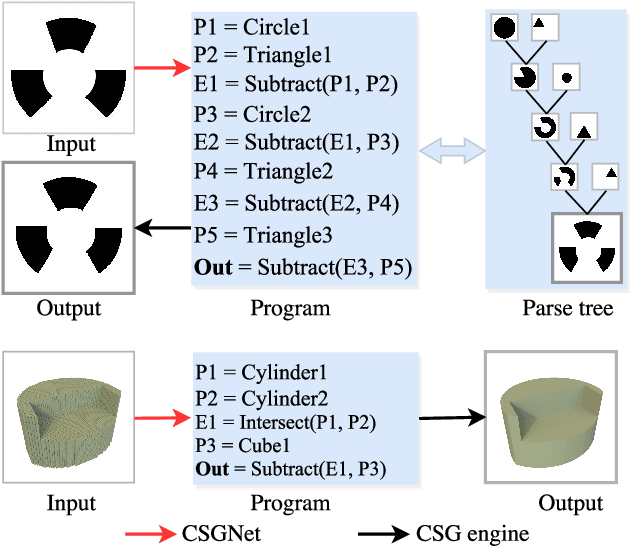
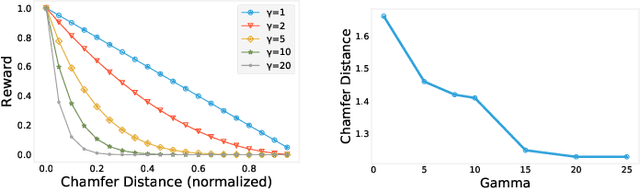
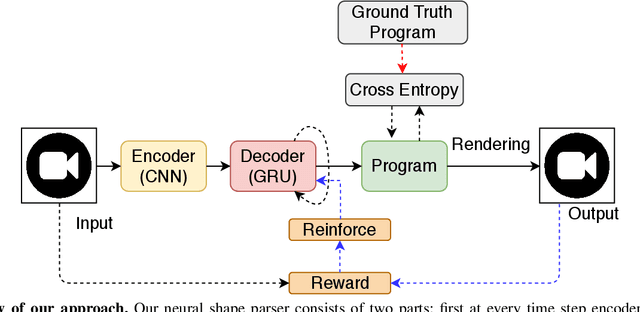
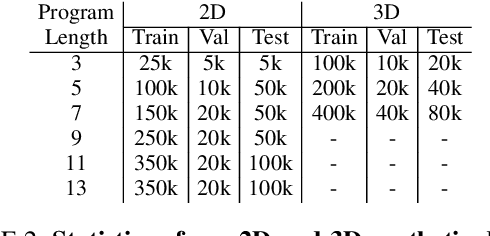
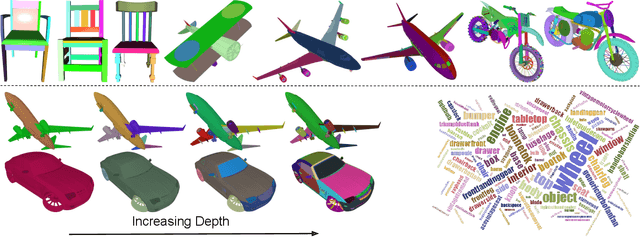
Constructive Solid Geometry (CSG) is a geometric modeling technique that defines complex shapes by recursively applying boolean operations on primitives such as spheres and cylinders. We present CSGNe, a deep network architecture that takes as input a 2D or 3D shape and outputs a CSG program that models it. Parsing shapes into CSG programs is desirable as it yields a compact and interpretable generative model. However, the task is challenging since the space of primitives and their combinations can be prohibitively large. CSGNe uses a convolutional encoder and recurrent decoder based on deep networks to map shapes to modeling instructions in a feed-forward manner and is significantly faster than bottom-up approaches. We investigate two architectures for this task --- a vanilla encoder (CNN) - decoder (RNN) and another architecture that augments the encoder with an explicit memory module based on the program execution stack. The stack augmentation improves the reconstruction quality of the generated shape and learning efficiency. Our approach is also more effective as a shape primitive detector compared to a state-of-the-art object detector. Finally, we demonstrate CSGNet can be trained on novel datasets without program annotations through policy gradient techniques.
Learning Point Embeddings from Shape Repositories for Few-Shot Segmentation
Oct 03, 2019


User generated 3D shapes in online repositories contain rich information about surfaces, primitives, and their geometric relations, often arranged in a hierarchy. We present a framework for learning representations of 3D shapes that reflect the information present in this meta data and show that it leads to improved generalization for semantic segmentation tasks. Our approach is a point embedding network that generates a vectorial representation of the 3D points such that it reflects the grouping hierarchy and tag data. The main challenge is that the data is noisy and highly variable. To this end, we present a tree-aware metric-learning approach and demonstrate that such learned embeddings offer excellent transfer to semantic segmentation tasks, especially when training data is limited. Our approach reduces the relative error by $10.2\%$ with $8$ training examples, by $11.72\%$ with $120$ training examples on the ShapeNet semantic segmentation benchmark, in comparison to the network trained from scratch. By utilizing tag data the relative error is reduced by $12.8\%$ with $8$ training examples, in comparison to the network trained from scratch. These improvements come at no additional labeling cost as the meta data is freely available.
Predicting Animation Skeletons for 3D Articulated Models via Volumetric Nets
Aug 22, 2019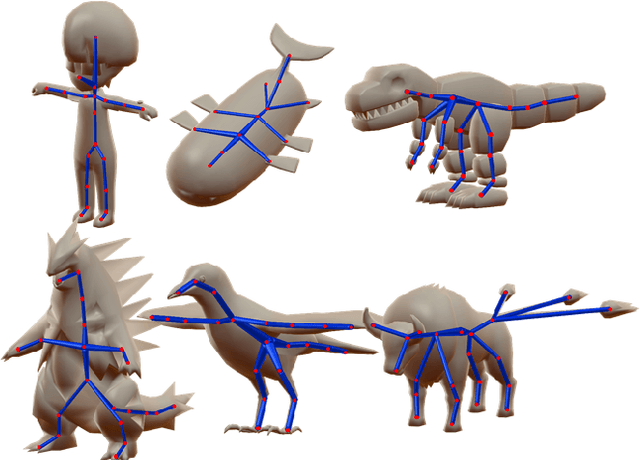

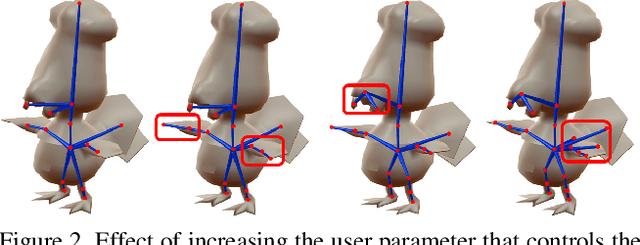
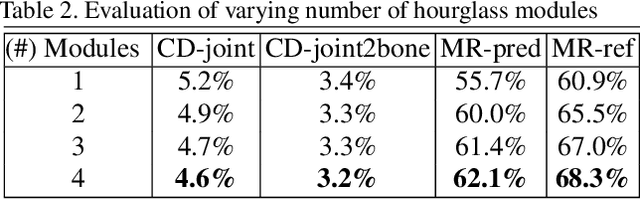
We present a learning method for predicting animation skeletons for input 3D models of articulated characters. In contrast to previous approaches that fit pre-defined skeleton templates or predict fixed sets of joints, our method produces an animation skeleton tailored for the structure and geometry of the input 3D model. Our architecture is based on a stack of hourglass modules trained on a large dataset of 3D rigged characters mined from the web. It operates on the volumetric representation of the input 3D shapes augmented with geometric shape features that provide additional cues for joint and bone locations. Our method also enables intuitive user control of the level-of-detail for the output skeleton. Our evaluation demonstrates that our approach predicts animation skeletons that are much more similar to the ones created by humans compared to several alternatives and baselines.