 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Warrant Gap: Claim-Conditioned Re-scoring for Fact-Checking
Jun 23, 2026Fact-checking systems built on LLMs achieve high verdict accuracy on standard benchmarks, yet routinely output Supports labels whose cited evidence does not license the claim. Structured decomposition is the natural way to inspect those warrants, but rigid extraction protocols strip the full-claim context that facets need. We introduce SIFT -- claim-conditioned re-scoring of extracted evidence spans against the full claim -- paired with WSP (Warranted Supports Proportion), an automatic NLI check that the cited warrant entails the claim. We evaluate on FEVER, SciFact, 5PILS, and DP across four open-source backbones. SIFT recovers accuracy on cells where naive decomposition costs up to 27.6 points, while raising WSP above direct prompting; WSP itself calibrates against human gold evidence at AUC 0.92 and precision 0.98.
Image-text matching for large-scale book collections
Jul 29, 2024



We address the problem of detecting and mapping all books in a collection of images to entries in a given book catalogue. Instead of performing independent retrieval for each book detected, we treat the image-text mapping problem as a many-to-many matching process, looking for the best overall match between the two sets. We combine a state-of-the-art segmentation method (SAM) to detect book spines and extract book information using a commercial OCR. We then propose a two-stage approach for text-image matching, where CLIP embeddings are used first for fast matching, followed by a second slower stage to refine the matching, employing either the Hungarian Algorithm or a BERT-based model trained to cope with noisy OCR input and partial text matches. To evaluate our approach, we publish a new dataset of annotated bookshelf images that covers the whole book collection of a public library in Spain. In addition, we provide two target lists of book metadata, a closed-set of 15k book titles that corresponds to the known library inventory, and an open-set of 2.3M book titles to simulate an open-world scenario. We report results on two settings, on one hand on a matching-only task, where the book segments and OCR is given and the objective is to perform many-to-many matching against the target lists, and a combined detection and matching task, where books must be first detected and recognised before they are matched to the target list entries. We show that both the Hungarian Matching and the proposed BERT-based model outperform a fuzzy string matching baseline, and we highlight inherent limitations of the matching algorithms as the target increases in size, and when either of the two sets (detected books or target book list) is incomplete. The dataset and code are available at https://github.com/llabres/library-dataset
External Knowledge Augmented Text Visual Question Answering
Aug 22, 2021
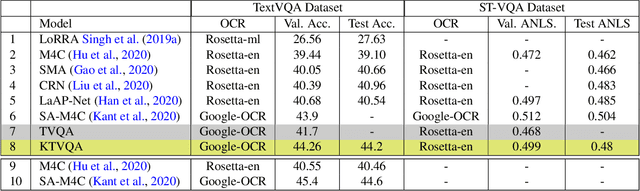
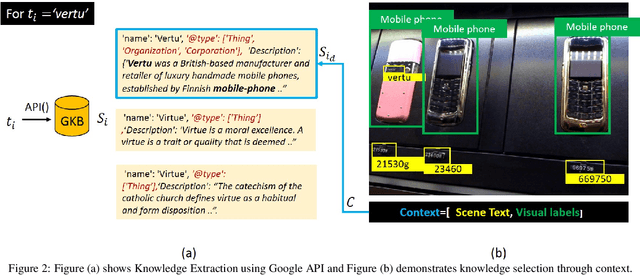
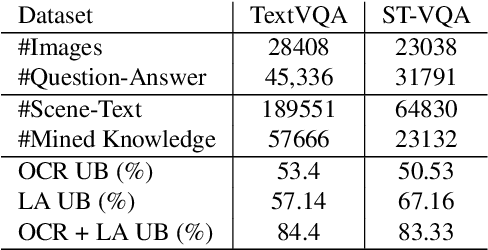
The open-ended question answering task of Text-VQA requires reading and reasoning about local, often previously unseen, scene-text content of an image to generate answers. In this work, we propose the generalized use of external knowledge to augment our understanding of the said scene-text. We design a framework to extract, filter, and encode knowledge atop a standard multimodal transformer for vision language understanding tasks. Through empirical evidence, we demonstrate how knowledge can highlight instance-only cues and thus help deal with training data bias, improve answer entity type correctness, and detect multiword named entities. We generate results comparable to the state-of-the-art on two publicly available datasets, under the constraints of similar upstream OCR systems and training data.
Beyond Visual Semantics: Exploring the Role of Scene Text in Image Understanding
May 25, 2019
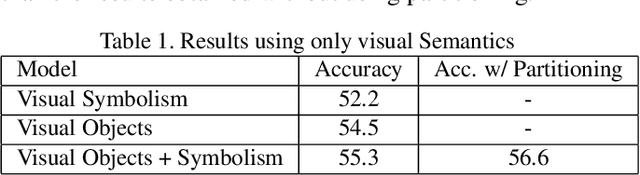
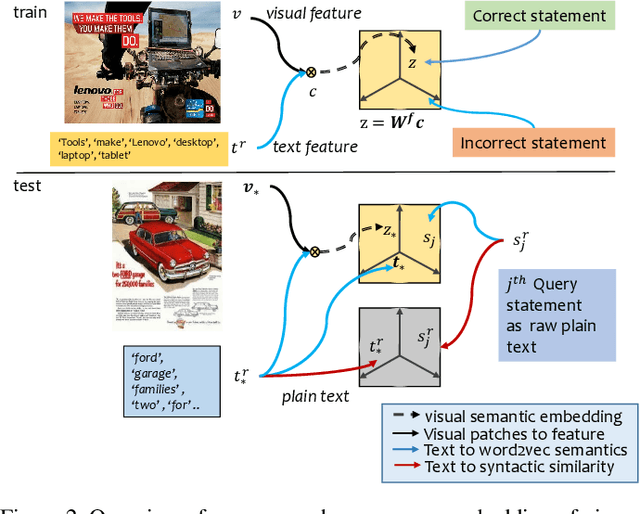

Images with visual and scene text content are ubiquitous in everyday life. However current image interpretation systems are mostly limited to using only the visual features, neglecting to leverage the scene text content. In this paper we propose to jointly use scene text and visual channels for robust semantic interpretation of images. We undertake the task of matching Advertisement images against their human generated statements that describe the action that the ad prompts and the rationale it provides for taking this action. We extract the scene text and generate semantic and lexical text representations, which are used in the interpretation of the Ad Image. To deal with irrelevant or erroneous detection of scene text, we use a text attention scheme. We also learn an embedding of the visual channel,\ie visual features based on detected symbolism and objects, into a semantic embedding space, leveraging text semantics obtained from scene text. We show how the multi channel approach, involving visual semantics and scene text, improves upon the current state of the art.