 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sample-Specific Models with Low-Rank Personalized Regression
Oct 15, 2019
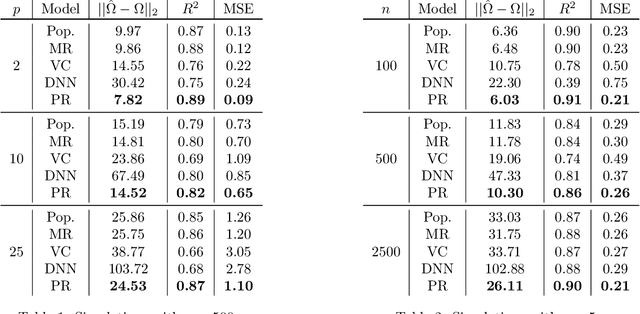
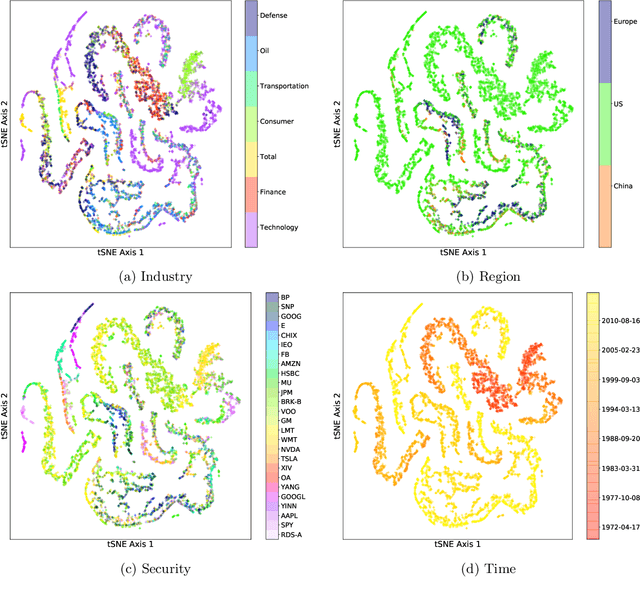
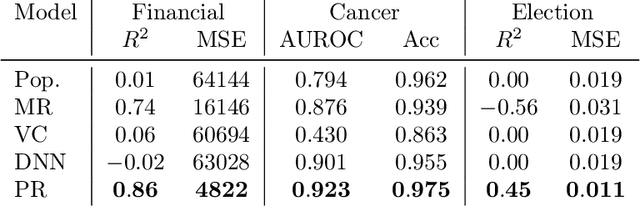
Modern applications of machine learning (ML) deal with increasingly heterogeneous datasets comprised of data collected from overlapping latent subpopulations. As a result, traditional models trained over large datasets may fail to recognize highly predictive localized effects in favour of weakly predictive global patterns. This is a problem because localized effects are critical to developing individualized policies and treatment plans in applications ranging from precision medicine to advertising. To address this challenge, we propose to estimate sample-specific models that tailor inference and prediction at the individual level. In contrast to classical ML models that estimate a single, complex model (or only a few complex models), our approach produces a model personalized to each sample. These sample-specific models can be studied to understand subgroup dynamics that go beyond coarse-grained class labels. Crucially, our approach does not assume that relationships between samples (e.g. a similarity network) are known a priori. Instead, we use unmodeled covariates to learn a latent distance metric over the samples. We apply this approach to financial, biomedical, and electoral data as well as simulated data and show that sample-specific models provide fine-grained interpretations of complicated phenomena without sacrificing predictive accuracy compared to state-of-the-art models such as deep neural networks.
Learning Sparse Nonparametric DAGs
Sep 29, 2019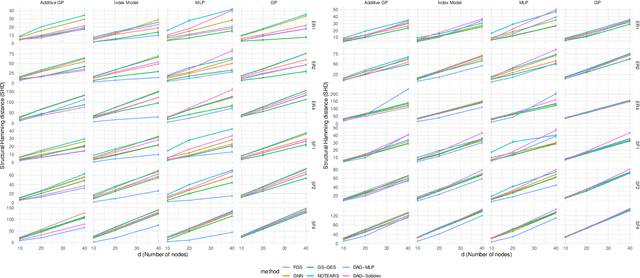


We develop a framework for learning sparse nonparametric directed acyclic graphs (DAGs) from data. Our approach is based on a recent algebraic characterization of DAGs that led to the first fully continuous optimization for score-based learning of DAG models parametrized by a linear structural equation model (SEM). We extend this algebraic characterization to nonparametric SEM by leveraging nonparametric sparsity based on partial derivatives, resulting in a continuous optimization problem that can be applied to a variety of nonparametric and semiparametric models including GLMs, additive noise models, and index models as special cases. We also explore the use of neural networks and orthogonal basis expansions to model nonlinearities for general nonparametric models. Extensive empirical study confirms the necessity of nonlinear dependency and the advantage of continuous optimization for score-based learning.
ChemBO: Bayesian Optimization of Small Organic Molecules with Synthesizable Recommendations
Aug 05, 2019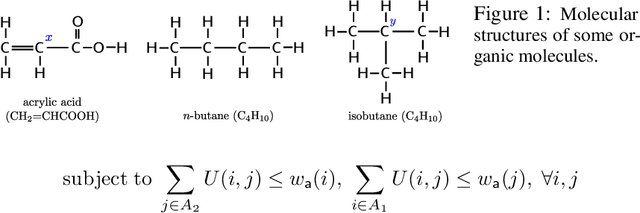

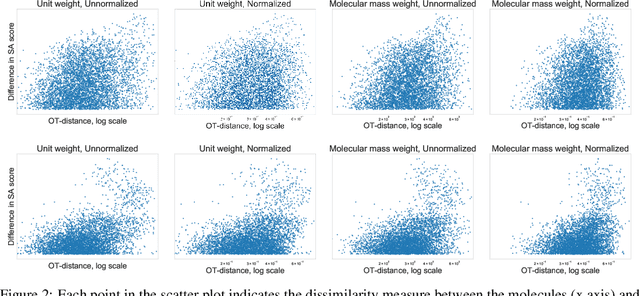
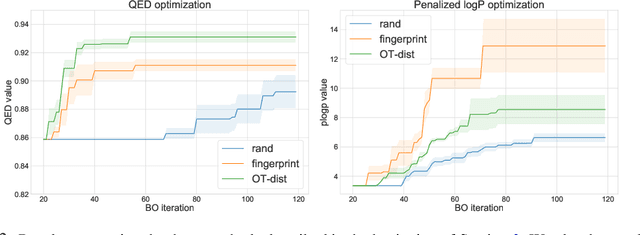
We describe ChemBO, a Bayesian Optimization framework for generating and optimizing organic molecules for desired molecular properties. This framework is useful in applications such as drug discovery, where an algorithm recommends new candidate molecules; these molecules first need to be synthesized and then tested for drug-like properties. The algorithm uses the results of past tests to recommend new ones so as to find good molecules efficiently. Most existing data-driven methods for this problem do not account for sample efficiency and/or fail to enforce realistic constraints on synthesizability. In this work, we explore existing kernels for molecules in the literature as well as propose a novel kernel which views a molecule as a graph. In ChemBO, we implement these kernels in a Gaussian process model. Then we explore the chemical space by traversing possible paths of molecular synthesis. Consequently, our approach provides a proposal synthesis path every time it recommends a new molecule to test, a crucial advantage when compared to existing methods. In our experiments, we demonstrate the efficacy of the proposed approach on several molecular optimization problems.
Target-Guided Open-Domain Conversation
May 29, 2019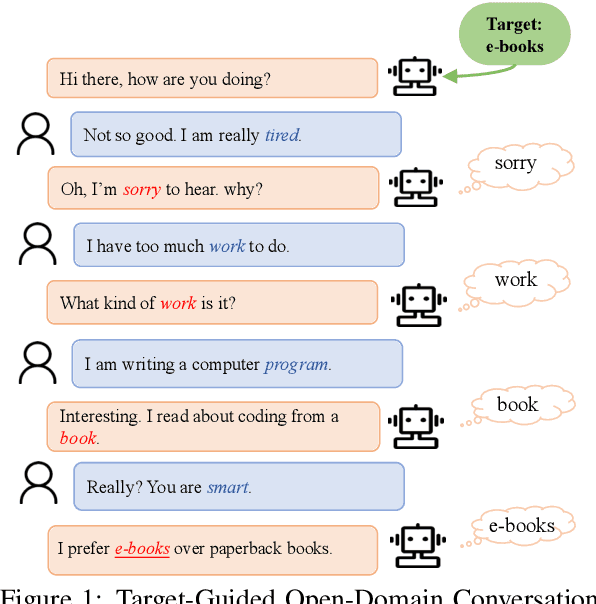
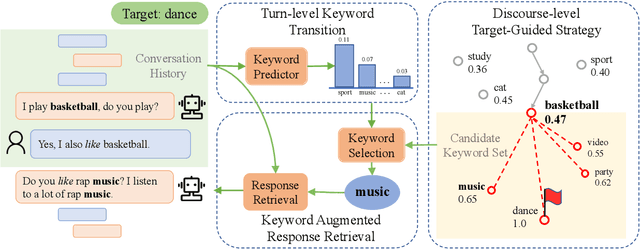

Many real-world open-domain conversation applications have specific goals to achieve during open-ended chats, such as recommendation, psychotherapy, education, etc. We study the problem of imposing conversational goals on open-domain chat agents. In particular, we want a conversational system to chat naturally with human and proactively guide the conversation to a designated target subject. The problem is challenging as no public data is available for learning such a target-guided strategy. We propose a structured approach that introduces coarse-grained keywords to control the intended content of system responses. We then attain smooth conversation transition through turn-level supervised learning, and drive the conversation towards the target with discourse-level constraints. We further derive a keyword-augmented conversation dataset for the study. Quantitative and human evaluations show our system can produce meaningful and effective conversations, significantly improving over other approaches.
Learning Robust Global Representations by Penalizing Local Predictive Power
May 29, 2019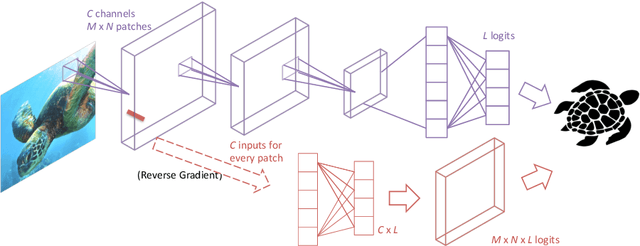

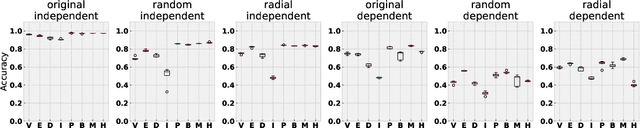
Despite their renowned predictive power on i.i.d. data, convolutional neural networks are known to rely more on high-frequency patterns that humans deem superficial than on low-frequency patterns that agree better with intuitions about what constitutes category membership. This paper proposes a method for training robust convolutional networks by penalizing the predictive power of the local representations learned by earlier layers. Intuitively, our networks are forced to discard predictive signals such as color and texture that can be gleaned from local receptive fields and to rely instead on the global structures of the image. Across a battery of synthetic and benchmark domain adaptation tasks, our method confers improved generalization out of the domain. Also, to evaluate cross-domain transfer, we introduce ImageNet-Sketch, a new dataset consisting of sketch-like images, that matches the ImageNet classification validation set in categories and scale.
High Frequency Component Helps Explain the Generalization of Convolutional Neural Networks
May 28, 2019
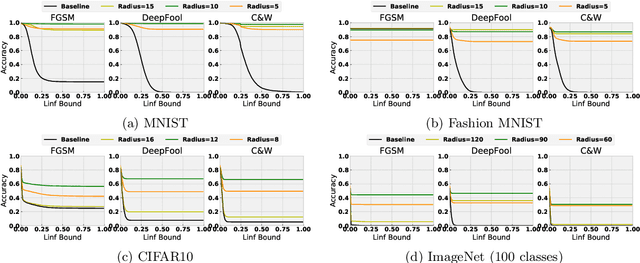
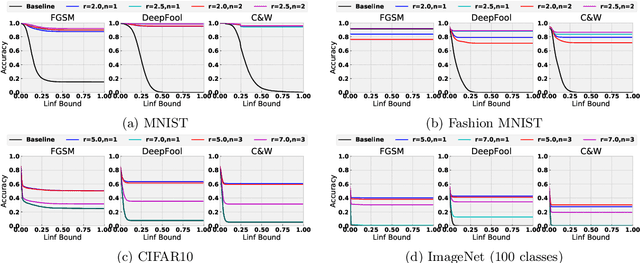
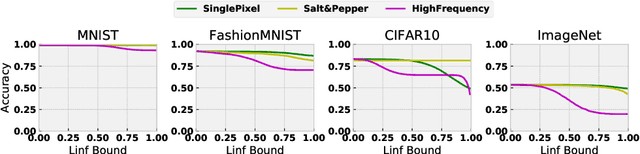
We investigate the relationship between the frequency spectrum of image data and the generalization behavior of convolutional neural networks (CNN). We first notice CNN's ability in capturing the high-frequency components of images. These high-frequency components are almost imperceptible to a human. Thus the observation can serve as one of the explanations of the existence of adversarial examples, and can also help verify CNN's trade-off between robustness and accuracy. Our observation also immediately leads to methods that can improve the adversarial robustness of trained CNN. Finally, we also utilize this observation to design a (semi) black-box adversarial attack method.
Adversarial Domain Adaptation Being Aware of Class Relationships
May 28, 2019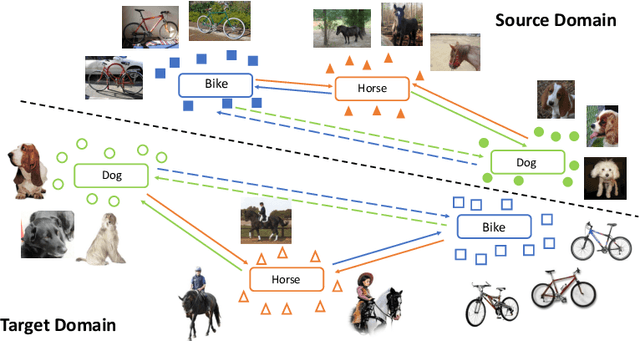
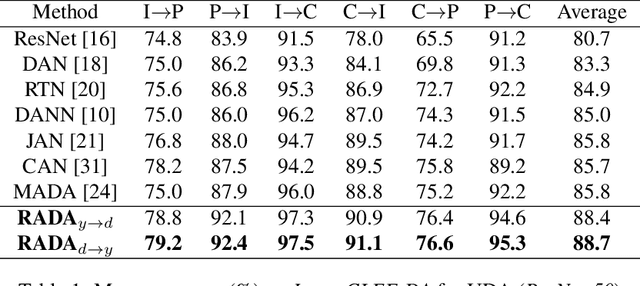
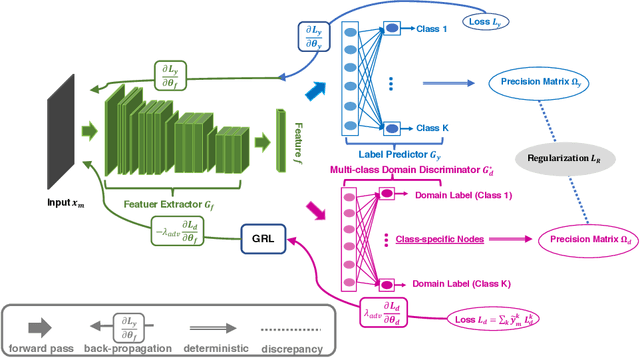
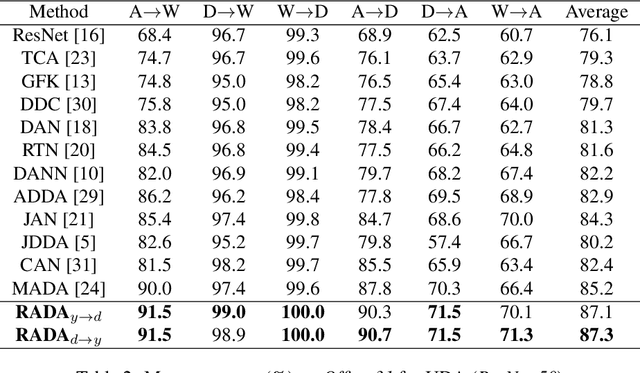
Adversarial training is a useful approach to promote the learning of transferable representations across the source and target domains, which has been widely applied for domain adaptation (DA) tasks based on deep neural networks. Until very recently, existing adversarial domain adaptation (ADA) methods ignore the useful information from the label space, which is an important factor accountable for the complicated data distributions associated with different semantic classes. Especially, the inter-class semantic relationships have been rarely considered and discussed in the current work of transfer learning. In this paper, we propose a novel relationship-aware adversarial domain adaptation (RADA) algorithm, which first utilizes a single multi-class domain discriminator to enforce the learning of inter-class dependency structure during domain-adversarial training and then aligns this structure with the inter-class dependencies that are characterized from training the label predictor on the source domain. Specifically, we impose a regularization term to penalize the structure discrepancy between the inter-class dependencies respectively estimated from domain discriminator and label predictor. Through this alignment, our proposed method makes the ADA aware of class relationships. Empirical studies show that the incorporation of class relationships significantly improves the performance on benchmark datasets.
Knowledge-driven Encode, Retrieve, Paraphrase for Medical Image Report Generation
Mar 25, 2019
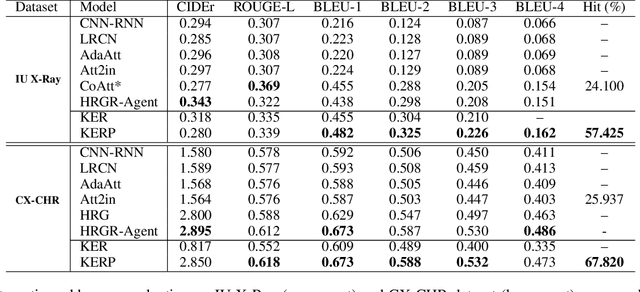
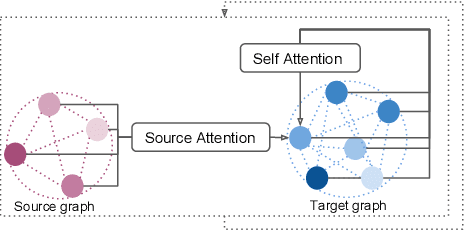
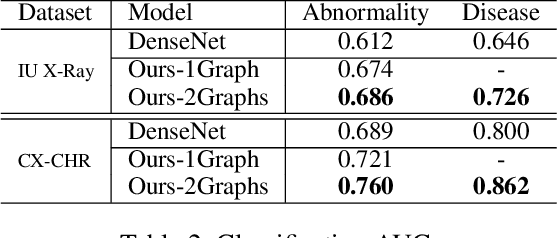
Generating long and semantic-coherent reports to describe medical images poses great challenges towards bridging visual and linguistic modalities, incorporating medical domain knowledge, and generating realistic and accurate descriptions. We propose a novel Knowledge-driven Encode, Retrieve, Paraphrase (KERP) approach which reconciles traditional knowledge- and retrieval-based methods with modern learning-based methods for accurate and robust medical report generation. Specifically, KERP decomposes medical report generation into explicit medical abnormality graph learning and subsequent natural language modeling. KERP first employs an Encode module that transforms visual features into a structured abnormality graph by incorporating prior medical knowledge; then a Retrieve module that retrieves text templates based on the detected abnormalities; and lastly, a Paraphrase module that rewrites the templates according to specific cases. The core of KERP is a proposed generic implementation unit---Graph Transformer (GTR) that dynamically transforms high-level semantics between graph-structured data of multiple domains such as knowledge graphs, images and sequences. Experiments show that the proposed approach generates structured and robust reports supported with accurate abnormality description and explainable attentive regions, achieving the state-of-the-art results on two medical report benchmarks, with the best medical abnormality and disease classification accuracy and improved human evaluation performance.
Tuning Hyperparameters without Grad Students: Scalable and Robust Bayesian Optimisation with Dragonfly
Mar 15, 2019
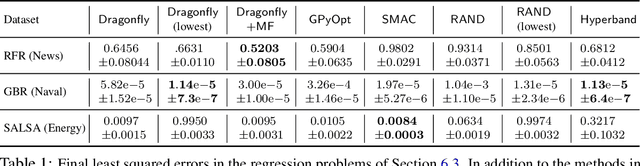
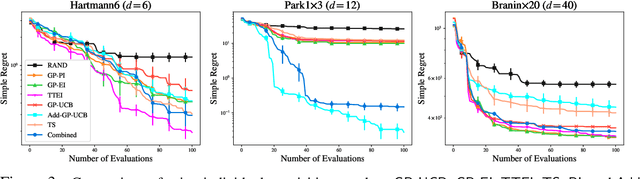
Bayesian Optimisation (BO), refers to a suite of techniques for global optimisation of expensive black box functions, which use introspective Bayesian models of the function to efficiently find the optimum. While BO has been applied successfully in many applications, modern optimisation tasks usher in new challenges where conventional methods fail spectacularly. In this work, we present Dragonfly, an open source Python library for scalable and robust BO. Dragonfly incorporates multiple recently developed methods that allow BO to be applied in challenging real world settings; these include better methods for handling higher dimensional domains, methods for handling multi-fidelity evaluations when cheap approximations of an expensive function are available, methods for optimising over structured combinatorial spaces, such as the space of neural network architectures, and methods for handling parallel evaluations. Additionally, we develop new methodological improvements in BO for selecting the Bayesian model, selecting the acquisition function, and optimising over complex domains with different variable types and additional constraints. We compare Dragonfly to a suite of other packages and algorithms for global optimisation and demonstrate that when the above methods are integrated, they enable significant improvements in the performance of BO. The Dragonfly library is available at dragonfly.github.io.
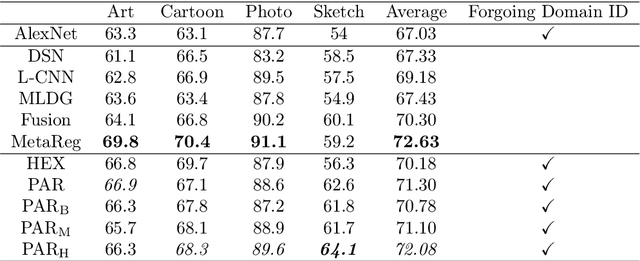
Learning Robust Representations by Projecting Superficial Statistics Out
Mar 02, 2019

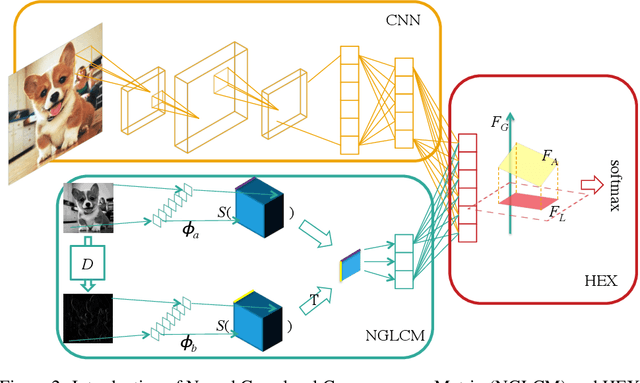

Despite impressive performance as evaluated on i.i.d. holdout data, deep neural networks depend heavily on superficial statistics of the training data and are liable to break under distribution shift. For example, subtle changes to the background or texture of an image can break a seemingly powerful classifier. Building on previous work on domain generalization, we hope to produce a classifier that will generalize to previously unseen domains, even when domain identifiers are not available during training. This setting is challenging because the model may extract many distribution-specific (superficial) signals together with distribution-agnostic (semantic) signals. To overcome this challenge, we incorporate the gray-level co-occurrence matrix (GLCM) to extract patterns that our prior knowledge suggests are superficial: they are sensitive to the texture but unable to capture the gestalt of an image. Then we introduce two techniques for improving our networks' out-of-sample performance. The first method is built on the reverse gradient method that pushes our model to learn representations from which the GLCM representation is not predictable. The second method is built on the independence introduced by projecting the model's representation onto the subspace orthogonal to GLCM representation's. We test our method on the battery of standard domain generalization data sets and, interestingly, achieve comparable or better performance as compared to other domain generalization methods that explicitly require samples from the target distribution for training.