 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Reuse and Compose Knowledge for a Lifetime of Tasks: A Survey on Continual Learning and Functional Composition
Jul 15, 2022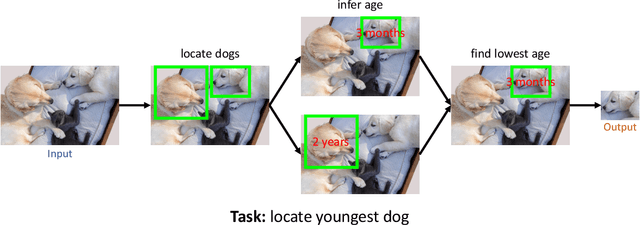

A major goal of artificial intelligence (AI) is to create an agent capable of acquiring a general understanding of the world. Such an agent would require the ability to continually accumulate and build upon its knowledge as it encounters new experiences. Lifelong or continual learning addresses this setting, whereby an agent faces a continual stream of problems and must strive to capture the knowledge necessary for solving each new task it encounters. If the agent is capable of accumulating knowledge in some form of compositional representation, it could then selectively reuse and combine relevant pieces of knowledge to construct novel solutions. Despite the intuitive appeal of this simple idea, the literatures on lifelong learning and compositional learning have proceeded largely separately. In an effort to promote developments that bridge between the two fields, this article surveys their respective research landscapes and discusses existing and future connections between them.
CompoSuite: A Compositional Reinforcement Learning Benchmark
Jul 08, 2022
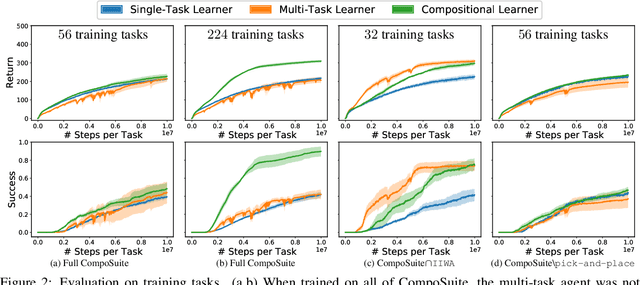
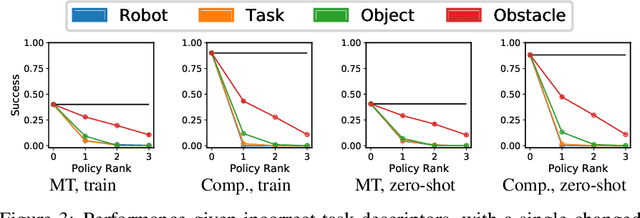

We present CompoSuite, an open-source simulated robotic manipulation benchmark for compositional multi-task reinforcement learning (RL). Each CompoSuite task requires a particular robot arm to manipulate one individual object to achieve a task objective while avoiding an obstacle. This compositional definition of the tasks endows CompoSuite with two remarkable properties. First, varying the robot/object/objective/obstacle elements leads to hundreds of RL tasks, each of which requires a meaningfully different behavior. Second, RL approaches can be evaluated specifically for their ability to learn the compositional structure of the tasks. This latter capability to functionally decompose problems would enable intelligent agents to identify and exploit commonalities between learning tasks to handle large varieties of highly diverse problems. We benchmark existing single-task, multi-task, and compositional learning algorithms on various training settings, and assess their capability to compositionally generalize to unseen tasks. Our evaluation exposes the shortcomings of existing RL approaches with respect to compositionality and opens new avenues for investigation.
Lifelong Inverse Reinforcement Learning
Jul 01, 2022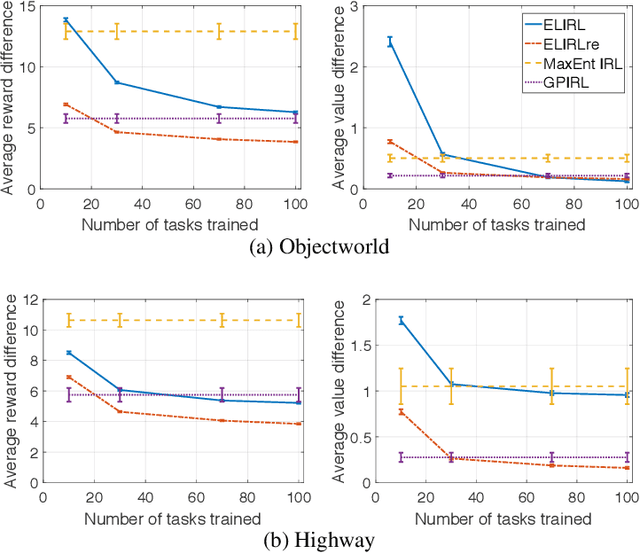

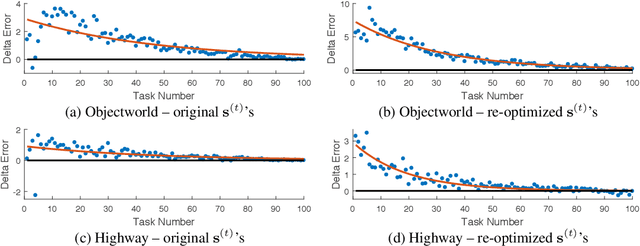
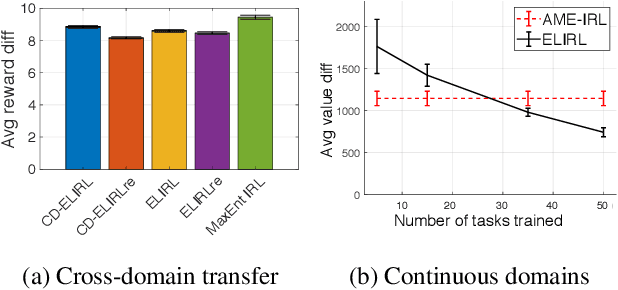
Methods for learning from demonstration (LfD) have shown success in acquiring behavior policies by imitating a user. However, even for a single task, LfD may require numerous demonstrations. For versatile agents that must learn many tasks via demonstration, this process would substantially burden the user if each task were learned in isolation. To address this challenge, we introduce the novel problem of lifelong learning from demonstration, which allows the agent to continually build upon knowledge learned from previously demonstrated tasks to accelerate the learning of new tasks, reducing the amount of demonstrations required. As one solution to this problem, we propose the first lifelong learning approach to inverse reinforcement learning, which learns consecutive tasks via demonstration, continually transferring knowledge between tasks to improve performance.
Modular Lifelong Reinforcement Learning via Neural Composition
Jul 01, 2022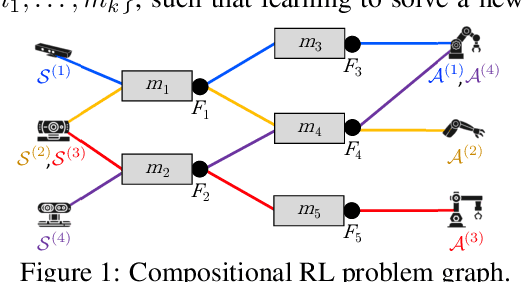
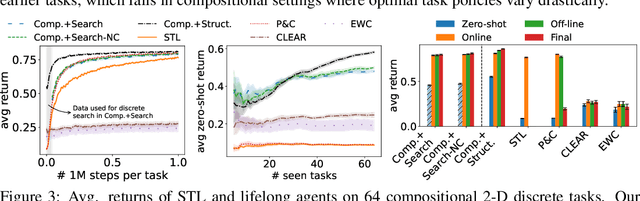
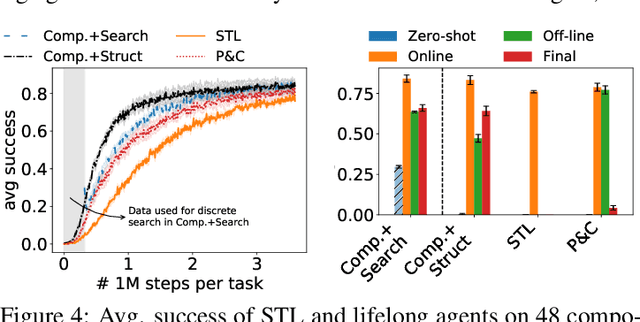

Humans commonly solve complex problems by decomposing them into easier subproblems and then combining the subproblem solutions. This type of compositional reasoning permits reuse of the subproblem solutions when tackling future tasks that share part of the underlying compositional structure. In a continual or lifelong reinforcement learning (RL) setting, this ability to decompose knowledge into reusable components would enable agents to quickly learn new RL tasks by leveraging accumulated compositional structures. We explore a particular form of composition based on neural modules and present a set of RL problems that intuitively admit compositional solutions. Empirically, we demonstrate that neural composition indeed captures the underlying structure of this space of problems. We further propose a compositional lifelong RL method that leverages accumulated neural components to accelerate the learning of future tasks while retaining performance on previous tasks via off-line RL over replayed experiences.
SHELS: Exclusive Feature Sets for Novelty Detection and Continual Learning Without Class Boundaries
Jun 28, 2022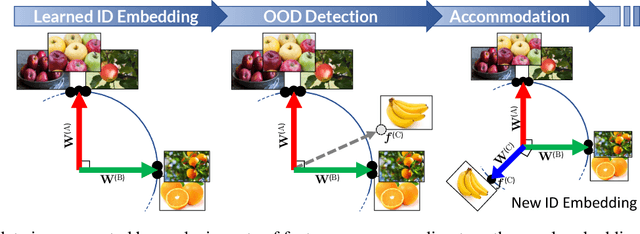
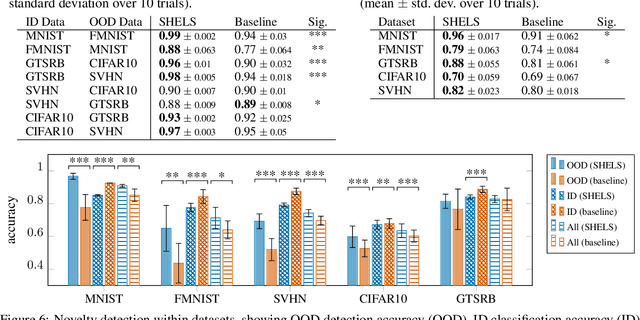
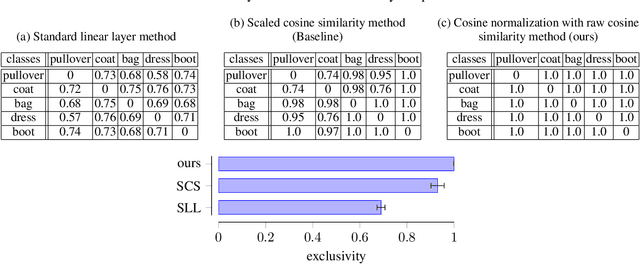
While deep neural networks (DNNs) have achieved impressive classification performance in closed-world learning scenarios, they typically fail to generalize to unseen categories in dynamic open-world environments, in which the number of concepts is unbounded. In contrast, human and animal learners have the ability to incrementally update their knowledge by recognizing and adapting to novel observations. In particular, humans characterize concepts via exclusive (unique) sets of essential features, which are used for both recognizing known classes and identifying novelty. Inspired by natural learners, we introduce a Sparse High-level-Exclusive, Low-level-Shared feature representation (SHELS) that simultaneously encourages learning exclusive sets of high-level features and essential, shared low-level features. The exclusivity of the high-level features enables the DNN to automatically detect out-of-distribution (OOD) data, while the efficient use of capacity via sparse low-level features permits accommodating new knowledge. The resulting approach uses OOD detection to perform class-incremental continual learning without known class boundaries. We show that using SHELS for novelty detection results in statistically significant improvements over state-of-the-art OOD detection approaches over a variety of benchmark datasets. Further, we demonstrate that the SHELS model mitigates catastrophic forgetting in a class-incremental learning setting,enabling a combined novelty detection and accommodation framework that supports learning in open-world settings
Gap Minimization for Knowledge Sharing and Transfer
Jan 26, 2022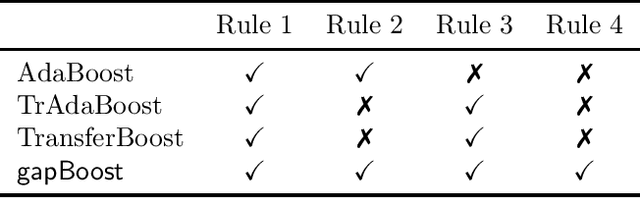
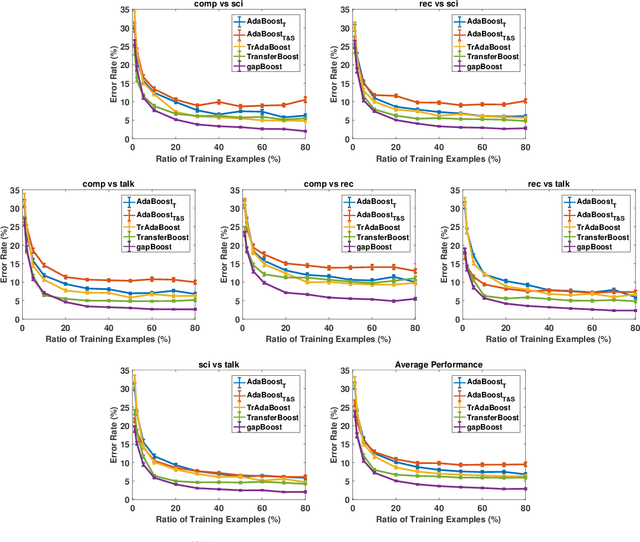
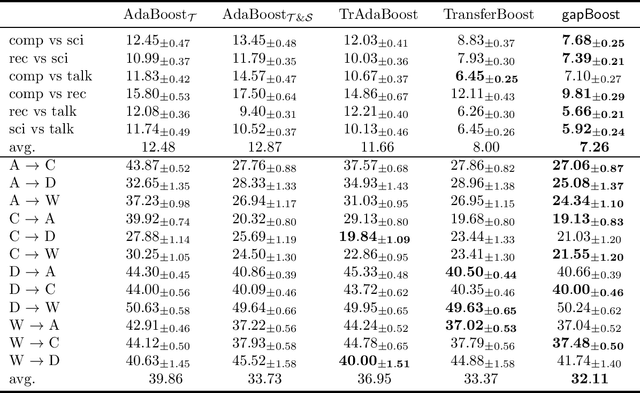
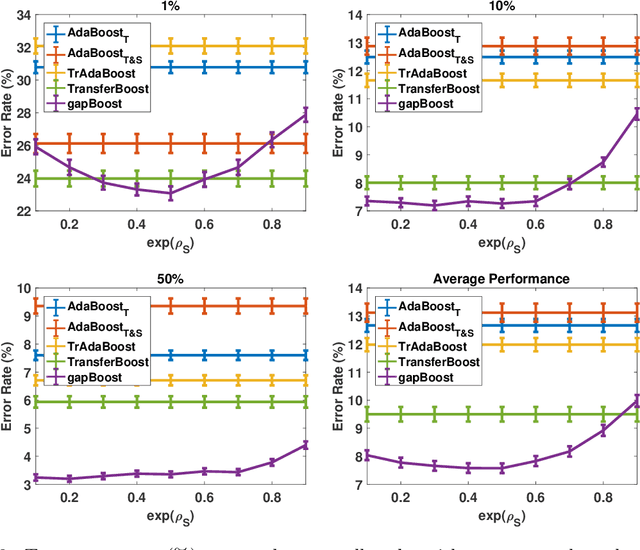
Learning from multiple related tasks by knowledge sharing and transfer has become increasingly relevant over the last two decades. In order to successfully transfer information from one task to another, it is critical to understand the similarities and differences between the domains. In this paper, we introduce the notion of \emph{performance gap}, an intuitive and novel measure of the distance between learning tasks. Unlike existing measures which are used as tools to bound the difference of expected risks between tasks (e.g., $\mathcal{H}$-divergence or discrepancy distance), we theoretically show that the performance gap can be viewed as a data- and algorithm-dependent regularizer, which controls the model complexity and leads to finer guarantees. More importantly, it also provides new insights and motivates a novel principle for designing strategies for knowledge sharing and transfer: gap minimization. We instantiate this principle with two algorithms: 1. {gapBoost}, a novel and principled boosting algorithm that explicitly minimizes the performance gap between source and target domains for transfer learning; and 2. {gapMTNN}, a representation learning algorithm that reformulates gap minimization as semantic conditional matching for multitask learning. Our extensive evaluation on both transfer learning and multitask learning benchmark data sets shows that our methods outperform existing baselines.
Prospective Learning: Back to the Future
Jan 19, 2022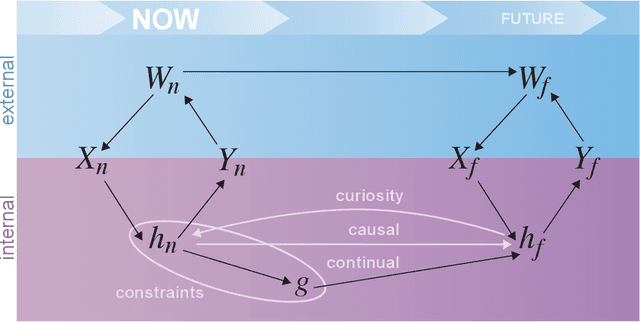

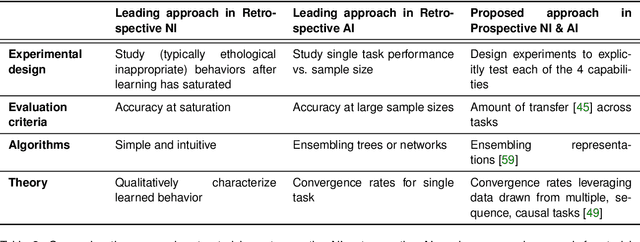
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Towards a theory of out-of-distribution learning
Oct 07, 2021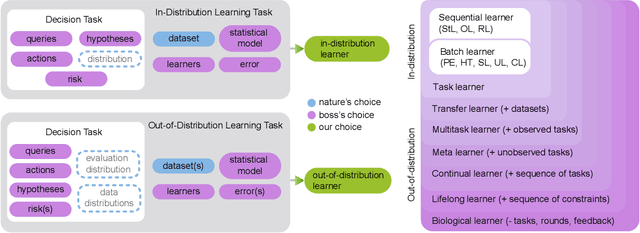
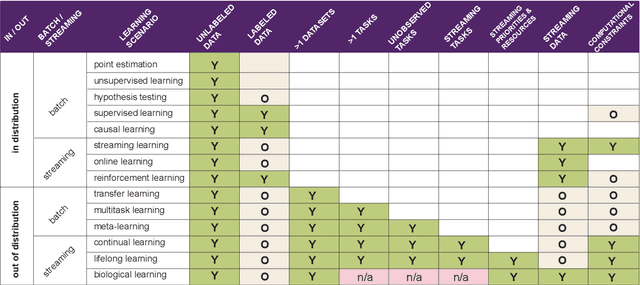
What is learning? 20$^{st}$ century formalizations of learning theory -- which precipitated revolutions in artificial intelligence -- focus primarily on $\mathit{in-distribution}$ learning, that is, learning under the assumption that the training data are sampled from the same distribution as the evaluation distribution. This assumption renders these theories inadequate for characterizing 21$^{st}$ century real world data problems, which are typically characterized by evaluation distributions that differ from the training data distributions (referred to as out-of-distribution learning). We therefore make a small change to existing formal definitions of learnability by relaxing that assumption. We then introduce $\mathbf{learning\ efficiency}$ (LE) to quantify the amount a learner is able to leverage data for a given problem, regardless of whether it is an in- or out-of-distribution problem. We then define and prove the relationship between generalized notions of learnability, and show how this framework is sufficiently general to characterize transfer, multitask, meta, continual, and lifelong learning. We hope this unification helps bridge the gap between empirical practice and theoretical guidance in real world problems. Finally, because biological learning continues to outperform machine learning algorithms on certain OOD challenges, we discuss the limitations of this framework vis-\'a-vis its ability to formalize biological learning, suggesting multiple avenues for future research.
Sparse PointPillars: Exploiting Sparsity in Birds-Eye-View Object Detection
Jun 12, 2021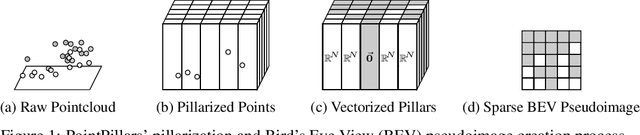

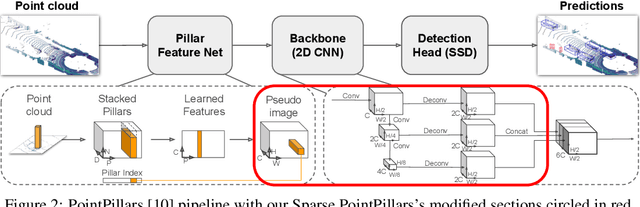
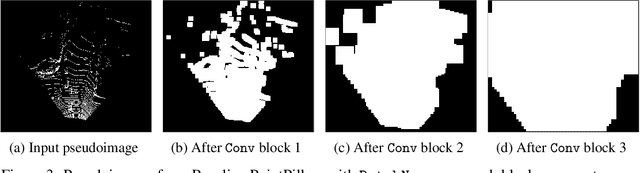
Bird's Eye View (BEV) is a popular representation for processing 3D point clouds, and by its nature is fundamentally sparse. Motivated by the computational limitations of mobile robot platforms, we take a fast high-performance BEV 3D object detector - PointPillars - and modify its backbone to exploit this sparsity, leading to decreased runtimes. We present preliminary results demonstrating decreased runtimes with either the same performance or a modest decrease in performance, which we anticipate will be remedied by model specific hyperparameter tuning. Our work is a first step towards a new class of 3D object detectors that exploit sparsity throughout their entire pipeline in order to reduce runtime and resource usage while maintaining good detection performance.
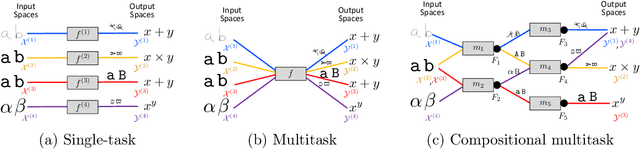
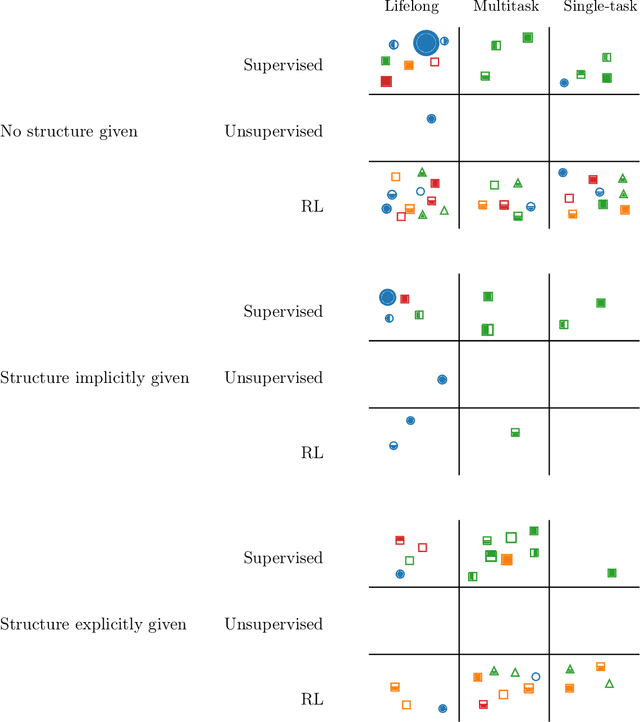
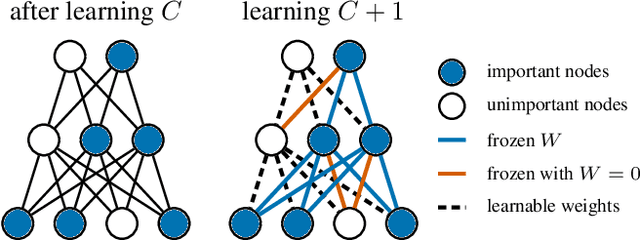
Lifelong Learning of Compositional Structures
Jul 15, 2020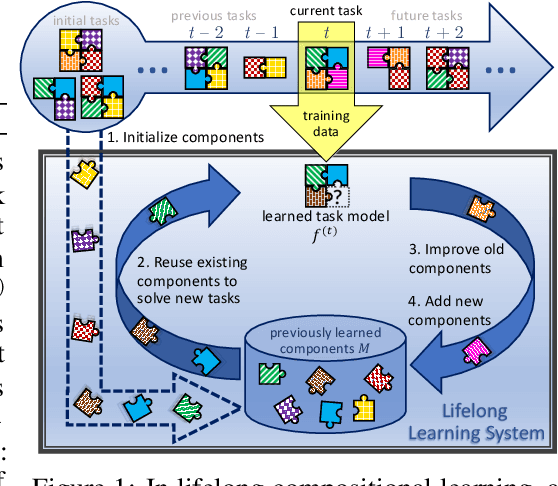
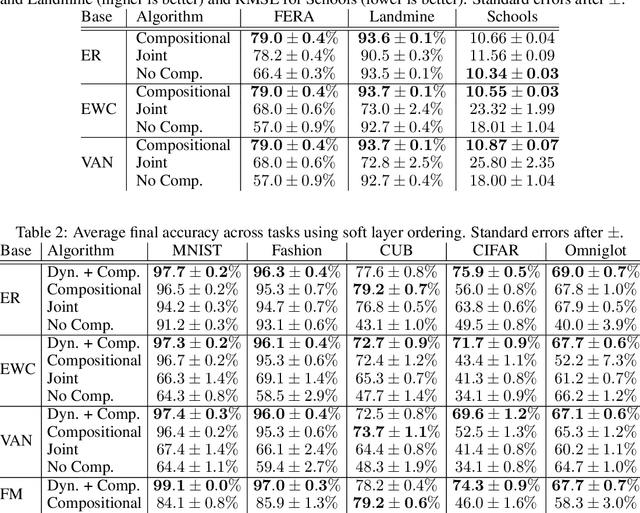
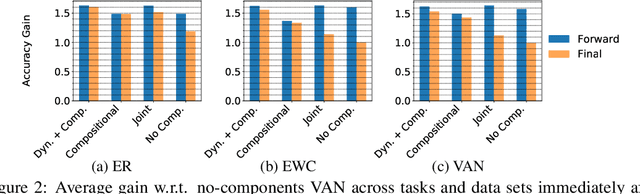

A hallmark of human intelligence is the ability to construct self-contained chunks of knowledge and adequately reuse them in novel combinations for solving different yet structurally related problems. Learning such compositional structures has been a significant challenge for artificial systems, due to the combinatorial nature of the underlying search problem. To date, research into compositional learning has largely proceeded separately from work on lifelong or continual learning. We integrate these two lines of work to present a general-purpose framework for lifelong learning of compositional structures that can be used for solving a stream of related tasks. Our framework separates the learning process into two broad stages: learning how to best combine existing components in order to assimilate a novel problem, and learning how to adapt the set of existing components to accommodate the new problem. This separation explicitly handles the trade-off between the stability required to remember how to solve earlier tasks and the flexibility required to solve new tasks, as we show empirically in an extensive evaluation.