 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Context Detection for Deep Lifelong Reinforcement Learning
May 29, 2024Context detection involves labeling segments of an online stream of data as belonging to different tasks. Task labels are used in lifelong learning algorithms to perform consolidation or other procedures that prevent catastrophic forgetting. Inferring task labels from online experiences remains a challenging problem. Most approaches assume finite and low-dimension observation spaces or a preliminary training phase during which task labels are learned. Moreover, changes in the transition or reward functions can be detected only in combination with a policy, and therefore are more difficult to detect than changes in the input distribution. This paper presents an approach to learning both policies and labels in an online deep reinforcement learning setting. The key idea is to use distance metrics, obtained via optimal transport methods, i.e., Wasserstein distance, on suitable latent action-reward spaces to measure distances between sets of data points from past and current streams. Such distances can then be used for statistical tests based on an adapted Kolmogorov-Smirnov calculation to assign labels to sequences of experiences. A rollback procedure is introduced to learn multiple policies by ensuring that only the appropriate data is used to train the corresponding policy. The combination of task detection and policy deployment allows for the optimization of lifelong reinforcement learning agents without an oracle that provides task labels. The approach is tested using two benchmarks and the results show promising performance when compared with related context detection algorithms. The results suggest that optimal transport statistical methods provide an explainable and justifiable procedure for online context detection and reward optimization in lifelong reinforcement learning.
Context Meta-Reinforcement Learning via Neuromodulation
Oct 30, 2021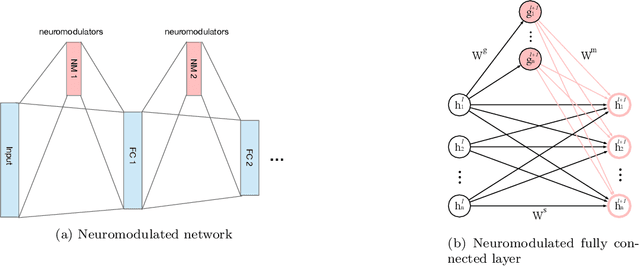
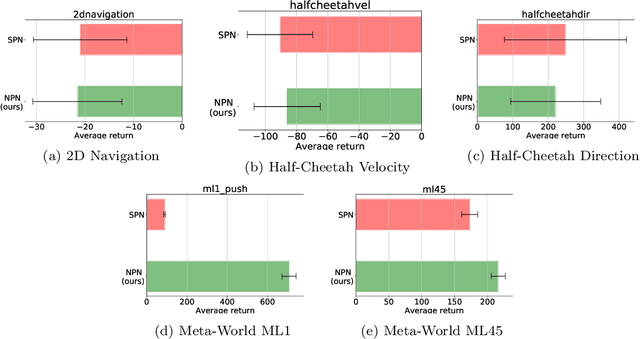
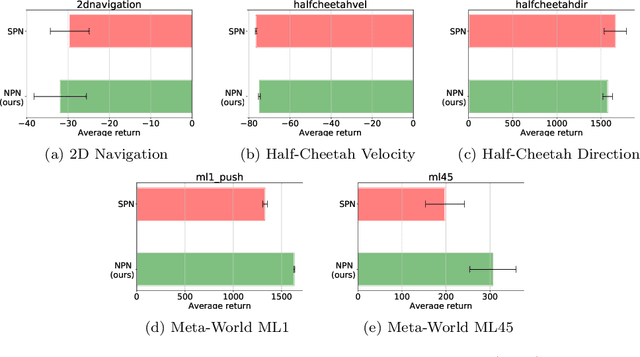

Meta-reinforcement learning (meta-RL) algorithms enable agents to adapt quickly to tasks from few samples in dynamic environments. Such a feat is achieved through dynamic representations in an agent's policy network (obtained via reasoning about task context, model parameter updates, or both). However, obtaining rich dynamic representations for fast adaptation beyond simple benchmark problems is challenging due to the burden placed on the policy network to accommodate different policies. This paper addresses the challenge by introducing neuromodulation as a modular component to augment a standard policy network that regulates neuronal activities in order to produce efficient dynamic representations for task adaptation. The proposed extension to the policy network is evaluated across multiple discrete and continuous control environments of increasing complexity. To prove the generality and benefits of the extension in meta-RL, the neuromodulated network was applied to two state-of-the-art meta-RL algorithms (CAVIA and PEARL). The result demonstrates that meta-RL augmented with neuromodulation produces significantly better result and richer dynamic representations in comparison to the baselines.
Towards a theory of out-of-distribution learning
Oct 07, 2021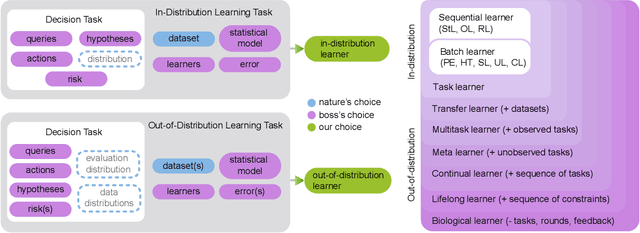
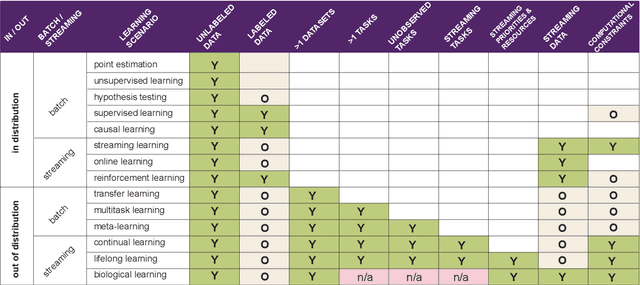
What is learning? 20$^{st}$ century formalizations of learning theory -- which precipitated revolutions in artificial intelligence -- focus primarily on $\mathit{in-distribution}$ learning, that is, learning under the assumption that the training data are sampled from the same distribution as the evaluation distribution. This assumption renders these theories inadequate for characterizing 21$^{st}$ century real world data problems, which are typically characterized by evaluation distributions that differ from the training data distributions (referred to as out-of-distribution learning). We therefore make a small change to existing formal definitions of learnability by relaxing that assumption. We then introduce $\mathbf{learning\ efficiency}$ (LE) to quantify the amount a learner is able to leverage data for a given problem, regardless of whether it is an in- or out-of-distribution problem. We then define and prove the relationship between generalized notions of learnability, and show how this framework is sufficiently general to characterize transfer, multitask, meta, continual, and lifelong learning. We hope this unification helps bridge the gap between empirical practice and theoretical guidance in real world problems. Finally, because biological learning continues to outperform machine learning algorithms on certain OOD challenges, we discuss the limitations of this framework vis-\'a-vis its ability to formalize biological learning, suggesting multiple avenues for future research.
Evolving Inborn Knowledge For Fast Adaptation in Dynamic POMDP Problems
Apr 28, 2020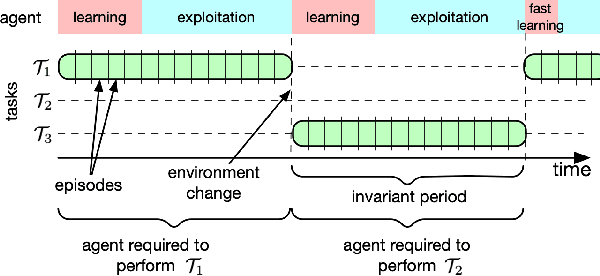
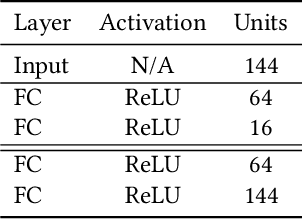
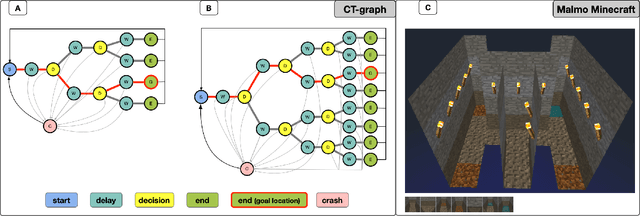
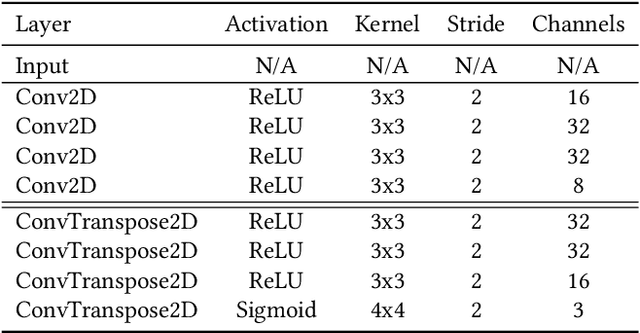
Rapid online adaptation to changing tasks is an important problem in machine learning and, recently, a focus of meta-reinforcement learning. However, reinforcement learning (RL) algorithms struggle in POMDP environments because the state of the system, essential in a RL framework, is not always visible. Additionally, hand-designed meta-RL architectures may not include suitable computational structures for specific learning problems. The evolution of online learning mechanisms, on the contrary, has the ability to incorporate learning strategies into an agent that can (i) evolve memory when required and (ii) optimize adaptation speed to specific online learning problems. In this paper, we exploit the highly adaptive nature of neuromodulated neural networks to evolve a controller that uses the latent space of an autoencoder in a POMDP. The analysis of the evolved networks reveals the ability of the proposed algorithm to acquire inborn knowledge in a variety of aspects such as the detection of cues that reveal implicit rewards, and the ability to evolve location neurons that help with navigation. The integration of inborn knowledge and online plasticity enabled fast adaptation and better performance in comparison to some non-evolutionary meta-reinforcement learning algorithms. The algorithm proved also to succeed in the 3D gaming environment Malmo Minecraft.