 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Case for a Single Model that can Both Generate Continuations and Fill in the Blank
Jun 09, 2022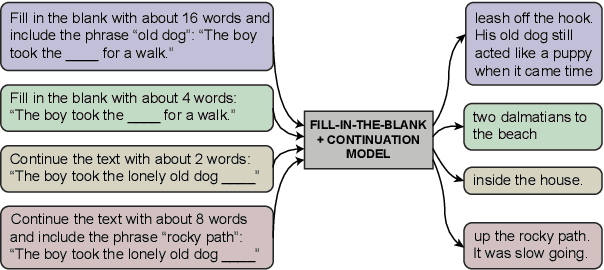

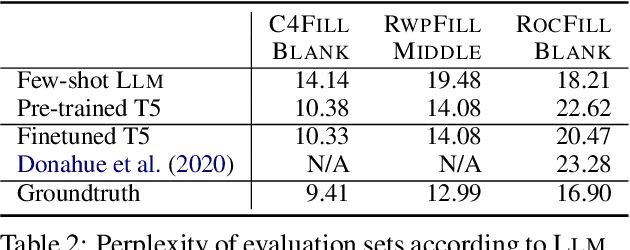
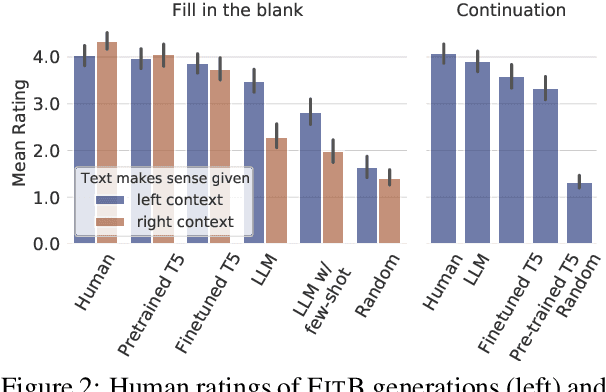
The task of inserting text into a specified position in a passage, known as fill in the blank (FitB), is useful for a variety of applications where writers interact with a natural language generation (NLG) system to craft text. While previous work has tackled this problem with models trained specifically to do the fill-in-the-blank task, a more useful model is one that can effectively perform _both_ FitB and continuation. In this work, we evaluate the feasibility of using a single model to do both tasks. We show that models pre-trained with a FitB-style objective are capable of both tasks, while models pre-trained for continuation are not. Finally, we show how FitB models can be easily finetuned to allow for fine-grained control over the length and word choice of the generation.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
A Recipe For Arbitrary Text Style Transfer with Large Language Models
Sep 16, 2021



In this paper, we leverage large language models (LMs) to perform zero-shot text style transfer. We present a prompting method that we call augmented zero-shot learning, which frames style transfer as a sentence rewriting task and requires only a natural language instruction, without model fine-tuning or exemplars in the target style. Augmented zero-shot learning is simple and demonstrates promising results not just on standard style transfer tasks such as sentiment, but also on arbitrary transformations such as "make this melodramatic" or "insert a metaphor."
Wordcraft: a Human-AI Collaborative Editor for Story Writing
Jul 15, 2021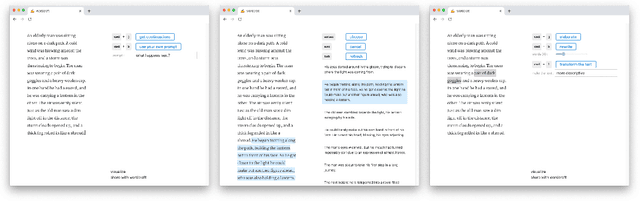


As neural language models grow in effectiveness, they are increasingly being applied in real-world settings. However these applications tend to be limited in the modes of interaction they support. In this extended abstract, we propose Wordcraft, an AI-assisted editor for story writing in which a writer and a dialog system collaborate to write a story. Our novel interface uses few-shot learning and the natural affordances of conversation to support a variety of interactions. Our editor provides a sandbox for writers to probe the boundaries of transformer-based language models and paves the way for future human-in-the-loop training pipelines and novel evaluation methods.
An Interpretability Illusion for BERT
Apr 14, 2021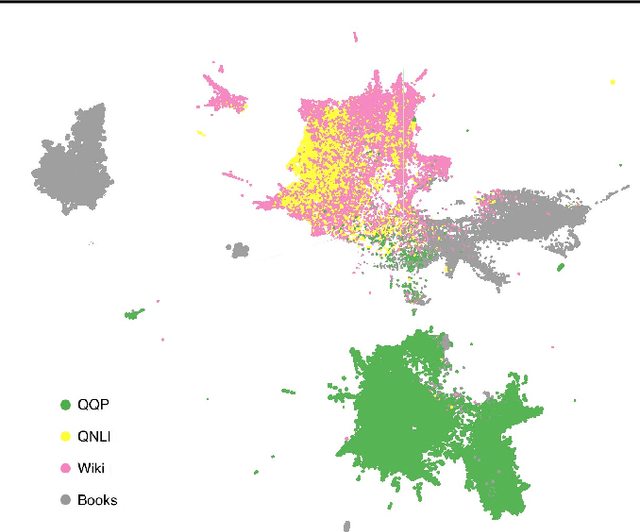


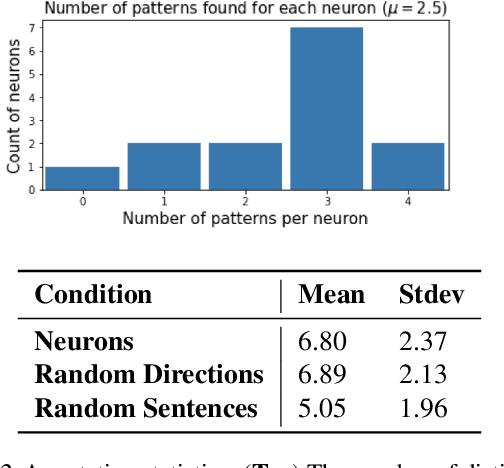
We describe an "interpretability illusion" that arises when analyzing the BERT model. Activations of individual neurons in the network may spuriously appear to encode a single, simple concept, when in fact they are encoding something far more complex. The same effect holds for linear combinations of activations. We trace the source of this illusion to geometric properties of BERT's embedding space as well as the fact that common text corpora represent only narrow slices of possible English sentences. We provide a taxonomy of model-learned concepts and discuss methodological implications for interpretability research, especially the importance of testing hypotheses on multiple data sets.
The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models
Aug 12, 2020



We present the Language Interpretability Tool (LIT), an open-source platform for visualization and understanding of NLP models. We focus on core questions about model behavior: Why did my model make this prediction? When does it perform poorly? What happens under a controlled change in the input? LIT integrates local explanations, aggregate analysis, and counterfactual generation into a streamlined, browser-based interface to enable rapid exploration and error analysis. We include case studies for a diverse set of workflows, including exploring counterfactuals for sentiment analysis, measuring gender bias in coreference systems, and exploring local behavior in text generation. LIT supports a wide range of models--including classification, seq2seq, and structured prediction--and is highly extensible through a declarative, framework-agnostic API. LIT is under active development, with code and full documentation available at https://github.com/pair-code/lit.
Visualizing and Measuring the Geometry of BERT
Jun 06, 2019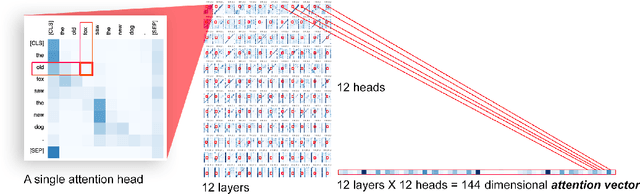
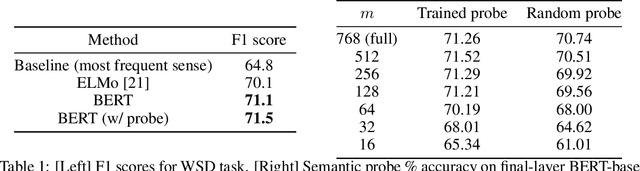
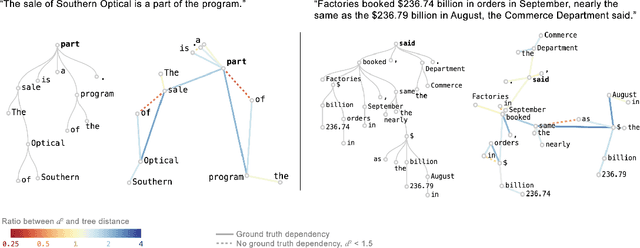
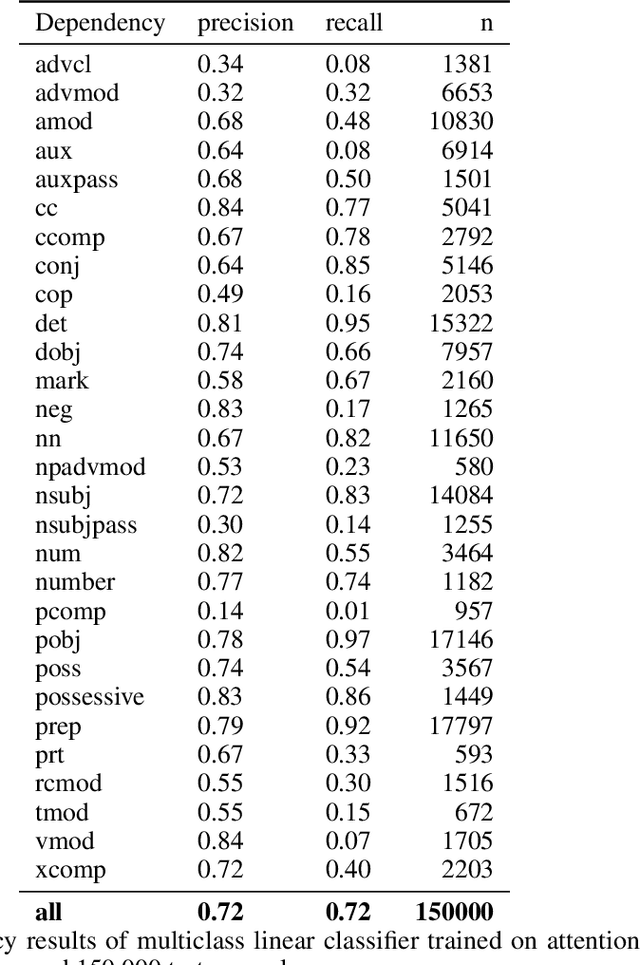
Transformer architectures show significant promise for natural language processing. Given that a single pretrained model can be fine-tuned to perform well on many different tasks, these networks appear to extract generally useful linguistic features. A natural question is how such networks represent this information internally. This paper describes qualitative and quantitative investigations of one particularly effective model, BERT. At a high level, linguistic features seem to be represented in separate semantic and syntactic subspaces. We find evidence of a fine-grained geometric representation of word senses. We also present empirical descriptions of syntactic representations in both attention matrices and individual word embeddings, as well as a mathematical argument to explain the geometry of these representations.
Do Neural Networks Show Gestalt Phenomena? An Exploration of the Law of Closure
Mar 21, 2019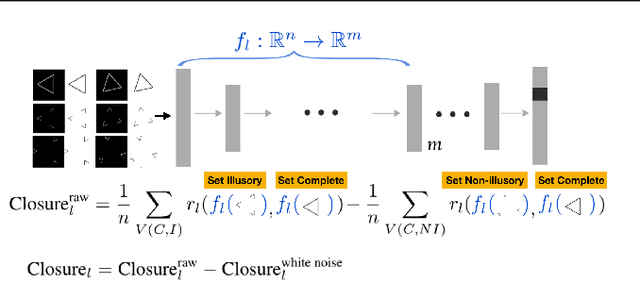
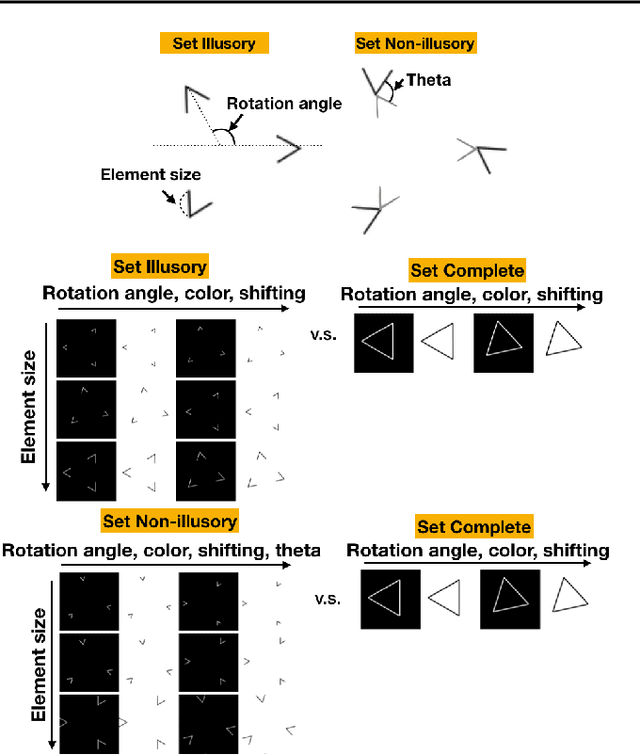
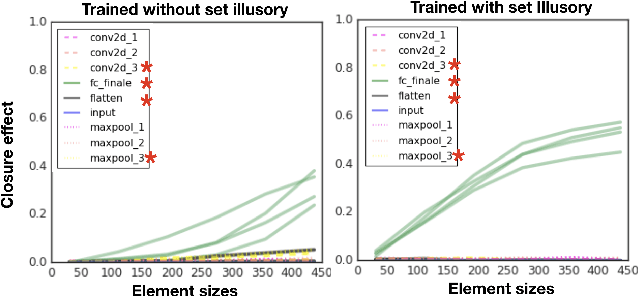
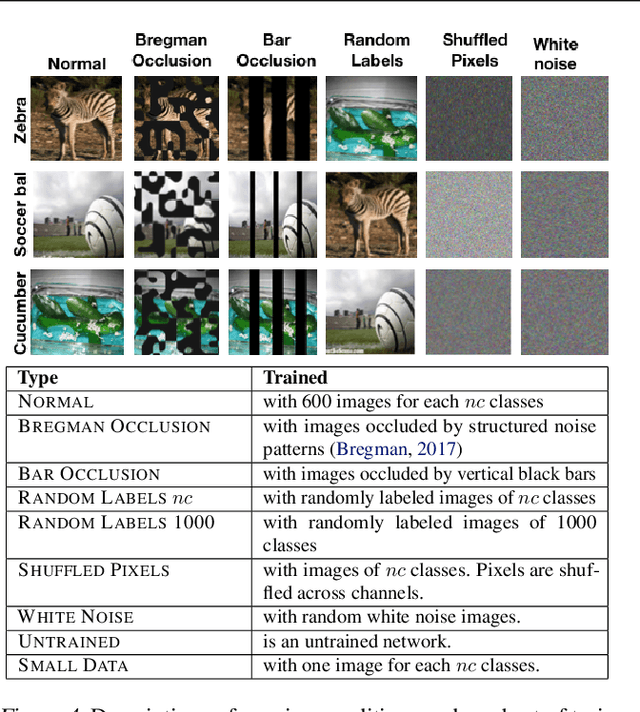
One characteristic of human visual perception is the presence of `Gestalt phenomena,' that is, that the whole is something other than the sum of its parts. A natural question is whether image-recognition networks show similar effects. Our paper investigates one particular type of Gestalt phenomenon, the law of closure, in the context of a feedforward image classification neural network (NN). This is a robust effect in human perception, but experiments typically rely on measurements (e.g., reaction time) that are not available for artificial neural nets. We describe a protocol for identifying closure effect in NNs, and report on the results of experiments with simple visual stimuli. Our findings suggest that NNs trained with natural images do exhibit closure, in contrast to networks with randomized weights or networks that have been trained on visually random data. Furthermore, the closure effect reflects something beyond good feature extraction; it is correlated with the network's higher layer features and ability to generalize.
Similar Image Search for Histopathology: SMILY
Feb 06, 2019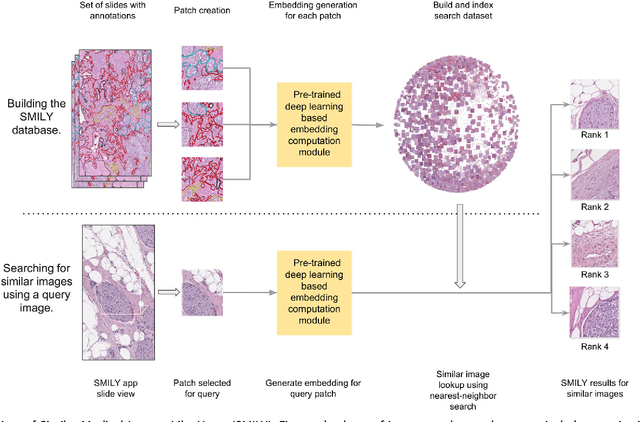
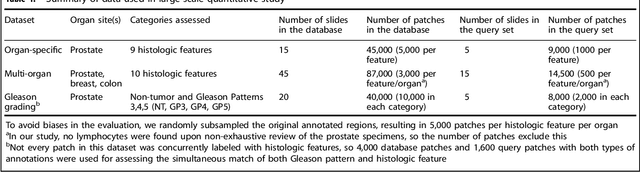
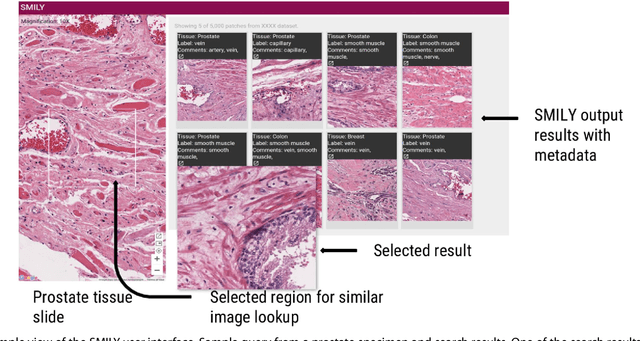
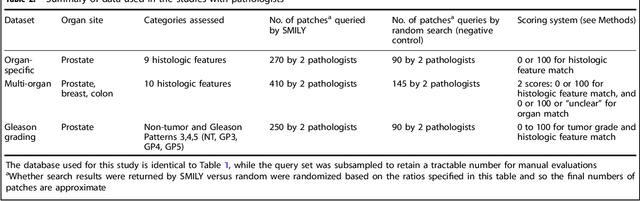
The increasing availability of large institutional and public histopathology image datasets is enabling the searching of these datasets for diagnosis, research, and education. Though these datasets typically have associated metadata such as diagnosis or clinical notes, even carefully curated datasets rarely contain annotations of the location of regions of interest on each image. Because pathology images are extremely large (up to 100,000 pixels in each dimension), further laborious visual search of each image may be needed to find the feature of interest. In this paper, we introduce a deep learning based reverse image search tool for histopathology images: Similar Medical Images Like Yours (SMILY). We assessed SMILY's ability to retrieve search results in two ways: using pathologist-provided annotations, and via prospective studies where pathologists evaluated the quality of SMILY search results. As a negative control in the second evaluation, pathologists were blinded to whether search results were retrieved by SMILY or randomly. In both types of assessments, SMILY was able to retrieve search results with similar histologic features, organ site, and prostate cancer Gleason grade compared with the original query. SMILY may be a useful general-purpose tool in the pathologist's arsenal, to improve the efficiency of searching large archives of histopathology images, without the need to develop and implement specific tools for each application.
Embedding Projector: Interactive Visualization and Interpretation of Embeddings
Nov 16, 2016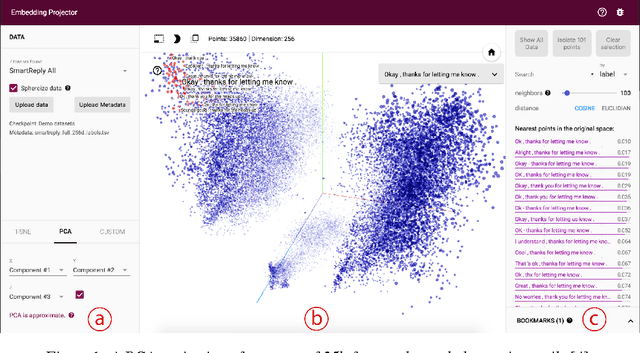

Embeddings are ubiquitous in machine learning, appearing in recommender systems, NLP, and many other applications. Researchers and developers often need to explore the properties of a specific embedding, and one way to analyze embeddings is to visualize them. We present the Embedding Projector, a tool for interactive visualization and interpretation of embeddings.