 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models to Detect Influence Campaigns in Social Media
Nov 14, 2023



Social media influence campaigns pose significant challenges to public discourse and democracy. Traditional detection methods fall short due to the complexity and dynamic nature of social media. Addressing this, we propose a novel detection method using Large Language Models (LLMs) that incorporates both user metadata and network structures. By converting these elements into a text format, our approach effectively processes multilingual content and adapts to the shifting tactics of malicious campaign actors. We validate our model through rigorous testing on multiple datasets, showcasing its superior performance in identifying influence efforts. This research not only offers a powerful tool for detecting campaigns, but also sets the stage for future enhancements to keep up with the fast-paced evolution of social media-based influence tactics.
Automated Claim Matching with Large Language Models: Empowering Fact-Checkers in the Fight Against Misinformation
Oct 13, 2023In today's digital era, the rapid spread of misinformation poses threats to public well-being and societal trust. As online misinformation proliferates, manual verification by fact checkers becomes increasingly challenging. We introduce FACT-GPT (Fact-checking Augmentation with Claim matching Task-oriented Generative Pre-trained Transformer), a framework designed to automate the claim matching phase of fact-checking using Large Language Models (LLMs). This framework identifies new social media content that either supports or contradicts claims previously debunked by fact-checkers. Our approach employs GPT-4 to generate a labeled dataset consisting of simulated social media posts. This data set serves as a training ground for fine-tuning more specialized LLMs. We evaluated FACT-GPT on an extensive dataset of social media content related to public health. The results indicate that our fine-tuned LLMs rival the performance of larger pre-trained LLMs in claim matching tasks, aligning closely with human annotations. This study achieves three key milestones: it provides an automated framework for enhanced fact-checking; demonstrates the potential of LLMs to complement human expertise; offers public resources, including datasets and models, to further research and applications in the fact-checking domain.
GenAI Against Humanity: Nefarious Applications of Generative Artificial Intelligence and Large Language Models
Oct 12, 2023Generative Artificial Intelligence (GenAI) and Large Language Models (LLMs) are marvels of technology; celebrated for their prowess in natural language processing and multimodal content generation, they promise a transformative future. But as with all powerful tools, they come with their shadows. Picture living in a world where deepfakes are indistinguishable from reality, where synthetic identities orchestrate malicious campaigns, and where targeted misinformation or scams are crafted with unparalleled precision. Welcome to the darker side of GenAI applications. This article is not just a journey through the meanders of potential misuse of GenAI and LLMs, but also a call to recognize the urgency of the challenges ahead. As we navigate the seas of misinformation campaigns, malicious content generation, and the eerie creation of sophisticated malware, we'll uncover the societal implications that ripple through the GenAI revolution we are witnessing. From AI-powered botnets on social media platforms to the unnerving potential of AI to generate fabricated identities, or alibis made of synthetic realities, the stakes have never been higher. The lines between the virtual and the real worlds are blurring, and the consequences of potential GenAI's nefarious applications impact us all. This article serves both as a synthesis of rigorous research presented on the risks of GenAI and misuse of LLMs and as a thought-provoking vision of the different types of harmful GenAI applications we might encounter in the near future, and some ways we can prepare for them.
Factuality Challenges in the Era of Large Language Models
Oct 10, 2023The emergence of tools based on Large Language Models (LLMs), such as OpenAI's ChatGPT, Microsoft's Bing Chat, and Google's Bard, has garnered immense public attention. These incredibly useful, natural-sounding tools mark significant advances in natural language generation, yet they exhibit a propensity to generate false, erroneous, or misleading content -- commonly referred to as "hallucinations." Moreover, LLMs can be exploited for malicious applications, such as generating false but credible-sounding content and profiles at scale. This poses a significant challenge to society in terms of the potential deception of users and the increasing dissemination of inaccurate information. In light of these risks, we explore the kinds of technological innovations, regulatory reforms, and AI literacy initiatives needed from fact-checkers, news organizations, and the broader research and policy communities. By identifying the risks, the imminent threats, and some viable solutions, we seek to shed light on navigating various aspects of veracity in the era of generative AI.
Controlled Text Generation with Hidden Representation Transformations
May 31, 2023



We propose CHRT (Control Hidden Representation Transformation) - a controlled language generation framework that steers large language models to generate text pertaining to certain attributes (such as toxicity). CHRT gains attribute control by modifying the hidden representation of the base model through learned transformations. We employ a contrastive-learning framework to learn these transformations that can be combined to gain multi-attribute control. The effectiveness of CHRT is experimentally shown by comparing it with seven baselines over three attributes. CHRT outperforms all the baselines in the task of detoxification, positive sentiment steering, and text simplification while minimizing the loss in linguistic qualities. Further, our approach has the lowest inference latency of only 0.01 seconds more than the base model, making it the most suitable for high-performance production environments. We open-source our code and release two novel datasets to further propel controlled language generation research.
Identifying Informational Sources in News Articles
May 24, 2023



News articles are driven by the informational sources journalists use in reporting. Modeling when, how and why sources get used together in stories can help us better understand the information we consume and even help journalists with the task of producing it. In this work, we take steps toward this goal by constructing the largest and widest-ranging annotated dataset, to date, of informational sources used in news writing. We show that our dataset can be used to train high-performing models for information detection and source attribution. We further introduce a novel task, source prediction, to study the compositionality of sources in news articles. We show good performance on this task, which we argue is an important proof for narrative science exploring the internal structure of news articles and aiding in planning-based language generation, and an important step towards a source-recommendation system to aid journalists.
Should ChatGPT be Biased? Challenges and Risks of Bias in Large Language Models
Apr 18, 2023As the capabilities of generative language models continue to advance, the implications of biases ingrained within these models have garnered increasing attention from researchers, practitioners, and the broader public. This article investigates the challenges and risks associated with biases in large-scale language models like ChatGPT. We discuss the origins of biases, stemming from, among others, the nature of training data, model specifications, algorithmic constraints, product design, and policy decisions. We explore the ethical concerns arising from the unintended consequences of biased model outputs. We further analyze the potential opportunities to mitigate biases, the inevitability of some biases, and the implications of deploying these models in various applications, such as virtual assistants, content generation, and chatbots. Finally, we review the current approaches to identify, quantify, and mitigate biases in language models, emphasizing the need for a multi-disciplinary, collaborative effort to develop more equitable, transparent, and responsible AI systems. This article aims to stimulate a thoughtful dialogue within the artificial intelligence community, encouraging researchers and developers to reflect on the role of biases in generative language models and the ongoing pursuit of ethical AI.
Leveraging Social Interactions to Detect Misinformation on Social Media
Apr 06, 2023



Detecting misinformation threads is crucial to guarantee a healthy environment on social media. We address the problem using the data set created during the COVID-19 pandemic. It contains cascades of tweets discussing information weakly labeled as reliable or unreliable, based on a previous evaluation of the information source. The models identifying unreliable threads usually rely on textual features. But reliability is not just what is said, but by whom and to whom. We additionally leverage on network information. Following the homophily principle, we hypothesize that users who interact are generally interested in similar topics and spreading similar kind of news, which in turn is generally reliable or not. We test several methods to learn representations of the social interactions within the cascades, combining them with deep neural language models in a Multi-Input (MI) framework. Keeping track of the sequence of the interactions during the time, we improve over previous state-of-the-art models.
From Fake News to #FakeNews: Mining Direct and Indirect Relationships among Hashtags for Fake News Detection
Nov 20, 2022The COVID-19 pandemic has gained worldwide attention and allowed fake news, such as ``COVID-19 is the flu,'' to spread quickly and widely on social media. Combating this coronavirus infodemic demands effective methods to detect fake news. To this end, we propose a method to infer news credibility from hashtags involved in news dissemination on social media, motivated by the tight connection between hashtags and news credibility observed in our empirical analyses. We first introduce a new graph that captures all (direct and \textit{indirect}) relationships among hashtags. Then, a language-independent semi-supervised algorithm is developed to predict fake news based on this constructed graph. This study first investigates the indirect relationship among hashtags; the proposed approach can be extended to any homogeneous graph to capture a comprehensive relationship among nodes. Language independence opens the proposed method to multilingual fake news detection. Experiments conducted on two real-world datasets demonstrate the effectiveness of our approach in identifying fake news, especially at an \textit{early} stage of propagation.
How "troll" are you? Measuring and detecting troll behavior in online social networks
Oct 17, 2022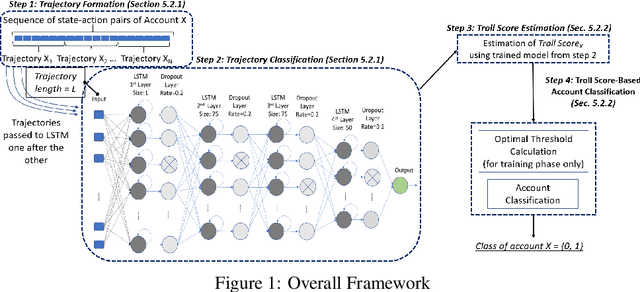
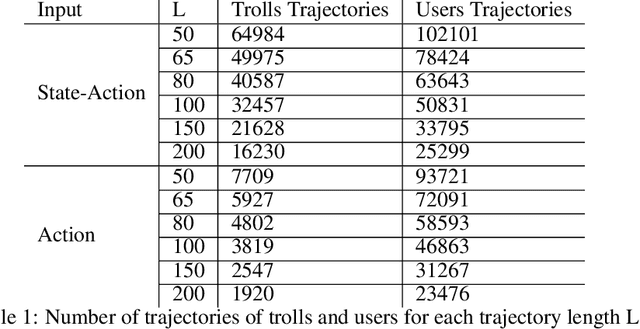
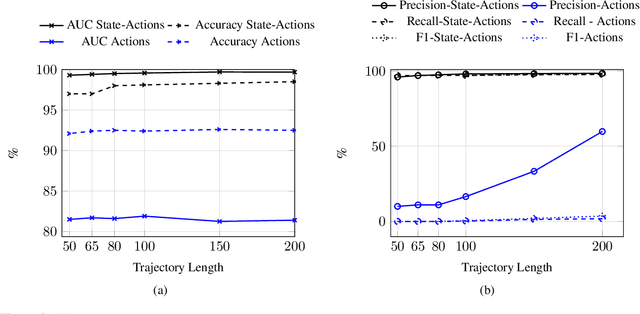

The detection of state-sponsored trolls acting in misinformation operations is an unsolved and critical challenge for the research community, with repercussions that go beyond the online realm. In this paper, we propose a novel approach for the detection of troll accounts, which consists of two steps. The first step aims at classifying trajectories of accounts' online activities as belonging to either a troll account or to an organic user account. In the second step, we exploit the classified trajectories to compute a metric, namely "troll score", which allows us to quantify the extent to which an account behaves like a troll. Experimental results show that our approach identifies accounts' trajectories with an AUC close to 99% and, accordingly, classify trolls and organic users with an AUC of 97%. Finally, we evaluate whether the proposed solution can be generalized to different contexts (e.g., discussions about Covid-19) and generic misbehaving users, showing promising results that will be further expanded in our future endeavors.