 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Frequency-Domain Feature Modeling for HRTF Magnitude Upsampling
Feb 12, 2026Accurate upsampling of Head-Related Transfer Functions (HRTFs) from sparse measurements is crucial for personalized spatial audio rendering. Traditional interpolation methods, such as kernel-based weighting or basis function expansions, rely on measurements from a single subject and are limited by the spatial sampling theorem, resulting in significant performance degradation under sparse sampling. Recent learning-based methods alleviate this limitation by leveraging cross-subject information, yet most existing neural architectures primarily focus on modeling spatial relationships across directions, while spectral dependencies along the frequency dimension are often modeled implicitly or treated independently. However, HRTF magnitude responses exhibit strong local continuity and long-range structure in the frequency domain, which are not fully exploited. This work investigates frequency-domain feature modeling by examining how different architectural choices, ranging from per-frequency multilayer perceptrons to convolutional, dilated convolutional, and attention-based models, affect performance under varying sparsity levels, showing that explicit spectral modeling consistently improves reconstruction accuracy, particularly under severe sparsity. Motivated by this observation, a frequency-domain Conformer-based architecture is adopted to jointly capture local spectral continuity and long-range frequency correlations. Experimental results on the SONICOM and HUTUBS datasets demonstrate that the proposed method achieves state-of-the-art performance in terms of interaural level difference and log-spectral distortion.
Point Neuron Learning: A New Physics-Informed Neural Network Architecture
Aug 30, 2024Machine learning and neural networks have advanced numerous research domains, but challenges such as large training data requirements and inconsistent model performance hinder their application in certain scientific problems. To overcome these challenges, researchers have investigated integrating physics principles into machine learning models, mainly through: (i) physics-guided loss functions, generally termed as physics-informed neural networks, and (ii) physics-guided architectural design. While both approaches have demonstrated success across multiple scientific disciplines, they have limitations including being trapped to a local minimum, poor interpretability, and restricted generalizability. This paper proposes a new physics-informed neural network (PINN) architecture that combines the strengths of both approaches by embedding the fundamental solution of the wave equation into the network architecture, enabling the learned model to strictly satisfy the wave equation. The proposed point neuron learning method can model an arbitrary sound field based on microphone observations without any dataset. Compared to other PINN methods, our approach directly processes complex numbers and offers better interpretability and generalizability. We evaluate the versatility of the proposed architecture by a sound field reconstruction problem in a reverberant environment. Results indicate that the point neuron method outperforms two competing methods and can efficiently handle noisy environments with sparse microphone observations.
Monaural speech enhancement on drone via Adapter based transfer learning
May 16, 2024



Monaural Speech enhancement on drones is challenging because the ego-noise from the rotating motors and propellers leads to extremely low signal-to-noise ratios at onboard microphones. Although recent masking-based deep neural network methods excel in monaural speech enhancement, they struggle in the challenging drone noise scenario. Furthermore, existing drone noise datasets are limited, causing models to overfit. Considering the harmonic nature of drone noise, this paper proposes a frequency domain bottleneck adapter to enable transfer learning. Specifically, the adapter's parameters are trained on drone noise while retaining the parameters of the pre-trained Frequency Recurrent Convolutional Recurrent Network (FRCRN) fixed. Evaluation results demonstrate the proposed method can effectively enhance speech quality. Moreover, it is a more efficient alternative to fine-tuning models for various drone types, which typically requires substantial computational resources.
Recursive Refinement Network for Deformable Lung Registration between Exhale and Inhale CT Scans
Jun 14, 2021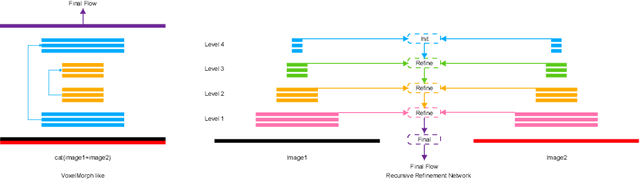
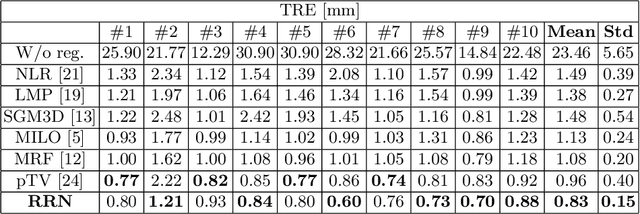
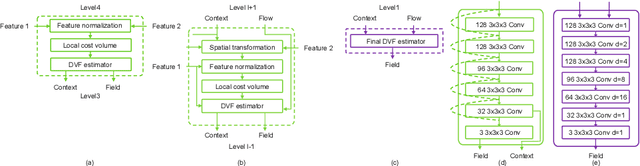

Unsupervised learning-based medical image registration approaches have witnessed rapid development in recent years. We propose to revisit a commonly ignored while simple and well-established principle: recursive refinement of deformation vector fields across scales. We introduce a recursive refinement network (RRN) for unsupervised medical image registration, to extract multi-scale features, construct normalized local cost correlation volume and recursively refine volumetric deformation vector fields. RRN achieves state of the art performance for 3D registration of expiratory-inspiratory pairs of CT lung scans. On DirLab COPDGene dataset, RRN returns an average Target Registration Error (TRE) of 0.83 mm, which corresponds to a 13% error reduction from the best result presented in the leaderboard. In addition to comparison with conventional methods, RRN leads to 89% error reduction compared to deep-learning-based peer approaches.