 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Style from Substance: Enhancing Cross-Genre Authorship Attribution through Data Selection and Presentation
Aug 09, 2024The task of deciding whether two documents are written by the same author is challenging for both machines and humans. This task is even more challenging when the two documents are written about different topics (e.g. baseball vs. politics) or in different genres (e.g. a blog post vs. an academic article). For machines, the problem is complicated by the relative lack of real-world training examples that cross the topic boundary and the vanishing scarcity of cross-genre data. We propose targeted methods for training data selection and a novel learning curriculum that are designed to discourage a model's reliance on topic information for authorship attribution and correspondingly force it to incorporate information more robustly indicative of style no matter the topic. These refinements yield a 62.7% relative improvement in average cross-genre authorship attribution, as well as 16.6% in the per-genre condition.
Granting GPT-4 License and Opportunity: Enhancing Accuracy and Confidence Estimation for Few-Shot Event Detection
Aug 01, 2024



Large Language Models (LLMs) such as GPT-4 have shown enough promise in the few-shot learning context to suggest use in the generation of "silver" data and refinement of new ontologies through iterative application and review. Such workflows become more effective with reliable confidence estimation. Unfortunately, confidence estimation is a documented weakness of models such as GPT-4, and established methods to compensate require significant additional complexity and computation. The present effort explores methods for effective confidence estimation with GPT-4 with few-shot learning for event detection in the BETTER ontology as a vehicle. The key innovation is expanding the prompt and task presented to GPT-4 to provide License to speculate when unsure and Opportunity to quantify and explain its uncertainty (L&O). This approach improves accuracy and provides usable confidence measures (0.759 AUC) with no additional machinery.
CAVE: Controllable Authorship Verification Explanations
Jun 24, 2024



Authorship Verification (AV) (do two documents have the same author?) is essential for many sensitive real-life applications. AV is often used in proprietary domains that require a private, offline model, making SOTA online models like ChatGPT undesirable. Other SOTA systems use methods, e.g. Siamese Networks, that are uninterpretable, and hence cannot be trusted in high-stakes applications. In this work, we take the first step to address the above challenges with our model CAVE (Controllable Authorship Verification Explanations): CAVE generates free-text AV explanations that are controlled to be 1) structured (can be decomposed into sub-explanations with respect to relevant linguistic features), and 2) easily verified for explanation-label consistency (via intermediate labels in sub-explanations). In this work, we train a Llama-3-8B as CAVE; since there are no human-written corpora for AV explanations, we sample silver-standard explanations from GPT-4-TURBO and distill them into a pretrained Llama-3-8B. Results on three difficult AV datasets IMdB2, Blog-Auth, and FanFiction show that CAVE generates high quality explanations (as measured by automatic and human evaluation) as well as competitive task accuracies.
Massively Multi-Lingual Event Understanding: Extraction, Visualization, and Search
May 17, 2023



In this paper, we present ISI-Clear, a state-of-the-art, cross-lingual, zero-shot event extraction system and accompanying user interface for event visualization & search. Using only English training data, ISI-Clear makes global events available on-demand, processing user-supplied text in 100 languages ranging from Afrikaans to Yiddish. We provide multiple event-centric views of extracted events, including both a graphical representation and a document-level summary. We also integrate existing cross-lingual search algorithms with event extraction capabilities to provide cross-lingual event-centric search, allowing English-speaking users to search over events automatically extracted from a corpus of non-English documents, using either English natural language queries (e.g. cholera outbreaks in Iran) or structured queries (e.g. find all events of type Disease-Outbreak with agent cholera and location Iran).
Impact of Subword Pooling Strategy on Cross-lingual Event Detection
Feb 23, 2023



Pre-trained multilingual language models (e.g., mBERT, XLM-RoBERTa) have significantly advanced the state-of-the-art for zero-shot cross-lingual information extraction. These language models ubiquitously rely on word segmentation techniques that break a word into smaller constituent subwords. Therefore, all word labeling tasks (e.g. named entity recognition, event detection, etc.), necessitate a pooling strategy that takes the subword representations as input and outputs a representation for the entire word. Taking the task of cross-lingual event detection as a motivating example, we show that the choice of pooling strategy can have a significant impact on the target language performance. For example, the performance varies by up to 16 absolute $f_{1}$ points depending on the pooling strategy when training in English and testing in Arabic on the ACE task. We carry out our analysis with five different pooling strategies across nine languages in diverse multi-lingual datasets. Across configurations, we find that the canonical strategy of taking just the first subword to represent the entire word is usually sub-optimal. On the other hand, we show that attention pooling is robust to language and dataset variations by being either the best or close to the optimal strategy. For reproducibility, we make our code available at https://github.com/isi-boston/ed-pooling.
Language Model Priming for Cross-Lingual Event Extraction
Sep 25, 2021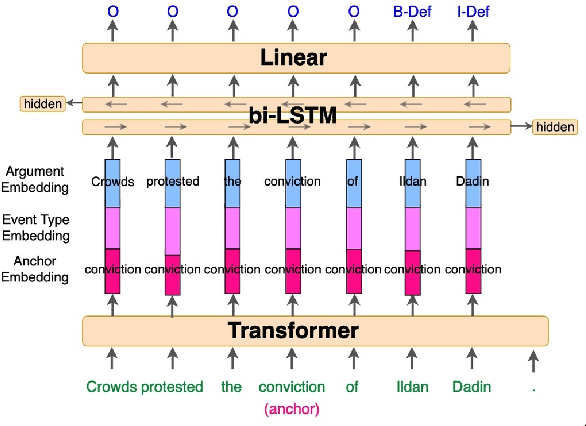
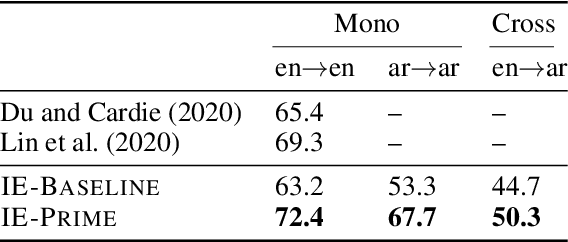


We present a novel, language-agnostic approach to "priming" language models for the task of event extraction, providing particularly effective performance in low-resource and zero-shot cross-lingual settings. With priming, we augment the input to the transformer stack's language model differently depending on the question(s) being asked of the model at runtime. For instance, if the model is being asked to identify arguments for the trigger "protested", we will provide that trigger as part of the input to the language model, allowing it to produce different representations for candidate arguments than when it is asked about arguments for the trigger "arrest" elsewhere in the same sentence. We show that by enabling the language model to better compensate for the deficits of sparse and noisy training data, our approach improves both trigger and argument detection and classification significantly over the state of the art in a zero-shot cross-lingual setting.
AutoTriggER: Named Entity Recognition with Auxiliary Trigger Extraction
Sep 10, 2021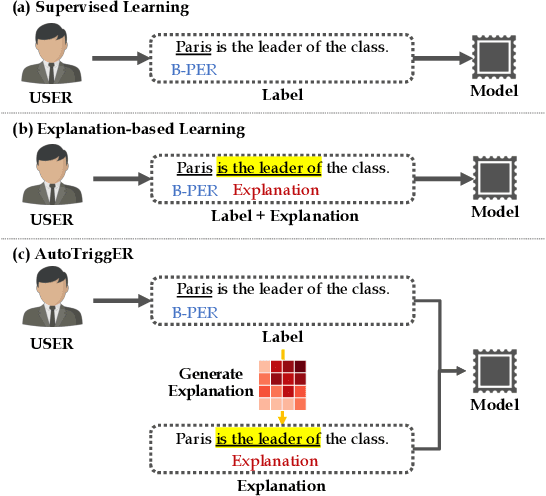
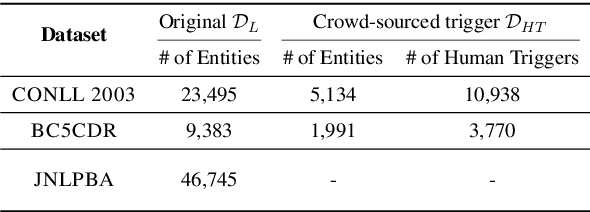

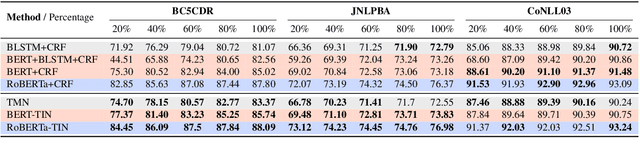
Deep neural models for low-resource named entity recognition (NER) have shown impressive results by leveraging distant super-vision or other meta-level information (e.g. explanation). However, the costs of acquiring such additional information are generally prohibitive, especially in domains where existing resources (e.g. databases to be used for distant supervision) may not exist. In this paper, we present a novel two-stage framework (AutoTriggER) to improve NER performance by automatically generating and leveraging "entity triggers" which are essentially human-readable clues in the text that can help guide the model to make better decisions. Thus, the framework is able to both create and leverage auxiliary supervision by itself. Through experiments on three well-studied NER datasets, we show that our automatically extracted triggers are well-matched to human triggers, and AutoTriggER improves performance over a RoBERTa-CRFarchitecture by nearly 0.5 F1 points on average and much more in a low resource setting.
Event Extraction as Natural Language Generation
Aug 29, 2021
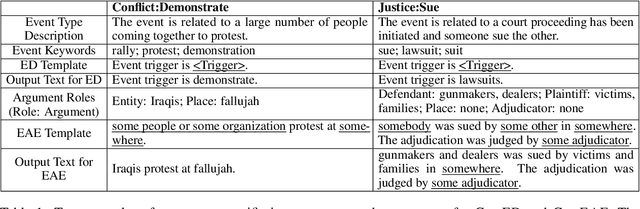
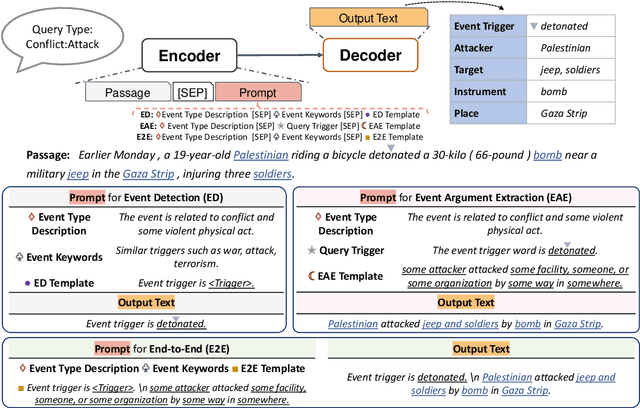
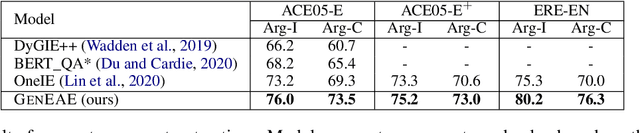
Event extraction (EE), the task that identifies event triggers and their arguments in text, is usually formulated as a classification or structured prediction problem. Such models usually reduce labels to numeric identifiers, making them unable to take advantage of label semantics (e.g. an event type named Arrest is related to words like arrest, detain, or apprehend). This prevents the generalization to new event types. In this work, we formulate EE as a natural language generation task and propose GenEE, a model that not only captures complex dependencies within an event but also generalizes well to unseen or rare event types. Given a passage and an event type, GenEE is trained to generate a natural sentence following a predefined template for that event type. The generated output is then decoded into trigger and argument predictions. The autoregressive generation process naturally models the dependencies among the predictions -- each new word predicted depends on those already generated in the output sentence. Using carefully designed input prompts during generation, GenEE is able to capture label semantics, which enables the generalization to new event types. Empirical results show that our model achieves strong performance on event extraction tasks under all zero-shot, few-shot, and high-resource scenarios. Especially, in the high-resource setting, GenEE outperforms the state-of-the-art model on argument extraction and gets competitive results with the current best on end-to-end EE tasks.
LEAN-LIFE: A Label-Efficient Annotation Framework Towards Learning from Explanation
Apr 16, 2020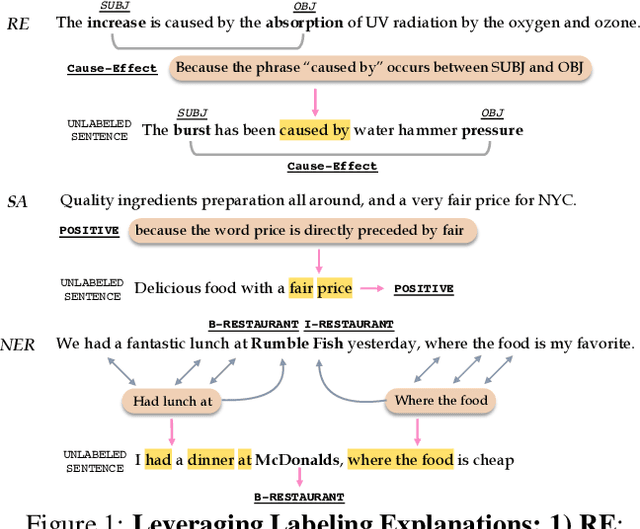
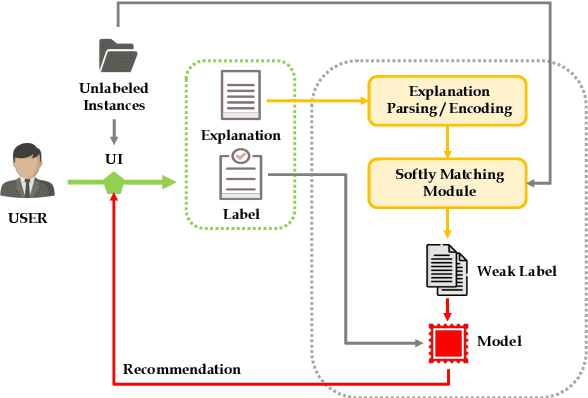

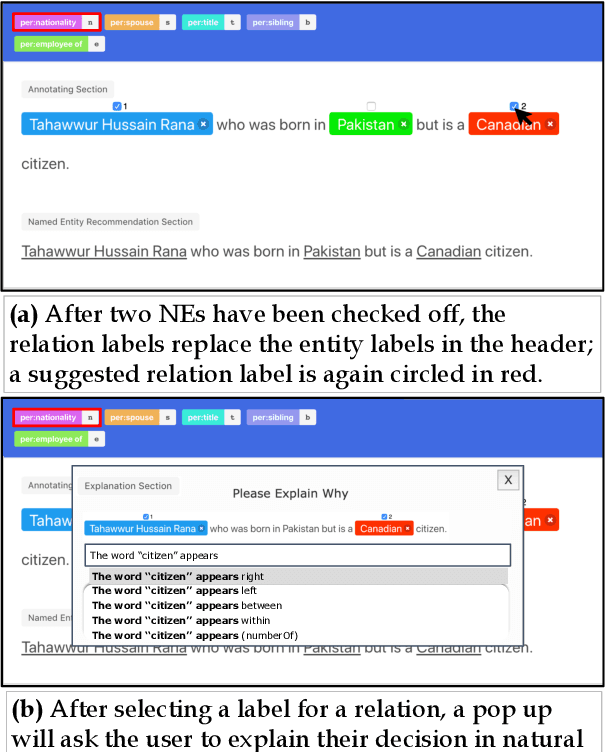
Successfully training a deep neural network demands a huge corpus of labeled data. However, each label only provides limited information to learn from and collecting the requisite number of labels involves massive human effort. In this work, we introduce LEAN-LIFE, a web-based, Label-Efficient AnnotatioN framework for sequence labeling and classification tasks, with an easy-to-use UI that not only allows an annotator to provide the needed labels for a task, but also enables LearnIng From Explanations for each labeling decision. Such explanations enable us to generate useful additional labeled data from unlabeled instances, bolstering the pool of available training data. On three popular NLP tasks (named entity recognition, relation extraction, sentiment analysis), we find that using this enhanced supervision allows our models to surpass competitive baseline F1 scores by more than 5-10 percentage points, while using 2X times fewer labeled instances. Our framework is the first to utilize this enhanced supervision technique and does so for three important tasks -- thus providing improved annotation recommendations to users and an ability to build datasets of (data, label, explanation) triples instead of the regular (data, label) pair.
Learning A Unified Named Entity Tagger From Multiple Partially Annotated Corpora For Efficient Adaptation
Oct 04, 2019
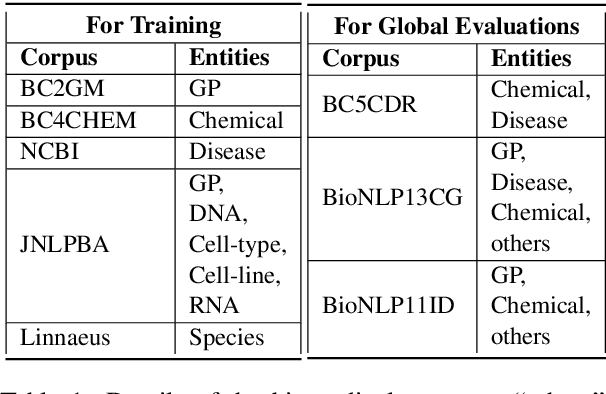
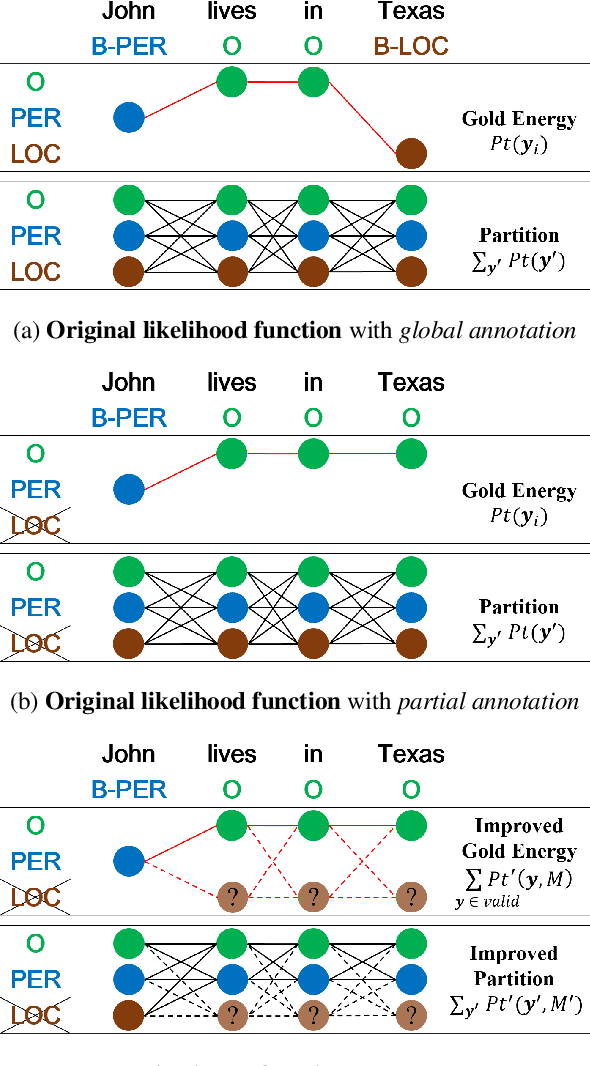
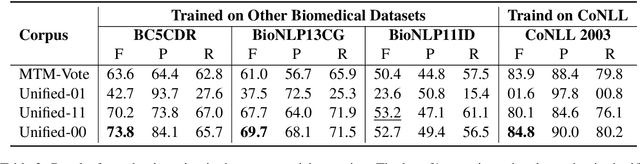
Named entity recognition (NER) identifies typed entity mentions in raw text. While the task is well-established, there is no universally used tagset: often, datasets are annotated for use in downstream applications and accordingly only cover a small set of entity types relevant to a particular task. For instance, in the biomedical domain, one corpus might annotate genes, another chemicals, and another diseases---despite the texts in each corpus containing references to all three types of entities. In this paper, we propose a deep structured model to integrate these "partially annotated" datasets to jointly identify all entity types appearing in the training corpora. By leveraging multiple datasets, the model can learn robust input representations; by building a joint structured model, it avoids potential conflicts caused by combining several models' predictions at test time. Experiments show that the proposed model significantly outperforms strong multi-task learning baselines when training on multiple, partially annotated datasets and testing on datasets that contain tags from more than one of the training corpora.