 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIP: Positional-encoding Image Prior
Nov 25, 2022



In Deep Image Prior (DIP), a Convolutional Neural Network (CNN) is fitted to map a latent space to a degraded (e.g. noisy) image but in the process learns to reconstruct the clean image. This phenomenon is attributed to CNN's internal image-prior. We revisit the DIP framework, examining it from the perspective of a neural implicit representation. Motivated by this perspective, we replace the random or learned latent with Fourier-Features (Positional Encoding). We show that thanks to the Fourier features properties, we can replace the convolution layers with simple pixel-level MLPs. We name this scheme ``Positional Encoding Image Prior" (PIP) and exhibit that it performs very similarly to DIP on various image-reconstruction tasks with much less parameters required. Additionally, we demonstrate that PIP can be easily extended to videos, where 3D-DIP struggles and suffers from instability. Code and additional examples for all tasks, including videos, are available on the project page https://nimrodshabtay.github.io/PIP/
Teaching Structured Vision&Language Concepts to Vision&Language Models
Nov 21, 2022



Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, some aspects of complex language understanding still remain a challenge. We introduce the collective notion of Structured Vision&Language Concepts (SVLC) which includes object attributes, relations, and states which are present in the text and visible in the image. Recent studies have shown that even the best VL models struggle with SVLC. A possible way of fixing this issue is by collecting dedicated datasets for teaching each SVLC type, yet this might be expensive and time-consuming. Instead, we propose a more elegant data-driven approach for enhancing VL models' understanding of SVLCs that makes more effective use of existing VL pre-training datasets and does not require any additional data. While automatic understanding of image structure still remains largely unsolved, language structure is much better modeled and understood, allowing for its effective utilization in teaching VL models. In this paper, we propose various techniques based on language structure understanding that can be used to manipulate the textual part of off-the-shelf paired VL datasets. VL models trained with the updated data exhibit a significant improvement of up to 15% in their SVLC understanding with only a mild degradation in their zero-shot capabilities both when training from scratch or fine-tuning a pre-trained model.
FETA: Towards Specializing Foundation Models for Expert Task Applications
Sep 08, 2022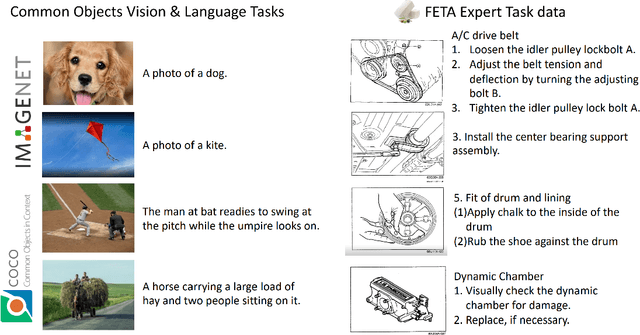

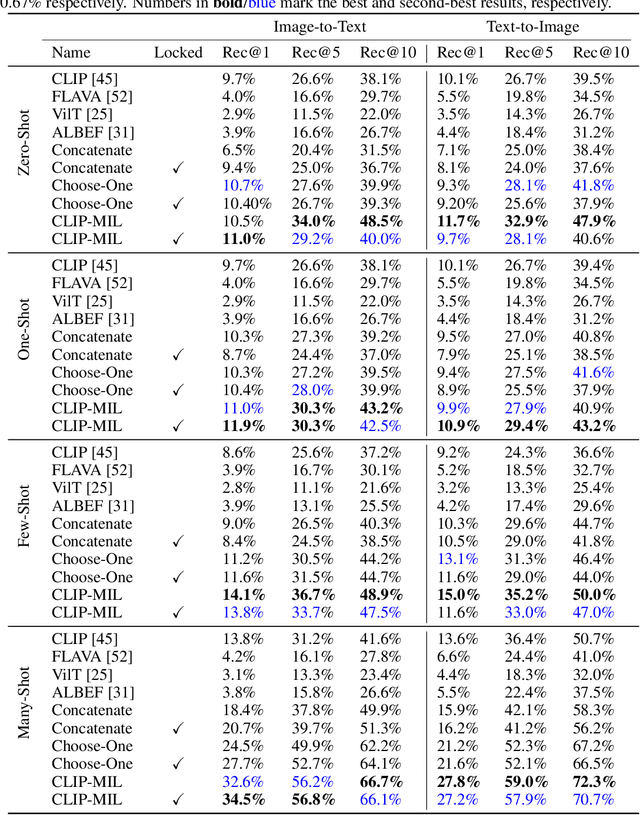
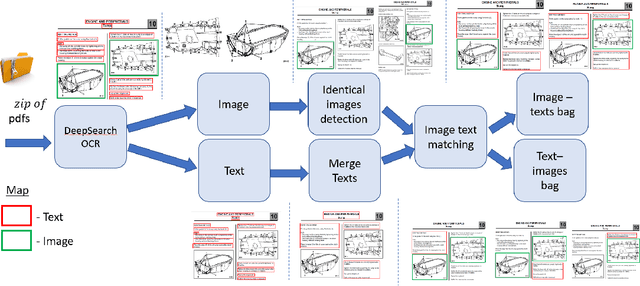
Foundation Models (FMs) have demonstrated unprecedented capabilities including zero-shot learning, high fidelity data synthesis, and out of domain generalization. However, as we show in this paper, FMs still have poor out-of-the-box performance on expert tasks (e.g. retrieval of car manuals technical illustrations from language queries), data for which is either unseen or belonging to a long-tail part of the data distribution of the huge datasets used for FM pre-training. This underlines the necessity to explicitly evaluate and finetune FMs on such expert tasks, arguably ones that appear the most in practical real-world applications. In this paper, we propose a first of its kind FETA benchmark built around the task of teaching FMs to understand technical documentation, via learning to match their graphical illustrations to corresponding language descriptions. Our FETA benchmark focuses on text-to-image and image-to-text retrieval in public car manuals and sales catalogue brochures. FETA is equipped with a procedure for completely automatic annotation extraction (code would be released upon acceptance), allowing easy extension of FETA to more documentation types and application domains in the future. Our automatic annotation leads to an automated performance metric shown to be consistent with metrics computed on human-curated annotations (also released). We provide multiple baselines and analysis of popular FMs on FETA leading to several interesting findings that we believe would be very valuable to the FM community, paving the way towards real-world application of FMs for practical expert tasks currently 'overlooked' by standard benchmarks focusing on common objects.
Unsupervised Domain Generalization by Learning a Bridge Across Domains
Dec 04, 2021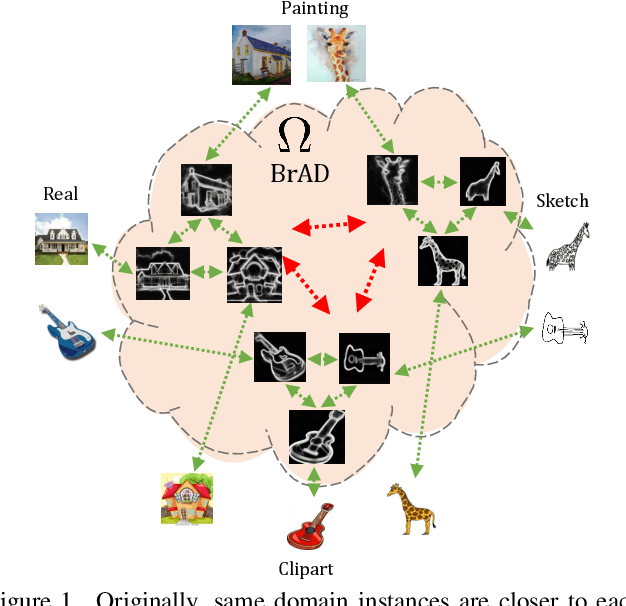
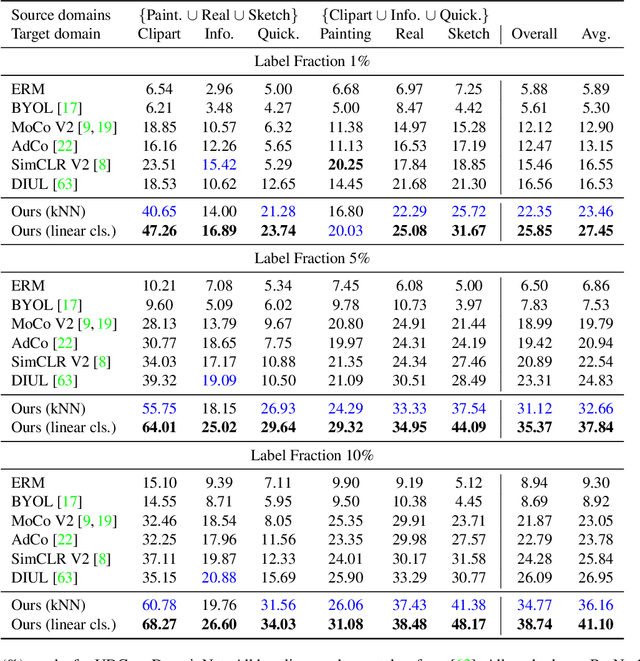
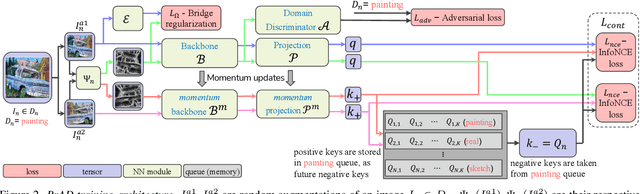
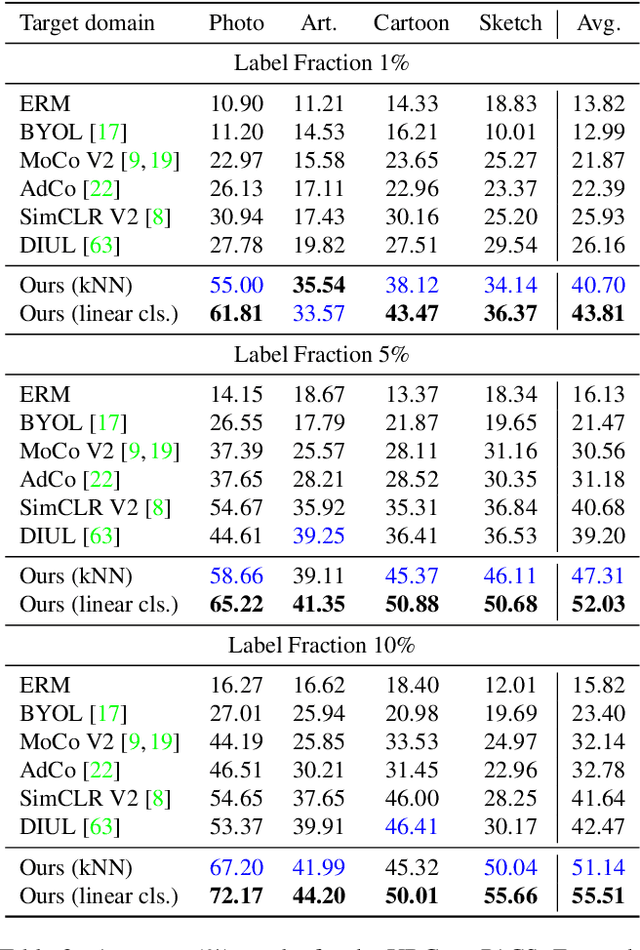
The ability to generalize learned representations across significantly different visual domains, such as between real photos, clipart, paintings, and sketches, is a fundamental capacity of the human visual system. In this paper, different from most cross-domain works that utilize some (or full) source domain supervision, we approach a relatively new and very practical Unsupervised Domain Generalization (UDG) setup of having no training supervision in neither source nor target domains. Our approach is based on self-supervised learning of a Bridge Across Domains (BrAD) - an auxiliary bridge domain accompanied by a set of semantics preserving visual (image-to-image) mappings to BrAD from each of the training domains. The BrAD and mappings to it are learned jointly (end-to-end) with a contrastive self-supervised representation model that semantically aligns each of the domains to its BrAD-projection, and hence implicitly drives all the domains (seen or unseen) to semantically align to each other. In this work, we show how using an edge-regularized BrAD our approach achieves significant gains across multiple benchmarks and a range of tasks, including UDG, Few-shot UDA, and unsupervised generalization across multi-domain datasets (including generalization to unseen domains and classes).
Detector-Free Weakly Supervised Grounding by Separation
Apr 20, 2021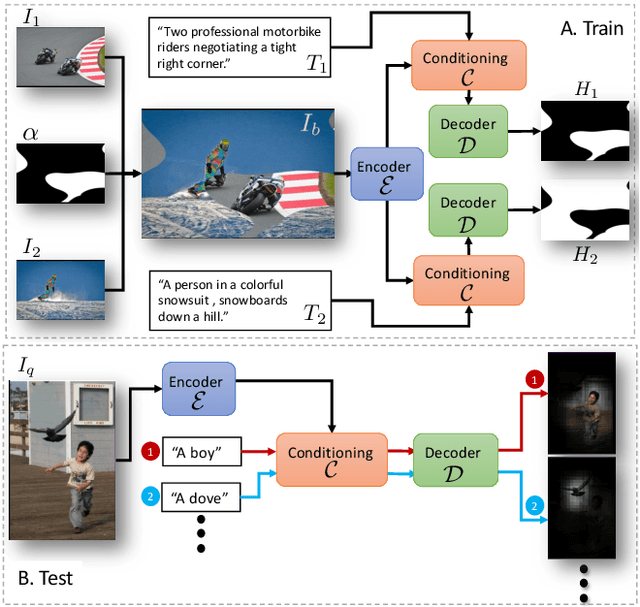
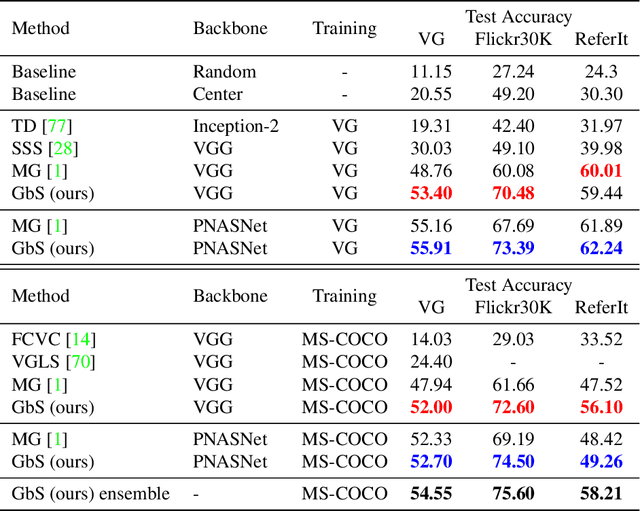
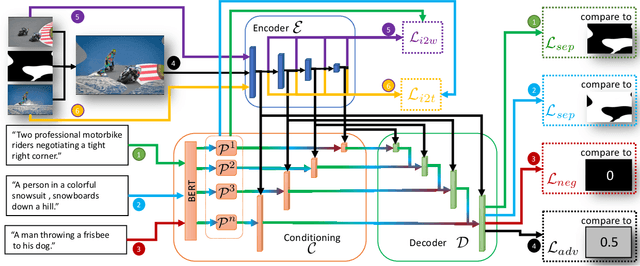
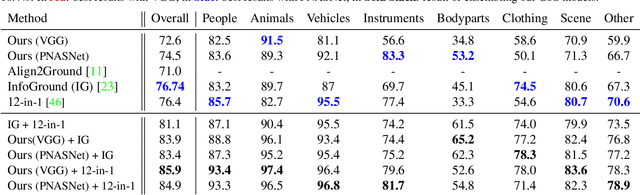
Nowadays, there is an abundance of data involving images and surrounding free-form text weakly corresponding to those images. Weakly Supervised phrase-Grounding (WSG) deals with the task of using this data to learn to localize (or to ground) arbitrary text phrases in images without any additional annotations. However, most recent SotA methods for WSG assume the existence of a pre-trained object detector, relying on it to produce the ROIs for localization. In this work, we focus on the task of Detector-Free WSG (DF-WSG) to solve WSG without relying on a pre-trained detector. We directly learn everything from the images and associated free-form text pairs, thus potentially gaining an advantage on the categories unsupported by the detector. The key idea behind our proposed Grounding by Separation (GbS) method is synthesizing `text to image-regions' associations by random alpha-blending of arbitrary image pairs and using the corresponding texts of the pair as conditions to recover the alpha map from the blended image via a segmentation network. At test time, this allows using the query phrase as a condition for a non-blended query image, thus interpreting the test image as a composition of a region corresponding to the phrase and the complement region. Using this approach we demonstrate a significant accuracy improvement, of up to $8.5\%$ over previous DF-WSG SotA, for a range of benchmarks including Flickr30K, Visual Genome, and ReferIt, as well as a significant complementary improvement (above $7\%$) over the detector-based approaches for WSG.
ISP Distillation
Jan 25, 2021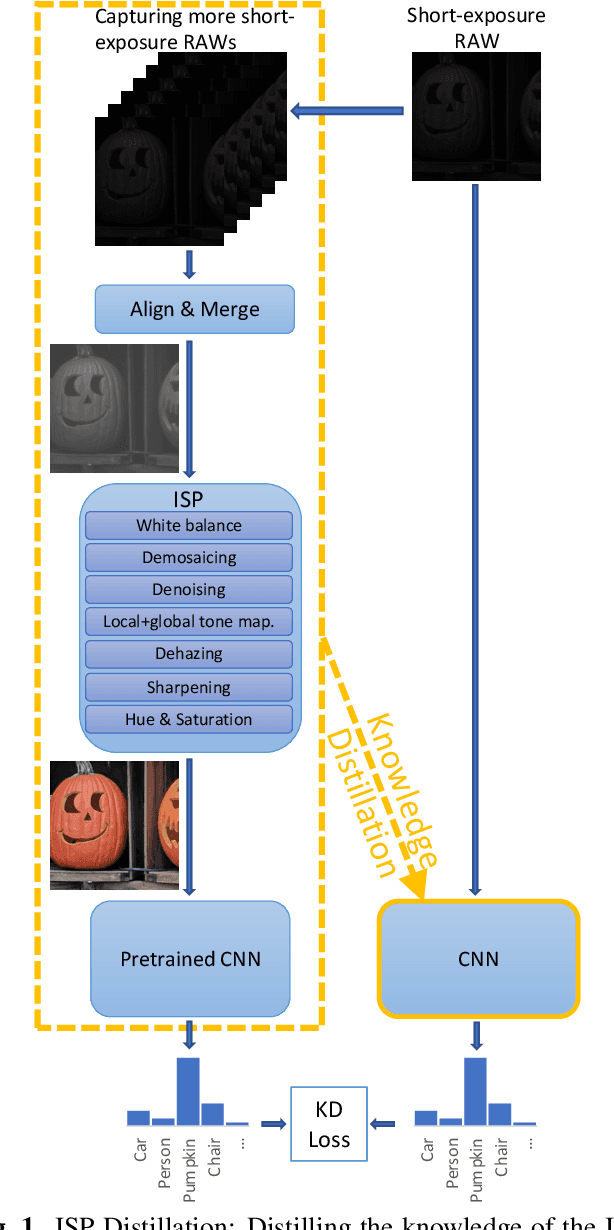
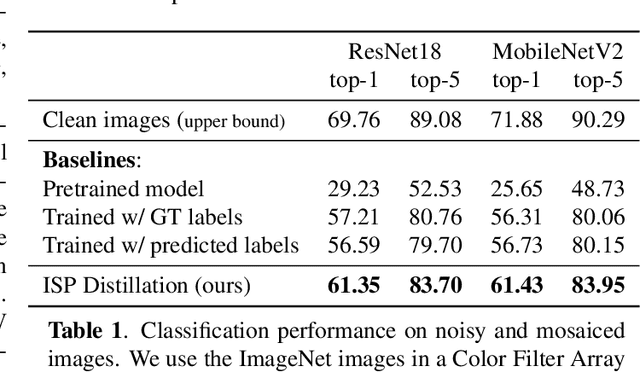
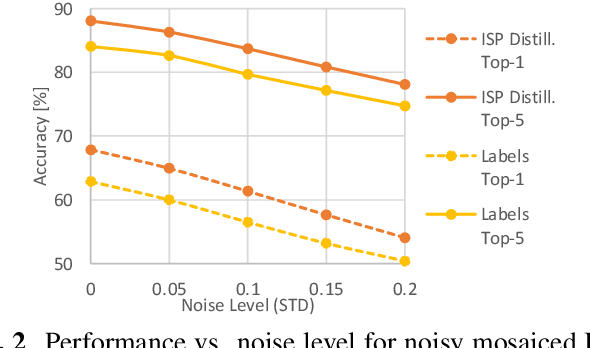
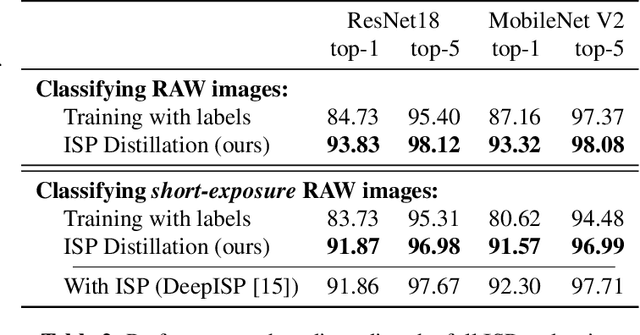
Nowadays, many of the images captured are "observed" by machines only and not by humans, for example, robots' or autonomous cars' cameras. High-level machine vision models, such as object recognition, assume images are transformed to some canonical image space by the camera ISP. However, the camera ISP is optimized for producing visually pleasing images to human observers and not for machines, thus, one may spare the ISP compute time and apply the vision models directly to the raw data. Yet, it has been shown that training such models directly on the RAW images results in a performance drop. To mitigate this drop in performance (without the need to annotate RAW data), we use a dataset of RAW and RGB image pairs, which can be easily acquired with no human labeling. We then train a model that is applied directly to the RAW data by using knowledge distillation such that the model predictions for RAW images will be aligned with the predictions of an off-the-shelf pre-trained model for processed RGB images. Our experiments show that our performance on RAW images is significantly better than a model trained on labeled RAW images. It also reasonably matches the predictions of a pre-trained model on processed RGB images, while saving the ISP compute overhead.
Fine-grained Angular Contrastive Learning with Coarse Labels
Dec 07, 2020
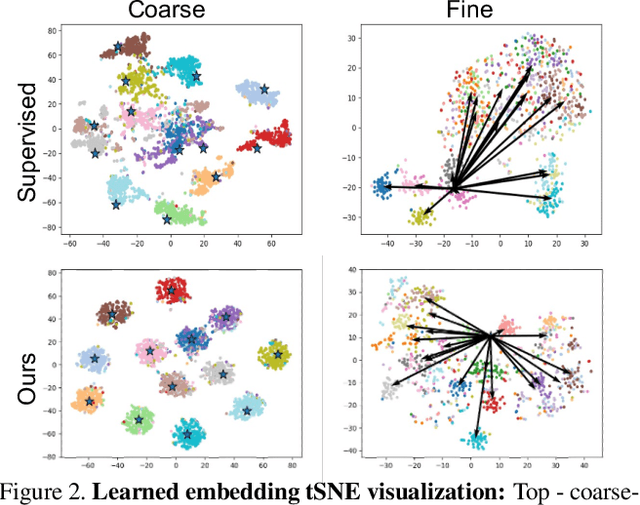
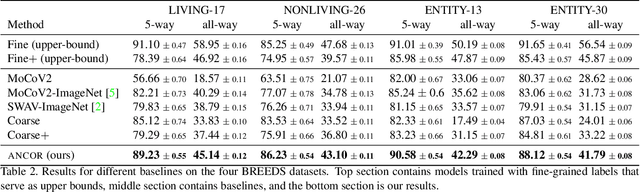
Few-shot learning methods offer pre-training techniques optimized for easier later adaptation of the model to new classes (unseen during training) using one or a few examples. This adaptivity to unseen classes is especially important for many practical applications where the pre-trained label space cannot remain fixed for effective use and the model needs to be "specialized" to support new categories on the fly. One particularly interesting scenario, essentially overlooked by the few-shot literature, is Coarse-to-Fine Few-Shot (C2FS), where the training classes (e.g. animals) are of much `coarser granularity' than the target (test) classes (e.g. breeds). A very practical example of C2FS is when the target classes are sub-classes of the training classes. Intuitively, it is especially challenging as (both regular and few-shot) supervised pre-training tends to learn to ignore intra-class variability which is essential for separating sub-classes. In this paper, we introduce a novel 'Angular normalization' module that allows to effectively combine supervised and self-supervised contrastive pre-training to approach the proposed C2FS task, demonstrating significant gains in a broad study over multiple baselines and datasets. We hope that this work will help to pave the way for future research on this new, challenging, and very practical topic of C2FS classification.
StarNet: towards weakly supervised few-shot detection and explainable few-shot classification
Mar 15, 2020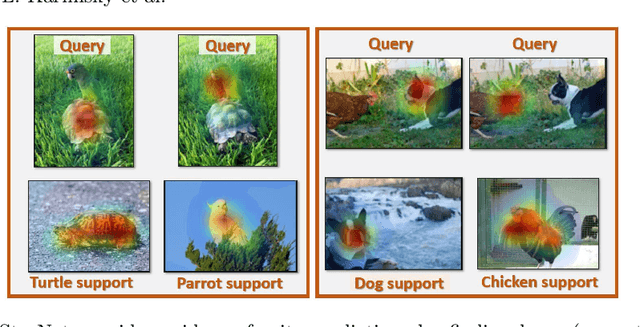
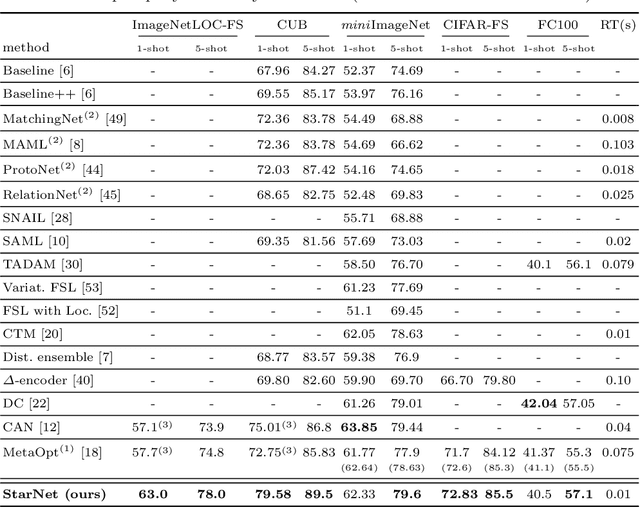
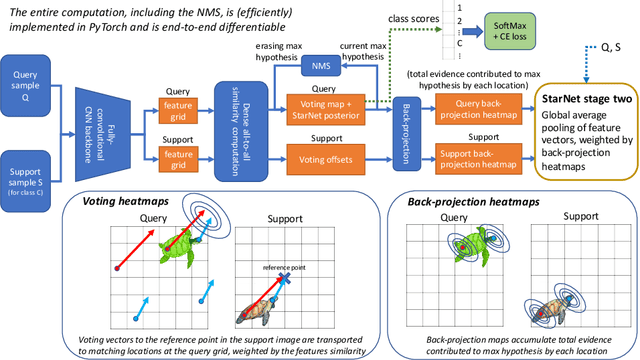
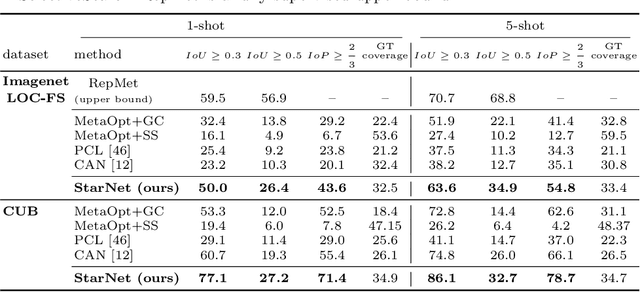
In this paper, we propose a new few-shot learning method called StarNet, which is an end-to-end trainable non-parametric star-model few-shot classifier. While being meta-trained using only image-level class labels, StarNet learns not only to predict the class labels for each query image of a few-shot task, but also to localize (via a heatmap) what it believes to be the key image regions supporting its prediction, thus effectively detecting the instances of the novel categories. The localization is enabled by the StarNet's ability to find large, arbitrarily shaped, semantically matching regions between all pairs of support and query images of a few-shot task. We evaluate StarNet on multiple few-shot classification benchmarks attaining significant state-of-the-art improvement on the CUB and ImageNetLOC-FS, and smaller improvements on other benchmarks. At the same time, in many cases, StarNet provides plausible explanations for its class label predictions, by highlighting the correctly paired novel category instances on the query and on its best matching support (for the predicted class). In addition, we test the proposed approach on the previously unexplored and challenging task of Weakly Supervised Few-Shot Object Detection (WS-FSOD), obtaining significant improvements over the baselines.
MetAdapt: Meta-Learned Task-Adaptive Architecture for Few-Shot Classification
Dec 03, 2019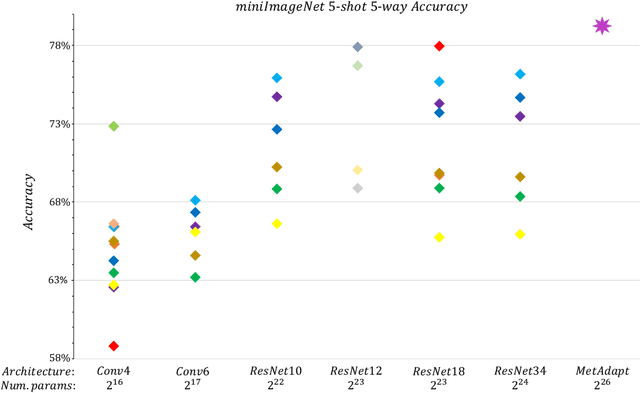

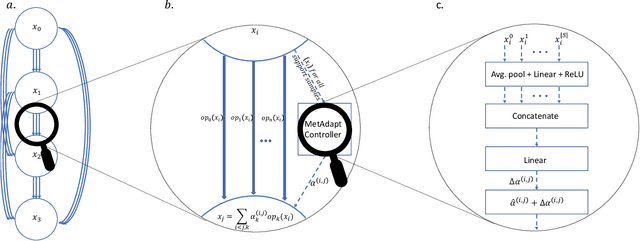
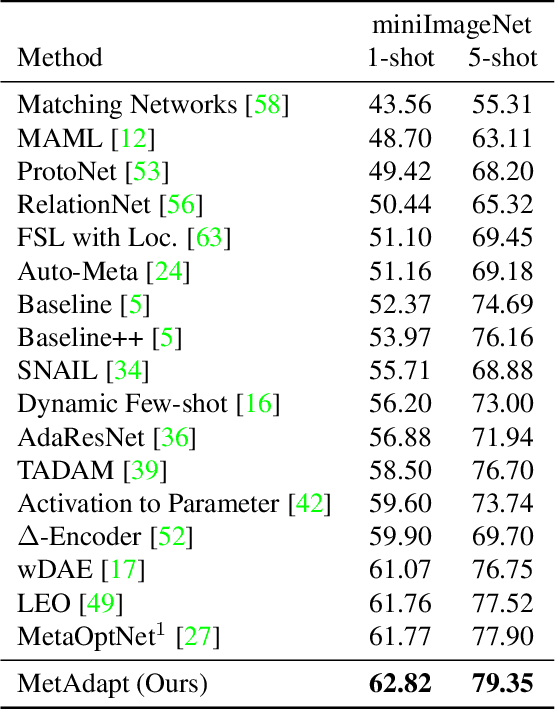
Few-Shot Learning (FSL) is a topic of rapidly growing interest. Typically, in FSL a model is trained on a dataset consisting of many small tasks (meta-tasks) and learns to adapt to novel tasks that it will encounter during test time. This is also referred to as meta-learning. So far, meta-learning FSL methods have focused on optimizing parameters of pre-defined network architectures, in order to make them easily adaptable to novel tasks. Moreover, it was observed that, in general, larger architectures perform better than smaller ones up to a certain saturation point (and even degrade due to over-fitting). However, little attention has been given to explicitly optimizing the architectures for FSL, nor to an adaptation of the architecture at test time to particular novel tasks. In this work, we propose to employ tools borrowed from the Differentiable Neural Architecture Search (D-NAS) literature in order to optimize the architecture for FSL without over-fitting. Additionally, to make the architecture task adaptive, we propose the concept of `MetAdapt Controller' modules. These modules are added to the model and are meta-trained to predict the optimal network connections for a given novel task. Using the proposed approach we observe state-of-the-art results on two popular few-shot benchmarks: miniImageNet and FC100.
Baby steps towards few-shot learning with multiple semantics
Jun 05, 2019

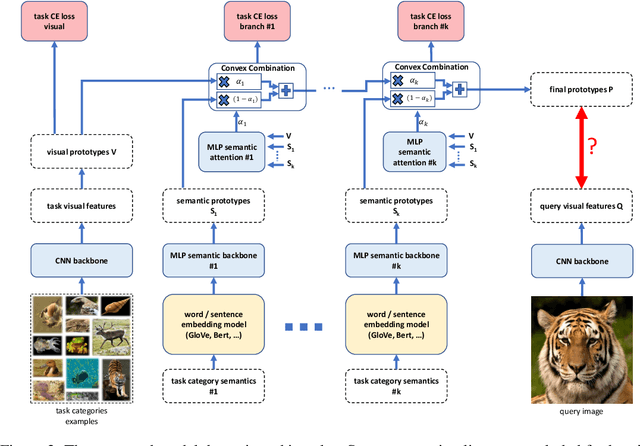
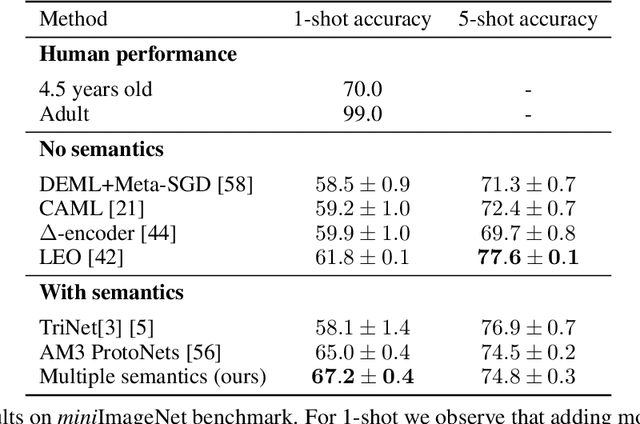
Learning from one or few visual examples is one of the key capabilities of humans since early infancy, but is still a significant challenge for modern AI systems. While considerable progress has been achieved in few-shot learning from a few image examples, much less attention has been given to the verbal descriptions that are usually provided to infants when they are presented with a new object. In this paper, we focus on the role of additional semantics that can significantly facilitate few-shot visual learning. Building upon recent advances in few-shot learning with additional semantic information, we demonstrate that further improvements are possible using richer semantics and multiple semantic sources. Using these ideas, we offer the community a new result on the one-shot test of the popular miniImageNet benchmark, comparing favorably to the previous state-of-the-art results for both visual only and visual plus semantics-based approaches. We also performed an ablation study investigating the components and design choices of our approach.