 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Classifiers with Label Noise Modeling and Distance Awareness
Oct 06, 2021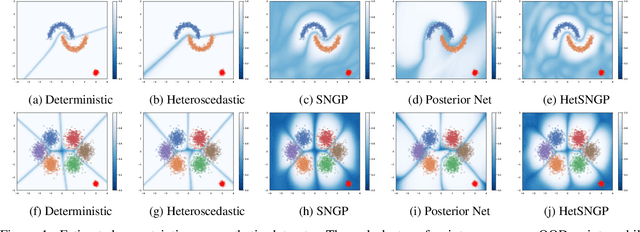



Uncertainty estimation in deep learning has recently emerged as a crucial area of interest to advance reliability and robustness in safety-critical applications. While there have been many proposed methods that either focus on distance-aware model uncertainties for out-of-distribution detection or on input-dependent label uncertainties for in-distribution calibration, both of these types of uncertainty are often necessary. In this work, we propose the HetSNGP method for jointly modeling the model and data uncertainty. We show that our proposed model affords a favorable combination between these two complementary types of uncertainty and thus outperforms the baseline methods on some challenging out-of-distribution datasets, including CIFAR-100C, Imagenet-C, and Imagenet-A. Moreover, we propose HetSNGP Ensemble, an ensembled version of our method which adds an additional type of uncertainty and also outperforms other ensemble baselines.
Soft Calibration Objectives for Neural Networks
Jul 30, 2021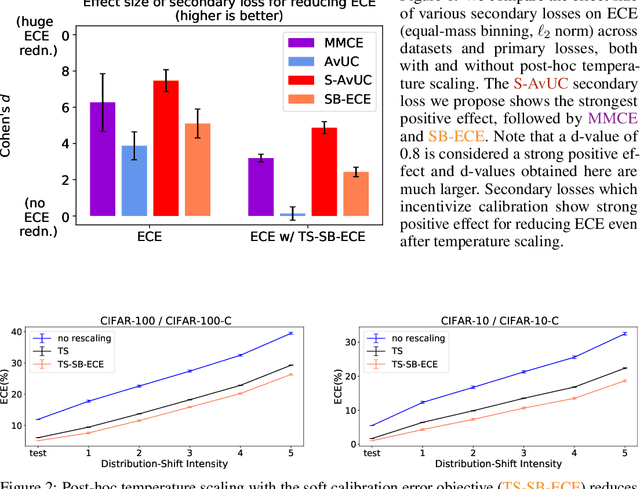
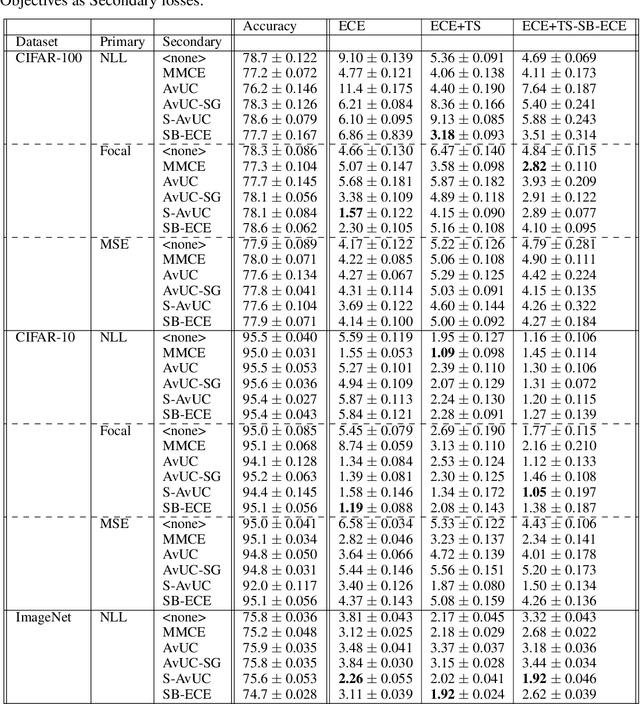
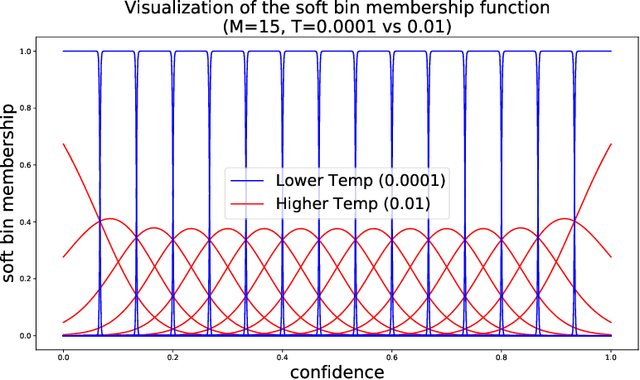
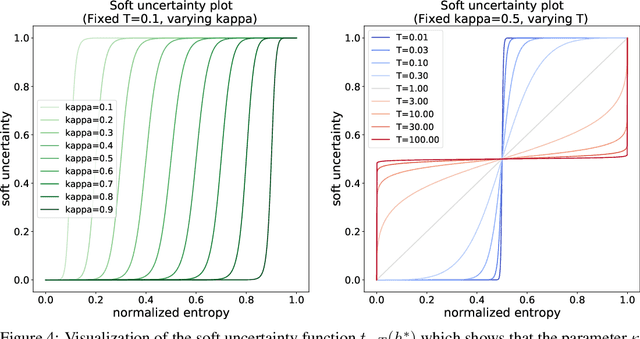
Optimal decision making requires that classifiers produce uncertainty estimates consistent with their empirical accuracy. However, deep neural networks are often under- or over-confident in their predictions. Consequently, methods have been developed to improve the calibration of their predictive uncertainty both during training and post-hoc. In this work, we propose differentiable losses to improve calibration based on a soft (continuous) version of the binning operation underlying popular calibration-error estimators. When incorporated into training, these soft calibration losses achieve state-of-the-art single-model ECE across multiple datasets with less than 1% decrease in accuracy. For instance, we observe an 82% reduction in ECE (70% relative to the post-hoc rescaled ECE) in exchange for a 0.7% relative decrease in accuracy relative to the cross entropy baseline on CIFAR-100. When incorporated post-training, the soft-binning-based calibration error objective improves upon temperature scaling, a popular recalibration method. Overall, experiments across losses and datasets demonstrate that using calibration-sensitive procedures yield better uncertainty estimates under dataset shift than the standard practice of using a cross entropy loss and post-hoc recalibration methods.
Revisiting the Calibration of Modern Neural Networks
Jun 15, 2021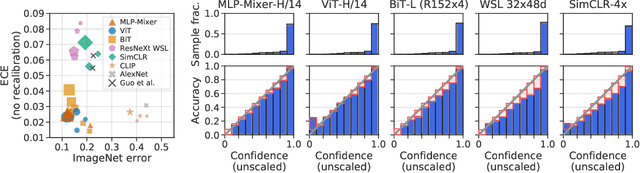

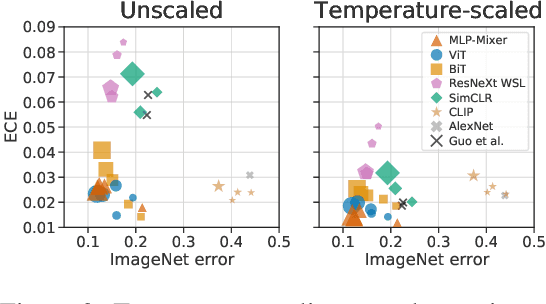
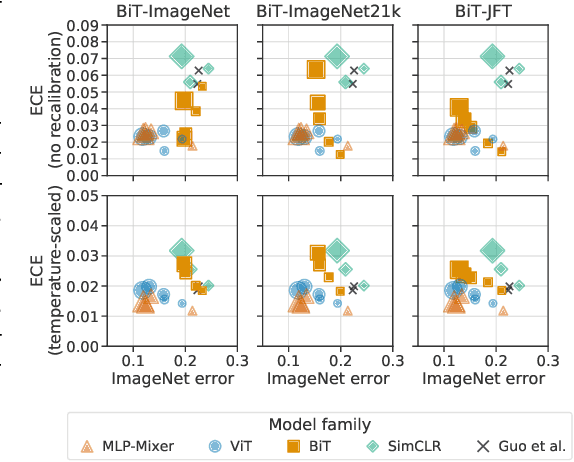
Accurate estimation of predictive uncertainty (model calibration) is essential for the safe application of neural networks. Many instances of miscalibration in modern neural networks have been reported, suggesting a trend that newer, more accurate models produce poorly calibrated predictions. Here, we revisit this question for recent state-of-the-art image classification models. We systematically relate model calibration and accuracy, and find that the most recent models, notably those not using convolutions, are among the best calibrated. Trends observed in prior model generations, such as decay of calibration with distribution shift or model size, are less pronounced in recent architectures. We also show that model size and amount of pretraining do not fully explain these differences, suggesting that architecture is a major determinant of calibration properties.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021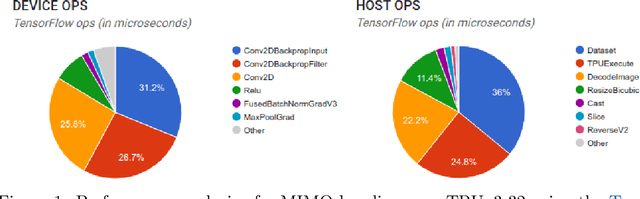
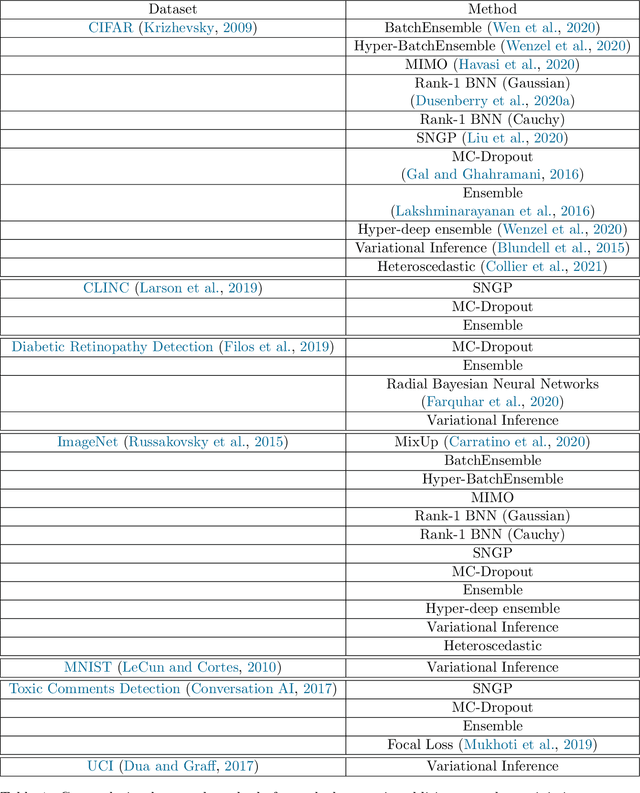
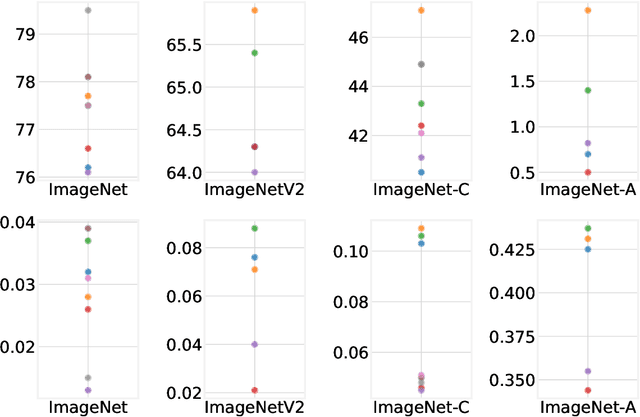
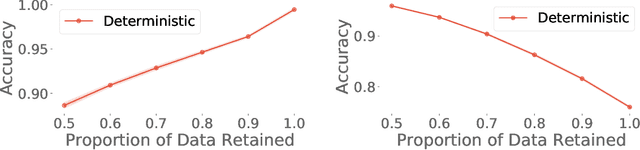
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
RecSim NG: Toward Principled Uncertainty Modeling for Recommender Ecosystems
Mar 14, 2021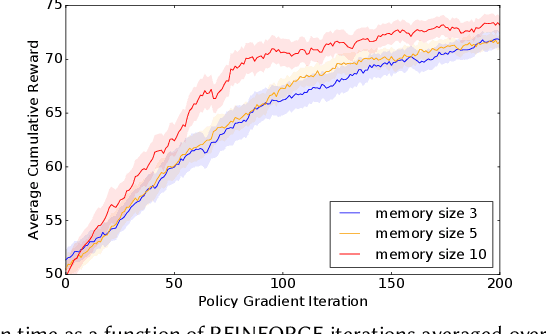
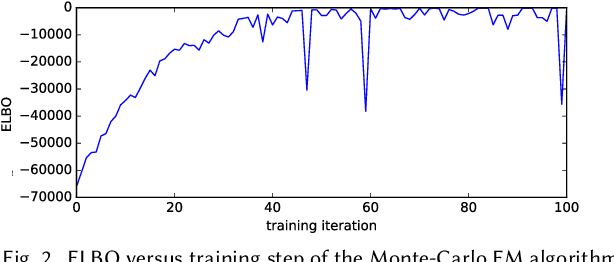
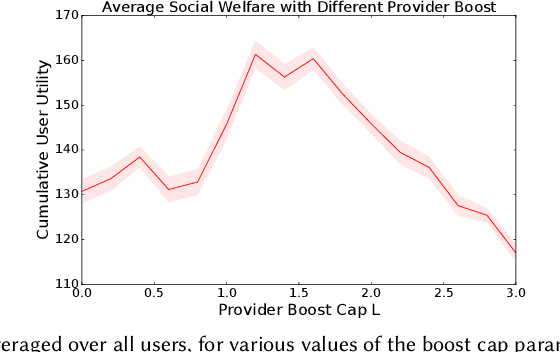
The development of recommender systems that optimize multi-turn interaction with users, and model the interactions of different agents (e.g., users, content providers, vendors) in the recommender ecosystem have drawn increasing attention in recent years. Developing and training models and algorithms for such recommenders can be especially difficult using static datasets, which often fail to offer the types of counterfactual predictions needed to evaluate policies over extended horizons. To address this, we develop RecSim NG, a probabilistic platform for the simulation of multi-agent recommender systems. RecSim NG is a scalable, modular, differentiable simulator implemented in Edward2 and TensorFlow. It offers: a powerful, general probabilistic programming language for agent-behavior specification; tools for probabilistic inference and latent-variable model learning, backed by automatic differentiation and tracing; and a TensorFlow-based runtime for running simulations on accelerated hardware. We describe RecSim NG and illustrate how it can be used to create transparent, configurable, end-to-end models of a recommender ecosystem, complemented by a small set of simple use cases that demonstrate how RecSim NG can help both researchers and practitioners easily develop and train novel algorithms for recommender systems.
Combining Ensembles and Data Augmentation can Harm your Calibration
Oct 19, 2020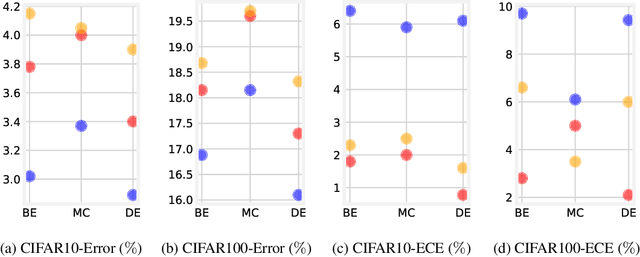
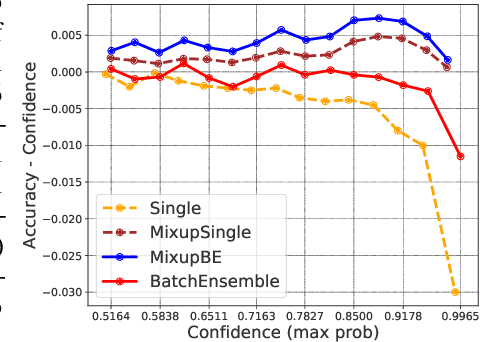
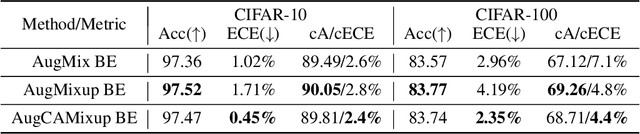
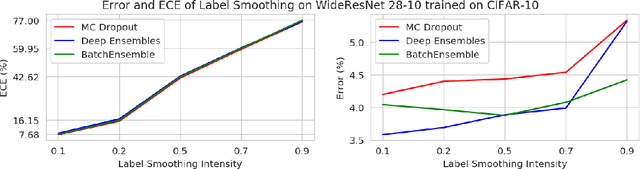
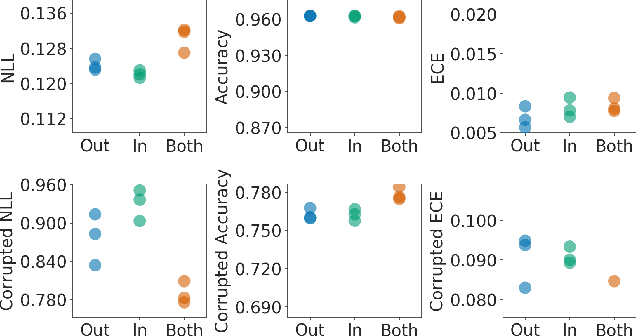
Ensemble methods which average over multiple neural network predictions are a simple approach to improve a model's calibration and robustness. Similarly, data augmentation techniques, which encode prior information in the form of invariant feature transformations, are effective for improving calibration and robustness. In this paper, we show a surprising pathology: combining ensembles and data augmentation can harm model calibration. This leads to a trade-off in practice, whereby improved accuracy by combining the two techniques comes at the expense of calibration. On the other hand, selecting only one of the techniques ensures good uncertainty estimates at the expense of accuracy. We investigate this pathology and identify a compounding under-confidence among methods which marginalize over sets of weights and data augmentation techniques which soften labels. Finally, we propose a simple correction, achieving the best of both worlds with significant accuracy and calibration gains over using only ensembles or data augmentation individually. Applying the correction produces new state-of-the art in uncertainty calibration across CIFAR-10, CIFAR-100, and ImageNet.
Training independent subnetworks for robust prediction
Oct 13, 2020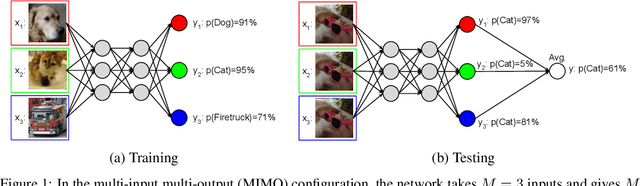
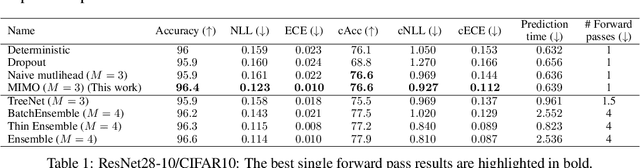

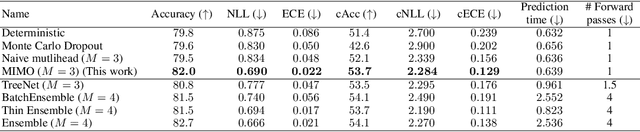
Recent approaches to efficiently ensemble neural networks have shown that strong robustness and uncertainty performance can be achieved with a negligible gain in parameters over the original network. However, these methods still require multiple forward passes for prediction, leading to a significant computational cost. In this work, we show a surprising result: the benefits of using multiple predictions can be achieved `for free' under a single model's forward pass. In particular, we show that, using a multi-input multi-output (MIMO) configuration, one can utilize a single model's capacity to train multiple subnetworks that independently learn the task at hand. By ensembling the predictions made by the subnetworks, we improve model robustness without increasing compute. We observe a significant improvement in negative log-likelihood, accuracy, and calibration error on CIFAR10, CIFAR100, ImageNet, and their out-of-distribution variants compared to previous methods.
Hyperparameter Ensembles for Robustness and Uncertainty Quantification
Jun 24, 2020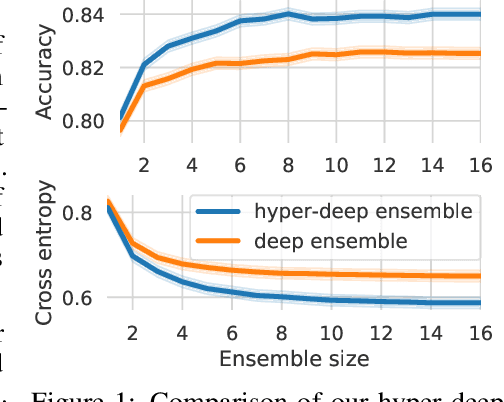
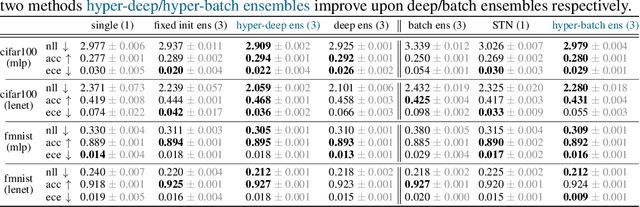

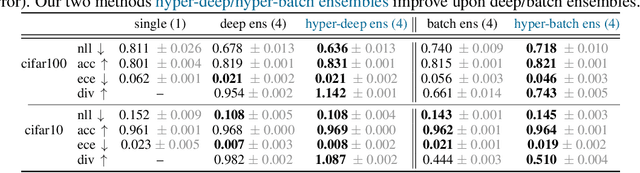
Ensembles over neural network weights trained from different random initialization, known as deep ensembles, achieve state-of-the-art accuracy and calibration. The recently introduced batch ensembles provide a drop-in replacement that is more parameter efficient. In this paper, we design ensembles not only over weights, but over hyperparameters to improve the state of the art in both settings. For best performance independent of budget, we propose hyper-deep ensembles, a simple procedure that involves a random search over different hyperparameters, themselves stratified across multiple random initializations. Its strong performance highlights the benefit of combining models with both weight and hyperparameter diversity. We further propose a parameter efficient version, hyper-batch ensembles, which builds on the layer structure of batch ensembles and self-tuning networks. The computational and memory costs of our method are notably lower than typical ensembles. On image classification tasks, with MLP, LeNet, and Wide ResNet 28-10 architectures, our methodology improves upon both deep and batch ensembles.
Simple and Principled Uncertainty Estimation with Deterministic Deep Learning via Distance Awareness
Jun 17, 2020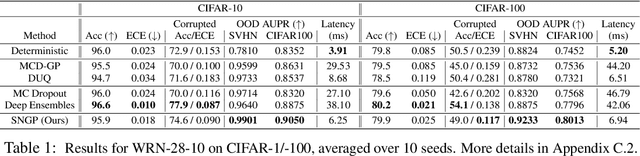
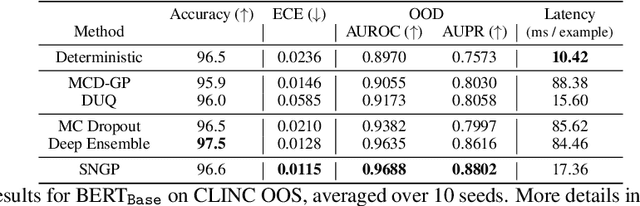
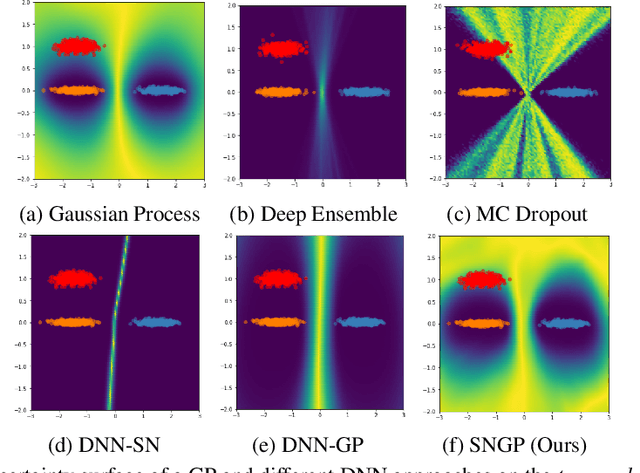
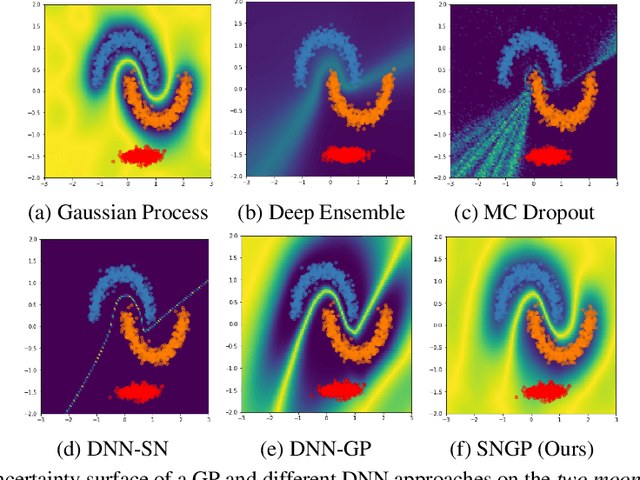
Bayesian neural networks (BNN) and deep ensembles are principled approaches to estimate the predictive uncertainty of a deep learning model. However their practicality in real-time, industrial-scale applications are limited due to their heavy memory and inference cost. This motivates us to study principled approaches to high-quality uncertainty estimation that require only a single deep neural network (DNN). By formalizing the uncertainty quantification as a minimax learning problem, we first identify input distance awareness, i.e., the model's ability to quantify the distance of a testing example from the training data in the input space, as a necessary condition for a DNN to achieve high-quality (i.e., minimax optimal) uncertainty estimation. We then propose Spectral-normalized Neural Gaussian Process (SNGP), a simple method that improves the distance-awareness ability of modern DNNs, by adding a weight normalization step during training and replacing the output layer with a Gaussian process. On a suite of vision and language understanding tasks and on modern architectures (Wide-ResNet and BERT), SNGP is competitive with deep ensembles in prediction, calibration and out-of-domain detection, and outperforms the other single-model approaches.
Efficient and Scalable Bayesian Neural Nets with Rank-1 Factors
May 14, 2020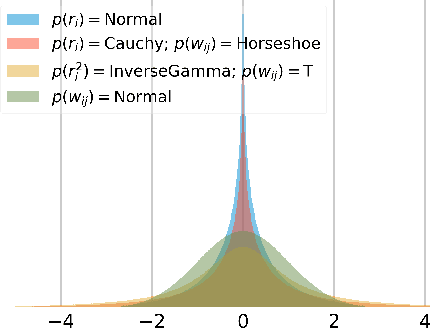
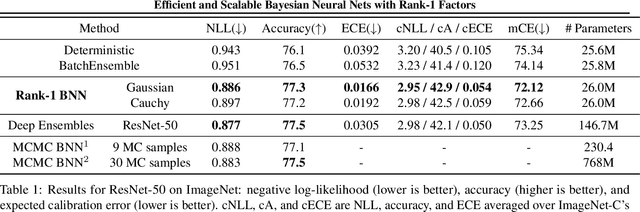
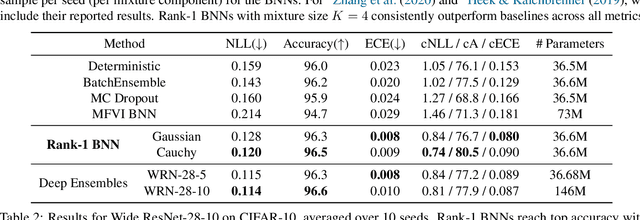
Bayesian neural networks (BNNs) demonstrate promising success in improving the robustness and uncertainty quantification of modern deep learning. However, they generally struggle with underfitting at scale and parameter efficiency. On the other hand, deep ensembles have emerged as alternatives for uncertainty quantification that, while outperforming BNNs on certain problems, also suffer from efficiency issues. It remains unclear how to combine the strengths of these two approaches and remediate their common issues. To tackle this challenge, we propose a rank-1 parameterization of BNNs, where each weight matrix involves only a distribution on a rank-1 subspace. We also revisit the use of mixture approximate posteriors to capture multiple modes, where unlike typical mixtures, this approach admits a significantly smaller memory increase (e.g., only a 0.4% increase for a ResNet-50 mixture of size 10). We perform a systematic empirical study on the choices of prior, variational posterior, and methods to improve training. For ResNet-50 on ImageNet, Wide ResNet 28-10 on CIFAR-10/100, and an RNN on MIMIC-III, rank-1 BNNs achieve state-of-the-art performance across log-likelihood, accuracy, and calibration on the test sets and out-of-distribution variants.