 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeTaQA: Free-form Table Question Answering
Apr 01, 2021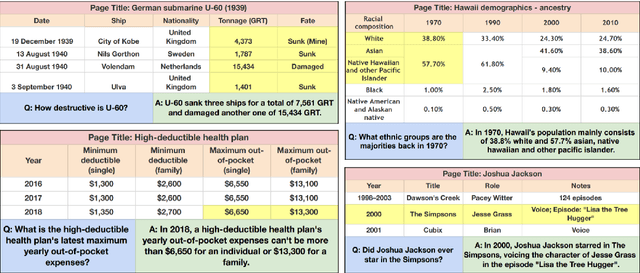

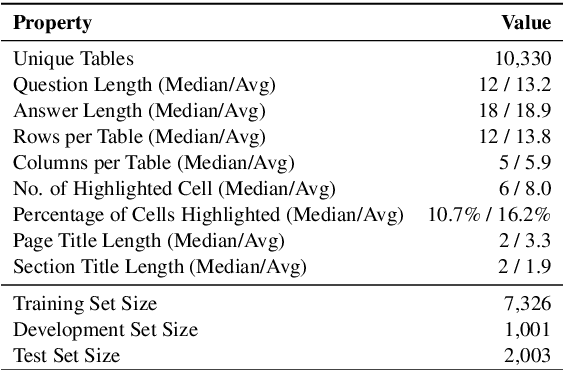
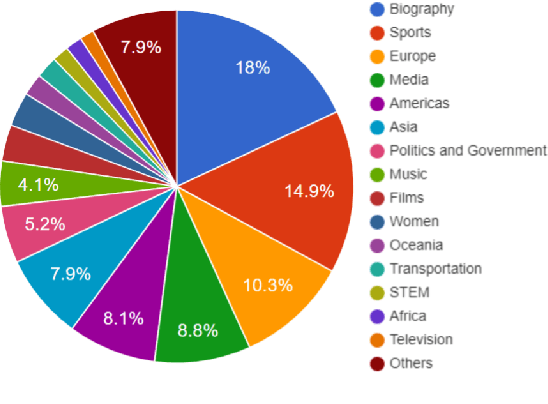
Existing table question answering datasets contain abundant factual questions that primarily evaluate the query and schema comprehension capability of a system, but they fail to include questions that require complex reasoning and integration of information due to the constraint of the associated short-form answers. To address these issues and to demonstrate the full challenge of table question answering, we introduce FeTaQA, a new dataset with 10K Wikipedia-based {table, question, free-form answer, supporting table cells} pairs. FeTaQA yields a more challenging table question answering setting because it requires generating free-form text answers after retrieval, inference, and integration of multiple discontinuous facts from a structured knowledge source. Unlike datasets of generative QA over text in which answers are prevalent with copies of short text spans from the source, answers in our dataset are human-generated explanations involving entities and their high-level relations. We provide two benchmark methods for the proposed task: a pipeline method based on semantic-parsing-based QA systems and an end-to-end method based on large pretrained text generation models, and show that FeTaQA poses a challenge for both methods.
Improving Zero and Few-Shot Abstractive Summarization with Intermediate Fine-tuning and Data Augmentation
Oct 24, 2020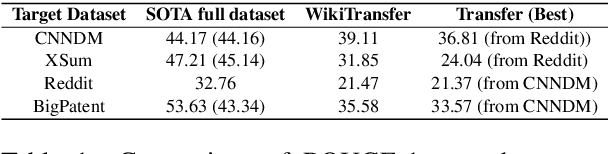
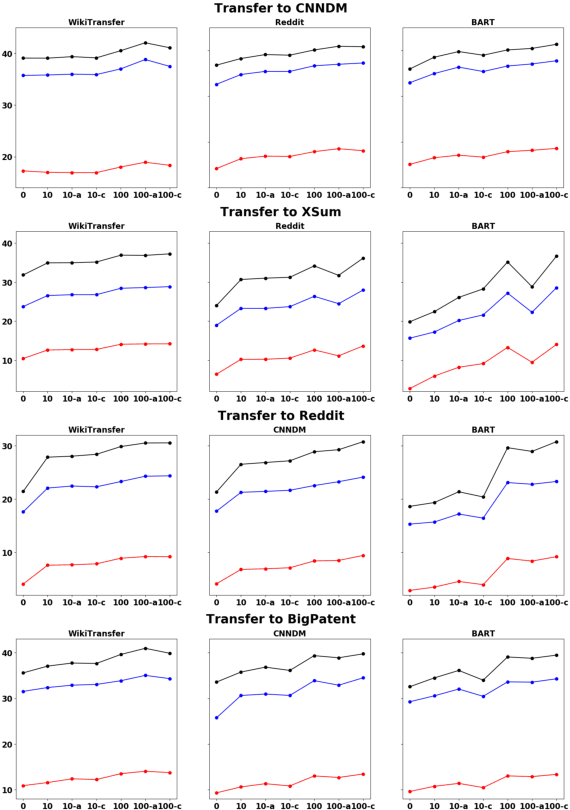

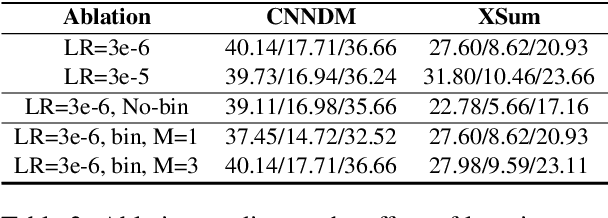
Models pretrained with self-supervised objectives on large text corpora achieve state-of-the-art performance on text summarization tasks. However, these models are typically fine-tuned on hundreds of thousands of data points, an infeasible requirement when applying summarization to new, niche domains. In this work, we introduce a general method, called WikiTransfer, for fine-tuning pretrained models for summarization in an unsupervised, dataset-specific manner which makes use of characteristics of the target dataset such as the length and abstractiveness of the desired summaries. We achieve state-of-the-art, zero-shot abstractive summarization performance on the CNN-DailyMail dataset and demonstrate the effectiveness of our approach on three additional, diverse datasets. The models fine-tuned in this unsupervised manner are more robust to noisy data and also achieve better few-shot performance using 10 and 100 training examples. We perform ablation studies on the effect of the components of our unsupervised fine-tuning data and analyze the performance of these models in few-shot scenarios along with data augmentation techniques using both automatic and human evaluation.
Universal Natural Language Processing with Limited Annotations: Try Few-shot Textual Entailment as a Start
Oct 06, 2020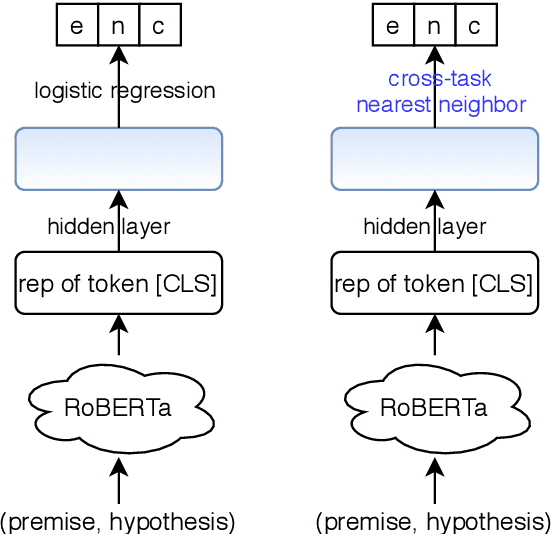
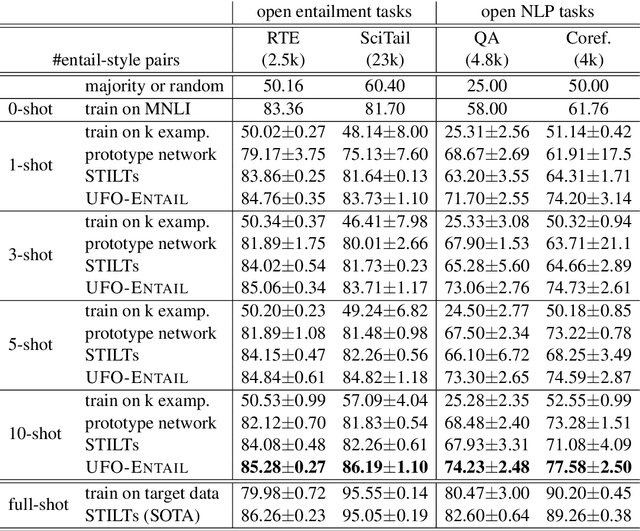
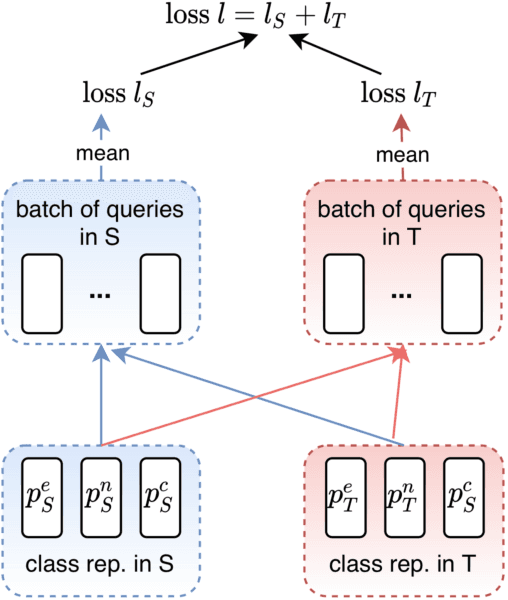
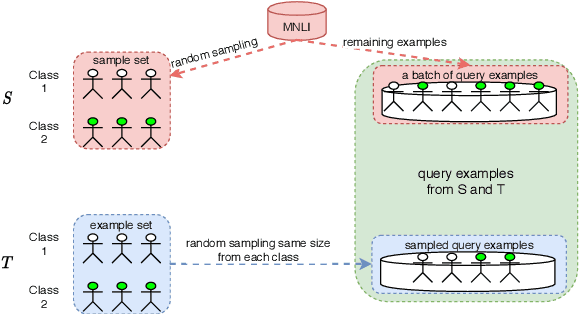
A standard way to address different NLP problems is by first constructing a problem-specific dataset, then building a model to fit this dataset. To build the ultimate artificial intelligence, we desire a single machine that can handle diverse new problems, for which task-specific annotations are limited. We bring up textual entailment as a unified solver for such NLP problems. However, current research of textual entailment has not spilled much ink on the following questions: (i) How well does a pretrained textual entailment system generalize across domains with only a handful of domain-specific examples? and (ii) When is it worth transforming an NLP task into textual entailment? We argue that the transforming is unnecessary if we can obtain rich annotations for this task. Textual entailment really matters particularly when the target NLP task has insufficient annotations. Universal NLP can be probably achieved through different routines. In this work, we introduce Universal Few-shot textual Entailment (UFO-Entail). We demonstrate that this framework enables a pretrained entailment model to work well on new entailment domains in a few-shot setting, and show its effectiveness as a unified solver for several downstream NLP tasks such as question answering and coreference resolution when the end-task annotations are limited. Code: https://github.com/salesforce/UniversalFewShotNLP
GraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing
Sep 29, 2020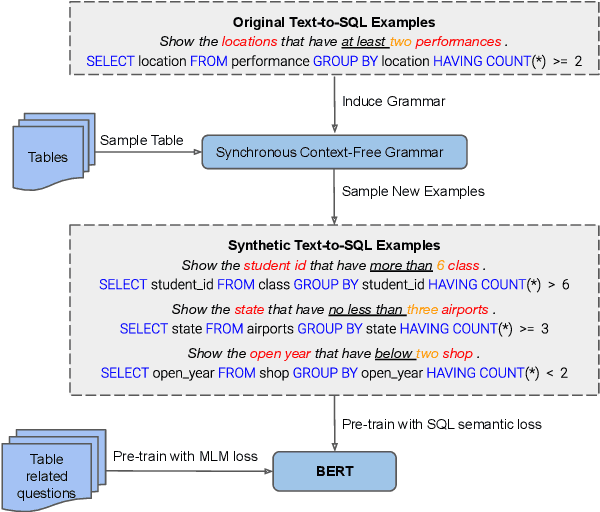


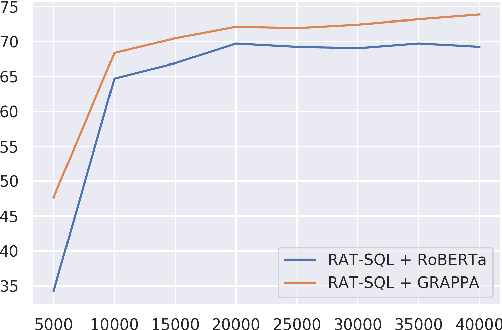
We present GraPPa, an effective pre-training approach for table semantic parsing that learns a compositional inductive bias in the joint representations of textual and tabular data. We construct synthetic question-SQL pairs over high-quality tables via a synchronous context-free grammar (SCFG) induced from existing text-to-SQL datasets. We pre-train our model on the synthetic data using a novel text-schema linking objective that predicts the syntactic role of a table field in the SQL for each question-SQL pair. To maintain the model's ability to represent real-world data, we also include masked language modeling (MLM) over several existing table-and-language datasets to regularize the pre-training process. On four popular fully supervised and weakly supervised table semantic parsing benchmarks, GraPPa significantly outperforms RoBERTa-large as the feature representation layers and establishes new state-of-the-art results on all of them.
SummEval: Re-evaluating Summarization Evaluation
Jul 31, 2020
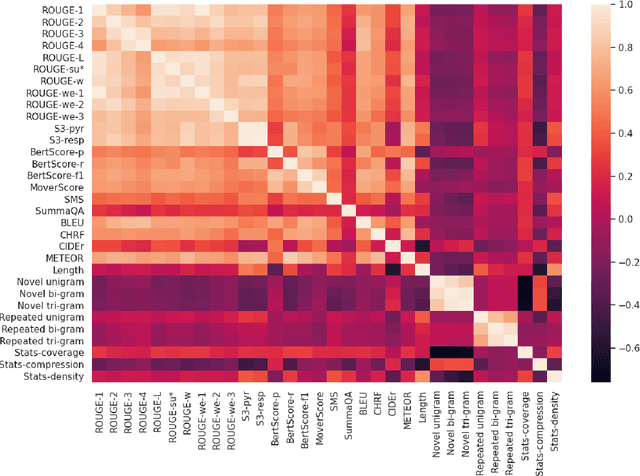
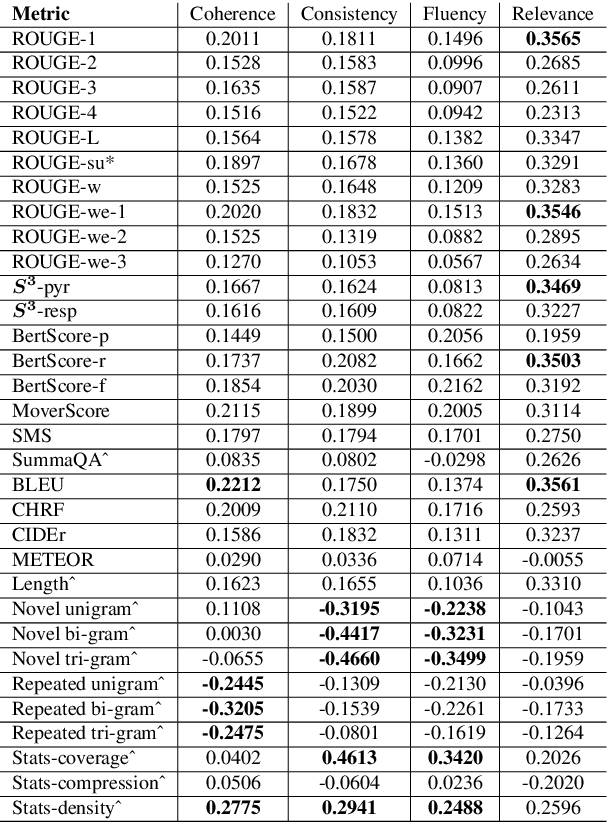
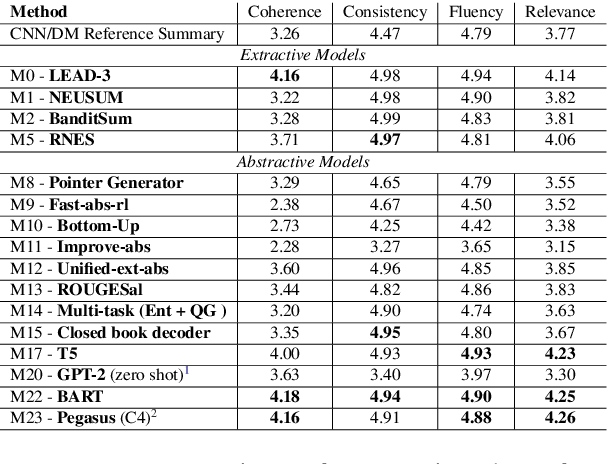
The scarcity of comprehensive up-to-date studies on evaluation metrics for text summarization and the lack of consensus regarding evaluation protocols continues to inhibit progress. We address the existing shortcomings of summarization evaluation methods along five dimensions: 1) we re-evaluate 12 automatic evaluation metrics in a comprehensive and consistent fashion using neural summarization model outputs along with expert and crowd-sourced human annotations, 2) we consistently benchmark 23 recent summarization models using the aforementioned automatic evaluation metrics, 3) we assemble the largest collection of summaries generated by models trained on the CNN/DailyMail news dataset and share it in a unified format, 4) we implement and share a toolkit that provides an extensible and unified API for evaluating summarization models across a broad range of automatic metrics, 5) we assemble and share the largest and most diverse, in terms of model types, collection of human judgments of model-generated summaries on the CNN/Daily Mail dataset annotated by both expert judges and crowd source workers. We hope that this work will help promote a more complete evaluation protocol for text summarization as well as advance research in developing evaluation metrics that better correlate with human judgements.
DART: Open-Domain Structured Data Record to Text Generation
Jul 06, 2020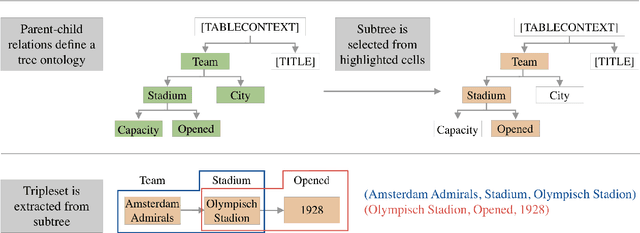
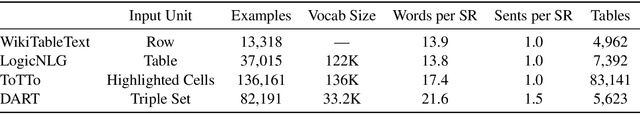
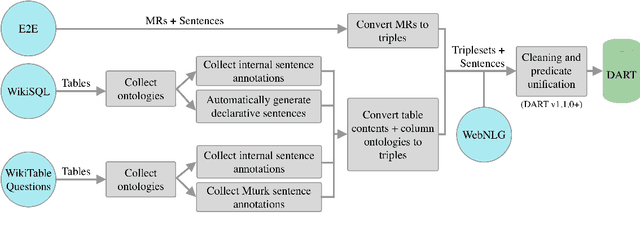
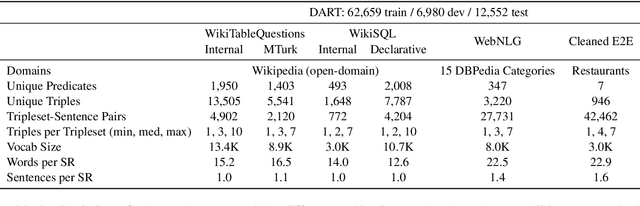
We introduce DART, a large dataset for open-domain structured data record to text generation. We consider the structured data record input as a set of RDF entity-relation triples, a format widely used for knowledge representation and semantics description. DART consists of 82,191 examples across different domains with each input being a semantic RDF triple set derived from data records in tables and the tree ontology of the schema, annotated with sentence descriptions that cover all facts in the triple set. This hierarchical, structured format with its open-domain nature differentiates DART from other existing table-to-text corpora. We conduct an analysis of DART on several state-of-the-art text generation models, showing that it introduces new and interesting challenges compared to existing datasets. Furthermore, we demonstrate that finetuning pretrained language models on DART facilitates out-of-domain generalization on the WebNLG 2017 dataset. DART is available at https://github.com/Yale-LILY/dart.
CO-Search: COVID-19 Information Retrieval with Semantic Search, Question Answering, and Abstractive Summarization
Jun 17, 2020
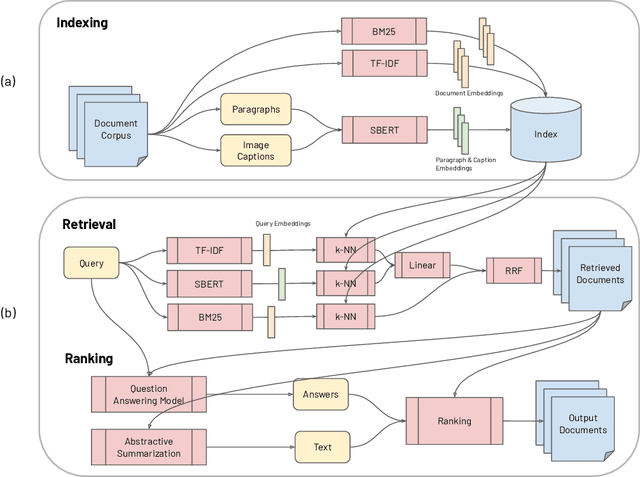
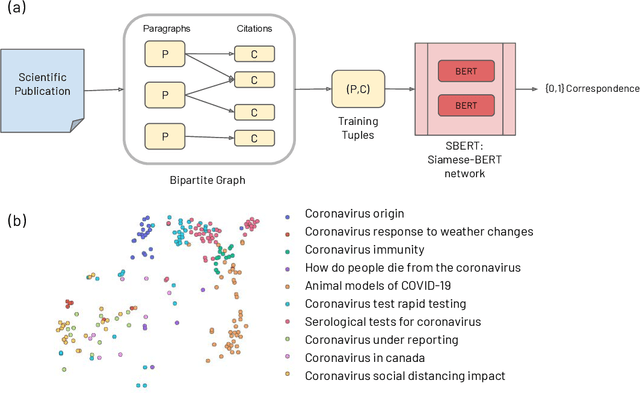
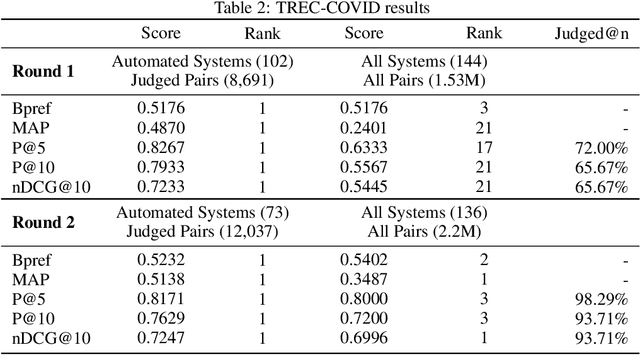
The COVID-19 global pandemic has resulted in international efforts to understand, track, and mitigate the disease, yielding a significant corpus of COVID-19 and SARS-CoV-2-related publications across scientific disciplines. As of May 2020, 128,000 coronavirus-related publications have been collected through the COVID-19 Open Research Dataset Challenge. Here we present CO-Search, a retriever-ranker semantic search engine designed to handle complex queries over the COVID-19 literature, potentially aiding overburdened health workers in finding scientific answers during a time of crisis. The retriever is built from a Siamese-BERT encoder that is linearly composed with a TF-IDF vectorizer, and reciprocal-rank fused with a BM25 vectorizer. The ranker is composed of a multi-hop question-answering module, that together with a multi-paragraph abstractive summarizer adjust retriever scores. To account for the domain-specific and relatively limited dataset, we generate a bipartite graph of document paragraphs and citations, creating 1.3 million (citation title, paragraph) tuples for training the encoder. We evaluate our system on the data of the TREC-COVID information retrieval challenge. CO-Search obtains top performance on the datasets of the first and second rounds, across several key metrics: normalized discounted cumulative gain, precision, mean average precision, and binary preference.
ESPRIT: Explaining Solutions to Physical Reasoning Tasks
May 14, 2020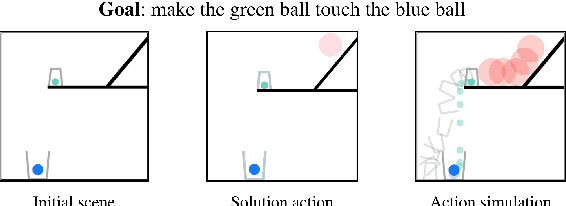

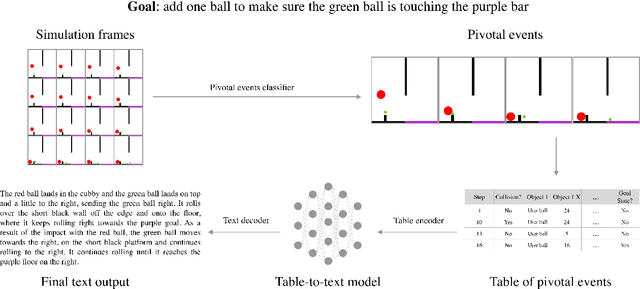
Neural networks lack the ability to reason about qualitative physics and so cannot generalize to scenarios and tasks unseen during training. We propose ESPRIT, a framework for commonsense reasoning about qualitative physics in natural language that generates interpretable descriptions of physical events. We use a two-step approach of first identifying the pivotal physical events in an environment and then generating natural language descriptions of those events using a data-to-text approach. Our framework learns to generate explanations of how the physical simulation will causally evolve so that an agent or a human can easily reason about a solution using those interpretable descriptions. Human evaluations indicate that ESPRIT produces crucial fine-grained details and has high coverage of physical concepts compared to even human annotations. Dataset, code and documentation are available at https://github.com/salesforce/esprit.
R-VGAE: Relational-variational Graph Autoencoder for Unsupervised Prerequisite Chain Learning
Apr 22, 2020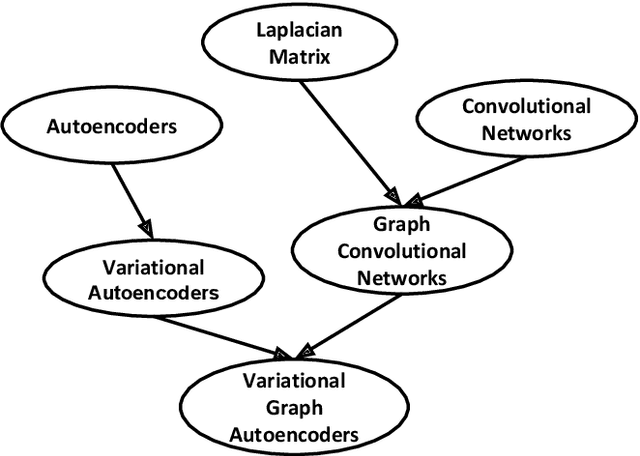
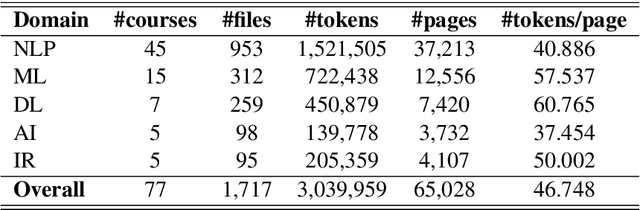
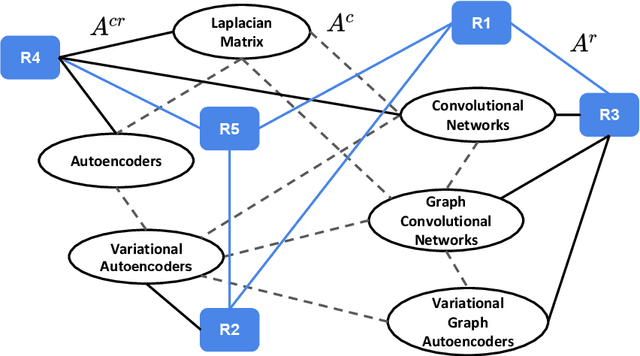
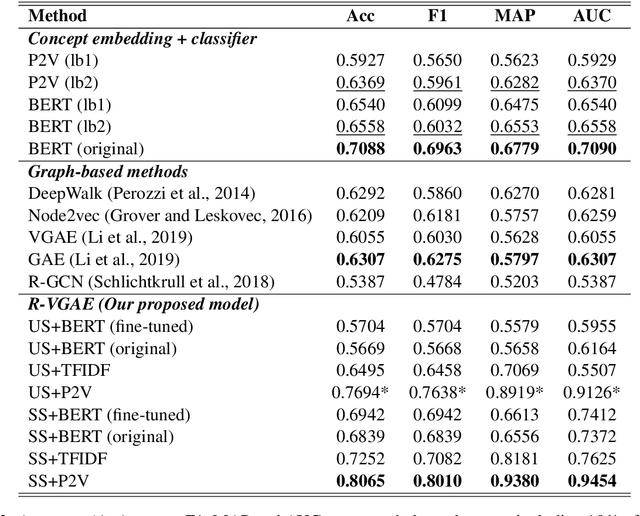
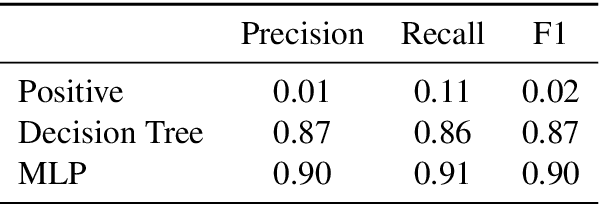
The task of concept prerequisite chain learning is to automatically determine the existence of prerequisite relationships among concept pairs. In this paper, we frame learning prerequisite relationships among concepts as an unsupervised task with no access to labeled concept pairs during training. We propose a model called the Relational-Variational Graph AutoEncoder (R-VGAE) to predict concept relations within a graph consisting of concept and resource nodes. Results show that our unsupervised approach outperforms graph-based semi-supervised methods and other baseline methods by up to 9.77% and 10.47% in terms of prerequisite relation prediction accuracy and F1 score. Our method is notably the first graph-based model that attempts to make use of deep learning representations for the task of unsupervised prerequisite learning. We also expand an existing corpus which totals 1,717 English Natural Language Processing (NLP)-related lecture slide files and manual concept pair annotations over 322 topics.
A Neural Topic-Attention Model for Medical Term Abbreviation Disambiguation
Oct 30, 2019

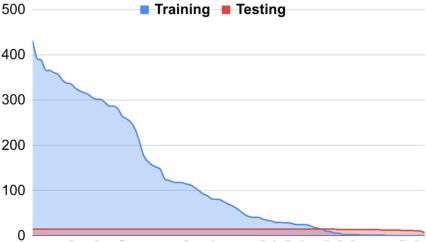
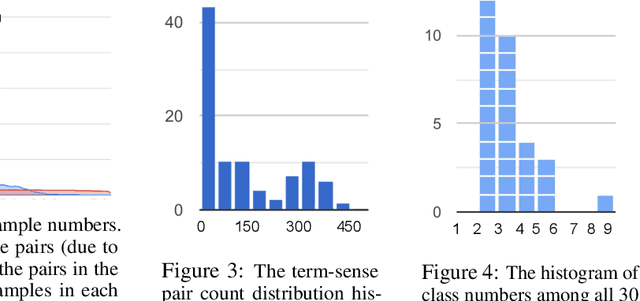
Automated analysis of clinical notes is attracting increasing attention. However, there has not been much work on medical term abbreviation disambiguation. Such abbreviations are abundant, and highly ambiguous, in clinical documents. One of the main obstacles is the lack of large scale, balance labeled data sets. To address the issue, we propose a few-shot learning approach to take advantage of limited labeled data. Specifically, a neural topic-attention model is applied to learn improved contextualized sentence representations for medical term abbreviation disambiguation. Another vital issue is that the existing scarce annotations are noisy and missing. We re-examine and correct an existing dataset for training and collect a test set to evaluate the models fairly especially for rare senses. We train our model on the training set which contains 30 abbreviation terms as categories (on average, 479 samples and 3.24 classes in each term) selected from a public abbreviation disambiguation dataset, and then test on a manually-created balanced dataset (each class in each term has 15 samples). We show that enhancing the sentence representation with topic information improves the performance on small-scale unbalanced training datasets by a large margin, compared to a number of baseline models.