 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Driven Representation Learning for Robotics
Feb 24, 2023



Recent work in visual representation learning for robotics demonstrates the viability of learning from large video datasets of humans performing everyday tasks. Leveraging methods such as masked autoencoding and contrastive learning, these representations exhibit strong transfer to policy learning for visuomotor control. But, robot learning encompasses a diverse set of problems beyond control including grasp affordance prediction, language-conditioned imitation learning, and intent scoring for human-robot collaboration, amongst others. First, we demonstrate that existing representations yield inconsistent results across these tasks: masked autoencoding approaches pick up on low-level spatial features at the cost of high-level semantics, while contrastive learning approaches capture the opposite. We then introduce Voltron, a framework for language-driven representation learning from human videos and associated captions. Voltron trades off language-conditioned visual reconstruction to learn low-level visual patterns, and visually-grounded language generation to encode high-level semantics. We also construct a new evaluation suite spanning five distinct robot learning problems $\unicode{x2013}$ a unified platform for holistically evaluating visual representations for robotics. Through comprehensive, controlled experiments across all five problems, we find that Voltron's language-driven representations outperform the prior state-of-the-art, especially on targeted problems requiring higher-level features.
Long Horizon Temperature Scaling
Feb 07, 2023



Temperature scaling is a popular technique for tuning the sharpness of a model distribution. It is used extensively for sampling likely generations and calibrating model uncertainty, and even features as a controllable parameter to many large language models in deployment. However, autoregressive models rely on myopic temperature scaling that greedily optimizes the next token. To address this, we propose Long Horizon Temperature Scaling (LHTS), a novel approach for sampling from temperature-scaled joint distributions. LHTS is compatible with all likelihood-based models, and optimizes for the long-horizon likelihood of samples. We derive a temperature-dependent LHTS objective, and show that fine-tuning a model on a range of temperatures produces a single model capable of generation with a controllable long-horizon temperature parameter. We experiment with LHTS on image diffusion models and character/language autoregressive models, demonstrating advantages over myopic temperature scaling in likelihood and sample quality, and showing improvements in accuracy on a multiple choice analogy task by $10\%$.
"No, to the Right" -- Online Language Corrections for Robotic Manipulation via Shared Autonomy
Jan 06, 2023



Systems for language-guided human-robot interaction must satisfy two key desiderata for broad adoption: adaptivity and learning efficiency. Unfortunately, existing instruction-following agents cannot adapt, lacking the ability to incorporate online natural language supervision, and even if they could, require hundreds of demonstrations to learn even simple policies. In this work, we address these problems by presenting Language-Informed Latent Actions with Corrections (LILAC), a framework for incorporating and adapting to natural language corrections - "to the right," or "no, towards the book" - online, during execution. We explore rich manipulation domains within a shared autonomy paradigm. Instead of discrete turn-taking between a human and robot, LILAC splits agency between the human and robot: language is an input to a learned model that produces a meaningful, low-dimensional control space that the human can use to guide the robot. Each real-time correction refines the human's control space, enabling precise, extended behaviors - with the added benefit of requiring only a handful of demonstrations to learn. We evaluate our approach via a user study where users work with a Franka Emika Panda manipulator to complete complex manipulation tasks. Compared to existing learned baselines covering both open-loop instruction following and single-turn shared autonomy, we show that our corrections-aware approach obtains higher task completion rates, and is subjectively preferred by users because of its reliability, precision, and ease of use.
Few-Shot Preference Learning for Human-in-the-Loop RL
Dec 06, 2022While reinforcement learning (RL) has become a more popular approach for robotics, designing sufficiently informative reward functions for complex tasks has proven to be extremely difficult due their inability to capture human intent and policy exploitation. Preference based RL algorithms seek to overcome these challenges by directly learning reward functions from human feedback. Unfortunately, prior work either requires an unreasonable number of queries implausible for any human to answer or overly restricts the class of reward functions to guarantee the elicitation of the most informative queries, resulting in models that are insufficiently expressive for realistic robotics tasks. Contrary to most works that focus on query selection to \emph{minimize} the amount of data required for learning reward functions, we take an opposite approach: \emph{expanding} the pool of available data by viewing human-in-the-loop RL through the more flexible lens of multi-task learning. Motivated by the success of meta-learning, we pre-train preference models on prior task data and quickly adapt them for new tasks using only a handful of queries. Empirically, we reduce the amount of online feedback needed to train manipulation policies in Meta-World by 20$\times$, and demonstrate the effectiveness of our method on a real Franka Panda Robot. Moreover, this reduction in query-complexity allows us to train robot policies from actual human users. Videos of our results and code can be found at https://sites.google.com/view/few-shot-preference-rl/home.
Learning Visuo-Haptic Skewering Strategies for Robot-Assisted Feeding
Nov 30, 2022



Acquiring food items with a fork poses an immense challenge to a robot-assisted feeding system, due to the wide range of material properties and visual appearances present across food groups. Deformable foods necessitate different skewering strategies than firm ones, but inferring such characteristics for several previously unseen items on a plate remains nontrivial. Our key insight is to leverage visual and haptic observations during interaction with an item to rapidly and reactively plan skewering motions. We learn a generalizable, multimodal representation for a food item from raw sensory inputs which informs the optimal skewering strategy. Given this representation, we propose a zero-shot framework to sense visuo-haptic properties of a previously unseen item and reactively skewer it, all within a single interaction. Real-robot experiments with foods of varying levels of visual and textural diversity demonstrate that our multimodal policy outperforms baselines which do not exploit both visual and haptic cues or do not reactively plan. Across 6 plates of different food items, our proposed framework achieves 71% success over 69 skewering attempts total. Supplementary material, datasets, code, and videos are available on our website: https://sites.google.com/view/hapticvisualnet-corl22/home
Learning Bimanual Scooping Policies for Food Acquisition
Nov 26, 2022



A robotic feeding system must be able to acquire a variety of foods. Prior bite acquisition works consider single-arm spoon scooping or fork skewering, which do not generalize to foods with complex geometries and deformabilities. For example, when acquiring a group of peas, skewering could smoosh the peas while scooping without a barrier could result in chasing the peas on the plate. In order to acquire foods with such diverse properties, we propose stabilizing food items during scooping using a second arm, for example, by pushing peas against the spoon with a flat surface to prevent dispersion. The added stabilizing arm can lead to new challenges. Critically, this arm should stabilize the food scene without interfering with the acquisition motion, which is especially difficult for easily breakable high-risk food items like tofu. These high-risk foods can break between the pusher and spoon during scooping, which can lead to food waste falling out of the spoon. We propose a general bimanual scooping primitive and an adaptive stabilization strategy that enables successful acquisition of a diverse set of food geometries and physical properties. Our approach, CARBS: Coordinated Acquisition with Reactive Bimanual Scooping, learns to stabilize without impeding task progress by identifying high-risk foods and robustly scooping them using closed-loop visual feedback. We find that CARBS is able to generalize across food shape, size, and deformability and is additionally able to manipulate multiple food items simultaneously. CARBS achieves 87.0% success on scooping rigid foods, which is 25.8% more successful than a single-arm baseline, and reduces food breakage by 16.2% compared to an analytical baseline. Videos can be found at https://sites.google.com/view/bimanualscoop-corl22/home .
Assistive Teaching of Motor Control Tasks to Humans
Nov 25, 2022



Recent works on shared autonomy and assistive-AI technologies, such as assistive robot teleoperation, seek to model and help human users with limited ability in a fixed task. However, these approaches often fail to account for humans' ability to adapt and eventually learn how to execute a control task themselves. Furthermore, in applications where it may be desirable for a human to intervene, these methods may inhibit their ability to learn how to succeed with full self-control. In this paper, we focus on the problem of assistive teaching of motor control tasks such as parking a car or landing an aircraft. Despite their ubiquitous role in humans' daily activities and occupations, motor tasks are rarely taught in a uniform way due to their high complexity and variance. We propose an AI-assisted teaching algorithm that leverages skill discovery methods from reinforcement learning (RL) to (i) break down any motor control task into teachable skills, (ii) construct novel drill sequences, and (iii) individualize curricula to students with different capabilities. Through an extensive mix of synthetic and user studies on two motor control tasks -- parking a car with a joystick and writing characters from the Balinese alphabet -- we show that assisted teaching with skills improves student performance by around 40% compared to practicing full trajectories without skills, and practicing with individualized drills can result in up to 25% further improvement. Our source code is available at https://github.com/Stanford-ILIAD/teaching
In-Mouth Robotic Bite Transfer with Visual and Haptic Sensing
Nov 23, 2022



Assistance during eating is essential for those with severe mobility issues or eating risks. However, dependence on traditional human caregivers is linked to malnutrition, weight loss, and low self-esteem. For those who require eating assistance, a semi-autonomous robotic platform can provide independence and a healthier lifestyle. We demonstrate an essential capability of this platform: safe, comfortable, and effective transfer of a bite-sized food item from a utensil directly to the inside of a person's mouth. Our system uses a force-reactive controller to safely accommodate the user's motions throughout the transfer, allowing full reactivity until bite detection then reducing reactivity in the direction of exit. Additionally, we introduce a novel dexterous wrist-like end effector capable of small, unimposing movements to reduce user discomfort. We conduct a user study with 11 participants covering 8 diverse food categories to evaluate our system end-to-end, and we find that users strongly prefer our method to a wide range of baselines. Appendices and videos are available at our website: https://tinyurl.com/btICRA.
Learning Tool Morphology for Contact-Rich Manipulation Tasks with Differentiable Simulation
Nov 04, 2022When humans perform contact-rich manipulation tasks, customized tools are often necessary and play an important role in simplifying the task. For instance, in our daily life, we use various utensils for handling food, such as knives, forks and spoons. Similarly, customized tools for robots may enable them to more easily perform a variety of tasks. Here, we present an end-to-end framework to automatically learn tool morphology for contact-rich manipulation tasks by leveraging differentiable physics simulators. Previous work approached this problem by introducing manually constructed priors that required detailed specification of object 3D model, grasp pose and task description to facilitate the search or optimization. In our approach, we instead only need to define the objective with respect to the task performance and enable learning a robust morphology by randomizing the task variations. The optimization is made tractable by casting this as a continual learning problem. We demonstrate the effectiveness of our method for designing new tools in several scenarios such as winding ropes, flipping a box and pushing peas onto a scoop in simulation. We also validate that the shapes discovered by our method help real robots succeed in these scenarios.
Eliciting Compatible Demonstrations for Multi-Human Imitation Learning
Oct 14, 2022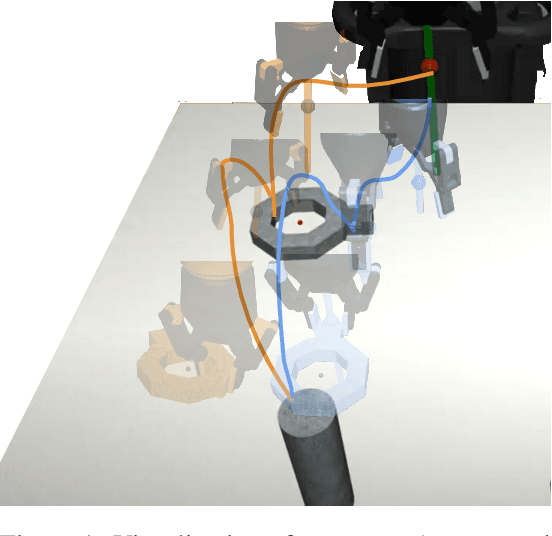
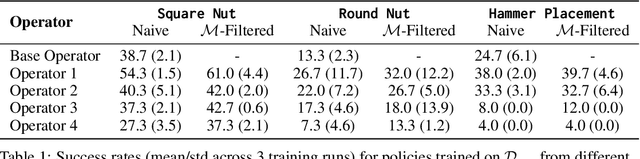
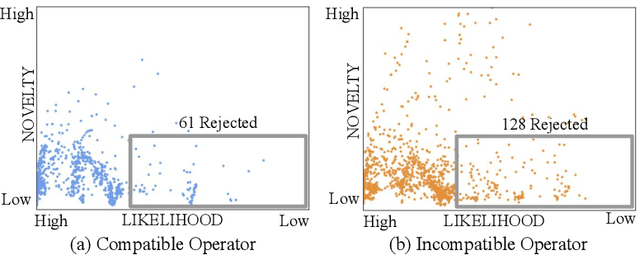

Imitation learning from human-provided demonstrations is a strong approach for learning policies for robot manipulation. While the ideal dataset for imitation learning is homogenous and low-variance -- reflecting a single, optimal method for performing a task -- natural human behavior has a great deal of heterogeneity, with several optimal ways to demonstrate a task. This multimodality is inconsequential to human users, with task variations manifesting as subconscious choices; for example, reaching down, then across to grasp an object, versus reaching across, then down. Yet, this mismatch presents a problem for interactive imitation learning, where sequences of users improve on a policy by iteratively collecting new, possibly conflicting demonstrations. To combat this problem of demonstrator incompatibility, this work designs an approach for 1) measuring the compatibility of a new demonstration given a base policy, and 2) actively eliciting more compatible demonstrations from new users. Across two simulation tasks requiring long-horizon, dexterous manipulation and a real-world "food plating" task with a Franka Emika Panda arm, we show that we can both identify incompatible demonstrations via post-hoc filtering, and apply our compatibility measure to actively elicit compatible demonstrations from new users, leading to improved task success rates across simulated and real environments.