 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Contextual Bandits Through Perturbed Rewards
Jan 24, 2022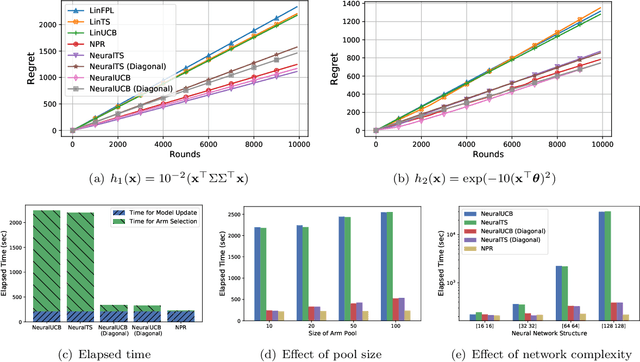

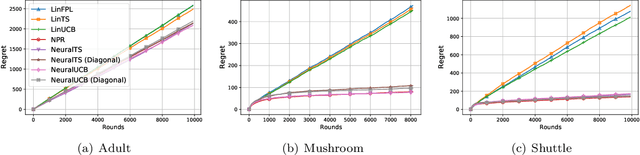
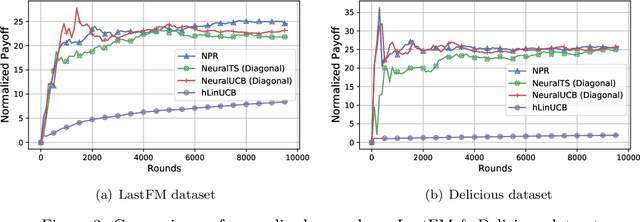
Thanks to the power of representation learning, neural contextual bandit algorithms demonstrate remarkable performance improvement against their classical counterparts. But because their exploration has to be performed in the entire neural network parameter space to obtain nearly optimal regret, the resulting computational cost is prohibitively high. We perturb the rewards when updating the neural network to eliminate the need of explicit exploration and the corresponding computational overhead. We prove that a $\tilde{O}(\tilde{d}\sqrt{T})$ regret upper bound is still achievable under standard regularity conditions, where $T$ is the number of rounds of interactions and $\tilde{d}$ is the effective dimension of a neural tangent kernel matrix. Extensive comparisons with several benchmark contextual bandit algorithms, including two recent neural contextual bandit models, demonstrate the effectiveness and computational efficiency of our proposed neural bandit algorithm.
Faster Perturbed Stochastic Gradient Methods for Finding Local Minima
Oct 25, 2021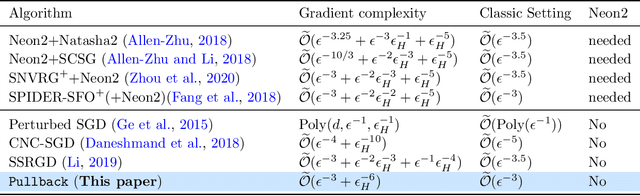
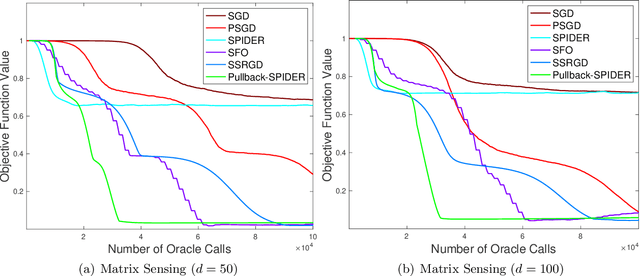
Escaping from saddle points and finding local minima is a central problem in nonconvex optimization. Perturbed gradient methods are perhaps the simplest approach for this problem. However, to find $(\epsilon, \sqrt{\epsilon})$-approximate local minima, the existing best stochastic gradient complexity for this type of algorithms is $\tilde O(\epsilon^{-3.5})$, which is not optimal. In this paper, we propose \texttt{Pullback}, a faster perturbed stochastic gradient framework for finding local minima. We show that Pullback with stochastic gradient estimators such as SARAH/SPIDER and STORM can find $(\epsilon, \epsilon_{H})$-approximate local minima within $\tilde O(\epsilon^{-3} + \epsilon_{H}^{-6})$ stochastic gradient evaluations (or $\tilde O(\epsilon^{-3})$ when $\epsilon_H = \sqrt{\epsilon}$). The core idea of our framework is a step-size ``pullback'' scheme to control the average movement of the iterates, which leads to faster convergence to the local minima. Experiments on matrix factorization problems corroborate our theory.
Linear Contextual Bandits with Adversarial Corruptions
Oct 25, 2021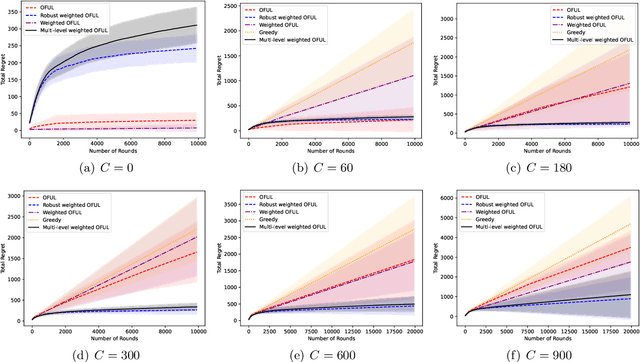
We study the linear contextual bandit problem in the presence of adversarial corruption, where the interaction between the player and a possibly infinite decision set is contaminated by an adversary that can corrupt the reward up to a corruption level $C$ measured by the sum of the largest alteration on rewards in each round. We present a variance-aware algorithm that is adaptive to the level of adversarial contamination $C$. The key algorithmic design includes (1) a multi-level partition scheme of the observed data, (2) a cascade of confidence sets that are adaptive to the level of the corruption, and (3) a variance-aware confidence set construction that can take advantage of low-variance reward. We further prove that the regret of the proposed algorithm is $\tilde{O}(C^2d\sqrt{\sum_{t = 1}^T \sigma_t^2} + C^2R\sqrt{dT})$, where $d$ is the dimension of context vectors, $T$ is the number of rounds, $R$ is the range of noise and $\sigma_t^2,t=1\ldots,T$ are the variances of instantaneous reward. We also prove a gap-dependent regret bound for the proposed algorithm, which is instance-dependent and thus leads to better performance on good practical instances. To the best of our knowledge, this is the first variance-aware corruption-robust algorithm for contextual bandits. Experiments on synthetic data corroborate our theory.
Iterative Teacher-Aware Learning
Oct 17, 2021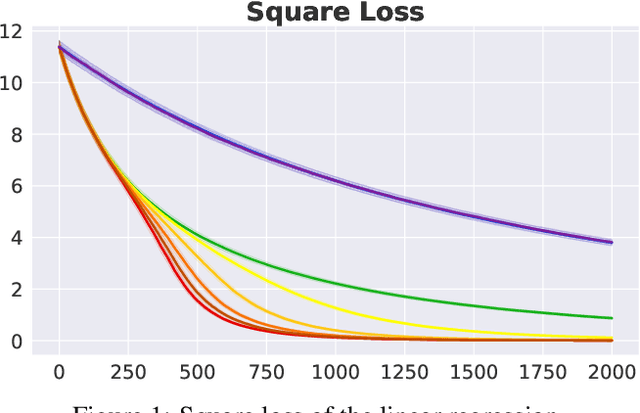
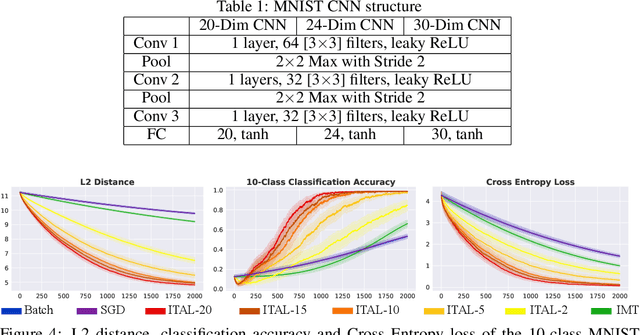
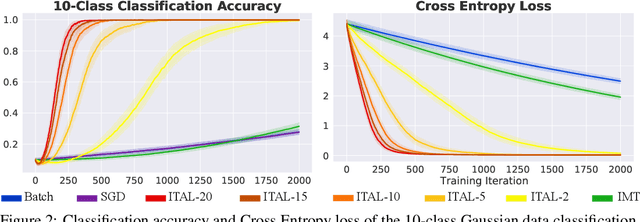

In human pedagogy, teachers and students can interact adaptively to maximize communication efficiency. The teacher adjusts her teaching method for different students, and the student, after getting familiar with the teacher's instruction mechanism, can infer the teacher's intention to learn faster. Recently, the benefits of integrating this cooperative pedagogy into machine concept learning in discrete spaces have been proved by multiple works. However, how cooperative pedagogy can facilitate machine parameter learning hasn't been thoroughly studied. In this paper, we propose a gradient optimization based teacher-aware learner who can incorporate teacher's cooperative intention into the likelihood function and learn provably faster compared with the naive learning algorithms used in previous machine teaching works. We give theoretical proof that the iterative teacher-aware learning (ITAL) process leads to local and global improvements. We then validate our algorithms with extensive experiments on various tasks including regression, classification, and inverse reinforcement learning using synthetic and real data. We also show the advantage of modeling teacher-awareness when agents are learning from human teachers.
Reward-Free Model-Based Reinforcement Learning with Linear Function Approximation
Oct 12, 2021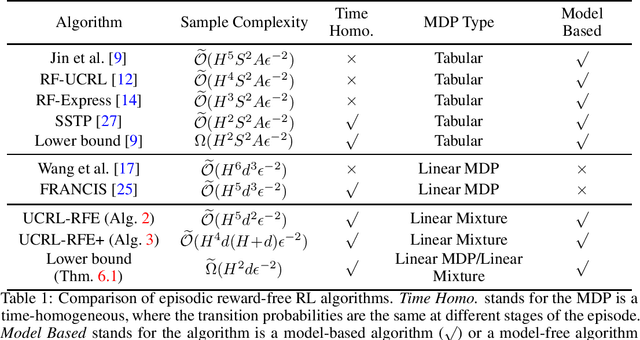
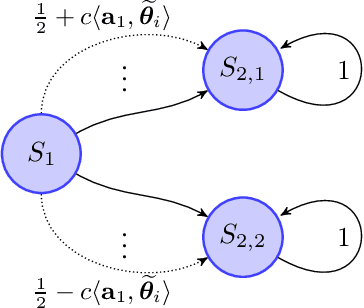
We study the model-based reward-free reinforcement learning with linear function approximation for episodic Markov decision processes (MDPs). In this setting, the agent works in two phases. In the exploration phase, the agent interacts with the environment and collects samples without the reward. In the planning phase, the agent is given a specific reward function and uses samples collected from the exploration phase to learn a good policy. We propose a new provably efficient algorithm, called UCRL-RFE under the Linear Mixture MDP assumption, where the transition probability kernel of the MDP can be parameterized by a linear function over certain feature mappings defined on the triplet of state, action, and next state. We show that to obtain an $\epsilon$-optimal policy for arbitrary reward function, UCRL-RFE needs to sample at most $\tilde O(H^5d^2\epsilon^{-2})$ episodes during the exploration phase. Here, $H$ is the length of the episode, $d$ is the dimension of the feature mapping. We also propose a variant of UCRL-RFE using Bernstein-type bonus and show that it needs to sample at most $\tilde O(H^4d(H + d)\epsilon^{-2})$ to achieve an $\epsilon$-optimal policy. By constructing a special class of linear Mixture MDPs, we also prove that for any reward-free algorithm, it needs to sample at least $\tilde \Omega(H^2d\epsilon^{-2})$ episodes to obtain an $\epsilon$-optimal policy. Our upper bound matches the lower bound in terms of the dependence on $\epsilon$ and the dependence on $d$ if $H \ge d$.
Pure Exploration in Kernel and Neural Bandits
Jun 22, 2021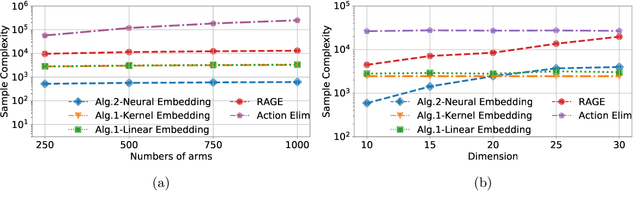

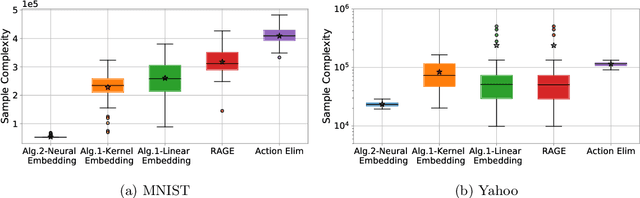
We study pure exploration in bandits, where the dimension of the feature representation can be much larger than the number of arms. To overcome the curse of dimensionality, we propose to adaptively embed the feature representation of each arm into a lower-dimensional space and carefully deal with the induced model misspecifications. Our approach is conceptually very different from existing works that can either only handle low-dimensional linear bandits or passively deal with model misspecifications. We showcase the application of our approach to two pure exploration settings that were previously under-studied: (1) the reward function belongs to a possibly infinite-dimensional Reproducing Kernel Hilbert Space, and (2) the reward function is nonlinear and can be approximated by neural networks. Our main results provide sample complexity guarantees that only depend on the effective dimension of the feature spaces in the kernel or neural representations. Extensive experiments conducted on both synthetic and real-world datasets demonstrate the efficacy of our methods.
Variance-Aware Off-Policy Evaluation with Linear Function Approximation
Jun 22, 2021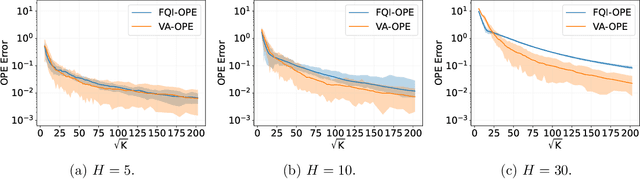
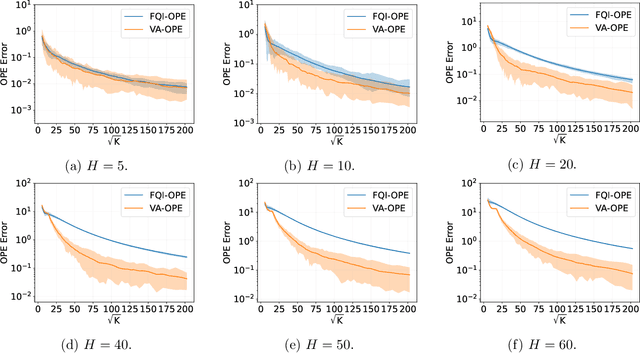
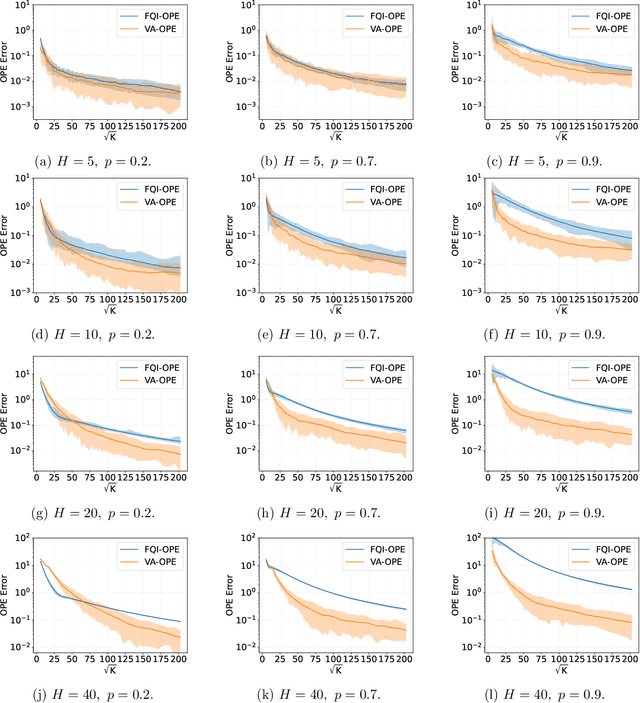
We study the off-policy evaluation (OPE) problem in reinforcement learning with linear function approximation, which aims to estimate the value function of a target policy based on the offline data collected by a behavior policy. We propose to incorporate the variance information of the value function to improve the sample efficiency of OPE. More specifically, for time-inhomogeneous episodic linear Markov decision processes (MDPs), we propose an algorithm, VA-OPE, which uses the estimated variance of the value function to reweight the Bellman residual in Fitted Q-Iteration. We show that our algorithm achieves a tighter error bound than the best-known result. We also provide a fine-grained characterization of the distribution shift between the behavior policy and the target policy. Extensive numerical experiments corroborate our theory.
Provably Efficient Representation Learning in Low-rank Markov Decision Processes
Jun 22, 2021The success of deep reinforcement learning (DRL) is due to the power of learning a representation that is suitable for the underlying exploration and exploitation task. However, existing provable reinforcement learning algorithms with linear function approximation often assume the feature representation is known and fixed. In order to understand how representation learning can improve the efficiency of RL, we study representation learning for a class of low-rank Markov Decision Processes (MDPs) where the transition kernel can be represented in a bilinear form. We propose a provably efficient algorithm called ReLEX that can simultaneously learn the representation and perform exploration. We show that ReLEX always performs no worse than a state-of-the-art algorithm without representation learning, and will be strictly better in terms of sample efficiency if the function class of representations enjoys a certain mild "coverage'' property over the whole state-action space.
Uniform-PAC Bounds for Reinforcement Learning with Linear Function Approximation
Jun 22, 2021We study reinforcement learning (RL) with linear function approximation. Existing algorithms for this problem only have high-probability regret and/or Probably Approximately Correct (PAC) sample complexity guarantees, which cannot guarantee the convergence to the optimal policy. In this paper, in order to overcome the limitation of existing algorithms, we propose a new algorithm called FLUTE, which enjoys uniform-PAC convergence to the optimal policy with high probability. The uniform-PAC guarantee is the strongest possible guarantee for reinforcement learning in the literature, which can directly imply both PAC and high probability regret bounds, making our algorithm superior to all existing algorithms with linear function approximation. At the core of our algorithm is a novel minimax value function estimator and a multi-level partition scheme to select the training samples from historical observations. Both of these techniques are new and of independent interest.
Batched Neural Bandits
Feb 25, 2021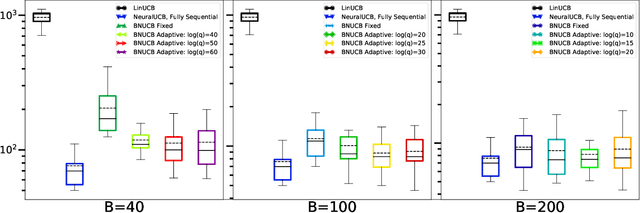
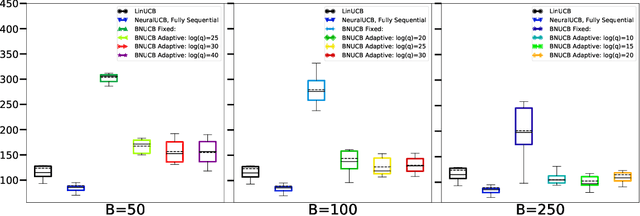
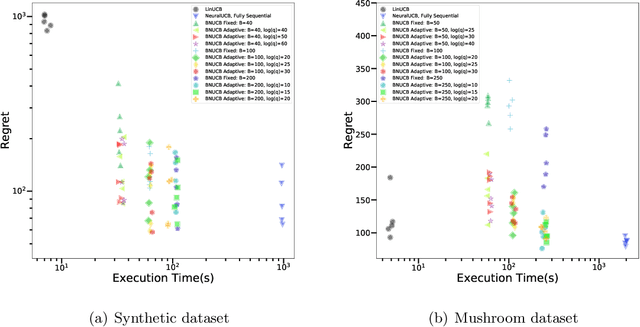
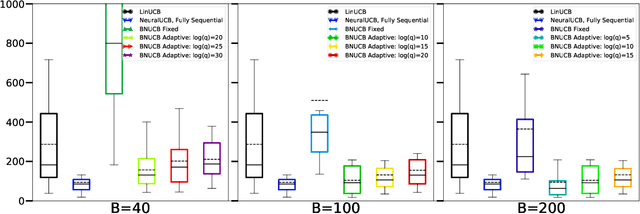
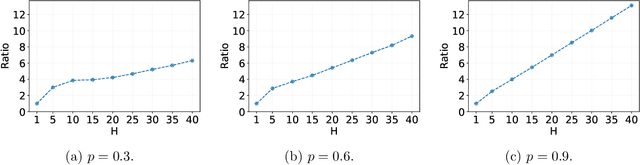
In many sequential decision-making problems, the individuals are split into several batches and the decision-maker is only allowed to change her policy at the end of batches. These batch problems have a large number of applications, ranging from clinical trials to crowdsourcing. Motivated by this, we study the stochastic contextual bandit problem for general reward distributions under the batched setting. We propose the BatchNeuralUCB algorithm which combines neural networks with optimism to address the exploration-exploitation tradeoff while keeping the total number of batches limited. We study BatchNeuralUCB under both fixed and adaptive batch size settings and prove that it achieves the same regret as the fully sequential version while reducing the number of policy updates considerably. We confirm our theoretical results via simulations on both synthetic and real-world datasets.