 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-THuMBS: Multi-person Tracking of 3D Human Meshes Beyond Video Shots
Jul 02, 2026Tracking multi-person 3D human meshes from in-the-wild videos is a highly challenging problem due to complex interactions, frequent occlusions, and severe truncation inherent in unconstrained environments. While recent approaches have improved robustness against these issues, they largely overlook the critical challenge prevalent in real-world footage: frequent shot changes. These abrupt transitions in camera viewpoints often cause existing methods to lose track of human identities and fail in reconstructing temporally coherent trajectories. Although several recent works have explored 3D human mesh tracking under shot changes, they are still limited to single-person scenarios, making them inadequate for real-world videos where multiple people interact and appear simultaneously. To address this limitation, we propose Multi-THuMBS (Multi-person Tracking of 3D Human Meshes Beyond Video Shots) that leverages a state-of-the-art 3D scene prior to reconstruct the two boundary frames in a single shared 3D space. Human meshes are then registered within the shared 3D space, maintaining per-person identity and motion consistency across shot changes. Extensive experiments demonstrate that our approach yields significant improvements in 3D human mesh recovery, camera pose estimation, and identity tracking, thereby ensuring high-fidelity motion reconstruction with consistent identity preservation across shots compared to previous state-of-the-art methods.
In-situ and Non-contact Etch Depth Prediction in Plasma Etching via Machine Learning (ANN & BNN) and Digital Image Colorimetry
May 03, 2025



Precise monitoring of etch depth and the thickness of insulating materials, such as Silicon dioxide and silicon nitride, is critical to ensuring device performance and yield in semiconductor manufacturing. While conventional ex-situ analysis methods are accurate, they are constrained by time delays and contamination risks. To address these limitations, this study proposes a non-contact, in-situ etch depth prediction framework based on machine learning (ML) techniques. Two scenarios are explored. In the first scenario, an artificial neural network (ANN) is trained to predict average etch depth from process parameters, achieving a significantly lower mean squared error (MSE) compared to a linear baseline model. The approach is then extended to incorporate variability from repeated measurements using a Bayesian Neural Network (BNN) to capture both aleatoric and epistemic uncertainty. Coverage analysis confirms the BNN's capability to provide reliable uncertainty estimates. In the second scenario, we demonstrate the feasibility of using RGB data from digital image colorimetry (DIC) as input for etch depth prediction, achieving strong performance even in the absence of explicit process parameters. These results suggest that the integration of DIC and ML offers a viable, cost-effective alternative for real-time, in-situ, and non-invasive monitoring in plasma etching processes, contributing to enhanced process stability, and manufacturing efficiency.
Consensus-aware Contrastive Learning for Group Recommendation
Apr 18, 2025



Group recommendation aims to provide personalized item suggestions to a group of users by reflecting their collective preferences. A fundamental challenge in this task is deriving a consensus that adequately represents the diverse interests of individual group members. Despite advancements made by deep learning-based models, existing approaches still struggle in two main areas: (1) Capturing consensus in small-group settings, which are more prevalent in real-world applications, and (2) Balancing individual preferences with overall group performance, particularly in hypergraph-based methods that tend to emphasize group accuracy at the expense of personalization. To address these challenges, we introduce a Consensus-aware Contrastive Learning for Group Recommendation (CoCoRec) that models group consensus through contrastive learning. CoCoRec utilizes a transformer encoder to jointly learn user and group representations, enabling richer modeling of intra-group dynamics. Additionally, the contrastive objective helps reduce overfitting from high-frequency user interactions, leading to more robust and representative group embeddings. Experiments conducted on four benchmark datasets show that CoCoRec consistently outperforms state-of-the-art baselines in both individual and group recommendation scenarios, highlighting the effectiveness of consensus-aware contrastive learning in group recommendation tasks.
Debiasing Classifiers by Amplifying Bias with Latent Diffusion and Large Language Models
Nov 25, 2024



Neural networks struggle with image classification when biases are learned and misleads correlations, affecting their generalization and performance. Previous methods require attribute labels (e.g. background, color) or utilizes Generative Adversarial Networks (GANs) to mitigate biases. We introduce DiffuBias, a novel pipeline for text-to-image generation that enhances classifier robustness by generating bias-conflict samples, without requiring training during the generation phase. Utilizing pretrained diffusion and image captioning models, DiffuBias generates images that challenge the biases of classifiers, using the top-$K$ losses from a biased classifier ($f_B$) to create more representative data samples. This method not only debiases effectively but also boosts classifier generalization capabilities. To the best of our knowledge, DiffuBias is the first approach leveraging a stable diffusion model to generate bias-conflict samples in debiasing tasks. Our comprehensive experimental evaluations demonstrate that DiffuBias achieves state-of-the-art performance on benchmark datasets. We also conduct a comparative analysis of various generative models in terms of carbon emissions and energy consumption to highlight the significance of computational efficiency.
DiffInject: Revisiting Debias via Synthetic Data Generation using Diffusion-based Style Injection
Jun 10, 2024Dataset bias is a significant challenge in machine learning, where specific attributes, such as texture or color of the images are unintentionally learned resulting in detrimental performance. To address this, previous efforts have focused on debiasing models either by developing novel debiasing algorithms or by generating synthetic data to mitigate the prevalent dataset biases. However, generative approaches to date have largely relied on using bias-specific samples from the dataset, which are typically too scarce. In this work, we propose, DiffInject, a straightforward yet powerful method to augment synthetic bias-conflict samples using a pretrained diffusion model. This approach significantly advances the use of diffusion models for debiasing purposes by manipulating the latent space. Our framework does not require any explicit knowledge of the bias types or labelling, making it a fully unsupervised setting for debiasing. Our methodology demonstrates substantial result in effectively reducing dataset bias.
Hierarchical Contrastive Learning with Multiple Augmentation for Sequential Recommendation
Aug 07, 2023



Sequential recommendation addresses the issue of preference drift by predicting the next item based on the user's previous behaviors. Recently, a promising approach using contrastive learning has emerged, demonstrating its effectiveness in recommending items under sparse user-item interactions. Significantly, the effectiveness of combinations of various augmentation methods has been demonstrated in different domains, particularly in computer vision. However, when it comes to augmentation within a contrastive learning framework in sequential recommendation, previous research has only focused on limited conditions and simple structures. Thus, it is still possible to extend existing approaches to boost the effects of augmentation methods by using progressed structures with the combinations of multiple augmentation methods. In this work, we propose a novel framework called Hierarchical Contrastive Learning with Multiple Augmentation for Sequential Recommendation(HCLRec) to overcome the aforementioned limitation. Our framework leverages existing augmentation methods hierarchically to improve performance. By combining augmentation methods continuously, we generate low-level and high-level view pairs. We employ a Transformers-based model to encode the input sequence effectively. Furthermore, we introduce additional blocks consisting of Transformers and position-wise feed-forward network(PFFN) layers to learn the invariance of the original sequences from hierarchically augmented views. We pass the input sequence to subsequent layers based on the number of increment levels applied to the views to handle various augmentation levels. Within each layer, we compute contrastive loss between pairs of views at the same level. Extensive experiments demonstrate that our proposed method outperforms state-of-the-art approaches and that HCLRec is robust even when faced with the problem of sparse interaction.
A Differentiable Ranking Metric Using Relaxed Sorting Opeartion for Top-K Recommender Systems
Sep 03, 2020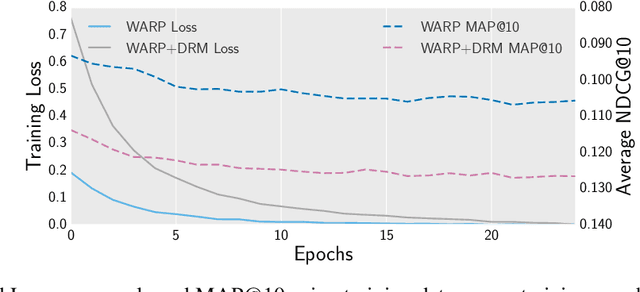
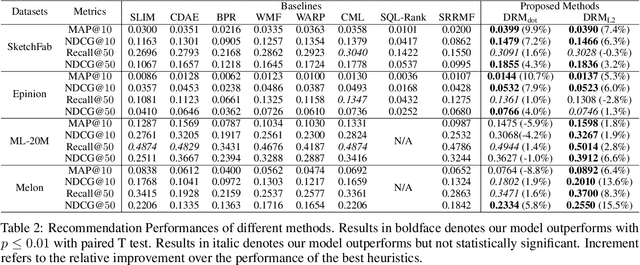
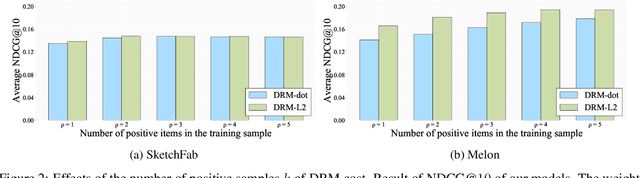
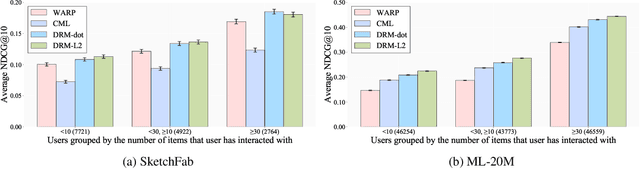
A recommender system generates personalized recommendations for a user by computing the preference score of items, sorting the items according to the score, and filtering the top-Kitemswith high scores. While sorting and ranking items are integral for this recommendation procedure,it is nontrivial to incorporate them in the process of end-to-end model training since sorting is non-differentiable and hard to optimize with gradient-based updates. This incurs the inconsistency issue between the existing learning objectives and ranking-based evaluation metrics of recommendation models. In this work, we present DRM (differentiable ranking metric) that mitigates the inconsistency and improves recommendation performance, by employing the differentiable relaxation of ranking-based evaluation metrics. Via experiments with several real-world datasets, we demonstrate that the joint learning of the DRM cost function upon existing factor based recommendation models significantly improves the quality of recommendations, in comparison with other state-of-the-art recommendation methods.