 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Decision-Time vs. Background Planning in Model-Based Reinforcement Learning
Jun 16, 2022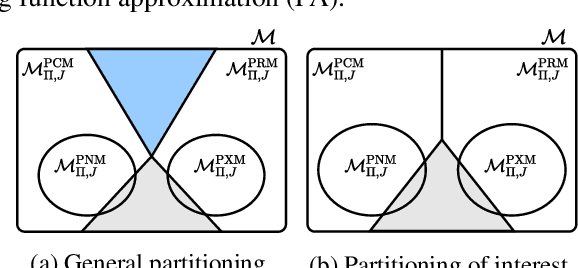
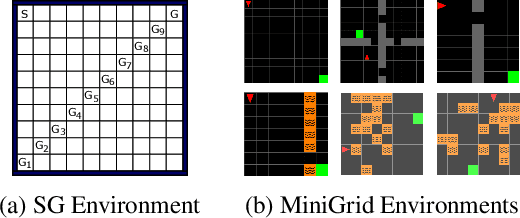
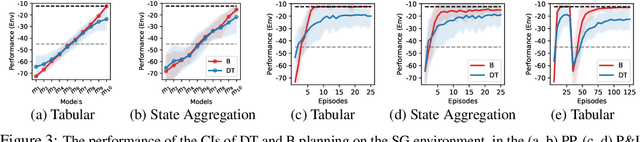
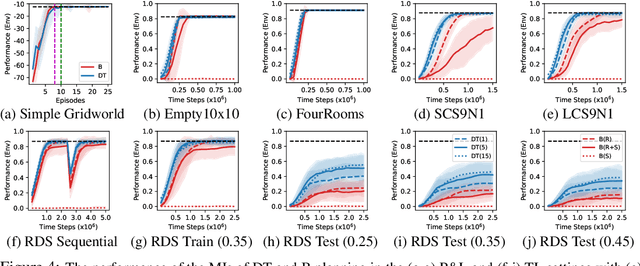
In model-based reinforcement learning, an agent can leverage a learned model to improve its way of behaving in different ways. Two prevalent approaches are decision-time planning and background planning. In this study, we are interested in understanding under what conditions and in which settings one of these two planning styles will perform better than the other in domains that require fast responses. After viewing them through the lens of dynamic programming, we first consider the classical instantiations of these planning styles and provide theoretical results and hypotheses on which one will perform better in the pure planning, planning & learning, and transfer learning settings. We then consider the modern instantiations of these planning styles and provide hypotheses on which one will perform better in the last two of the considered settings. Lastly, we perform several illustrative experiments to empirically validate both our theoretical results and hypotheses. Overall, our findings suggest that even though decision-time planning does not perform as well as background planning in their classical instantiations, in their modern instantiations, it can perform on par or better than background planning in both the planning & learning and transfer learning settings.
Improving Robustness against Real-World and Worst-Case Distribution Shifts through Decision Region Quantification
May 19, 2022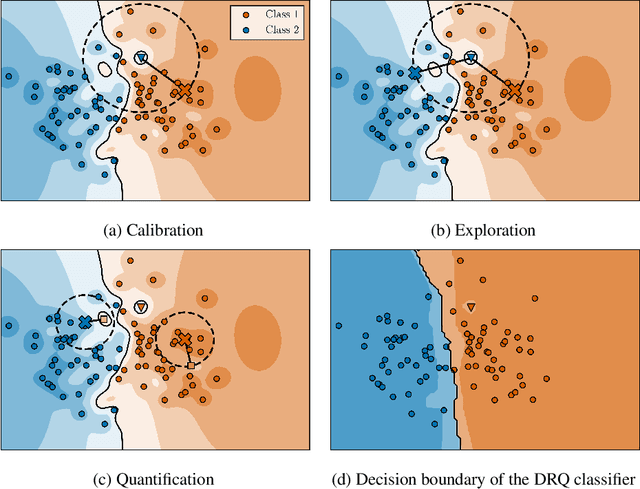
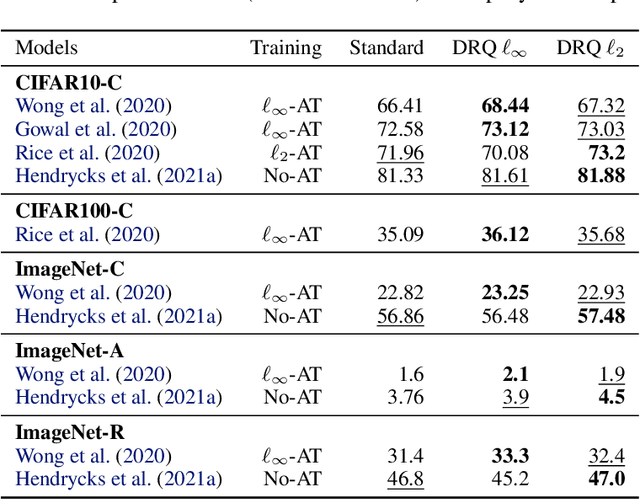

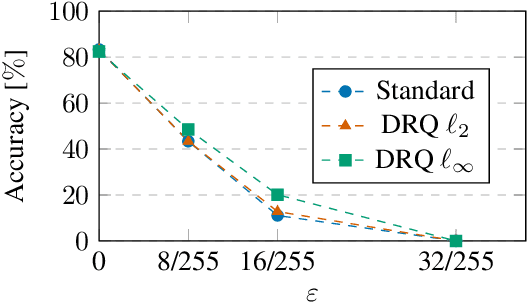
The reliability of neural networks is essential for their use in safety-critical applications. Existing approaches generally aim at improving the robustness of neural networks to either real-world distribution shifts (e.g., common corruptions and perturbations, spatial transformations, and natural adversarial examples) or worst-case distribution shifts (e.g., optimized adversarial examples). In this work, we propose the Decision Region Quantification (DRQ) algorithm to improve the robustness of any differentiable pre-trained model against both real-world and worst-case distribution shifts in the data. DRQ analyzes the robustness of local decision regions in the vicinity of a given data point to make more reliable predictions. We theoretically motivate the DRQ algorithm by showing that it effectively smooths spurious local extrema in the decision surface. Furthermore, we propose an implementation using targeted and untargeted adversarial attacks. An extensive empirical evaluation shows that DRQ increases the robustness of adversarially and non-adversarially trained models against real-world and worst-case distribution shifts on several computer vision benchmark datasets.
Learning how to Interact with a Complex Interface using Hierarchical Reinforcement Learning
Apr 21, 2022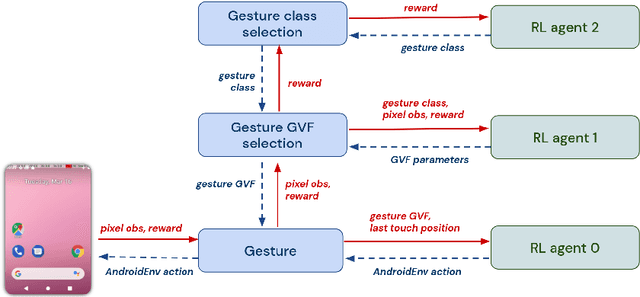
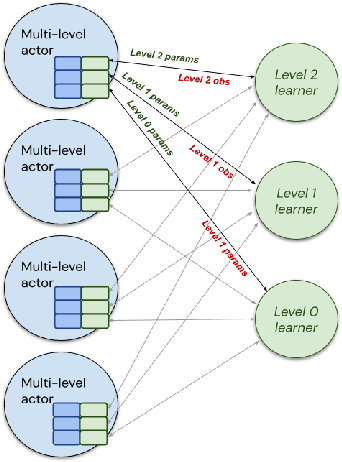
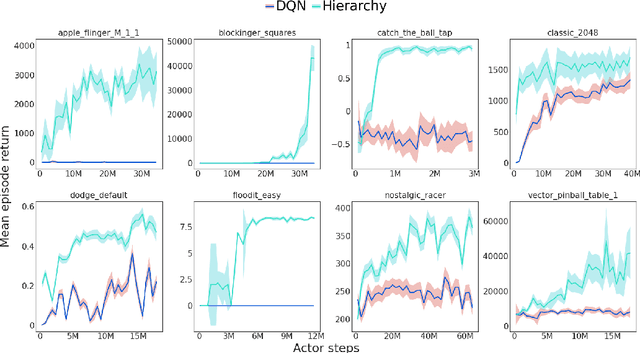
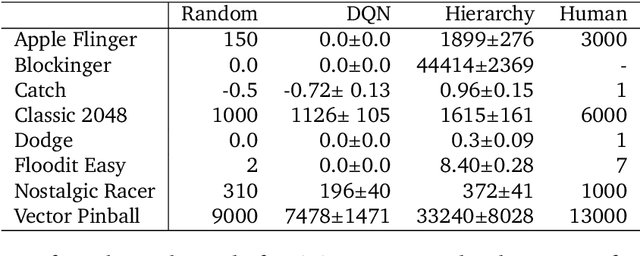
Hierarchical Reinforcement Learning (HRL) allows interactive agents to decompose complex problems into a hierarchy of sub-tasks. Higher-level tasks can invoke the solutions of lower-level tasks as if they were primitive actions. In this work, we study the utility of hierarchical decompositions for learning an appropriate way to interact with a complex interface. Specifically, we train HRL agents that can interface with applications in a simulated Android device. We introduce a Hierarchical Distributed Deep Reinforcement Learning architecture that learns (1) subtasks corresponding to simple finger gestures, and (2) how to combine these gestures to solve several Android tasks. Our approach relies on goal conditioning and can be used more generally to convert any base RL agent into an HRL agent. We use the AndroidEnv environment to evaluate our approach. For the experiments, the HRL agent uses a distributed version of the popular DQN algorithm to train different components of the hierarchy. While the native action space is completely intractable for simple DQN agents, our architecture can be used to establish an effective way to interact with different tasks, significantly improving the performance of the same DQN agent over different levels of abstraction.
Behind the Machine's Gaze: Biologically Constrained Neural Networks Exhibit Human-like Visual Attention
Apr 19, 2022
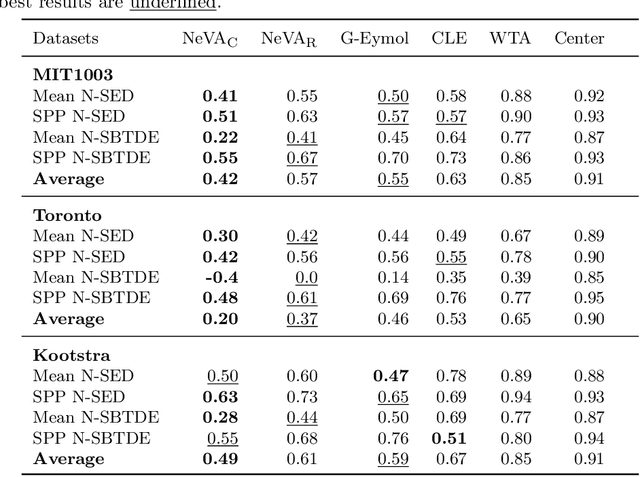
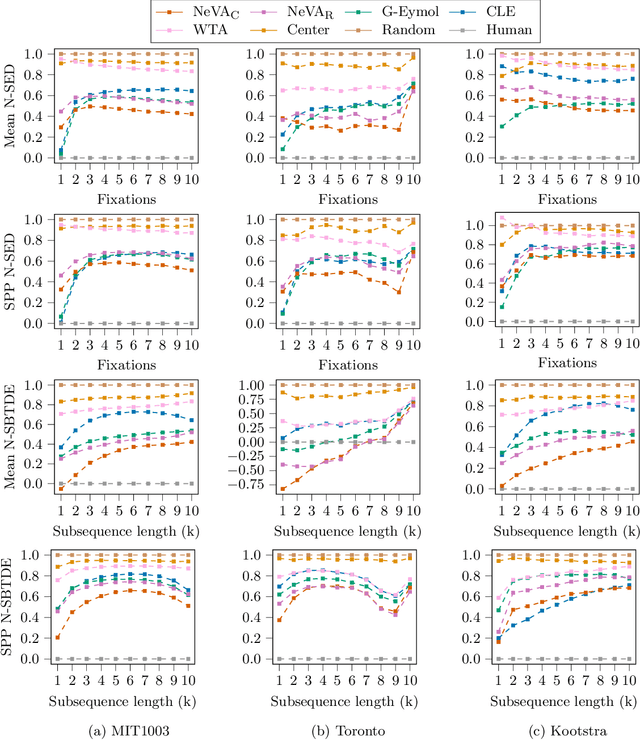

By and large, existing computational models of visual attention tacitly assume perfect vision and full access to the stimulus and thereby deviate from foveated biological vision. Moreover, modelling top-down attention is generally reduced to the integration of semantic features without incorporating the signal of a high-level visual tasks that have shown to partially guide human attention. We propose the Neural Visual Attention (NeVA) algorithm to generate visual scanpaths in a top-down manner. With our method, we explore the ability of neural networks on which we impose the biological constraints of foveated vision to generate human-like scanpaths. Thereby, the scanpaths are generated to maximize the performance with respect to the underlying visual task (i.e., classification or reconstruction). Extensive experiments show that the proposed method outperforms state-of-the-art unsupervised human attention models in terms of similarity to human scanpaths. Additionally, the flexibility of the framework allows to quantitatively investigate the role of different tasks in the generated visual behaviours. Finally, we demonstrate the superiority of the approach in a novel experiment that investigates the utility of scanpaths in real-world applications, where imperfect viewing conditions are given.
COptiDICE: Offline Constrained Reinforcement Learning via Stationary Distribution Correction Estimation
Apr 19, 2022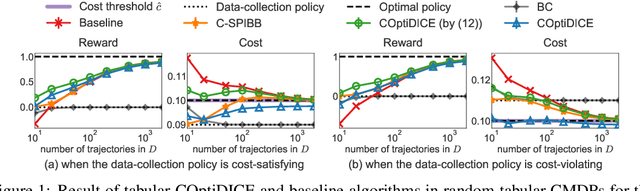
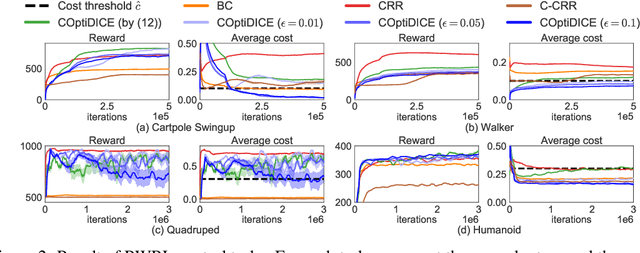
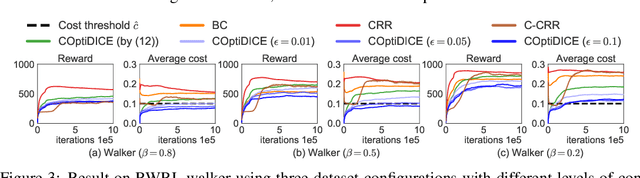
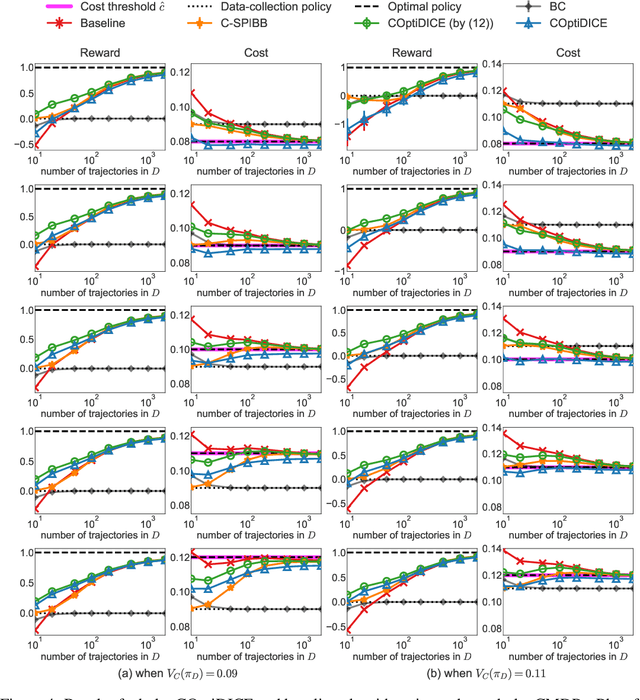
We consider the offline constrained reinforcement learning (RL) problem, in which the agent aims to compute a policy that maximizes expected return while satisfying given cost constraints, learning only from a pre-collected dataset. This problem setting is appealing in many real-world scenarios, where direct interaction with the environment is costly or risky, and where the resulting policy should comply with safety constraints. However, it is challenging to compute a policy that guarantees satisfying the cost constraints in the offline RL setting, since the off-policy evaluation inherently has an estimation error. In this paper, we present an offline constrained RL algorithm that optimizes the policy in the space of the stationary distribution. Our algorithm, COptiDICE, directly estimates the stationary distribution corrections of the optimal policy with respect to returns, while constraining the cost upper bound, with the goal of yielding a cost-conservative policy for actual constraint satisfaction. Experimental results show that COptiDICE attains better policies in terms of constraint satisfaction and return-maximization, outperforming baseline algorithms.
Towards Painless Policy Optimization for Constrained MDPs
Apr 11, 2022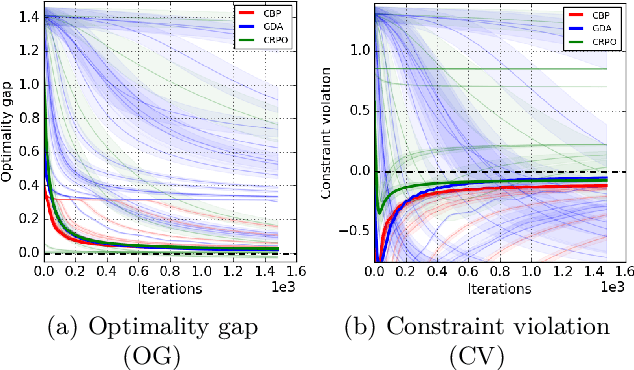

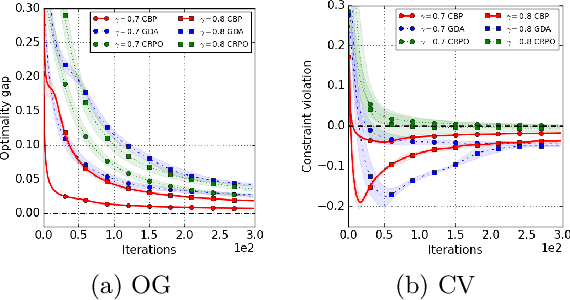
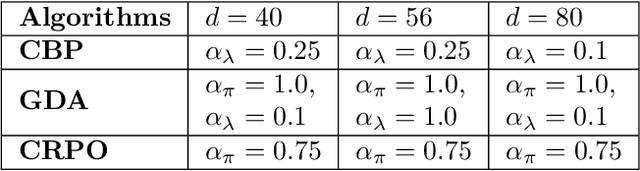
We study policy optimization in an infinite horizon, $\gamma$-discounted constrained Markov decision process (CMDP). Our objective is to return a policy that achieves large expected reward with a small constraint violation. We consider the online setting with linear function approximation and assume global access to the corresponding features. We propose a generic primal-dual framework that allows us to bound the reward sub-optimality and constraint violation for arbitrary algorithms in terms of their primal and dual regret on online linear optimization problems. We instantiate this framework to use coin-betting algorithms and propose the Coin Betting Politex (CBP) algorithm. Assuming that the action-value functions are $\varepsilon_b$-close to the span of the $d$-dimensional state-action features and no sampling errors, we prove that $T$ iterations of CBP result in an $O\left(\frac{1}{(1 - \gamma)^3 \sqrt{T}} + \frac{\varepsilon_b\sqrt{d}}{(1 - \gamma)^2} \right)$ reward sub-optimality and an $O\left(\frac{1}{(1 - \gamma)^2 \sqrt{T}} + \frac{\varepsilon_b \sqrt{d}}{1 - \gamma} \right)$ constraint violation. Importantly, unlike gradient descent-ascent and other recent methods, CBP does not require extensive hyperparameter tuning. Via experiments on synthetic and Cartpole environments, we demonstrate the effectiveness and robustness of CBP.
Selective Credit Assignment
Feb 20, 2022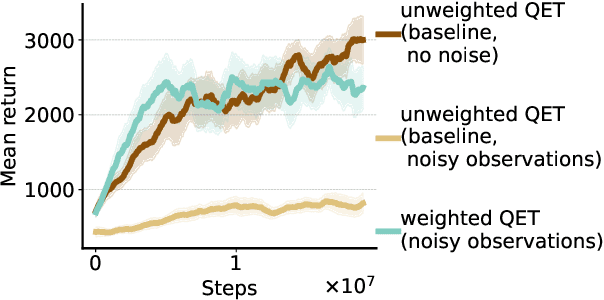
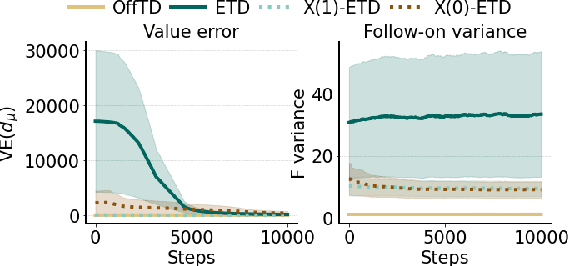
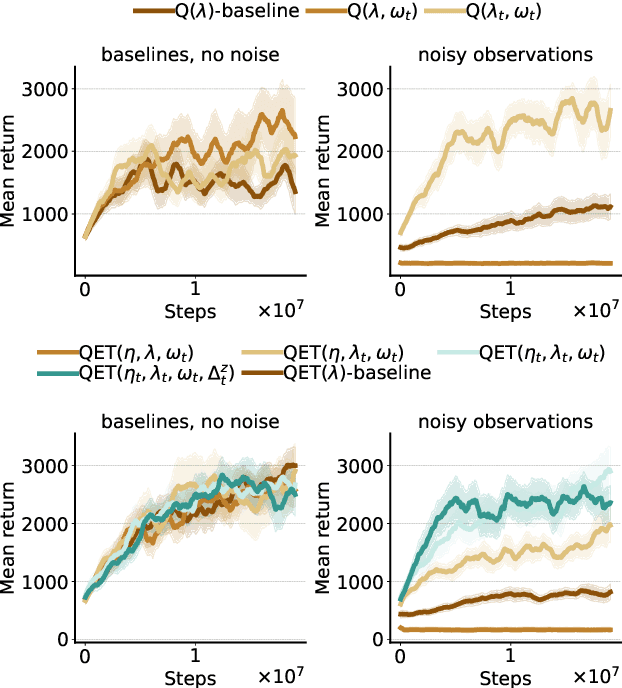
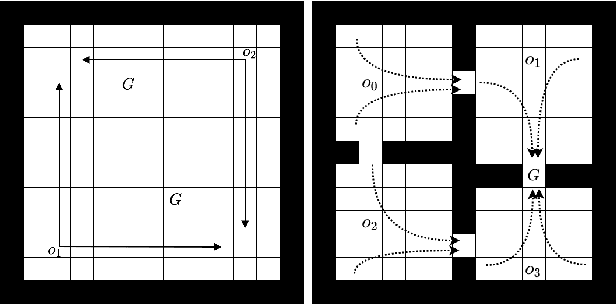
Efficient credit assignment is essential for reinforcement learning algorithms in both prediction and control settings. We describe a unified view on temporal-difference algorithms for selective credit assignment. These selective algorithms apply weightings to quantify the contribution of learning updates. We present insights into applying weightings to value-based learning and planning algorithms, and describe their role in mediating the backward credit distribution in prediction and control. Within this space, we identify some existing online learning algorithms that can assign credit selectively as special cases, as well as add new algorithms that assign credit backward in time counterfactually, allowing credit to be assigned off-trajectory and off-policy.
Improving Sample Efficiency of Value Based Models Using Attention and Vision Transformers
Feb 01, 2022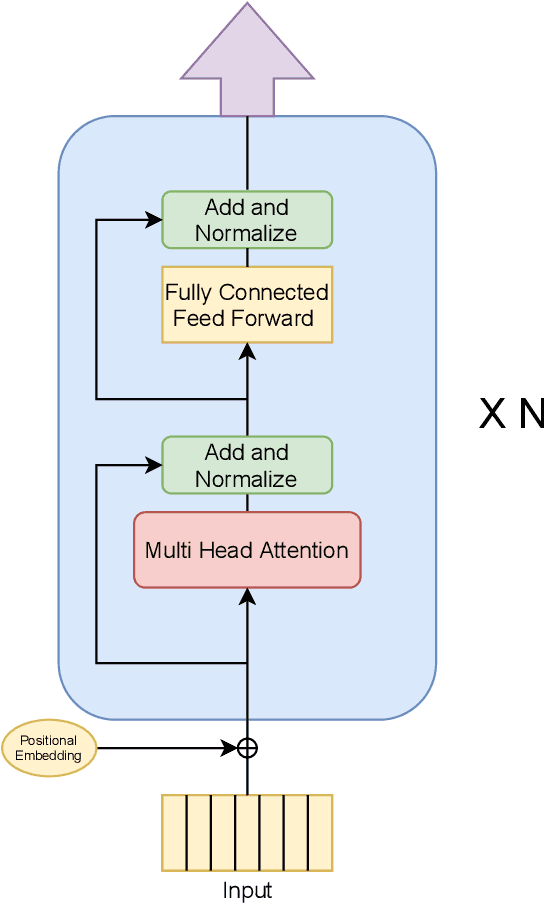
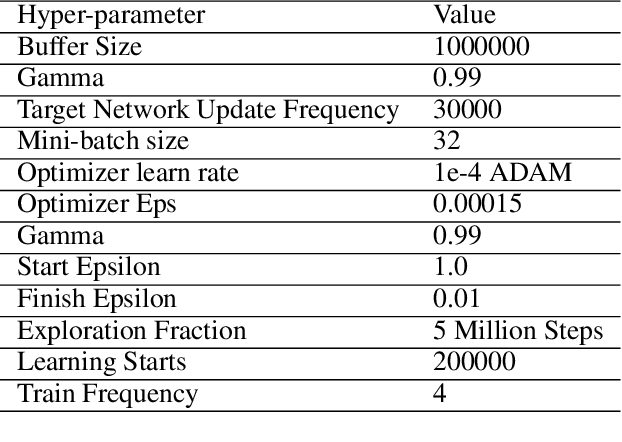
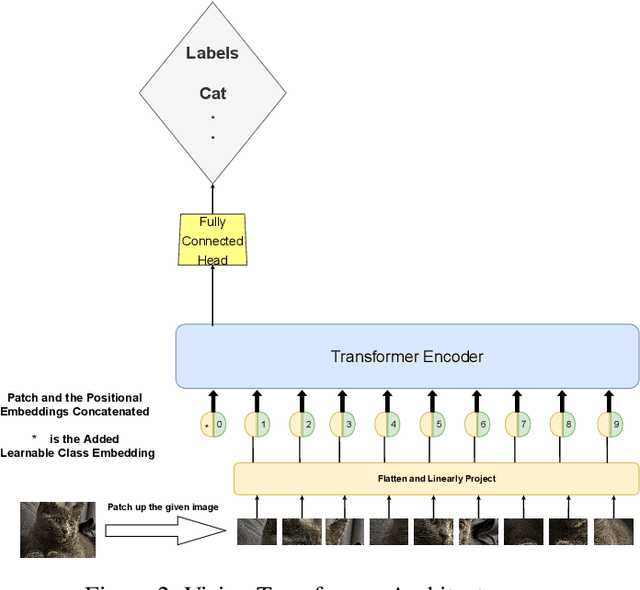
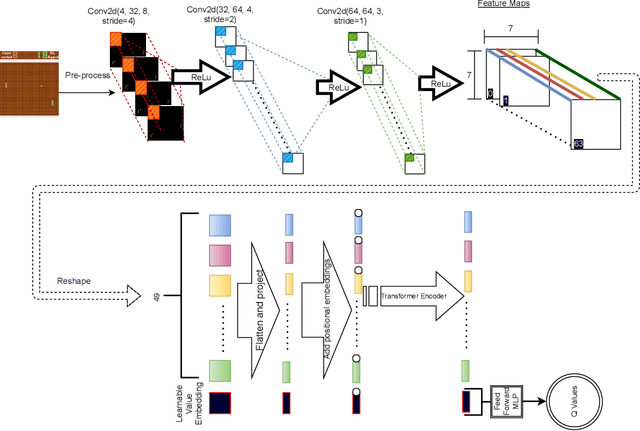
Much of recent Deep Reinforcement Learning success is owed to the neural architecture's potential to learn and use effective internal representations of the world. While many current algorithms access a simulator to train with a large amount of data, in realistic settings, including while playing games that may be played against people, collecting experience can be quite costly. In this paper, we introduce a deep reinforcement learning architecture whose purpose is to increase sample efficiency without sacrificing performance. We design this architecture by incorporating advances achieved in recent years in the field of Natural Language Processing and Computer Vision. Specifically, we propose a visually attentive model that uses transformers to learn a self-attention mechanism on the feature maps of the state representation, while simultaneously optimizing return. We demonstrate empirically that this architecture improves sample complexity for several Atari environments, while also achieving better performance in some of the games.
Why Should I Trust You, Bellman? The Bellman Error is a Poor Replacement for Value Error
Jan 28, 2022
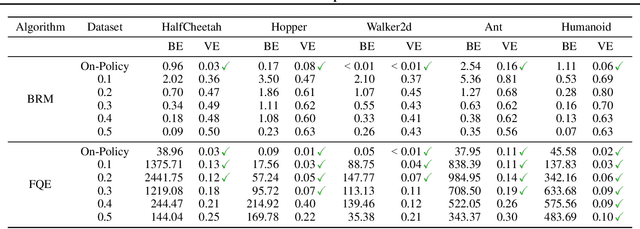
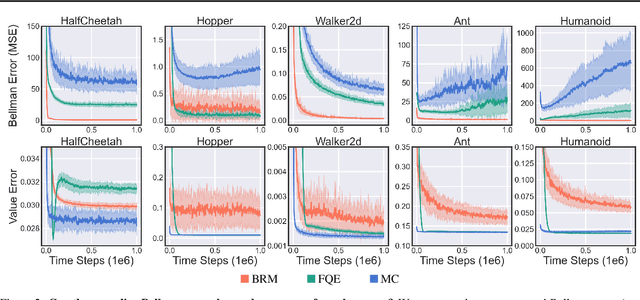
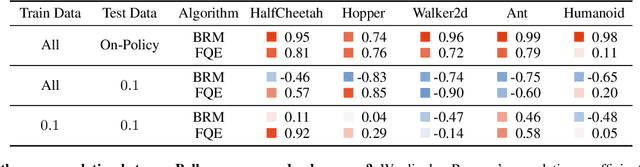
In this work, we study the use of the Bellman equation as a surrogate objective for value prediction accuracy. While the Bellman equation is uniquely solved by the true value function over all state-action pairs, we find that the Bellman error (the difference between both sides of the equation) is a poor proxy for the accuracy of the value function. In particular, we show that (1) due to cancellations from both sides of the Bellman equation, the magnitude of the Bellman error is only weakly related to the distance to the true value function, even when considering all state-action pairs, and (2) in the finite data regime, the Bellman equation can be satisfied exactly by infinitely many suboptimal solutions. This means that the Bellman error can be minimized without improving the accuracy of the value function. We demonstrate these phenomena through a series of propositions, illustrative toy examples, and empirical analysis in standard benchmark domains.
The Paradox of Choice: Using Attention in Hierarchical Reinforcement Learning
Jan 24, 2022



Decision-making AI agents are often faced with two important challenges: the depth of the planning horizon, and the branching factor due to having many choices. Hierarchical reinforcement learning methods aim to solve the first problem, by providing shortcuts that skip over multiple time steps. To cope with the breadth, it is desirable to restrict the agent's attention at each step to a reasonable number of possible choices. The concept of affordances (Gibson, 1977) suggests that only certain actions are feasible in certain states. In this work, we model "affordances" through an attention mechanism that limits the available choices of temporally extended options. We present an online, model-free algorithm to learn affordances that can be used to further learn subgoal options. We investigate the role of hard versus soft attention in training data collection, abstract value learning in long-horizon tasks, and handling a growing number of choices. We identify and empirically illustrate the settings in which the paradox of choice arises, i.e. when having fewer but more meaningful choices improves the learning speed and performance of a reinforcement learning agent.