 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaping representations through communication: community size effect in artificial learning systems
Dec 12, 2019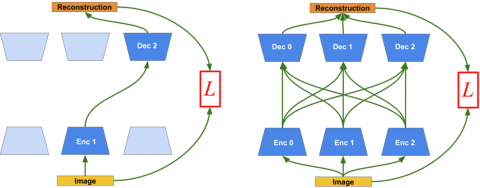
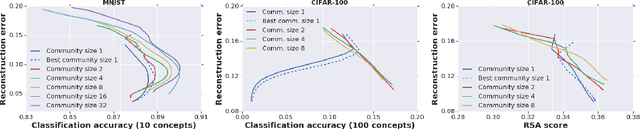
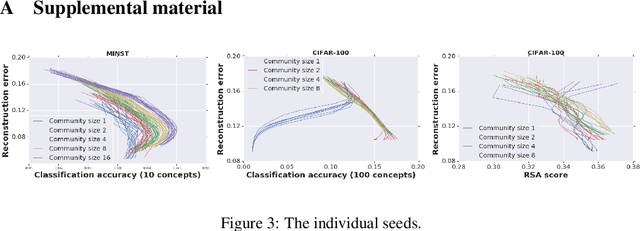
Motivated by theories of language and communication that explain why communities with large numbers of speakers have, on average, simpler languages with more regularity, we cast the representation learning problem in terms of learning to communicate. Our starting point sees the traditional autoencoder setup as a single encoder with a fixed decoder partner that must learn to communicate. Generalizing from there, we introduce community-based autoencoders in which multiple encoders and decoders collectively learn representations by being randomly paired up on successive training iterations. We find that increasing community sizes reduce idiosyncrasies in the learned codes, resulting in representations that better encode concept categories and correlate with human feature norms.
Marginalized State Distribution Entropy Regularization in Policy Optimization
Dec 11, 2019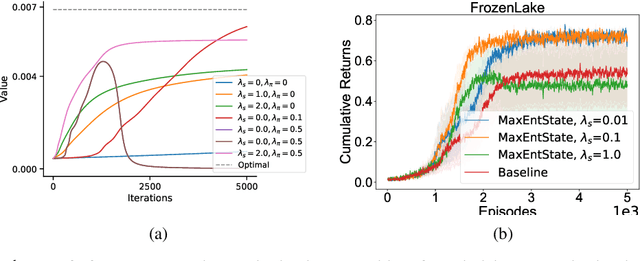
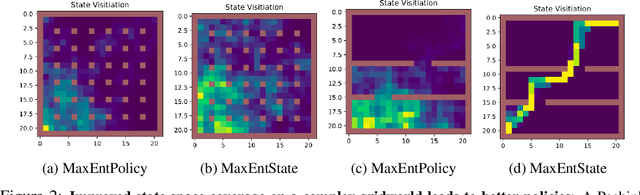
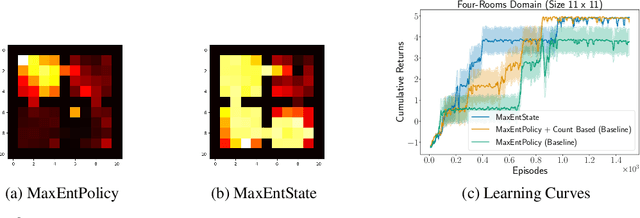
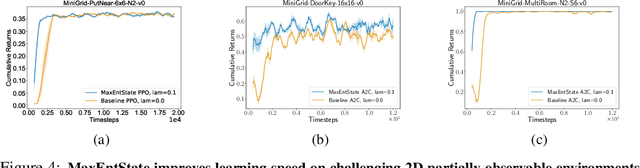
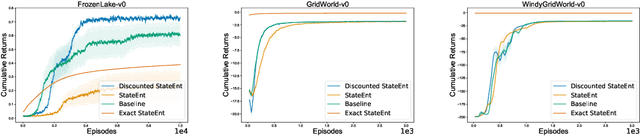
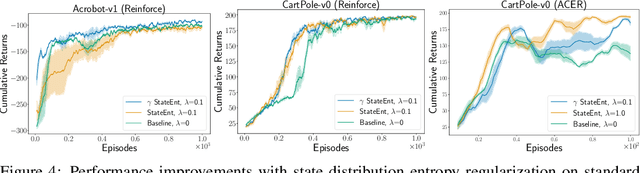
Entropy regularization is used to get improved optimization performance in reinforcement learning tasks. A common form of regularization is to maximize policy entropy to avoid premature convergence and lead to more stochastic policies for exploration through action space. However, this does not ensure exploration in the state space. In this work, we instead consider the distribution of discounted weighting of states, and propose to maximize the entropy of a lower bound approximation to the weighting of a state, based on latent space state representation. We propose entropy regularization based on the marginal state distribution, to encourage the policy to have a more uniform distribution over the state space for exploration. Our approach based on marginal state distribution achieves superior state space coverage on complex gridworld domains, that translate into empirical gains in sparse reward 3D maze navigation and continuous control domains compared to entropy regularization with stochastic policies.
Doubly Robust Off-Policy Actor-Critic Algorithms for Reinforcement Learning
Dec 11, 2019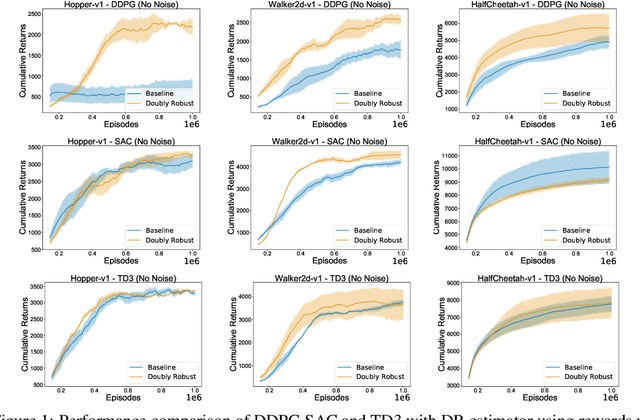
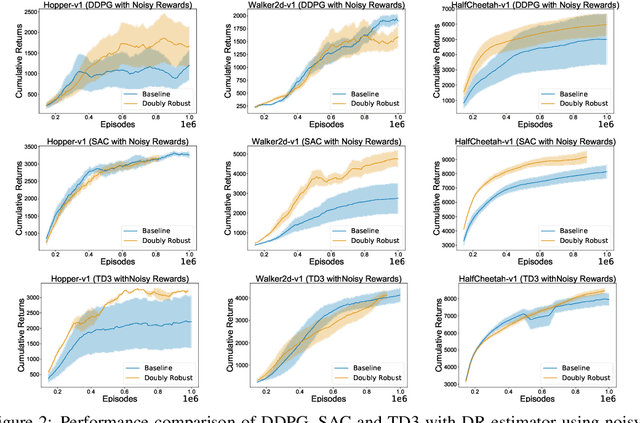
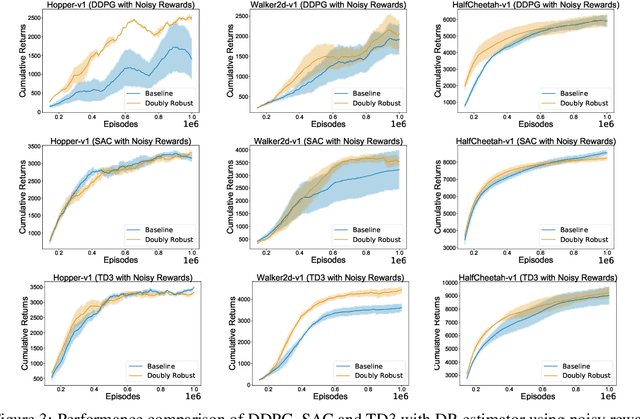
We study the problem of off-policy critic evaluation in several variants of value-based off-policy actor-critic algorithms. Off-policy actor-critic algorithms require an off-policy critic evaluation step, to estimate the value of the new policy after every policy gradient update. Despite enormous success of off-policy policy gradients on control tasks, existing general methods suffer from high variance and instability, partly because the policy improvement depends on gradient of the estimated value function. In this work, we present a new way of off-policy policy evaluation in actor-critic, based on the doubly robust estimators. We extend the doubly robust estimator from off-policy policy evaluation (OPE) to actor-critic algorithms that consist of a reward estimator performance model. We find that doubly robust estimation of the critic can significantly improve performance in continuous control tasks. Furthermore, in cases where the reward function is stochastic that can lead to high variance, doubly robust critic estimation can improve performance under corrupted, stochastic reward signals, indicating its usefulness for robust and safe reinforcement learning.
Entropy Regularization with Discounted Future State Distribution in Policy Gradient Methods
Dec 11, 2019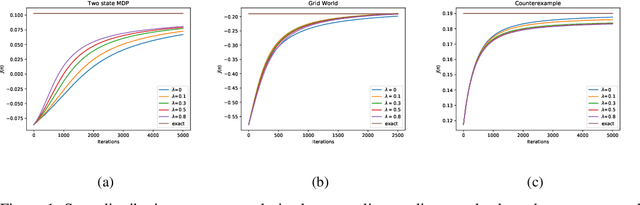
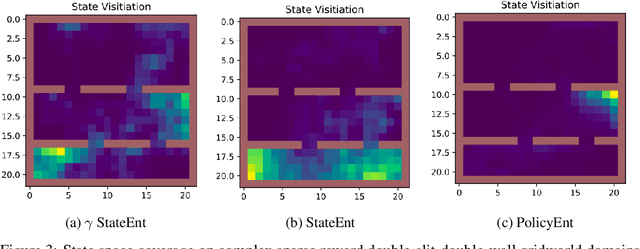
The policy gradient theorem is defined based on an objective with respect to the initial distribution over states. In the discounted case, this results in policies that are optimal for one distribution over initial states, but may not be uniformly optimal for others, no matter where the agent starts from. Furthermore, to obtain unbiased gradient estimates, the starting point of the policy gradient estimator requires sampling states from a normalized discounted weighting of states. However, the difficulty of estimating the normalized discounted weighting of states, or the stationary state distribution, is quite well-known. Additionally, the large sample complexity of policy gradient methods is often attributed to insufficient exploration, and to remedy this, it is often assumed that the restart distribution provides sufficient exploration in these algorithms. In this work, we propose exploration in policy gradient methods based on maximizing entropy of the discounted future state distribution. The key contribution of our work includes providing a practically feasible algorithm to estimate the normalized discounted weighting of states, i.e, the \textit{discounted future state distribution}. We propose that exploration can be achieved by entropy regularization with the discounted state distribution in policy gradients, where a metric for maximal coverage of the state space can be based on the entropy of the induced state distribution. The proposed approach can be considered as a three time-scale algorithm and under some mild technical conditions, we prove its convergence to a locally optimal policy. Experimentally, we demonstrate usefulness of regularization with the discounted future state distribution in terms of increased state space coverage and faster learning on a range of complex tasks.
Hindsight Credit Assignment
Dec 05, 2019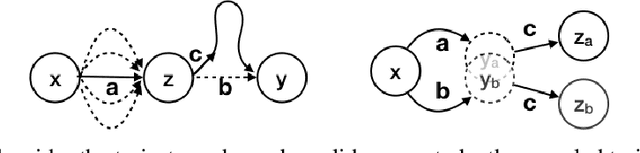

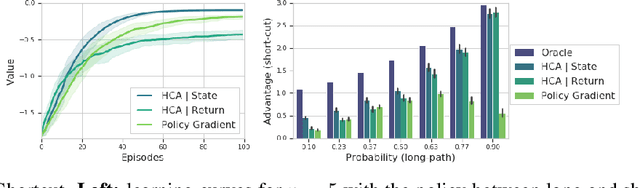
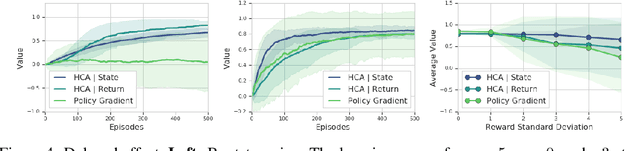
We consider the problem of efficient credit assignment in reinforcement learning. In order to efficiently and meaningfully utilize new data, we propose to explicitly assign credit to past decisions based on the likelihood of them having led to the observed outcome. This approach uses new information in hindsight, rather than employing foresight. Somewhat surprisingly, we show that value functions can be rewritten through this lens, yielding a new family of algorithms. We study the properties of these algorithms, and empirically show that they successfully address important credit assignment challenges, through a set of illustrative tasks.
Algorithmic Improvements for Deep Reinforcement Learning applied to Interactive Fiction
Nov 28, 2019

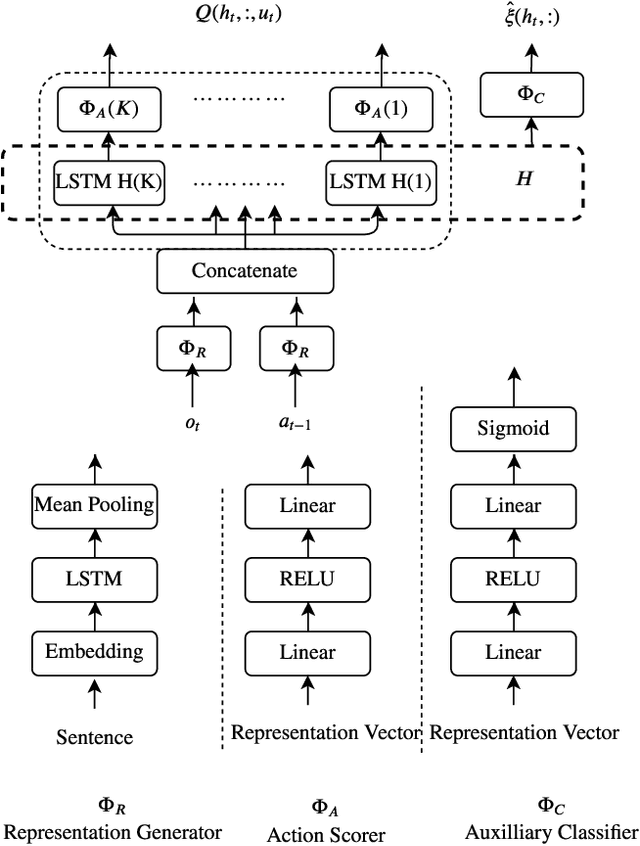

Text-based games are a natural challenge domain for deep reinforcement learning algorithms. Their state and action spaces are combinatorially large, their reward function is sparse, and they are partially observable: the agent is informed of the consequences of its actions through textual feedback. In this paper we emphasize this latter point and consider the design of a deep reinforcement learning agent that can play from feedback alone. Our design recognizes and takes advantage of the structural characteristics of text-based games. We first propose a contextualisation mechanism, based on accumulated reward, which simplifies the learning problem and mitigates partial observability. We then study different methods that rely on the notion that most actions are ineffectual in any given situation, following Zahavy et al.'s idea of an admissible action. We evaluate these techniques in a series of text-based games of increasing difficulty based on the TextWorld framework, as well as the iconic game Zork. Empirically, we find that these techniques improve the performance of a baseline deep reinforcement learning agent applied to text-based games.
Efficient Planning under Partial Observability with Unnormalized Q Functions and Spectral Learning
Nov 22, 2019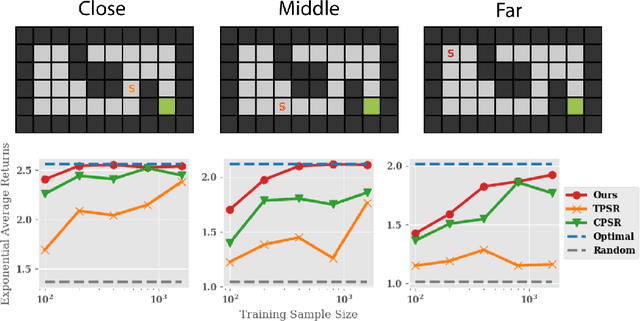
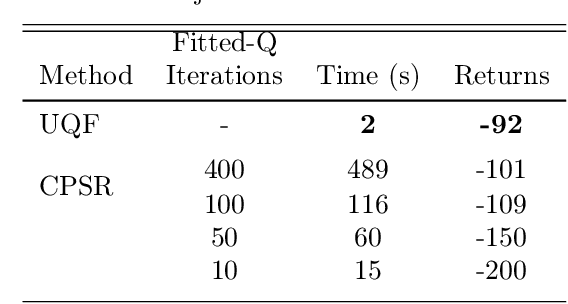
Learning and planning in partially-observable domains is one of the most difficult problems in reinforcement learning. Traditional methods consider these two problems as independent, resulting in a classical two-stage paradigm: first learn the environment dynamics and then plan accordingly. This approach, however, disconnects the two problems and can consequently lead to algorithms that are sample inefficient and time consuming. In this paper, we propose a novel algorithm that combines learning and planning together. Our algorithm is closely related to the spectral learning algorithm for predicitive state representations and offers appealing theoretical guarantees and time complexity. We empirically show on two domains that our approach is more sample and time efficient compared to classical methods.
Navigation Agents for the Visually Impaired: A Sidewalk Simulator and Experiments
Oct 29, 2019


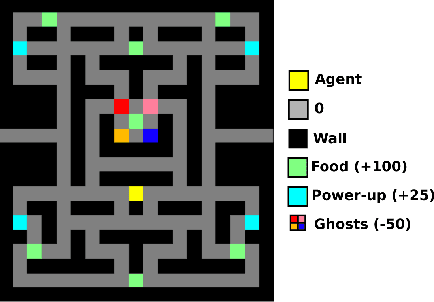
Millions of blind and visually-impaired (BVI) people navigate urban environments every day, using smartphones for high-level path-planning and white canes or guide dogs for local information. However, many BVI people still struggle to travel to new places. In our endeavor to create a navigation assistant for the BVI, we found that existing Reinforcement Learning (RL) environments were unsuitable for the task. This work introduces SEVN, a sidewalk simulation environment and a neural network-based approach to creating a navigation agent. SEVN contains panoramic images with labels for house numbers, doors, and street name signs, and formulations for several navigation tasks. We study the performance of an RL algorithm (PPO) in this setting. Our policy model fuses multi-modal observations in the form of variable resolution images, visible text, and simulated GPS data to navigate to a goal door. We hope that this dataset, simulator, and experimental results will provide a foundation for further research into the creation of agents that can assist members of the BVI community with outdoor navigation.
Actor Critic with Differentially Private Critic
Oct 14, 2019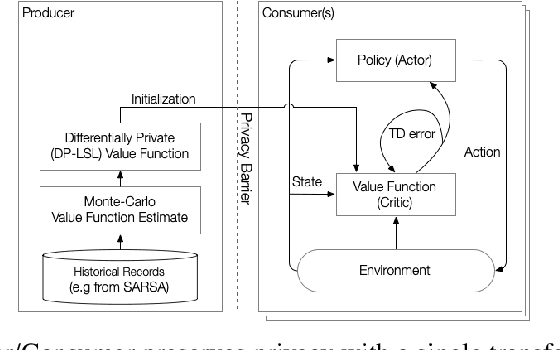
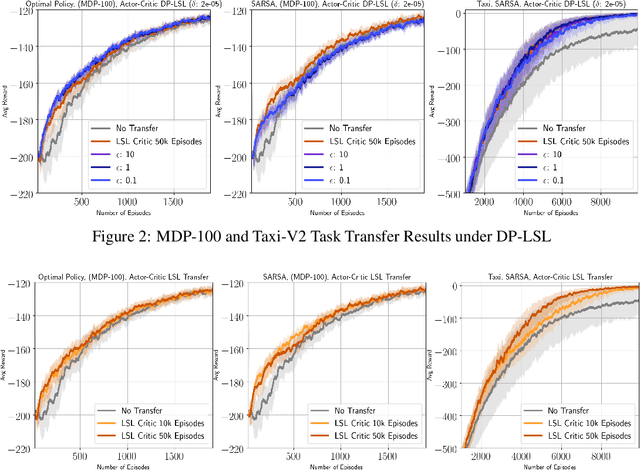
Reinforcement learning algorithms are known to be sample inefficient, and often performance on one task can be substantially improved by leveraging information (e.g., via pre-training) on other related tasks. In this work, we propose a technique to achieve such knowledge transfer in cases where agent trajectories contain sensitive or private information, such as in the healthcare domain. Our approach leverages a differentially private policy evaluation algorithm to initialize an actor-critic model and improve the effectiveness of learning in downstream tasks. We empirically show this technique increases sample efficiency in resource-constrained control problems while preserving the privacy of trajectories collected in an upstream task.
Augmenting learning using symmetry in a biologically-inspired domain
Oct 01, 2019
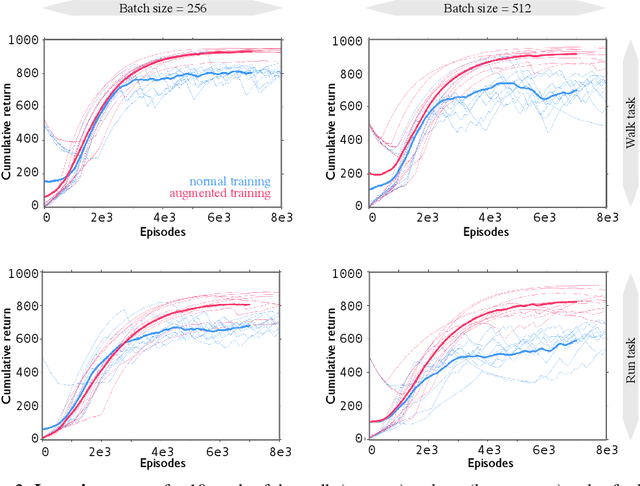
Invariances to translation, rotation and other spatial transformations are a hallmark of the laws of motion, and have widespread use in the natural sciences to reduce the dimensionality of systems of equations. In supervised learning, such as in image classification tasks, rotation, translation and scale invariances are used to augment training datasets. In this work, we use data augmentation in a similar way, exploiting symmetry in the quadruped domain of the DeepMind control suite (Tassa et al. 2018) to add to the trajectories experienced by the actor in the actor-critic algorithm of Abdolmaleki et al. (2018). In a data-limited regime, the agent using a set of experiences augmented through symmetry is able to learn faster. Our approach can be used to inject knowledge of invariances in the domain and task to augment learning in robots, and more generally, to speed up learning in realistic robotics applications.