 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraPN: Unstructured Terrain Navigation using Online Self-Supervised Learning
Mar 11, 2022
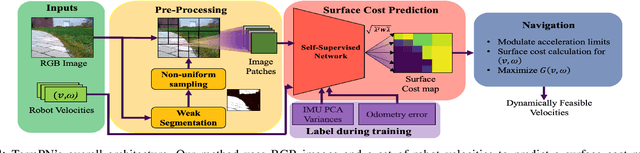
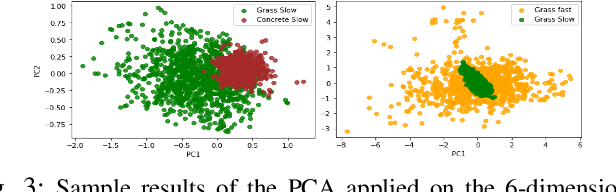
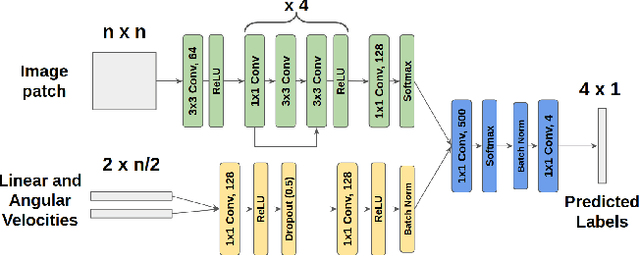
We present TerraPN, a novel method that learns the surface properties (traction, bumpiness, deformability, etc.) of complex outdoor terrains directly from robot-terrain interactions through self-supervised learning, and uses it for autonomous robot navigation. Our method uses RGB images of terrain surfaces and the robot's velocities as inputs, and the IMU vibrations and odometry errors experienced by the robot as labels for self-supervision. Our method computes a surface cost map that differentiates smooth, high-traction surfaces (low navigation costs) from bumpy, slippery, deformable surfaces (high navigation costs). We compute the cost map by non-uniformly sampling patches from the input RGB image by detecting boundaries between surfaces resulting in low inference times (47.27% lower) compared to uniform sampling and existing segmentation methods. We present a novel navigation algorithm that accounts for a surface's cost, computes cost-based acceleration limits for the robot, and dynamically feasible, collision-free trajectories. TerraPN's surface cost prediction can be trained in ~25 minutes for five different surfaces, compared to several hours for previous learning-based segmentation methods. In terms of navigation, our method outperforms previous works in terms of success rates (up to 35.84% higher), vibration cost of the trajectories (up to 21.52% lower), and slowing the robot on bumpy, deformable surfaces (up to 46.76% slower) in different scenarios.
SelfTune: Metrically Scaled Monocular Depth Estimation through Self-Supervised Learning
Mar 10, 2022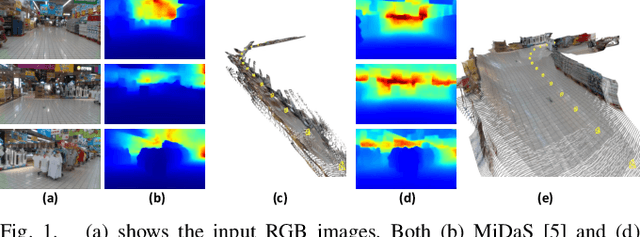
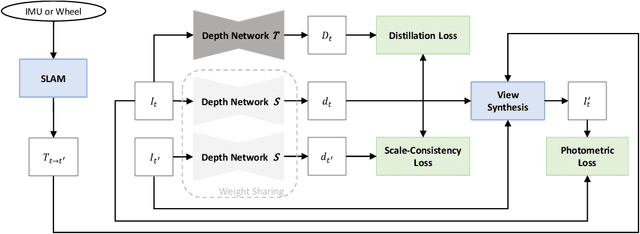
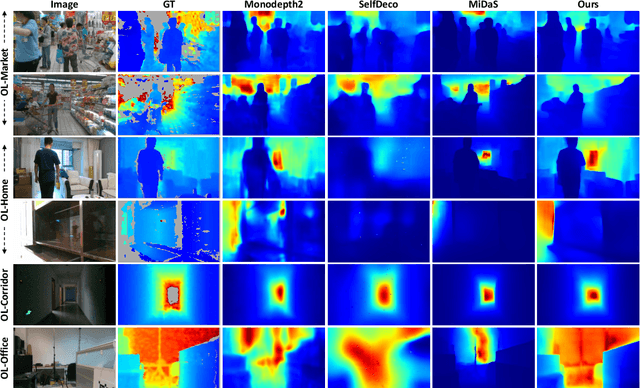
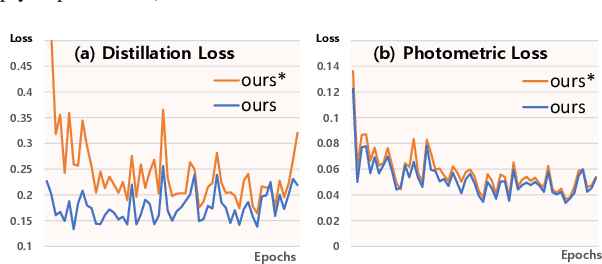
Monocular depth estimation in the wild inherently predicts depth up to an unknown scale. To resolve scale ambiguity issue, we present a learning algorithm that leverages monocular simultaneous localization and mapping (SLAM) with proprioceptive sensors. Such monocular SLAM systems can provide metrically scaled camera poses. Given these metric poses and monocular sequences, we propose a self-supervised learning method for the pre-trained supervised monocular depth networks to enable metrically scaled depth estimation. Our approach is based on a teacher-student formulation which guides our network to predict high-quality depths. We demonstrate that our approach is useful for various applications such as mobile robot navigation and is applicable to diverse environments. Our full system shows improvements over recent self-supervised depth estimation and completion methods on EuRoC, OpenLORIS, and ScanNet datasets.
Dense Multi-Agent Navigation Using Voronoi Cells and Congestion Metric-based Replanning
Feb 23, 2022
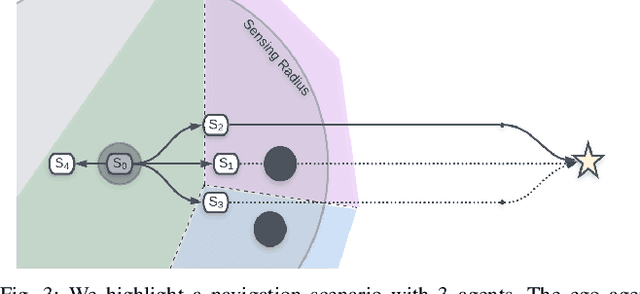
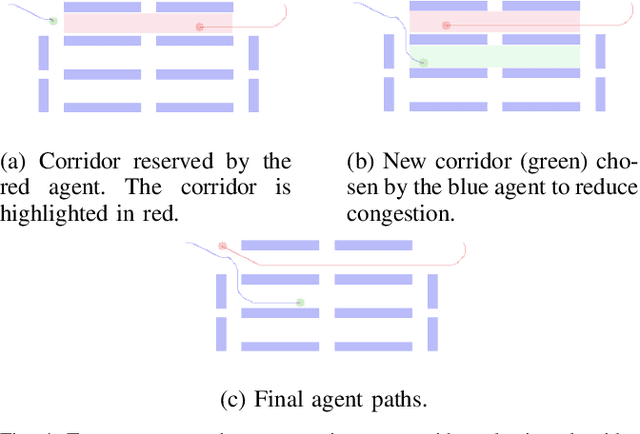
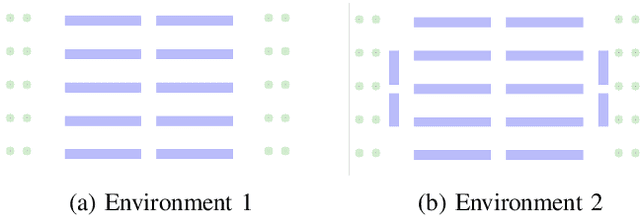
We present a decentralized path-planning algorithm for navigating multiple differential-drive robots in dense environments. In contrast to prior decentralized methods, we propose a novel congestion metric-based replanning that couples local and global planning techniques to efficiently navigate in scenarios with multiple corridors. To handle dense scenes with narrow passages, our approach computes the initial path for each agent to its assigned goal using a lattice planner. Based on neighbors' information, each agent performs online replanning using a congestion metric that tends to reduce the collisions and improves the navigation performance. Furthermore, we use the Voronoi cells of each agent to plan the local motion as well as a corridor selection strategy to limit the congestion in narrow passages. We evaluate the performance of our approach in complex warehouse-like scenes and demonstrate improved performance and efficiency over prior methods. In addition, our approach results in a higher success rate in terms of collision-free navigation to the goals.
Multimodal Emotion Recognition using Transfer Learning from Speaker Recognition and BERT-based models
Feb 16, 2022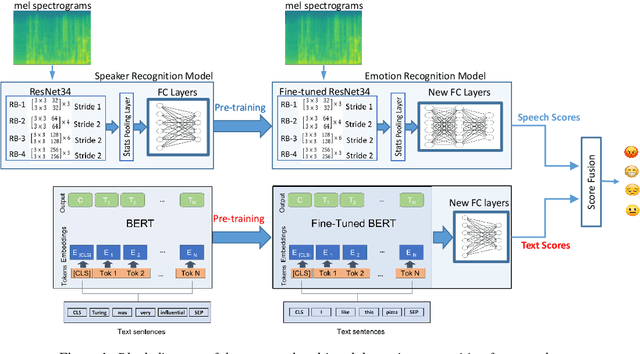
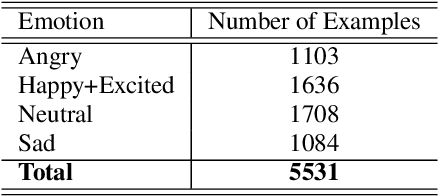
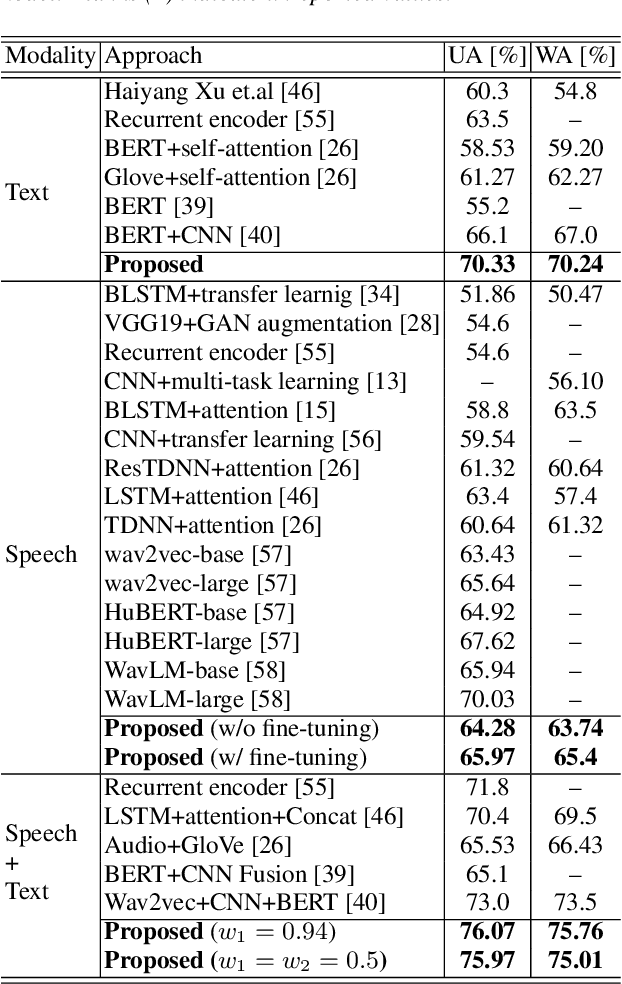
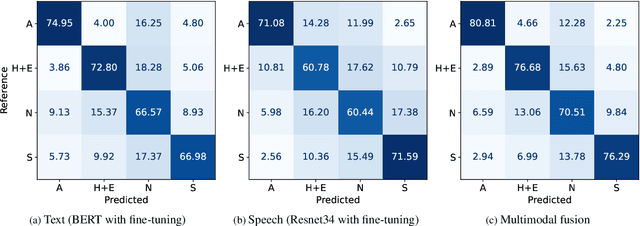
Automatic emotion recognition plays a key role in computer-human interaction as it has the potential to enrich the next-generation artificial intelligence with emotional intelligence. It finds applications in customer and/or representative behavior analysis in call centers, gaming, personal assistants, and social robots, to mention a few. Therefore, there has been an increasing demand to develop robust automatic methods to analyze and recognize the various emotions. In this paper, we propose a neural network-based emotion recognition framework that uses a late fusion of transfer-learned and fine-tuned models from speech and text modalities. More specifically, we i) adapt a residual network (ResNet) based model trained on a large-scale speaker recognition task using transfer learning along with a spectrogram augmentation approach to recognize emotions from speech, and ii) use a fine-tuned bidirectional encoder representations from transformers (BERT) based model to represent and recognize emotions from the text. The proposed system then combines the ResNet and BERT-based model scores using a late fusion strategy to further improve the emotion recognition performance. The proposed multimodal solution addresses the data scarcity limitation in emotion recognition using transfer learning, data augmentation, and fine-tuning, thereby improving the generalization performance of the emotion recognition models. We evaluate the effectiveness of our proposed multimodal approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that both audio and text-based models improve the emotion recognition performance and that the proposed multimodal solution achieves state-of-the-art results on the IEMOCAP benchmark.
A Psychoacoustic Quality Criterion for Path-Traced Sound Propagation
Feb 03, 2022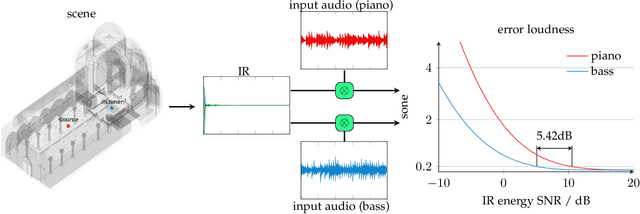


In developing virtual acoustic environments, it is important to understand the relationship between the computation cost and the perceptual significance of the resultant numerical error. In this paper, we propose a quality criterion that evaluates the error significance of path-tracing-based sound propagation simulators. We present an analytical formula that estimates the error signal power spectrum. With this spectrum estimation, we can use a modified Zwicker's loudness model to calculate the relative loudness of the error signal masked by the ideal output. Our experimental results show that the proposed criterion can explain the human perception of simulation error in a variety of cases.
An Intelligent Self-driving Truck System For Highway Transportation
Dec 31, 2021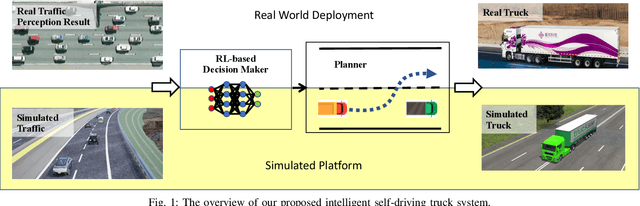
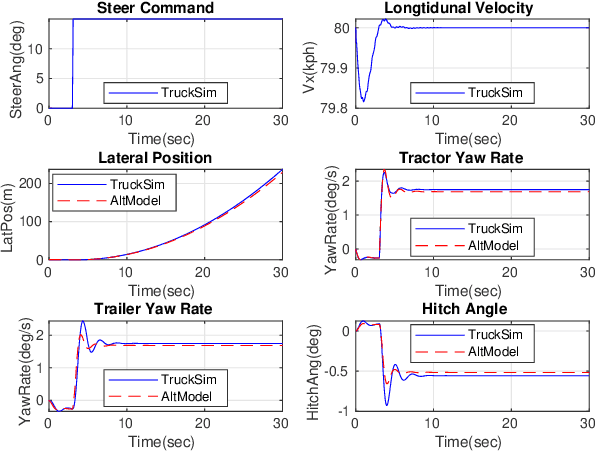
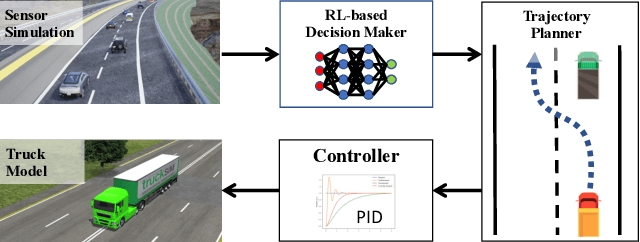
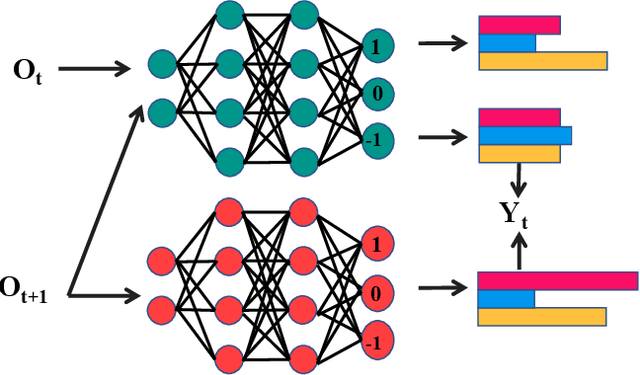
Recently, there have been many advances in autonomous driving society, attracting a lot of attention from academia and industry. However, existing works mainly focus on cars, extra development is still required for self-driving truck algorithms and models. In this paper, we introduce an intelligent self-driving truck system. Our presented system consists of three main components, 1) a realistic traffic simulation module for generating realistic traffic flow in testing scenarios, 2) a high-fidelity truck model which is designed and evaluated for mimicking real truck response in real-world deployment, 3) an intelligent planning module with learning-based decision making algorithm and multi-mode trajectory planner, taking into account the truck's constraints, road slope changes, and the surrounding traffic flow. We provide quantitative evaluations for each component individually to demonstrate the fidelity and performance of each part. We also deploy our proposed system on a real truck and conduct real world experiments which shows our system's capacity of mitigating sim-to-real gap. Our code is available at https://github.com/InceptioResearch/IITS
Dynamic Coherence-Based EM Ray Tracing Simulations in Vehicular Environments
Dec 14, 2021
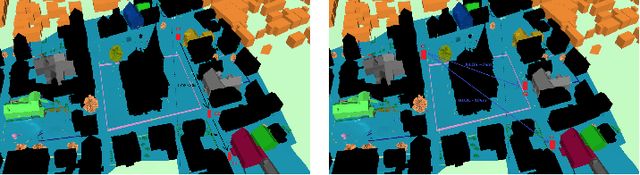
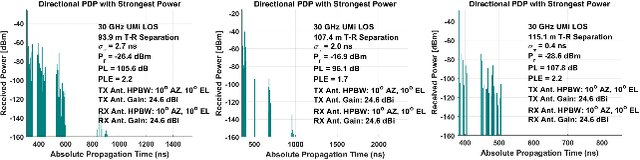
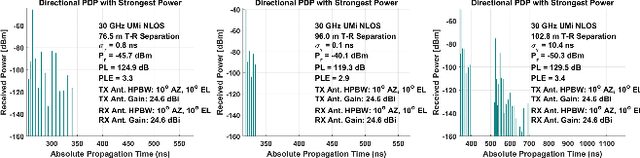
5G applications have become increasingly popular in recent years as the spread of 5G network deployment has grown. For vehicular networks, mmWave band signals have been well studied and used for communication and sensing. In this work, we propose a new dynamic ray tracing algorithm that exploits spatial and temporal coherence. We evaluate the performance by comparing the results on typical vehicular communication scenarios with NYUSIM, which builds on stochastic models, and Winprop, which utilizes the deterministic model for simulations with given environment information. We compare the performance of our algorithm on complex, urban models and observe the reduction in computation time by 60% compared to NYUSIM and 30% compared to Winprop, while maintaining similar prediction accuracy.
N-Cloth: Predicting 3D Cloth Deformation with Mesh-Based Networks
Dec 13, 2021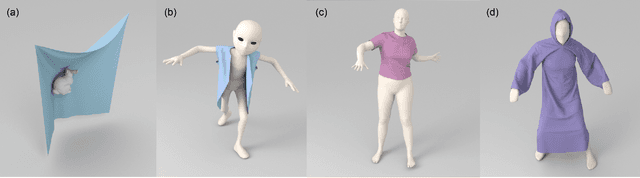
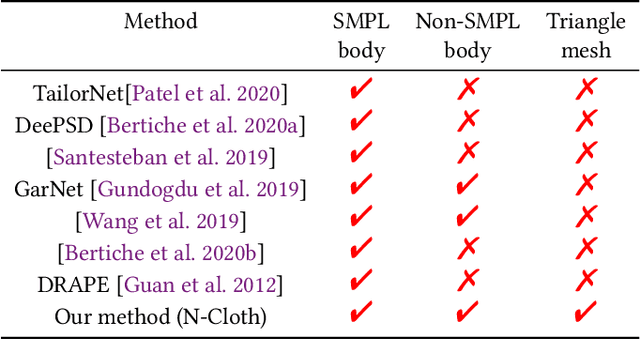
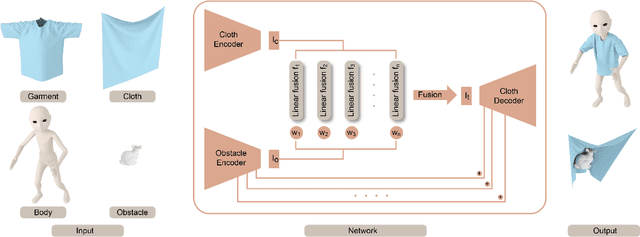

We present a novel mesh-based learning approach (N-Cloth) for plausible 3D cloth deformation prediction. Our approach is general and can handle cloth or obstacles represented by triangle meshes with arbitrary topology. We use graph convolution to transform the cloth and object meshes into a latent space to reduce the non-linearity in the mesh space. Our network can predict the target 3D cloth mesh deformation based on the state of the initial cloth mesh template and the target obstacle mesh. Our approach can handle complex cloth meshes with up to $100$K triangles and scenes with various objects corresponding to SMPL humans, Non-SMPL humans, or rigid bodies. In practice, our approach demonstrates good temporal coherence between successive input frames and can be used to generate plausible cloth simulation at $30-45$ fps on an NVIDIA GeForce RTX 3090 GPU. We highlight its benefits over prior learning-based methods and physically-based cloth simulators.
Using Graph-Theoretic Machine Learning to Predict Human Driver Behavior
Nov 04, 2021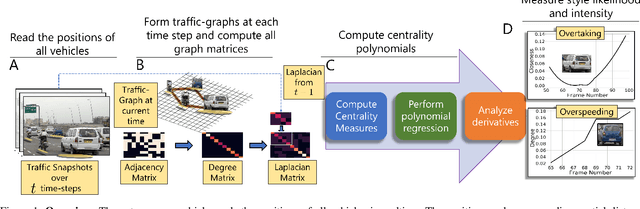
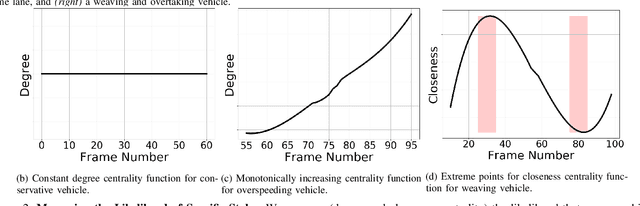
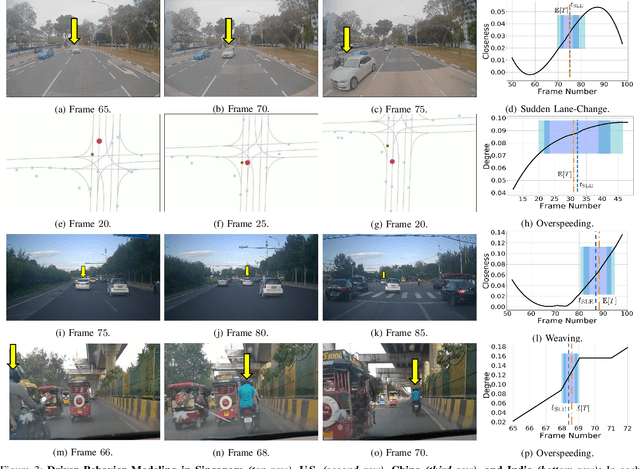

Studies have shown that autonomous vehicles (AVs) behave conservatively in a traffic environment composed of human drivers and do not adapt to local conditions and socio-cultural norms. It is known that socially aware AVs can be designed if there exists a mechanism to understand the behaviors of human drivers. We present an approach that leverages machine learning to predict, the behaviors of human drivers. This is similar to how humans implicitly interpret the behaviors of drivers on the road, by only observing the trajectories of their vehicles. We use graph-theoretic tools to extract driver behavior features from the trajectories and machine learning to obtain a computational mapping between the extracted trajectory of a vehicle in traffic and the driver behaviors. Compared to prior approaches in this domain, we prove that our method is robust, general, and extendable to broad-ranging applications such as autonomous navigation. We evaluate our approach on real-world traffic datasets captured in the U.S., India, China, and Singapore, as well as in simulation.
Active Learning of Neural Collision Handler for Complex 3D Mesh Deformations
Oct 08, 2021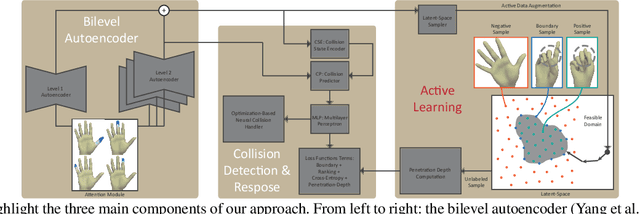
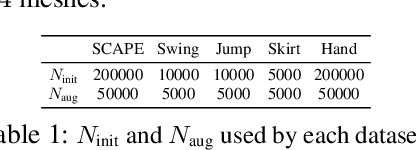
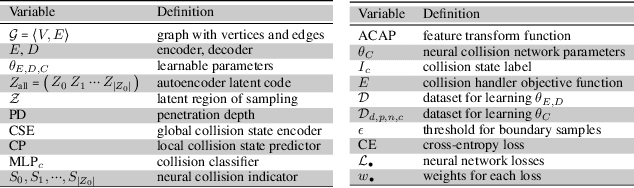
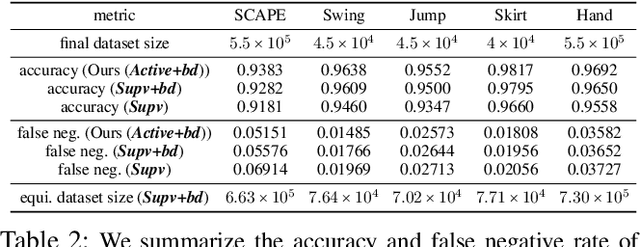
We present a robust learning algorithm to detect and handle collisions in 3D deforming meshes. Our collision detector is represented as a bilevel deep autoencoder with an attention mechanism that identifies colliding mesh sub-parts. We use a numerical optimization algorithm to resolve penetrations guided by the network. Our learned collision handler can resolve collisions for unseen, high-dimensional meshes with thousands of vertices. To obtain stable network performance in such large and unseen spaces, we progressively insert new collision data based on the errors in network inferences. We automatically label these data using an analytical collision detector and progressively fine-tune our detection networks. We evaluate our method for collision handling of complex, 3D meshes coming from several datasets with different shapes and topologies, including datasets corresponding to dressed and undressed human poses, cloth simulations, and human hand poses acquired using multiview capture systems. Our approach outperforms supervised learning methods and achieves $93.8-98.1\%$ accuracy compared to the groundtruth by analytic methods. Compared to prior learning methods, our approach results in a $5.16\%-25.50\%$ lower false negative rate in terms of collision checking and a $9.65\%-58.91\%$ higher success rate in collision handling.