 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlay It Back: Iterative Attention for Audio Recognition
Oct 20, 2022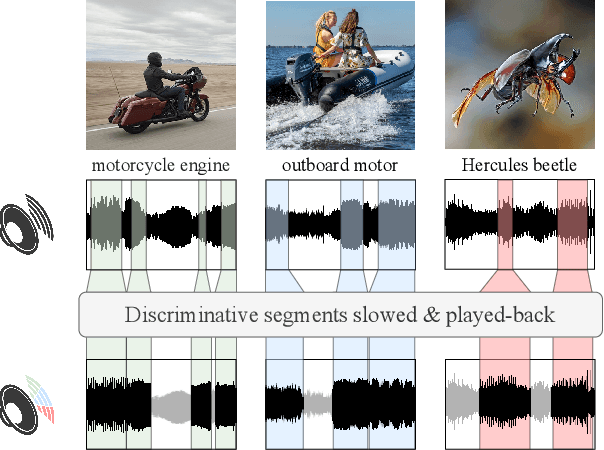
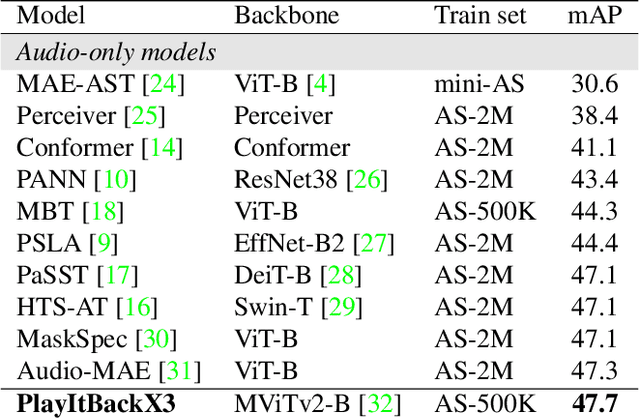
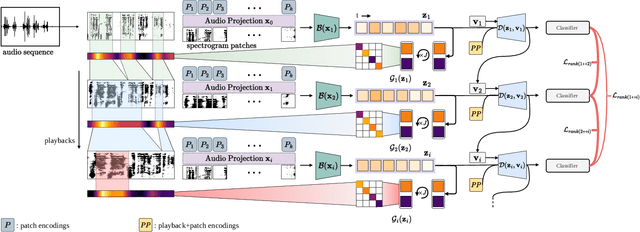
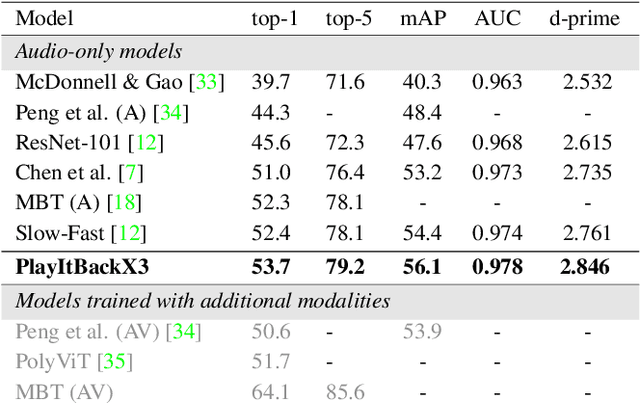
A key function of auditory cognition is the association of characteristic sounds with their corresponding semantics over time. Humans attempting to discriminate between fine-grained audio categories, often replay the same discriminative sounds to increase their prediction confidence. We propose an end-to-end attention-based architecture that through selective repetition attends over the most discriminative sounds across the audio sequence. Our model initially uses the full audio sequence and iteratively refines the temporal segments replayed based on slot attention. At each playback, the selected segments are replayed using a smaller hop length which represents higher resolution features within these segments. We show that our method can consistently achieve state-of-the-art performance across three audio-classification benchmarks: AudioSet, VGG-Sound, and EPIC-KITCHENS-100.
ConTra: text nsformer for Cross-Modal Video Retrieval
Oct 09, 2022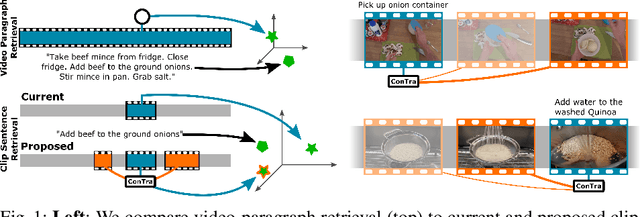
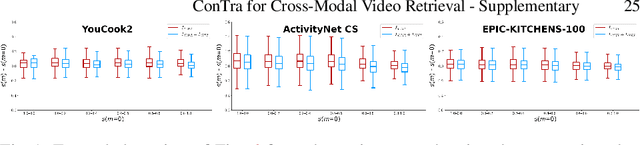
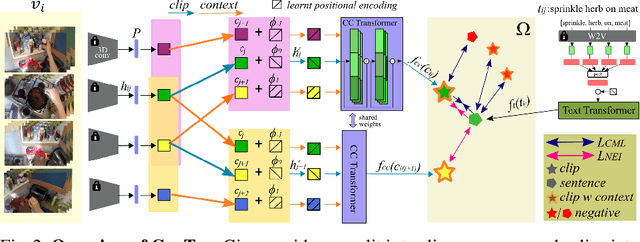
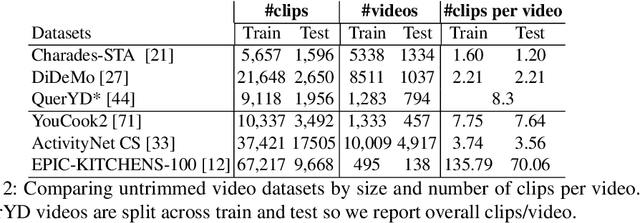
In this paper, we re-examine the task of cross-modal clip-sentence retrieval, where the clip is part of a longer untrimmed video. When the clip is short or visually ambiguous, knowledge of its local temporal context (i.e. surrounding video segments) can be used to improve the retrieval performance. We propose Context Transformer (ConTra); an encoder architecture that models the interaction between a video clip and its local temporal context in order to enhance its embedded representations. Importantly, we supervise the context transformer using contrastive losses in the cross-modal embedding space. We explore context transformers for video and text modalities. Results consistently demonstrate improved performance on three datasets: YouCook2, EPIC-KITCHENS and a clip-sentence version of ActivityNet Captions. Exhaustive ablation studies and context analysis show the efficacy of the proposed method.
EPIC-KITCHENS VISOR Benchmark: VIdeo Segmentations and Object Relations
Sep 26, 2022
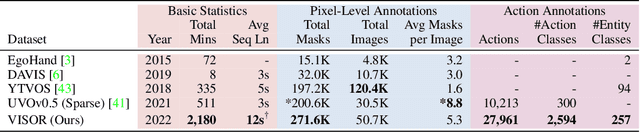
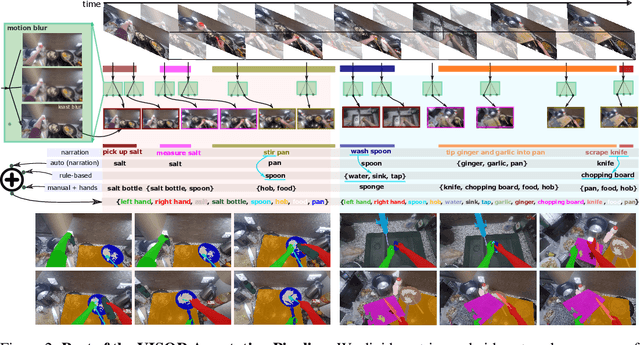
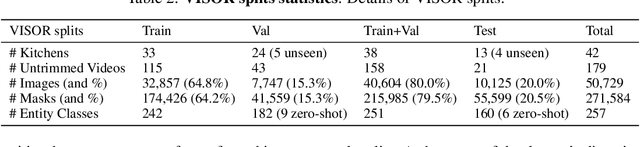
We introduce VISOR, a new dataset of pixel annotations and a benchmark suite for segmenting hands and active objects in egocentric video. VISOR annotates videos from EPIC-KITCHENS, which comes with a new set of challenges not encountered in current video segmentation datasets. Specifically, we need to ensure both short- and long-term consistency of pixel-level annotations as objects undergo transformative interactions, e.g. an onion is peeled, diced and cooked - where we aim to obtain accurate pixel-level annotations of the peel, onion pieces, chopping board, knife, pan, as well as the acting hands. VISOR introduces an annotation pipeline, AI-powered in parts, for scalability and quality. In total, we publicly release 272K manual semantic masks of 257 object classes, 9.9M interpolated dense masks, 67K hand-object relations, covering 36 hours of 179 untrimmed videos. Along with the annotations, we introduce three challenges in video object segmentation, interaction understanding and long-term reasoning. For data, code and leaderboards: http://epic-kitchens.github.io/VISOR
Inertial Hallucinations -- When Wearable Inertial Devices Start Seeing Things
Jul 14, 2022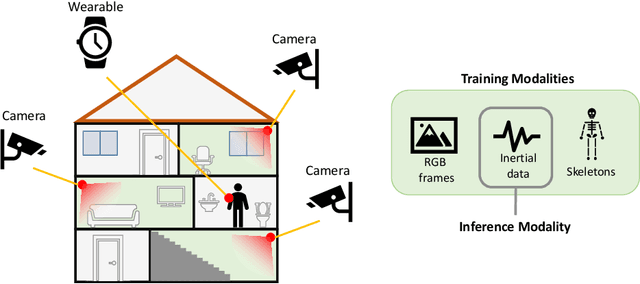

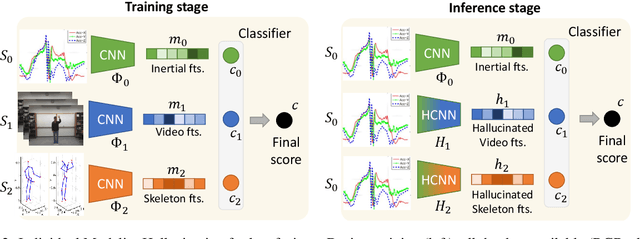
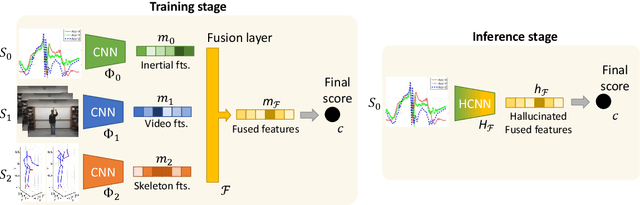
We propose a novel approach to multimodal sensor fusion for Ambient Assisted Living (AAL) which takes advantage of learning using privileged information (LUPI). We address two major shortcomings of standard multimodal approaches, limited area coverage and reduced reliability. Our new framework fuses the concept of modality hallucination with triplet learning to train a model with different modalities to handle missing sensors at inference time. We evaluate the proposed model on inertial data from a wearable accelerometer device, using RGB videos and skeletons as privileged modalities, and show an improvement of accuracy of an average 6.6% on the UTD-MHAD dataset and an average 5.5% on the Berkeley MHAD dataset, reaching a new state-of-the-art for inertial-only classification accuracy on these datasets. We validate our framework through several ablation studies.
Egocentric Video-Language Pretraining @ Ego4D Challenge 2022
Jul 04, 2022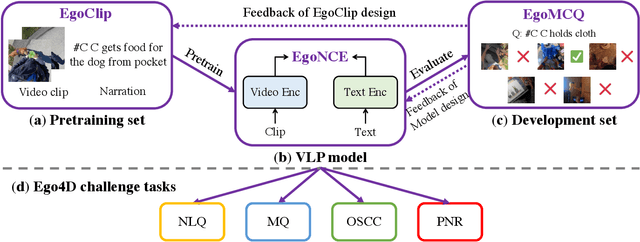
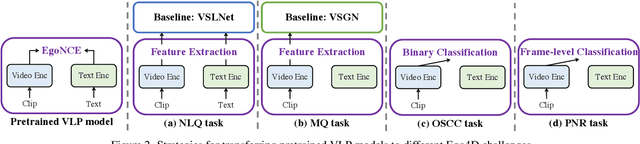
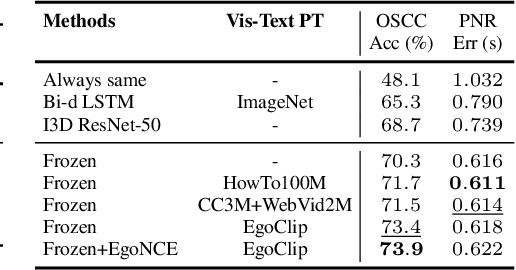
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for four Ego4D challenge tasks, including Natural Language Query (NLQ), Moment Query (MQ), Object State Change Classification (OSCC), and PNR Localization (PNR). Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation or video-only representation to several video downstream tasks. Our Egocentric VLP achieves 10.46R@1&IoU @0.3 on NLQ, 10.33 mAP on MQ, 74% Acc on OSCC, 0.67 sec error on PNR. The code is available at https://github.com/showlab/EgoVLP.
An Evaluation of OCR on Egocentric Data
Jun 11, 2022
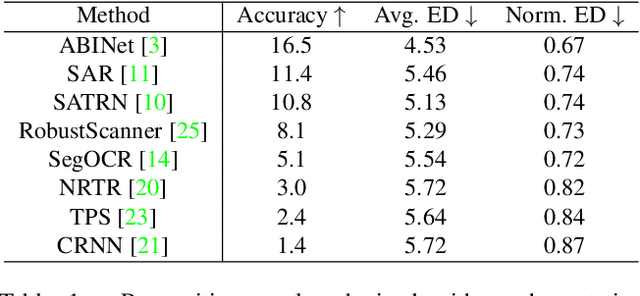
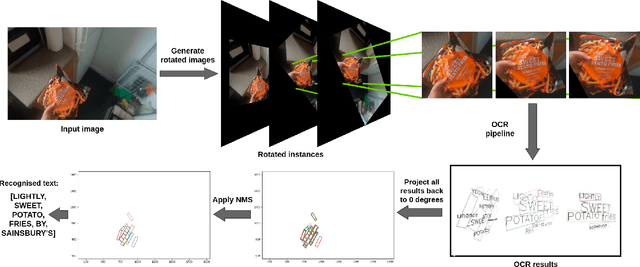
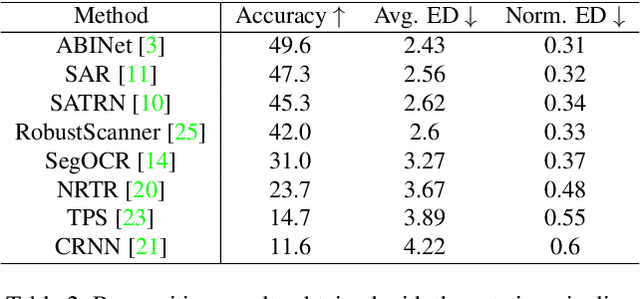
In this paper, we evaluate state-of-the-art OCR methods on Egocentric data. We annotate text in EPIC-KITCHENS images, and demonstrate that existing OCR methods struggle with rotated text, which is frequently observed on objects being handled. We introduce a simple rotate-and-merge procedure which can be applied to pre-trained OCR models that halves the normalized edit distance error. This suggests that future OCR attempts should incorporate rotation into model design and training procedures.
Egocentric Video-Language Pretraining
Jun 03, 2022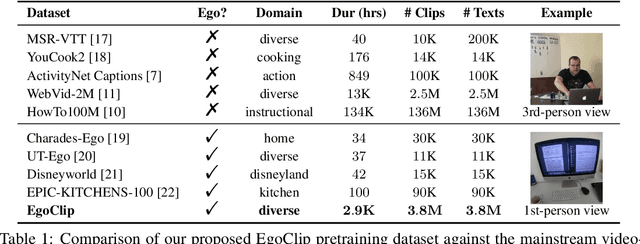
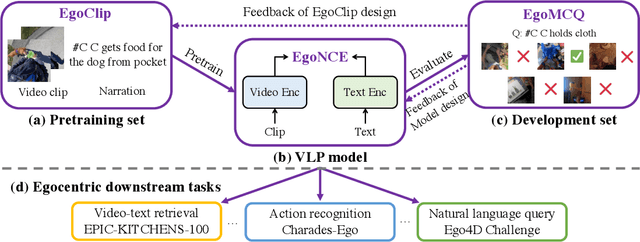

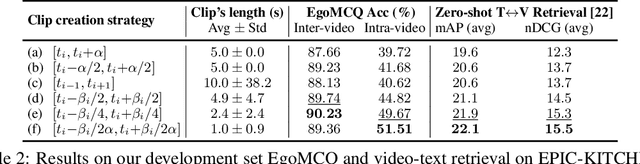
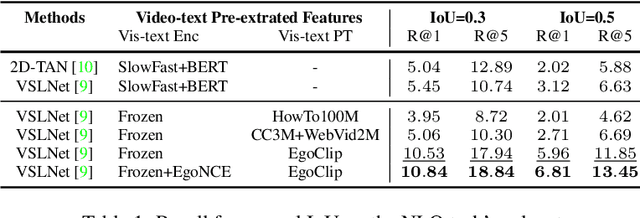
Video-Language Pretraining (VLP), aiming to learn transferable representation to advance a wide range of video-text downstream tasks, has recently received increasing attention. Dominant works that achieve strong performance rely on large-scale, 3rd-person video-text datasets, such as HowTo100M. In this work, we exploit the recently released Ego4D dataset to pioneer Egocentric VLP along three directions. (i) We create EgoClip, a 1st-person video-text pretraining dataset comprising 3.8M clip-text pairs well-chosen from Ego4D, covering a large variety of human daily activities. (ii) We propose a novel pretraining objective, dubbed as EgoNCE, which adapts video-text contrastive learning to egocentric domain by mining egocentric-aware positive and negative samples. (iii) We introduce EgoMCQ, a development benchmark that is close to EgoClip and hence can support effective validation and fast exploration of our design decisions regarding EgoClip and EgoNCE. Furthermore, we demonstrate strong performance on five egocentric downstream tasks across three datasets: video-text retrieval on EPIC-KITCHENS-100; action recognition on Charades-Ego; and natural language query, moment query, and object state change classification on Ego4D challenge benchmarks. The dataset and code will be available at https://github.com/showlab/EgoVLP.
Temporal Progressive Attention for Early Action Prediction
Apr 28, 2022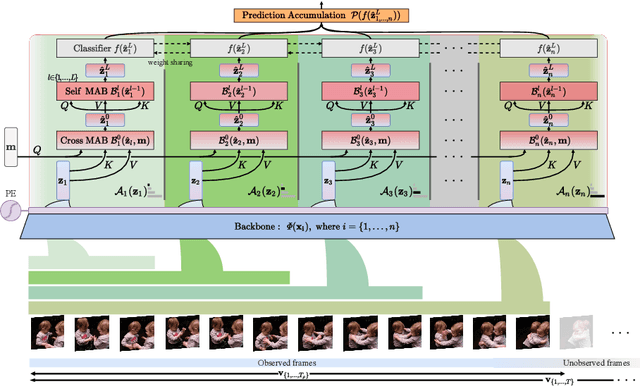
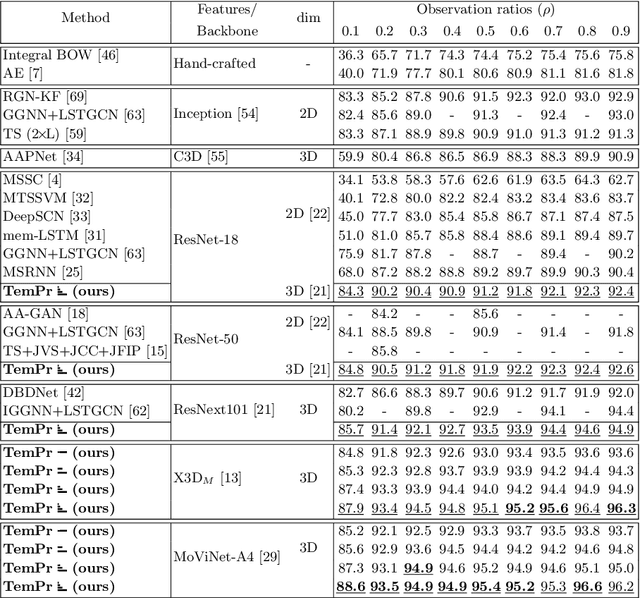
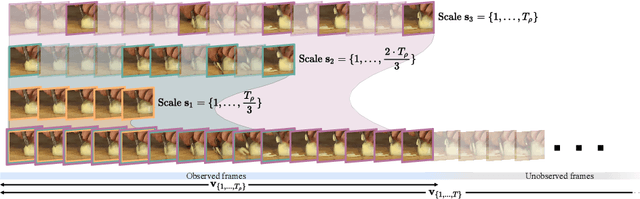
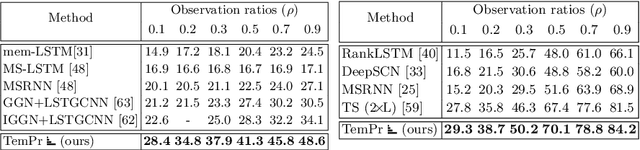
Early action prediction deals with inferring the ongoing action from partially-observed videos, typically at the outset of the video. We propose a bottleneck-based attention model that captures the evolution of the action, through progressive sampling over fine-to-coarse scales. Our proposed Temporal Progressive (TemPr) model is composed of multiple attention towers, one for each scale. The predicted action label is based on the collective agreement considering confidences of these attention towers. Extensive experiments over three video datasets showcase state-of-the-art performance on the task of Early Action Prediction across a range of backbone architectures. We demonstrate the effectiveness and consistency of TemPr through detailed ablations.
Dual-Domain Image Synthesis using Segmentation-Guided GAN
Apr 19, 2022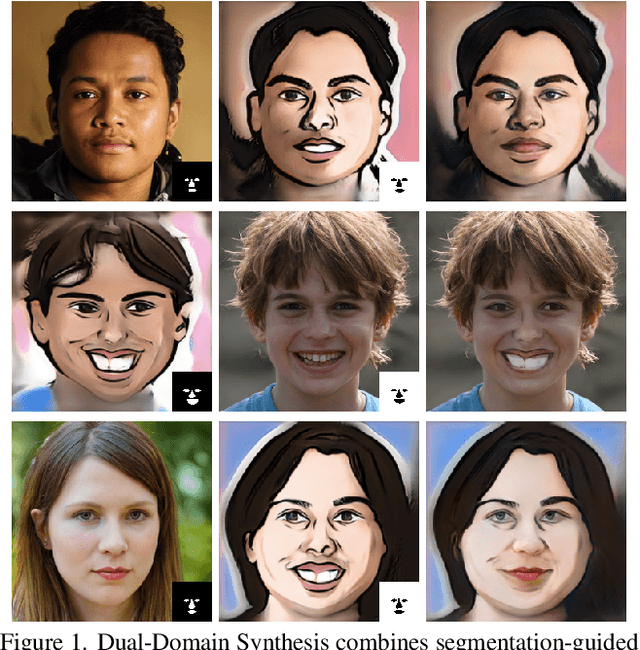
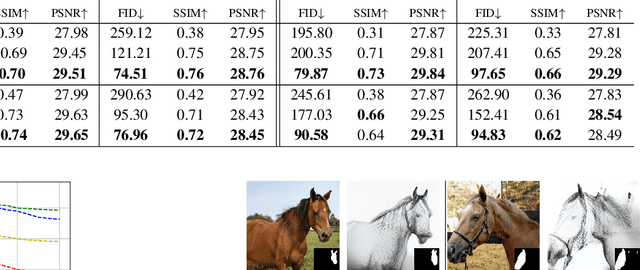
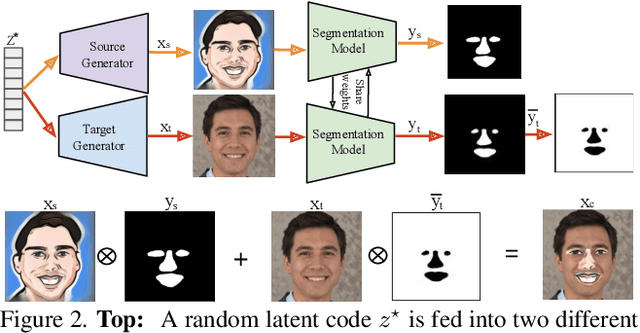
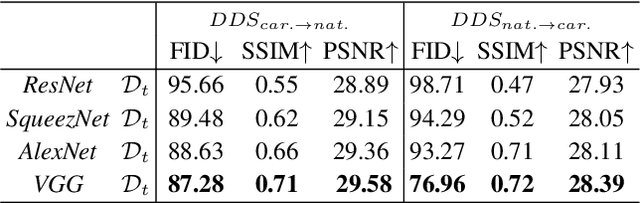
We introduce a segmentation-guided approach to synthesise images that integrate features from two distinct domains. Images synthesised by our dual-domain model belong to one domain within the semantic mask, and to another in the rest of the image - smoothly integrated. We build on the successes of few-shot StyleGAN and single-shot semantic segmentation to minimise the amount of training required in utilising two domains. The method combines a few-shot cross-domain StyleGAN with a latent optimiser to achieve images containing features of two distinct domains. We use a segmentation-guided perceptual loss, which compares both pixel-level and activations between domain-specific and dual-domain synthetic images. Results demonstrate qualitatively and quantitatively that our model is capable of synthesising dual-domain images on a variety of objects (faces, horses, cats, cars), domains (natural, caricature, sketches) and part-based masks (eyes, nose, mouth, hair, car bonnet). The code is publicly available at: https://github.com/denabazazian/Dual-Domain-Synthesis.
Hand-Object Interaction Reasoning
Jan 13, 2022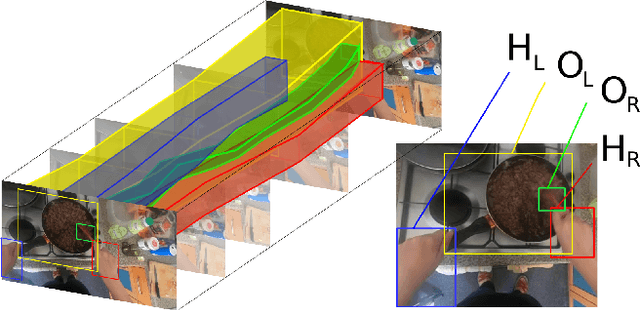
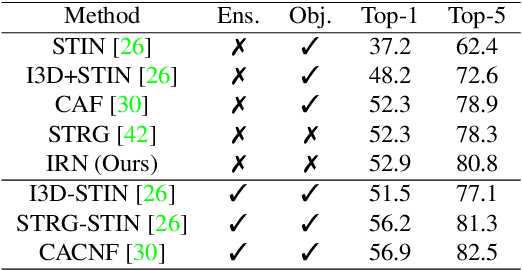
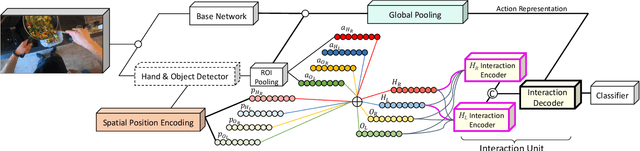

This paper proposes an interaction reasoning network for modelling spatio-temporal relationships between hands and objects in video. The proposed interaction unit utilises a Transformer module to reason about each acting hand, and its spatio-temporal relation to the other hand as well as objects being interacted with. We show that modelling two-handed interactions are critical for action recognition in egocentric video, and demonstrate that by using positionally-encoded trajectories, the network can better recognise observed interactions. We evaluate our proposal on EPIC-KITCHENS and Something-Else datasets, with an ablation study.