 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake-A-Video: Text-to-Video Generation without Text-Video Data
Sep 29, 2022

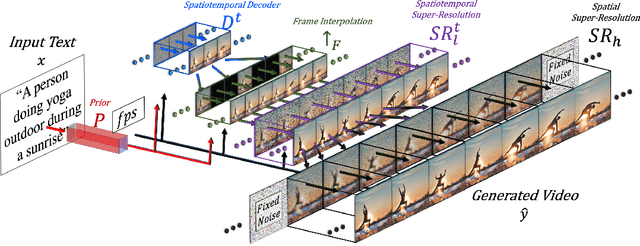
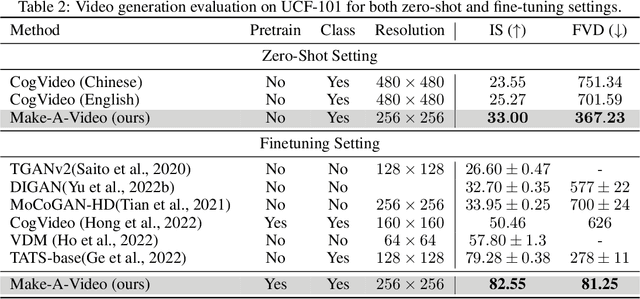
We propose Make-A-Video -- an approach for directly translating the tremendous recent progress in Text-to-Image (T2I) generation to Text-to-Video (T2V). Our intuition is simple: learn what the world looks like and how it is described from paired text-image data, and learn how the world moves from unsupervised video footage. Make-A-Video has three advantages: (1) it accelerates training of the T2V model (it does not need to learn visual and multimodal representations from scratch), (2) it does not require paired text-video data, and (3) the generated videos inherit the vastness (diversity in aesthetic, fantastical depictions, etc.) of today's image generation models. We design a simple yet effective way to build on T2I models with novel and effective spatial-temporal modules. First, we decompose the full temporal U-Net and attention tensors and approximate them in space and time. Second, we design a spatial temporal pipeline to generate high resolution and frame rate videos with a video decoder, interpolation model and two super resolution models that can enable various applications besides T2V. In all aspects, spatial and temporal resolution, faithfulness to text, and quality, Make-A-Video sets the new state-of-the-art in text-to-video generation, as determined by both qualitative and quantitative measures.
Episodic Memory Question Answering
May 03, 2022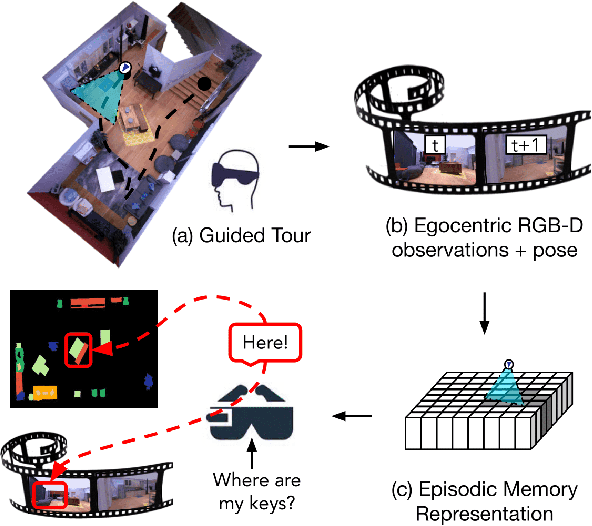
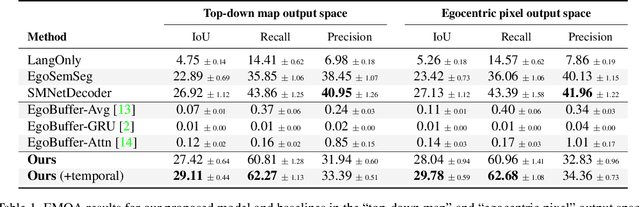
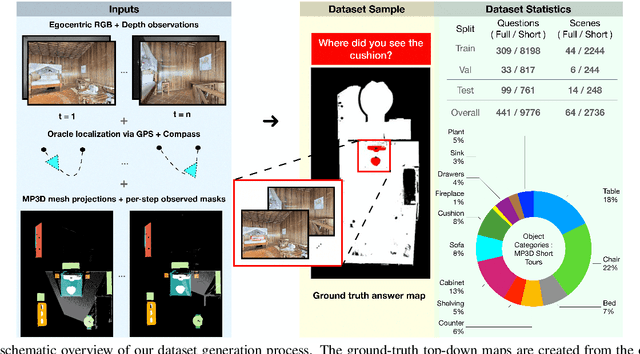
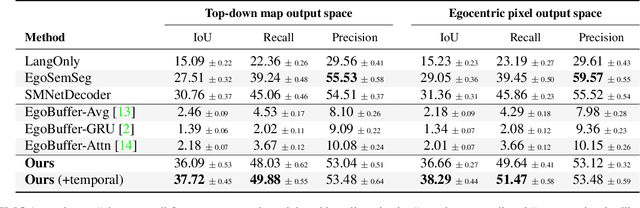
Egocentric augmented reality devices such as wearable glasses passively capture visual data as a human wearer tours a home environment. We envision a scenario wherein the human communicates with an AI agent powering such a device by asking questions (e.g., where did you last see my keys?). In order to succeed at this task, the egocentric AI assistant must (1) construct semantically rich and efficient scene memories that encode spatio-temporal information about objects seen during the tour and (2) possess the ability to understand the question and ground its answer into the semantic memory representation. Towards that end, we introduce (1) a new task - Episodic Memory Question Answering (EMQA) wherein an egocentric AI assistant is provided with a video sequence (the tour) and a question as an input and is asked to localize its answer to the question within the tour, (2) a dataset of grounded questions designed to probe the agent's spatio-temporal understanding of the tour, and (3) a model for the task that encodes the scene as an allocentric, top-down semantic feature map and grounds the question into the map to localize the answer. We show that our choice of episodic scene memory outperforms naive, off-the-shelf solutions for the task as well as a host of very competitive baselines and is robust to noise in depth, pose as well as camera jitter. The project page can be found at: https://samyak-268.github.io/emqa .
MUGEN: A Playground for Video-Audio-Text Multimodal Understanding and GENeration
Apr 28, 2022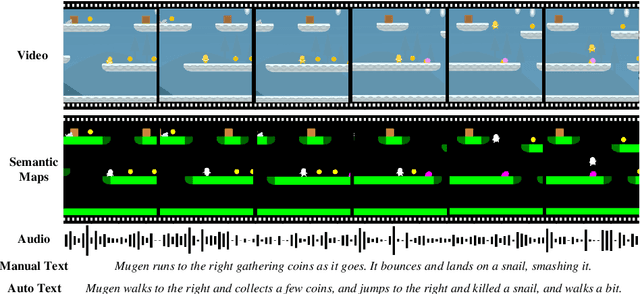
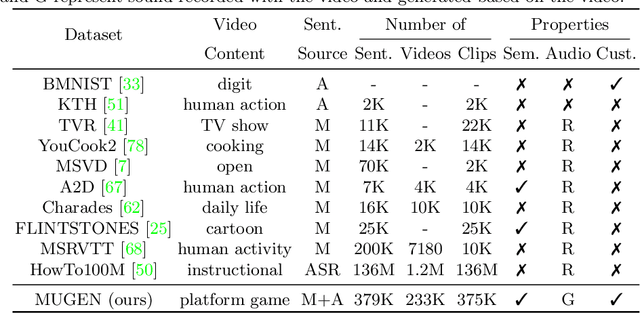
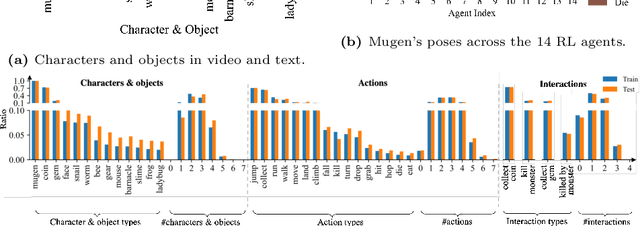

Multimodal video-audio-text understanding and generation can benefit from datasets that are narrow but rich. The narrowness allows bite-sized challenges that the research community can make progress on. The richness ensures we are making progress along the core challenges. To this end, we present a large-scale video-audio-text dataset MUGEN, collected using the open-sourced platform game CoinRun [11]. We made substantial modifications to make the game richer by introducing audio and enabling new interactions. We trained RL agents with different objectives to navigate the game and interact with 13 objects and characters. This allows us to automatically extract a large collection of diverse videos and associated audio. We sample 375K video clips (3.2s each) and collect text descriptions from human annotators. Each video has additional annotations that are extracted automatically from the game engine, such as accurate semantic maps for each frame and templated textual descriptions. Altogether, MUGEN can help progress research in many tasks in multimodal understanding and generation. We benchmark representative approaches on tasks involving video-audio-text retrieval and generation. Our dataset and code are released at: https://mugen-org.github.io/.
Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
Apr 07, 2022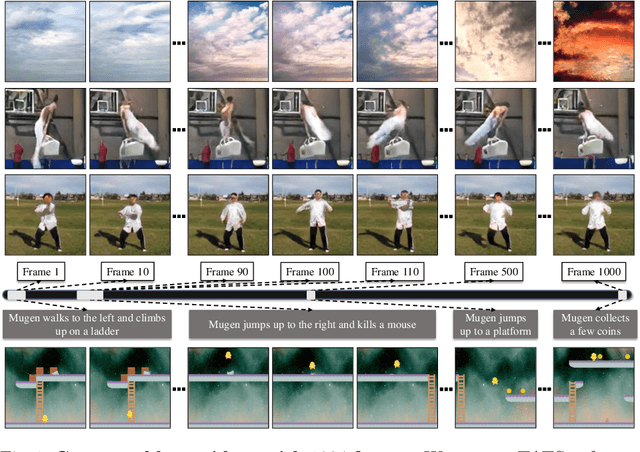
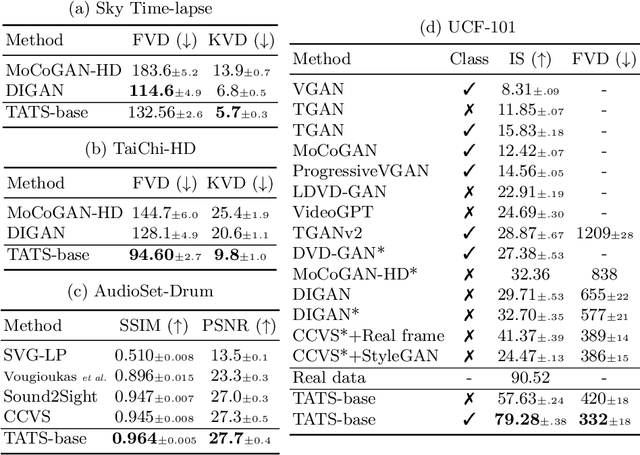

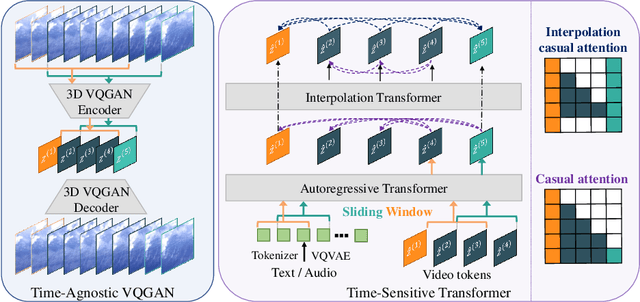
Videos are created to express emotion, exchange information, and share experiences. Video synthesis has intrigued researchers for a long time. Despite the rapid progress driven by advances in visual synthesis, most existing studies focus on improving the frames' quality and the transitions between them, while little progress has been made in generating longer videos. In this paper, we present a method that builds on 3D-VQGAN and transformers to generate videos with thousands of frames. Our evaluation shows that our model trained on 16-frame video clips from standard benchmarks such as UCF-101, Sky Time-lapse, and Taichi-HD datasets can generate diverse, coherent, and high-quality long videos. We also showcase conditional extensions of our approach for generating meaningful long videos by incorporating temporal information with text and audio. Videos and code can be found at https://songweige.github.io/projects/tats/index.html.
Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Mar 24, 2022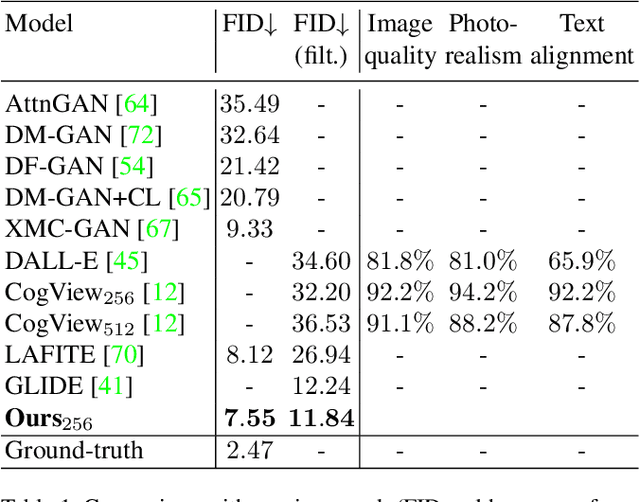

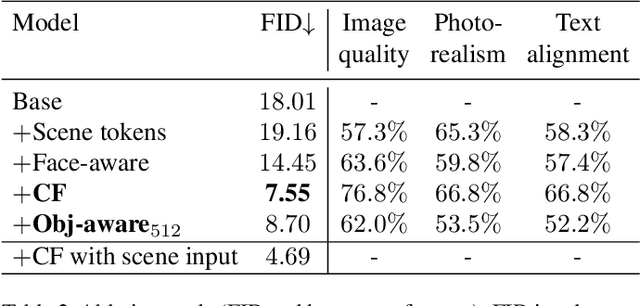

Recent text-to-image generation methods provide a simple yet exciting conversion capability between text and image domains. While these methods have incrementally improved the generated image fidelity and text relevancy, several pivotal gaps remain unanswered, limiting applicability and quality. We propose a novel text-to-image method that addresses these gaps by (i) enabling a simple control mechanism complementary to text in the form of a scene, (ii) introducing elements that substantially improve the tokenization process by employing domain-specific knowledge over key image regions (faces and salient objects), and (iii) adapting classifier-free guidance for the transformer use case. Our model achieves state-of-the-art FID and human evaluation results, unlocking the ability to generate high fidelity images in a resolution of 512x512 pixels, significantly improving visual quality. Through scene controllability, we introduce several new capabilities: (i) Scene editing, (ii) text editing with anchor scenes, (iii) overcoming out-of-distribution text prompts, and (iv) story illustration generation, as demonstrated in the story we wrote.
Telling Creative Stories Using Generative Visual Aids
Oct 27, 2021

Can visual artworks created using generative visual algorithms inspire human creativity in storytelling? We asked writers to write creative stories from a starting prompt, and provided them with visuals created by generative AI models from the same prompt. Compared to a control group, writers who used the visuals as story writing aid wrote significantly more creative, original, complete and visualizable stories, and found the task more fun. Of the generative algorithms used (BigGAN, VQGAN, DALL-E, CLIPDraw), VQGAN was the most preferred. The control group that did not view the visuals did significantly better in integrating the starting prompts. Findings indicate that cross modality inputs by AI can benefit divergent aspects of creativity in human-AI co-creation, but hinders convergent thinking.
Dance2Music: Automatic Dance-driven Music Generation
Jul 20, 2021
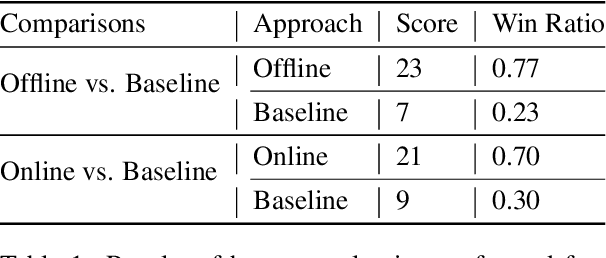

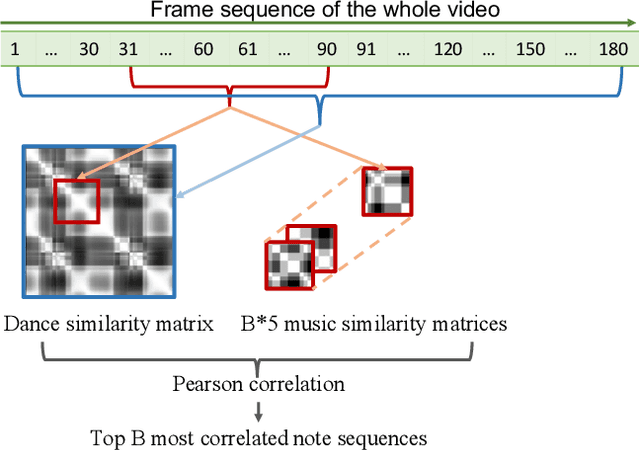
Dance and music typically go hand in hand. The complexities in dance, music, and their synchronisation make them fascinating to study from a computational creativity perspective. While several works have looked at generating dance for a given music, automatically generating music for a given dance remains under-explored. This capability could have several creative expression and entertainment applications. We present some early explorations in this direction. We present a search-based offline approach that generates music after processing the entire dance video and an online approach that uses a deep neural network to generate music on-the-fly as the video proceeds. We compare these approaches to a strong heuristic baseline via human studies and present our findings. We have integrated our online approach in a live demo! A video of the demo can be found here: https://sites.google.com/view/dance2music/live-demo.
Visual Conceptual Blending with Large-scale Language and Vision Models
Jun 27, 2021

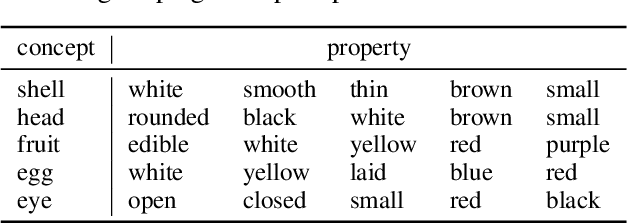

We ask the question: to what extent can recent large-scale language and image generation models blend visual concepts? Given an arbitrary object, we identify a relevant object and generate a single-sentence description of the blend of the two using a language model. We then generate a visual depiction of the blend using a text-based image generation model. Quantitative and qualitative evaluations demonstrate the superiority of language models over classical methods for conceptual blending, and of recent large-scale image generation models over prior models for the visual depiction.
Building Bridges: Generative Artworks to Explore AI Ethics
Jun 25, 2021
In recent years, there has been an increased emphasis on understanding and mitigating adverse impacts of artificial intelligence (AI) technologies on society. Across academia, industry, and government bodies, a variety of endeavours are being pursued towards enhancing AI ethics. A significant challenge in the design of ethical AI systems is that there are multiple stakeholders in the AI pipeline, each with their own set of constraints and interests. These different perspectives are often not understood, due in part to communication gaps.For example, AI researchers who design and develop AI models are not necessarily aware of the instability induced in consumers' lives by the compounded effects of AI decisions. Educating different stakeholders about their roles and responsibilities in the broader context becomes necessary. In this position paper, we outline some potential ways in which generative artworks can play this role by serving as accessible and powerful educational tools for surfacing different perspectives. We hope to spark interdisciplinary discussions about computational creativity broadly as a tool for enhancing AI ethics.
Human-Adversarial Visual Question Answering
Jun 04, 2021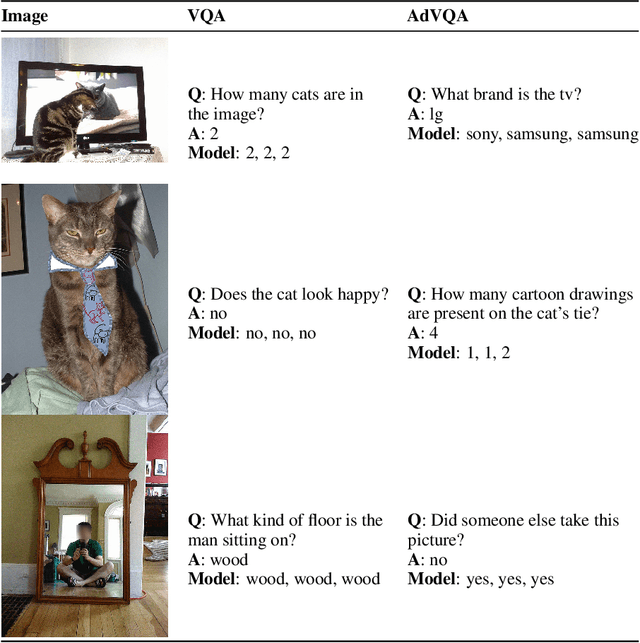
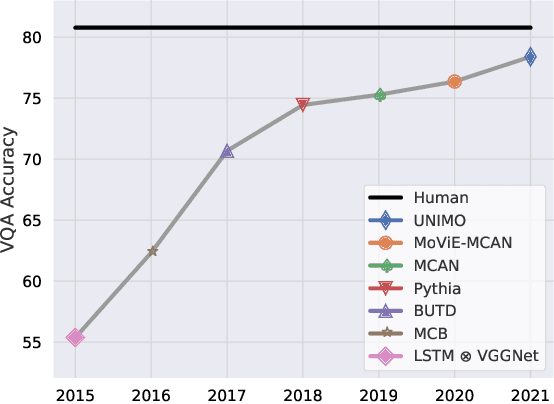
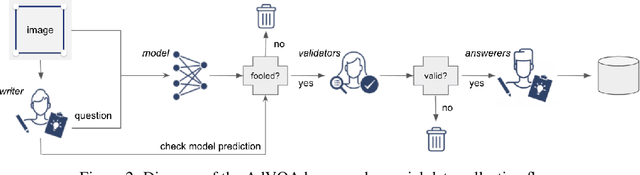

Performance on the most commonly used Visual Question Answering dataset (VQA v2) is starting to approach human accuracy. However, in interacting with state-of-the-art VQA models, it is clear that the problem is far from being solved. In order to stress test VQA models, we benchmark them against human-adversarial examples. Human subjects interact with a state-of-the-art VQA model, and for each image in the dataset, attempt to find a question where the model's predicted answer is incorrect. We find that a wide range of state-of-the-art models perform poorly when evaluated on these examples. We conduct an extensive analysis of the collected adversarial examples and provide guidance on future research directions. We hope that this Adversarial VQA (AdVQA) benchmark can help drive progress in the field and advance the state of the art.