 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
May 15, 2017
Problems at the intersection of vision and language are of significant importance both as challenging research questions and for the rich set of applications they enable. However, inherent structure in our world and bias in our language tend to be a simpler signal for learning than visual modalities, resulting in models that ignore visual information, leading to an inflated sense of their capability. We propose to counter these language priors for the task of Visual Question Answering (VQA) and make vision (the V in VQA) matter! Specifically, we balance the popular VQA dataset by collecting complementary images such that every question in our balanced dataset is associated with not just a single image, but rather a pair of similar images that result in two different answers to the question. Our dataset is by construction more balanced than the original VQA dataset and has approximately twice the number of image-question pairs. Our complete balanced dataset is publicly available at www.visualqa.org as part of the 2nd iteration of the Visual Question Answering Dataset and Challenge (VQA v2.0). We further benchmark a number of state-of-art VQA models on our balanced dataset. All models perform significantly worse on our balanced dataset, suggesting that these models have indeed learned to exploit language priors. This finding provides the first concrete empirical evidence for what seems to be a qualitative sense among practitioners. Finally, our data collection protocol for identifying complementary images enables us to develop a novel interpretable model, which in addition to providing an answer to the given (image, question) pair, also provides a counter-example based explanation. Specifically, it identifies an image that is similar to the original image, but it believes has a different answer to the same question. This can help in building trust for machines among their users.
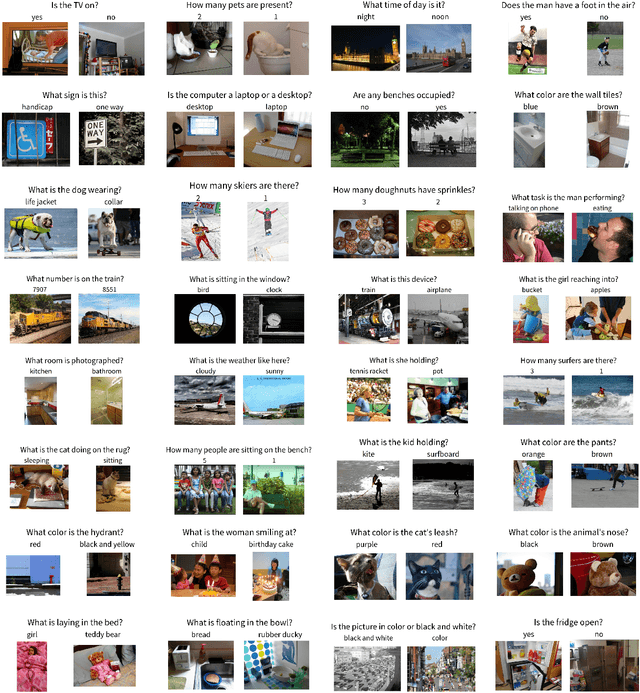
Counting Everyday Objects in Everyday Scenes
May 09, 2017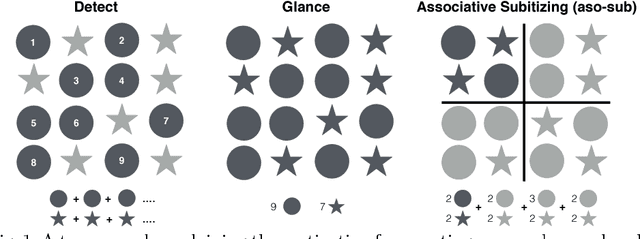
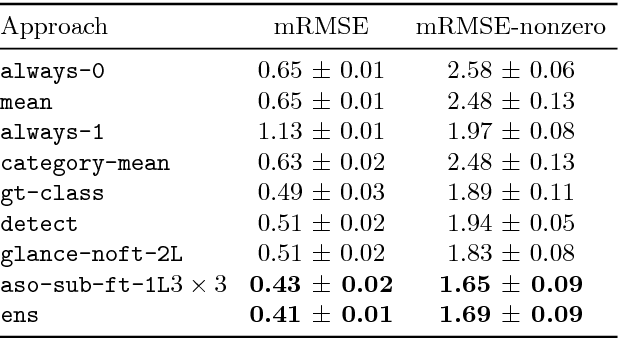
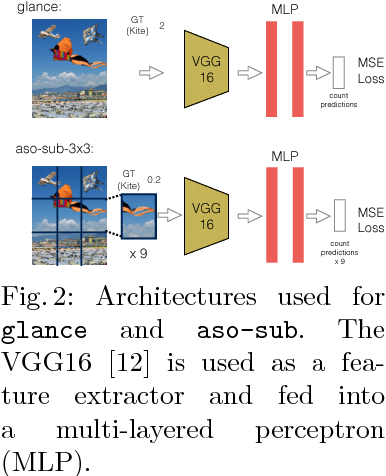
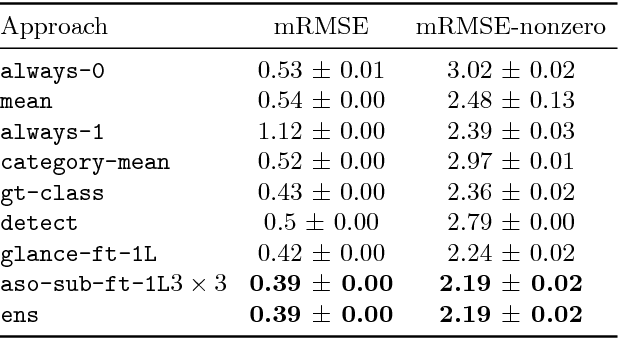
We are interested in counting the number of instances of object classes in natural, everyday images. Previous counting approaches tackle the problem in restricted domains such as counting pedestrians in surveillance videos. Counts can also be estimated from outputs of other vision tasks like object detection. In this work, we build dedicated models for counting designed to tackle the large variance in counts, appearances, and scales of objects found in natural scenes. Our approach is inspired by the phenomenon of subitizing - the ability of humans to make quick assessments of counts given a perceptual signal, for small count values. Given a natural scene, we employ a divide and conquer strategy while incorporating context across the scene to adapt the subitizing idea to counting. Our approach offers consistent improvements over numerous baseline approaches for counting on the PASCAL VOC 2007 and COCO datasets. Subsequently, we study how counting can be used to improve object detection. We then show a proof of concept application of our counting methods to the task of Visual Question Answering, by studying the `how many?' questions in the VQA and COCO-QA datasets.
C-VQA: A Compositional Split of the Visual Question Answering v1.0 Dataset
Apr 26, 2017
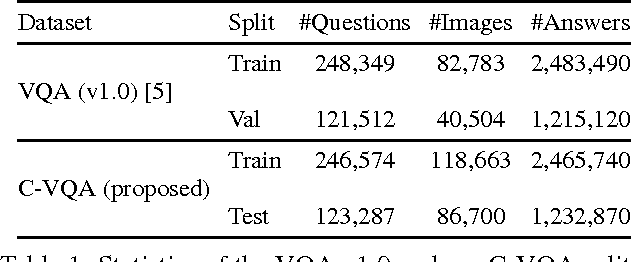
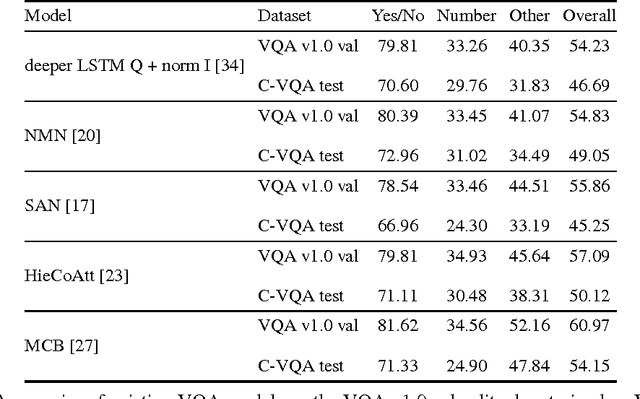
Visual Question Answering (VQA) has received a lot of attention over the past couple of years. A number of deep learning models have been proposed for this task. However, it has been shown that these models are heavily driven by superficial correlations in the training data and lack compositionality -- the ability to answer questions about unseen compositions of seen concepts. This compositionality is desirable and central to intelligence. In this paper, we propose a new setting for Visual Question Answering where the test question-answer pairs are compositionally novel compared to training question-answer pairs. To facilitate developing models under this setting, we present a new compositional split of the VQA v1.0 dataset, which we call Compositional VQA (C-VQA). We analyze the distribution of questions and answers in the C-VQA splits. Finally, we evaluate several existing VQA models under this new setting and show that the performances of these models degrade by a significant amount compared to the original VQA setting.
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Mar 21, 2017
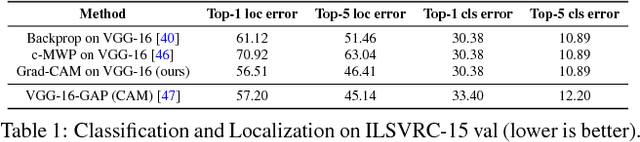
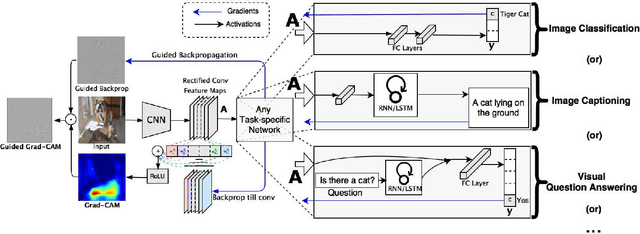
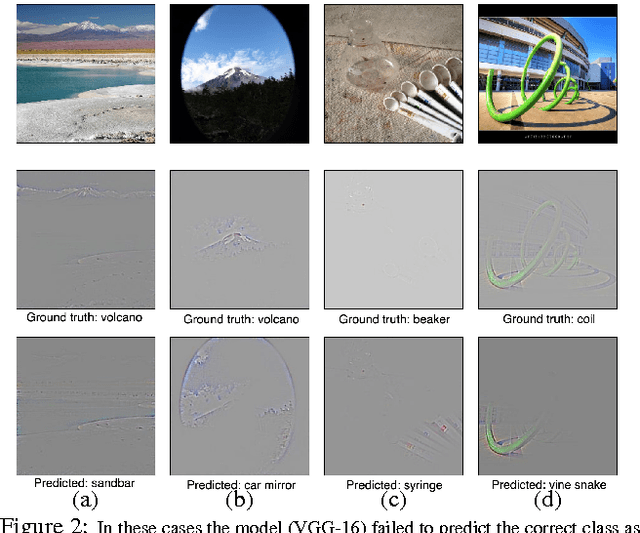
We propose a technique for producing "visual explanations" for decisions from a large class of CNN-based models, making them more transparent. Our approach - Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept, flowing into the final convolutional layer to produce a coarse localization map highlighting the important regions in the image for predicting the concept. Unlike previous approaches, GradCAM is applicable to a wide variety of CNN model-families: (1) CNNs with fully-connected layers (e.g. VGG), (2) CNNs used for structured outputs (e.g. captioning), (3) CNNs used in tasks with multimodal inputs (e.g. VQA) or reinforcement learning, without any architectural changes or re-training. We combine GradCAM with fine-grained visualizations to create a high-resolution class-discriminative visualization and apply it to off-the-shelf image classification, captioning, and visual question answering (VQA) models, including ResNet-based architectures. In the context of image classification models, our visualizations (a) lend insights into their failure modes (showing that seemingly unreasonable predictions have reasonable explanations), (b) are robust to adversarial images, (c) outperform previous methods on weakly-supervised localization, (d) are more faithful to the underlying model and (e) help achieve generalization by identifying dataset bias. For captioning and VQA, our visualizations show that even non-attention based models can localize inputs. Finally, we conduct human studies to measure if GradCAM explanations help users establish trust in predictions from deep networks and show that GradCAM helps untrained users successfully discern a "stronger" deep network from a "weaker" one. Our code is available at https://github.com/ramprs/grad-cam. A demo and a video of the demo can be found at http://gradcam.cloudcv.org and youtu.be/COjUB9Izk6E.
Grad-CAM: Why did you say that?
Jan 25, 2017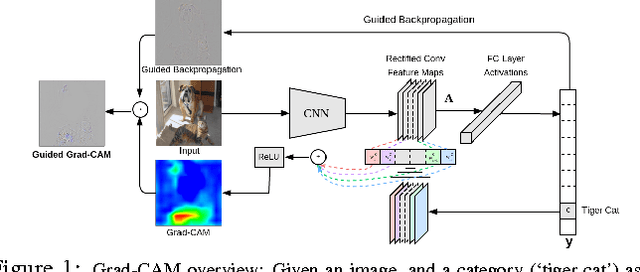
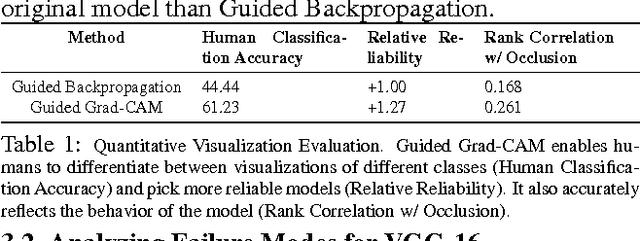
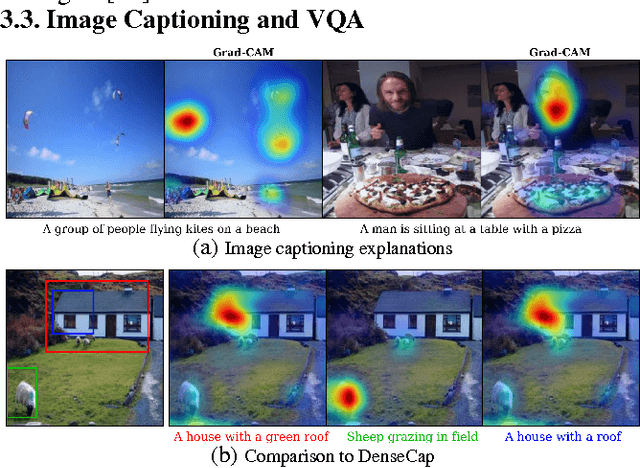
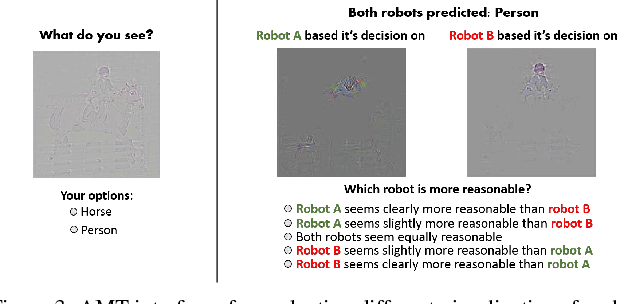
We propose a technique for making Convolutional Neural Network (CNN)-based models more transparent by visualizing input regions that are 'important' for predictions -- or visual explanations. Our approach, called Gradient-weighted Class Activation Mapping (Grad-CAM), uses class-specific gradient information to localize important regions. These localizations are combined with existing pixel-space visualizations to create a novel high-resolution and class-discriminative visualization called Guided Grad-CAM. These methods help better understand CNN-based models, including image captioning and visual question answering (VQA) models. We evaluate our visual explanations by measuring their ability to discriminate between classes, to inspire trust in humans, and their correlation with occlusion maps. Grad-CAM provides a new way to understand CNN-based models. We have released code, an online demo hosted on CloudCV, and a full version of this extended abstract.
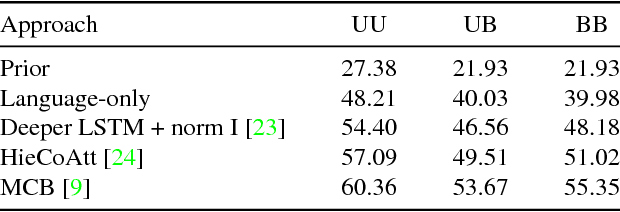
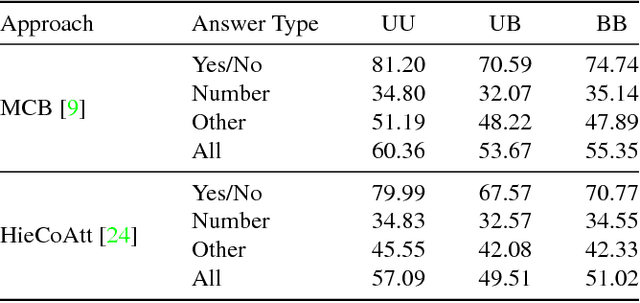
Hierarchical Question-Image Co-Attention for Visual Question Answering
Jan 19, 2017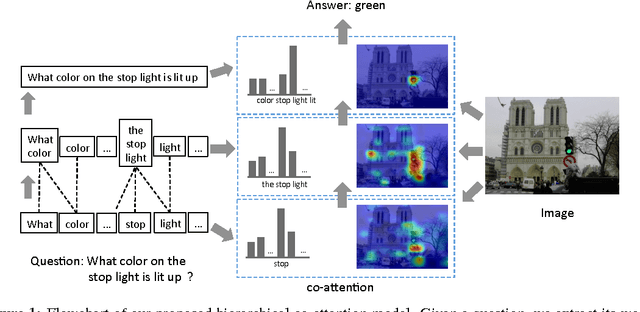
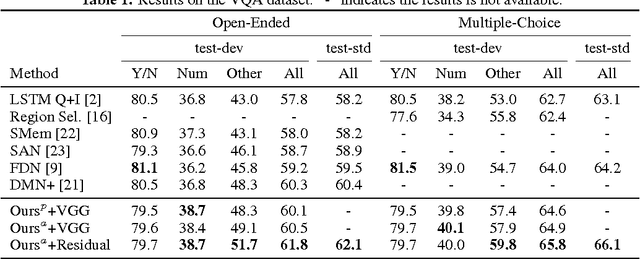
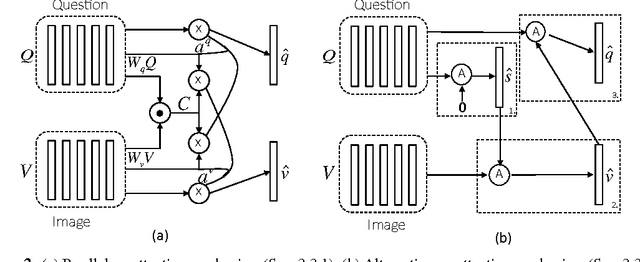
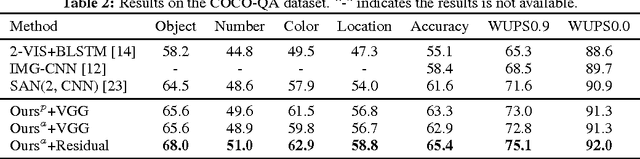
A number of recent works have proposed attention models for Visual Question Answering (VQA) that generate spatial maps highlighting image regions relevant to answering the question. In this paper, we argue that in addition to modeling "where to look" or visual attention, it is equally important to model "what words to listen to" or question attention. We present a novel co-attention model for VQA that jointly reasons about image and question attention. In addition, our model reasons about the question (and consequently the image via the co-attention mechanism) in a hierarchical fashion via a novel 1-dimensional convolution neural networks (CNN). Our model improves the state-of-the-art on the VQA dataset from 60.3% to 60.5%, and from 61.6% to 63.3% on the COCO-QA dataset. By using ResNet, the performance is further improved to 62.1% for VQA and 65.4% for COCO-QA.
Sort Story: Sorting Jumbled Images and Captions into Stories
Nov 07, 2016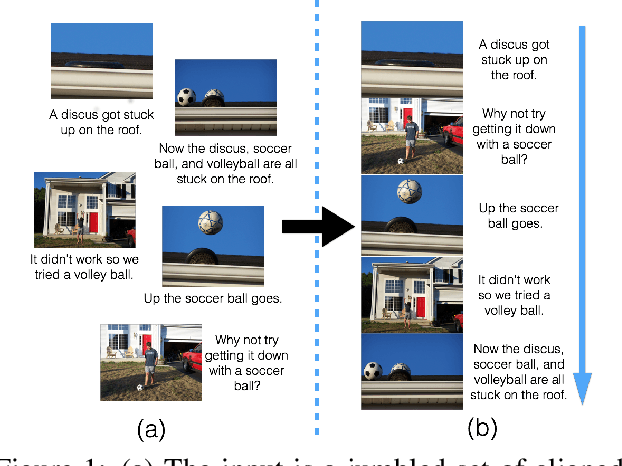
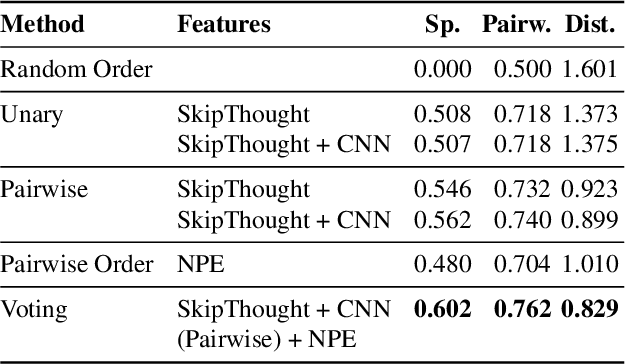
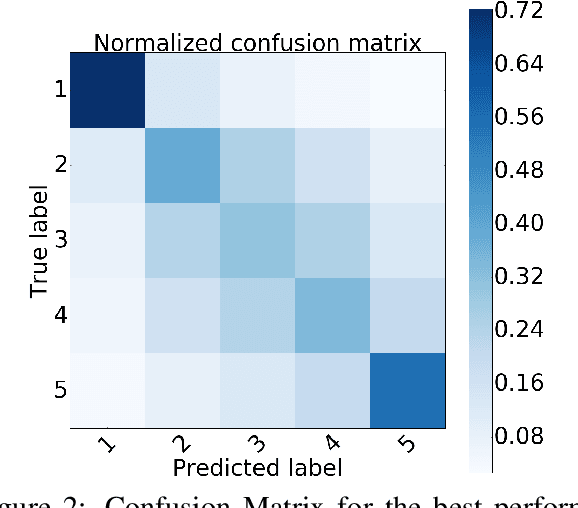

Temporal common sense has applications in AI tasks such as QA, multi-document summarization, and human-AI communication. We propose the task of sequencing -- given a jumbled set of aligned image-caption pairs that belong to a story, the task is to sort them such that the output sequence forms a coherent story. We present multiple approaches, via unary (position) and pairwise (order) predictions, and their ensemble-based combinations, achieving strong results on this task. We use both text-based and image-based features, which depict complementary improvements. Using qualitative examples, we demonstrate that our models have learnt interesting aspects of temporal common sense.
VQA: Visual Question Answering
Oct 27, 2016

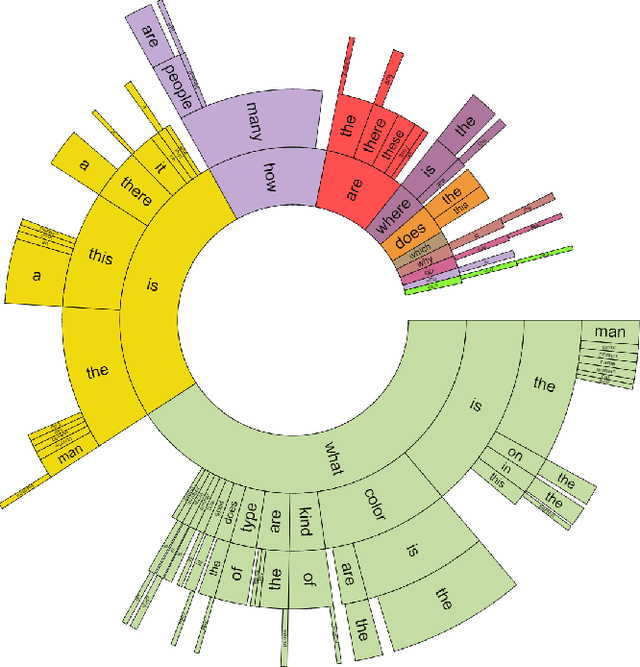
We propose the task of free-form and open-ended Visual Question Answering (VQA). Given an image and a natural language question about the image, the task is to provide an accurate natural language answer. Mirroring real-world scenarios, such as helping the visually impaired, both the questions and answers are open-ended. Visual questions selectively target different areas of an image, including background details and underlying context. As a result, a system that succeeds at VQA typically needs a more detailed understanding of the image and complex reasoning than a system producing generic image captions. Moreover, VQA is amenable to automatic evaluation, since many open-ended answers contain only a few words or a closed set of answers that can be provided in a multiple-choice format. We provide a dataset containing ~0.25M images, ~0.76M questions, and ~10M answers (www.visualqa.org), and discuss the information it provides. Numerous baselines and methods for VQA are provided and compared with human performance. Our VQA demo is available on CloudCV (http://cloudcv.org/vqa).
Analyzing the Behavior of Visual Question Answering Models
Sep 27, 2016
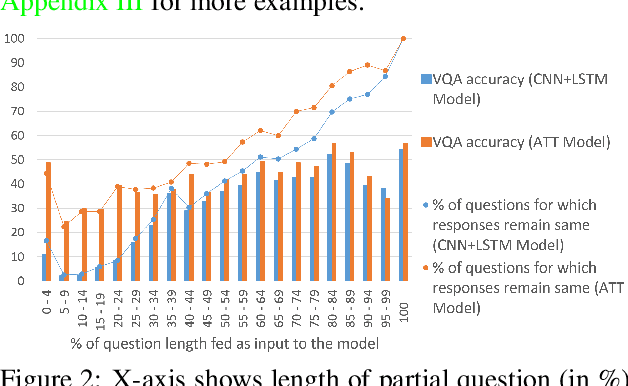

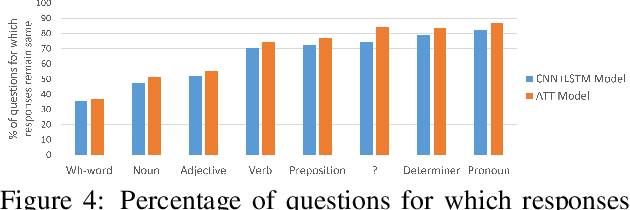
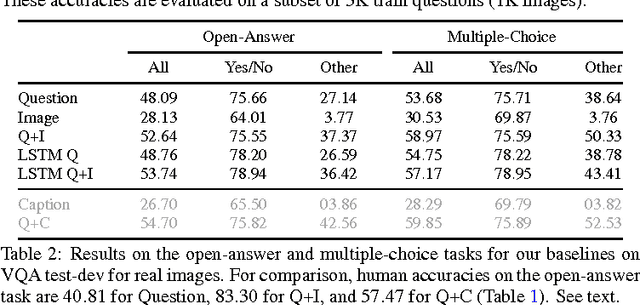
Recently, a number of deep-learning based models have been proposed for the task of Visual Question Answering (VQA). The performance of most models is clustered around 60-70%. In this paper we propose systematic methods to analyze the behavior of these models as a first step towards recognizing their strengths and weaknesses, and identifying the most fruitful directions for progress. We analyze two models, one each from two major classes of VQA models -- with-attention and without-attention and show the similarities and differences in the behavior of these models. We also analyze the winning entry of the VQA Challenge 2016. Our behavior analysis reveals that despite recent progress, today's VQA models are "myopic" (tend to fail on sufficiently novel instances), often "jump to conclusions" (converge on a predicted answer after 'listening' to just half the question), and are "stubborn" (do not change their answers across images).
Question Relevance in VQA: Identifying Non-Visual And False-Premise Questions
Sep 26, 2016


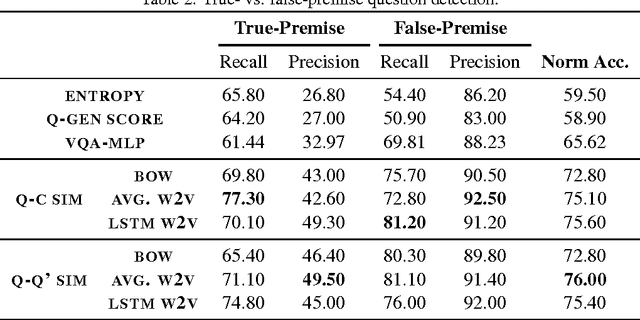
Visual Question Answering (VQA) is the task of answering natural-language questions about images. We introduce the novel problem of determining the relevance of questions to images in VQA. Current VQA models do not reason about whether a question is even related to the given image (e.g. What is the capital of Argentina?) or if it requires information from external resources to answer correctly. This can break the continuity of a dialogue in human-machine interaction. Our approaches for determining relevance are composed of two stages. Given an image and a question, (1) we first determine whether the question is visual or not, (2) if visual, we determine whether the question is relevant to the given image or not. Our approaches, based on LSTM-RNNs, VQA model uncertainty, and caption-question similarity, are able to outperform strong baselines on both relevance tasks. We also present human studies showing that VQA models augmented with such question relevance reasoning are perceived as more intelligent, reasonable, and human-like.