 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest of Both Worlds: Transferring Knowledge from Discriminative Learning to a Generative Visual Dialog Model
Oct 27, 2017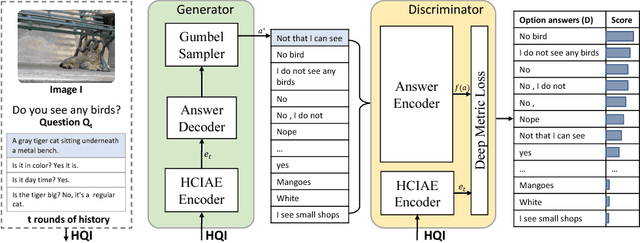
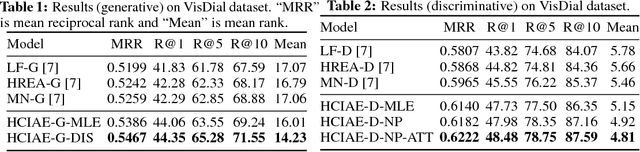
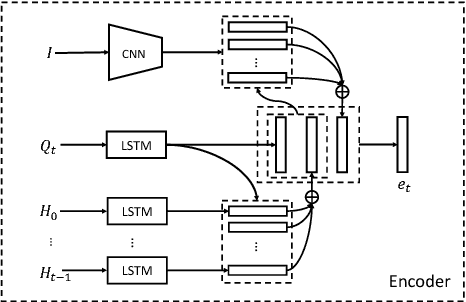
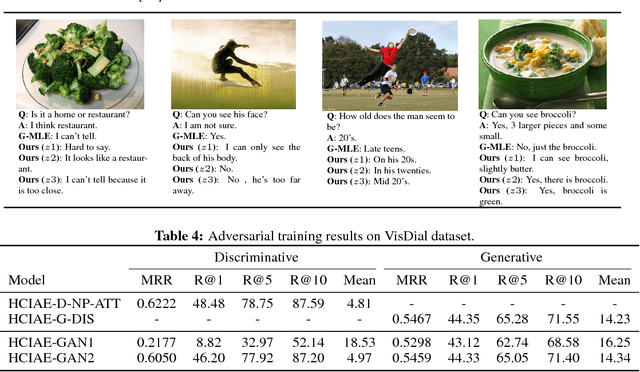
We present a novel training framework for neural sequence models, particularly for grounded dialog generation. The standard training paradigm for these models is maximum likelihood estimation (MLE), or minimizing the cross-entropy of the human responses. Across a variety of domains, a recurring problem with MLE trained generative neural dialog models (G) is that they tend to produce 'safe' and generic responses ("I don't know", "I can't tell"). In contrast, discriminative dialog models (D) that are trained to rank a list of candidate human responses outperform their generative counterparts; in terms of automatic metrics, diversity, and informativeness of the responses. However, D is not useful in practice since it cannot be deployed to have real conversations with users. Our work aims to achieve the best of both worlds -- the practical usefulness of G and the strong performance of D -- via knowledge transfer from D to G. Our primary contribution is an end-to-end trainable generative visual dialog model, where G receives gradients from D as a perceptual (not adversarial) loss of the sequence sampled from G. We leverage the recently proposed Gumbel-Softmax (GS) approximation to the discrete distribution -- specifically, an RNN augmented with a sequence of GS samplers, coupled with the straight-through gradient estimator to enable end-to-end differentiability. We also introduce a stronger encoder for visual dialog, and employ a self-attention mechanism for answer encoding along with a metric learning loss to aid D in better capturing semantic similarities in answer responses. Overall, our proposed model outperforms state-of-the-art on the VisDial dataset by a significant margin (2.67% on recall@10). The source code can be downloaded from https://github.com/jiasenlu/visDial.pytorch.
It Takes Two to Tango: Towards Theory of AI's Mind
Oct 02, 2017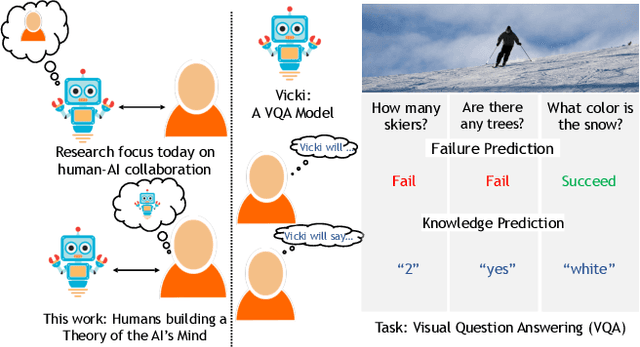

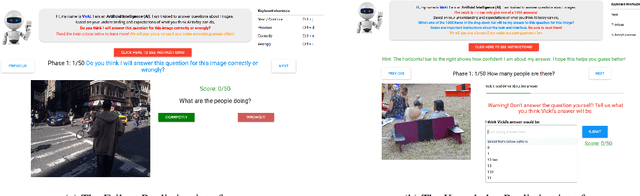
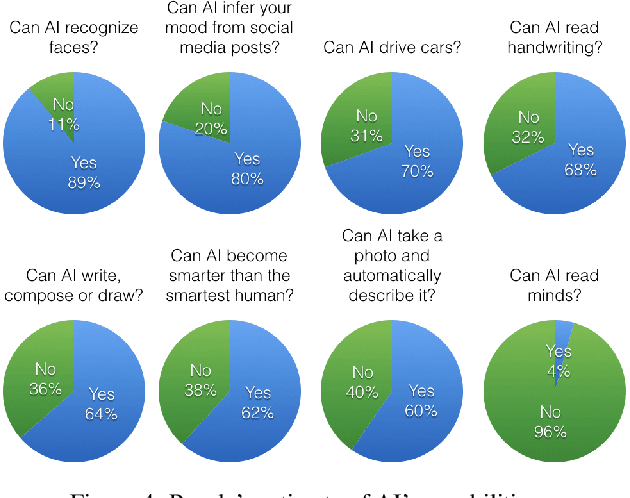
Theory of Mind is the ability to attribute mental states (beliefs, intents, knowledge, perspectives, etc.) to others and recognize that these mental states may differ from one's own. Theory of Mind is critical to effective communication and to teams demonstrating higher collective performance. To effectively leverage the progress in Artificial Intelligence (AI) to make our lives more productive, it is important for humans and AI to work well together in a team. Traditionally, there has been much emphasis on research to make AI more accurate, and (to a lesser extent) on having it better understand human intentions, tendencies, beliefs, and contexts. The latter involves making AI more human-like and having it develop a theory of our minds. In this work, we argue that for human-AI teams to be effective, humans must also develop a theory of AI's mind (ToAIM) - get to know its strengths, weaknesses, beliefs, and quirks. We instantiate these ideas within the domain of Visual Question Answering (VQA). We find that using just a few examples (50), lay people can be trained to better predict responses and oncoming failures of a complex VQA model. We further evaluate the role existing explanation (or interpretability) modalities play in helping humans build ToAIM. Explainable AI has received considerable scientific and popular attention in recent times. Surprisingly, we find that having access to the model's internal states - its confidence in its top-k predictions, explicit or implicit attention maps which highlight regions in the image (and words in the question) the model is looking at (and listening to) while answering a question about an image - do not help people better predict its behavior.
Sound-Word2Vec: Learning Word Representations Grounded in Sounds
Aug 29, 2017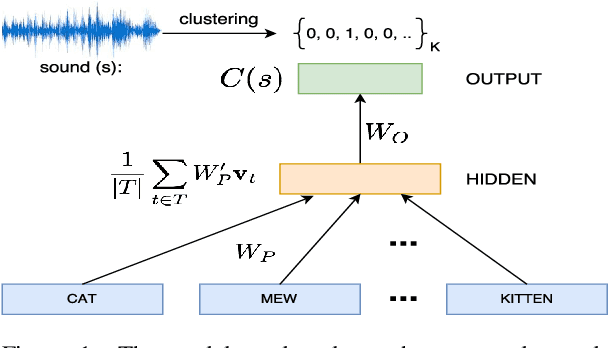

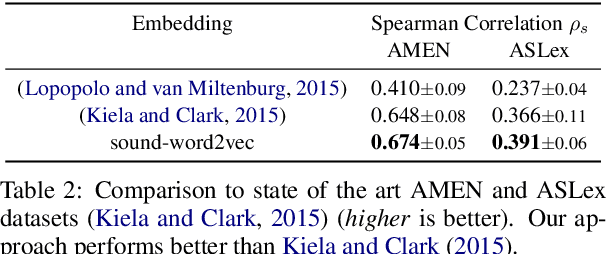
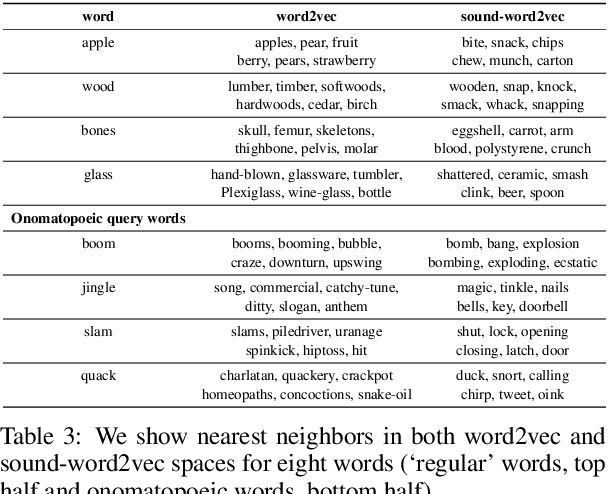
To be able to interact better with humans, it is crucial for machines to understand sound - a primary modality of human perception. Previous works have used sound to learn embeddings for improved generic textual similarity assessment. In this work, we treat sound as a first-class citizen, studying downstream textual tasks which require aural grounding. To this end, we propose sound-word2vec - a new embedding scheme that learns specialized word embeddings grounded in sounds. For example, we learn that two seemingly (semantically) unrelated concepts, like leaves and paper are similar due to the similar rustling sounds they make. Our embeddings prove useful in textual tasks requiring aural reasoning like text-based sound retrieval and discovering foley sound effects (used in movies). Moreover, our embedding space captures interesting dependencies between words and onomatopoeia and outperforms prior work on aurally-relevant word relatedness datasets such as AMEN and ASLex.
Evaluating Visual Conversational Agents via Cooperative Human-AI Games
Aug 17, 2017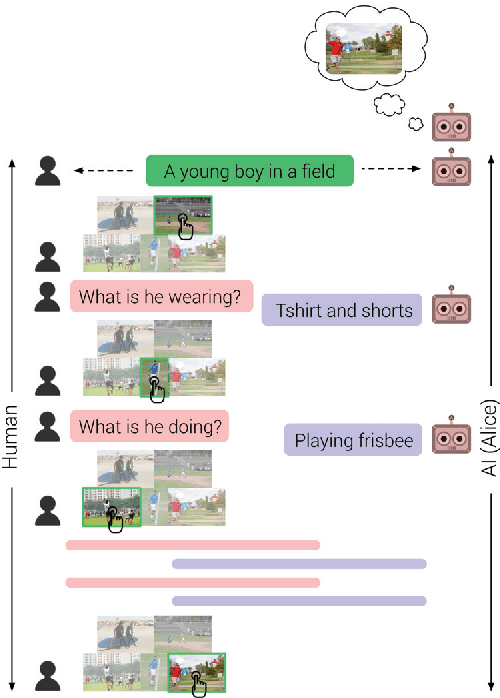


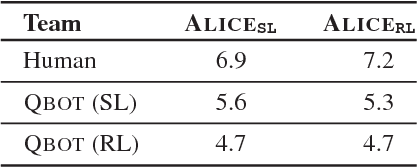
As AI continues to advance, human-AI teams are inevitable. However, progress in AI is routinely measured in isolation, without a human in the loop. It is crucial to benchmark progress in AI, not just in isolation, but also in terms of how it translates to helping humans perform certain tasks, i.e., the performance of human-AI teams. In this work, we design a cooperative game - GuessWhich - to measure human-AI team performance in the specific context of the AI being a visual conversational agent. GuessWhich involves live interaction between the human and the AI. The AI, which we call ALICE, is provided an image which is unseen by the human. Following a brief description of the image, the human questions ALICE about this secret image to identify it from a fixed pool of images. We measure performance of the human-ALICE team by the number of guesses it takes the human to correctly identify the secret image after a fixed number of dialog rounds with ALICE. We compare performance of the human-ALICE teams for two versions of ALICE. Our human studies suggest a counterintuitive trend - that while AI literature shows that one version outperforms the other when paired with an AI questioner bot, we find that this improvement in AI-AI performance does not translate to improved human-AI performance. This suggests a mismatch between benchmarking of AI in isolation and in the context of human-AI teams.
LR-GAN: Layered Recursive Generative Adversarial Networks for Image Generation
Aug 02, 2017
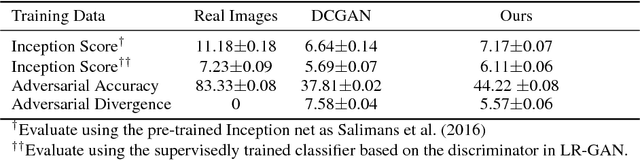
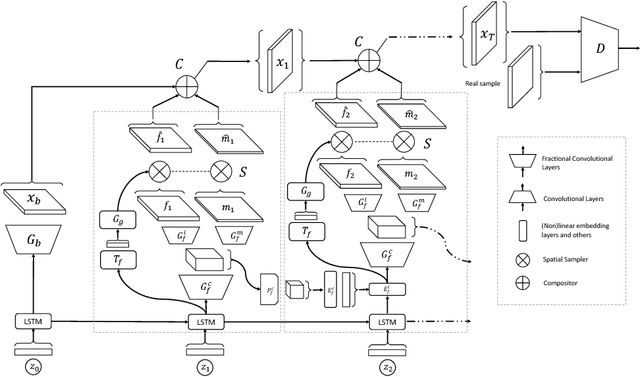

We present LR-GAN: an adversarial image generation model which takes scene structure and context into account. Unlike previous generative adversarial networks (GANs), the proposed GAN learns to generate image background and foregrounds separately and recursively, and stitch the foregrounds on the background in a contextually relevant manner to produce a complete natural image. For each foreground, the model learns to generate its appearance, shape and pose. The whole model is unsupervised, and is trained in an end-to-end manner with gradient descent methods. The experiments demonstrate that LR-GAN can generate more natural images with objects that are more human recognizable than DCGAN.
Visual Dialog
Aug 01, 2017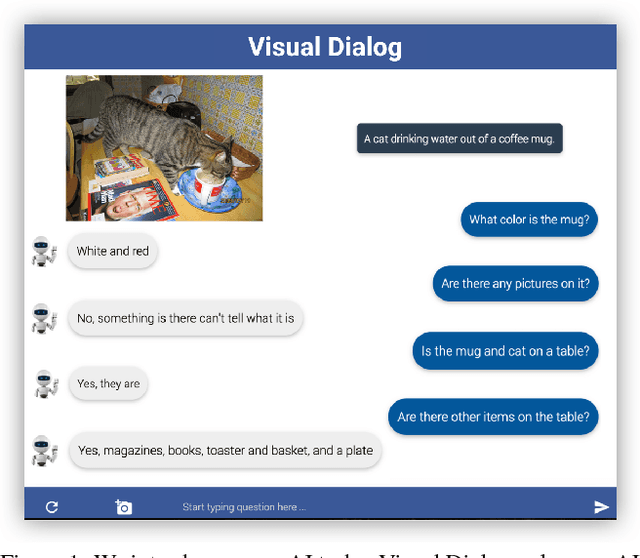
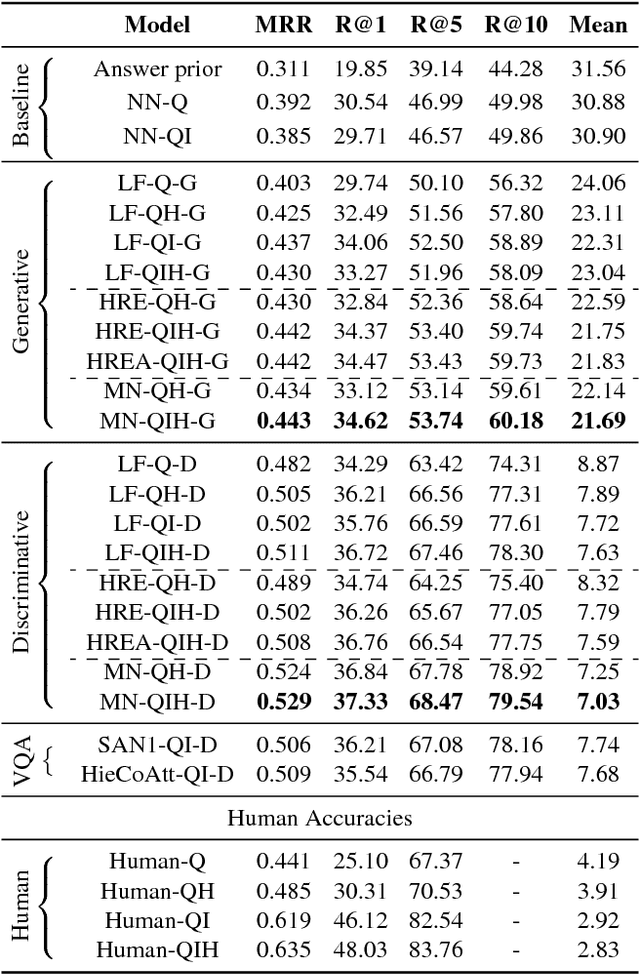


We introduce the task of Visual Dialog, which requires an AI agent to hold a meaningful dialog with humans in natural, conversational language about visual content. Specifically, given an image, a dialog history, and a question about the image, the agent has to ground the question in image, infer context from history, and answer the question accurately. Visual Dialog is disentangled enough from a specific downstream task so as to serve as a general test of machine intelligence, while being grounded in vision enough to allow objective evaluation of individual responses and benchmark progress. We develop a novel two-person chat data-collection protocol to curate a large-scale Visual Dialog dataset (VisDial). VisDial v0.9 has been released and contains 1 dialog with 10 question-answer pairs on ~120k images from COCO, with a total of ~1.2M dialog question-answer pairs. We introduce a family of neural encoder-decoder models for Visual Dialog with 3 encoders -- Late Fusion, Hierarchical Recurrent Encoder and Memory Network -- and 2 decoders (generative and discriminative), which outperform a number of sophisticated baselines. We propose a retrieval-based evaluation protocol for Visual Dialog where the AI agent is asked to sort a set of candidate answers and evaluated on metrics such as mean-reciprocal-rank of human response. We quantify gap between machine and human performance on the Visual Dialog task via human studies. Putting it all together, we demonstrate the first 'visual chatbot'! Our dataset, code, trained models and visual chatbot are available on https://visualdialog.org
Context-aware Captions from Context-agnostic Supervision
Jul 31, 2017

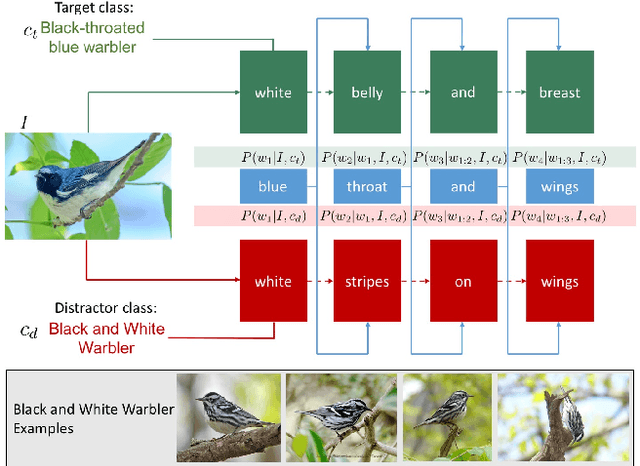

We introduce an inference technique to produce discriminative context-aware image captions (captions that describe differences between images or visual concepts) using only generic context-agnostic training data (captions that describe a concept or an image in isolation). For example, given images and captions of "siamese cat" and "tiger cat", we generate language that describes the "siamese cat" in a way that distinguishes it from "tiger cat". Our key novelty is that we show how to do joint inference over a language model that is context-agnostic and a listener which distinguishes closely-related concepts. We first apply our technique to a justification task, namely to describe why an image contains a particular fine-grained category as opposed to another closely-related category of the CUB-200-2011 dataset. We then study discriminative image captioning to generate language that uniquely refers to one of two semantically-similar images in the COCO dataset. Evaluations with discriminative ground truth for justification and human studies for discriminative image captioning reveal that our approach outperforms baseline generative and speaker-listener approaches for discrimination.
Deal or No Deal? End-to-End Learning for Negotiation Dialogues
Jun 16, 2017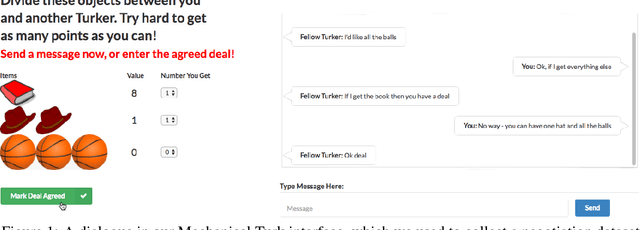
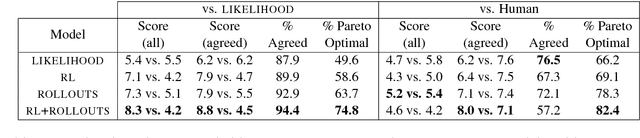
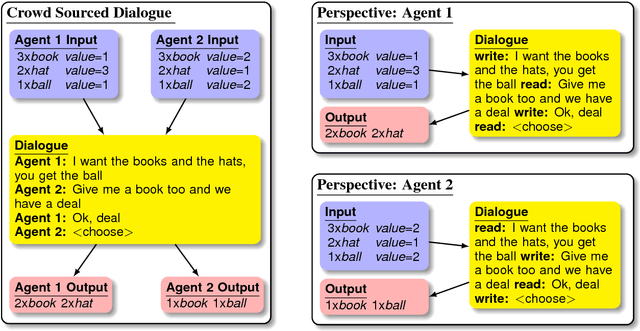
Much of human dialogue occurs in semi-cooperative settings, where agents with different goals attempt to agree on common decisions. Negotiations require complex communication and reasoning skills, but success is easy to measure, making this an interesting task for AI. We gather a large dataset of human-human negotiations on a multi-issue bargaining task, where agents who cannot observe each other's reward functions must reach an agreement (or a deal) via natural language dialogue. For the first time, we show it is possible to train end-to-end models for negotiation, which must learn both linguistic and reasoning skills with no annotated dialogue states. We also introduce dialogue rollouts, in which the model plans ahead by simulating possible complete continuations of the conversation, and find that this technique dramatically improves performance. Our code and dataset are publicly available (https://github.com/facebookresearch/end-to-end-negotiator).
Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
Jun 06, 2017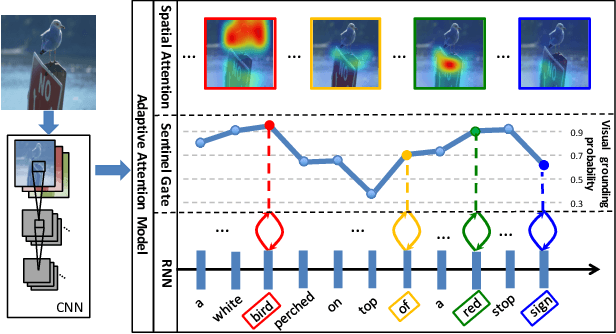
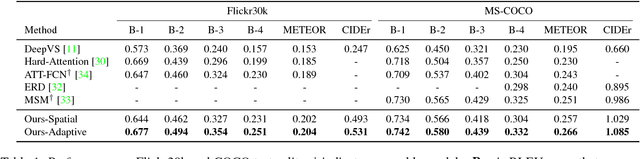
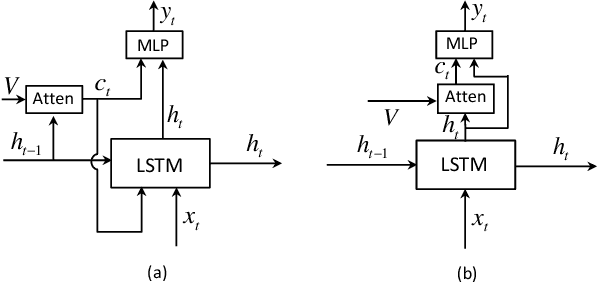
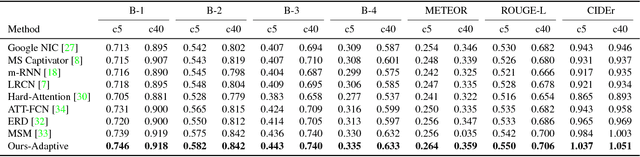
Attention-based neural encoder-decoder frameworks have been widely adopted for image captioning. Most methods force visual attention to be active for every generated word. However, the decoder likely requires little to no visual information from the image to predict non-visual words such as "the" and "of". Other words that may seem visual can often be predicted reliably just from the language model e.g., "sign" after "behind a red stop" or "phone" following "talking on a cell". In this paper, we propose a novel adaptive attention model with a visual sentinel. At each time step, our model decides whether to attend to the image (and if so, to which regions) or to the visual sentinel. The model decides whether to attend to the image and where, in order to extract meaningful information for sequential word generation. We test our method on the COCO image captioning 2015 challenge dataset and Flickr30K. Our approach sets the new state-of-the-art by a significant margin.
Cooperative Learning with Visual Attributes
May 16, 2017
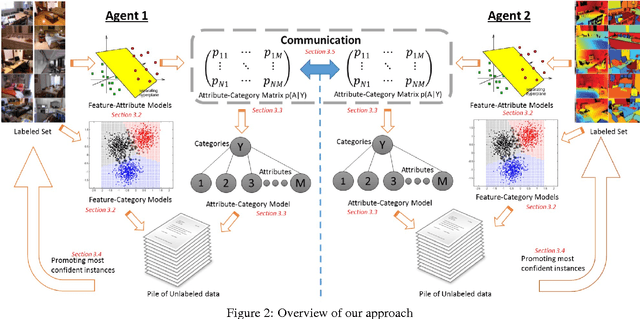
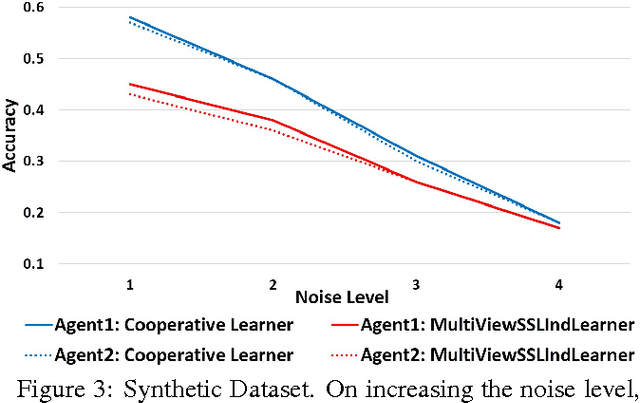
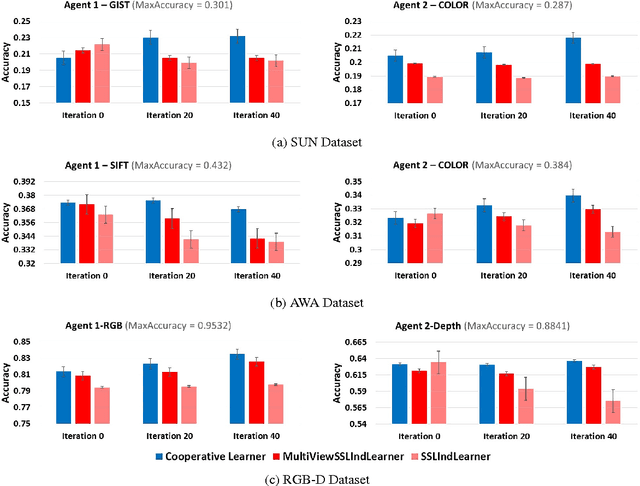
Learning paradigms involving varying levels of supervision have received a lot of interest within the computer vision and machine learning communities. The supervisory information is typically considered to come from a human supervisor -- a "teacher" figure. In this paper, we consider an alternate source of supervision -- a "peer" -- i.e. a different machine. We introduce cooperative learning, where two agents trying to learn the same visual concepts, but in potentially different environments using different sources of data (sensors), communicate their current knowledge of these concepts to each other. Given the distinct sources of data in both agents, the mode of communication between the two agents is not obvious. We propose the use of visual attributes -- semantic mid-level visual properties such as furry, wooden, etc.-- as the mode of communication between the agents. Our experiments in three domains -- objects, scenes, and animals -- demonstrate that our proposed cooperative learning approach improves the performance of both agents as compared to their performance if they were to learn in isolation. Our approach is particularly applicable in scenarios where privacy, security and/or bandwidth constraints restrict the amount and type of information the two agents can exchange.