 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePYROBOCOP : Python-based Robotic Control & Optimization Package for Manipulation and Collision Avoidance
Jun 06, 2021
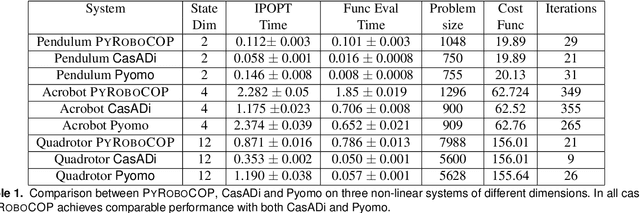
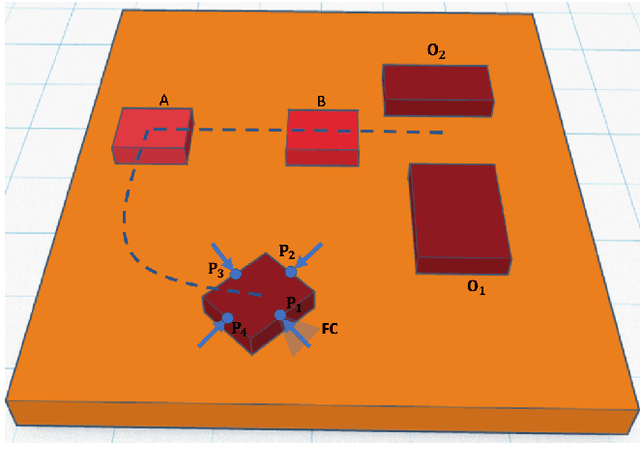
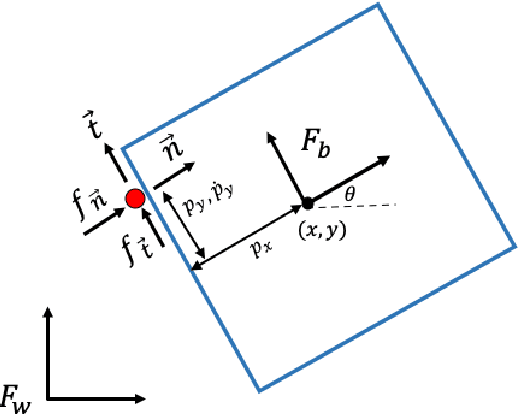
PYROBOCOP is a lightweight Python-based package for control and optimization of robotic systems described by nonlinear Differential Algebraic Equations (DAEs). In particular, the package can handle systems with contacts that are described by complementarity constraints and provides a general framework for specifying obstacle avoidance constraints. The package performs direct transcription of the DAEs into a set of nonlinear equations by performing orthogonal collocation on finite elements. The resulting optimization problem belongs to the class of Mathematical Programs with Complementarity Constraints (MPCCs). MPCCs fail to satisfy commonly assumed constraint qualifications and require special handling of the complementarity constraints in order for NonLinear Program (NLP) solvers to solve them effectively. PYROBOCOP provides automatic reformulation of the complementarity constraints that enables NLP solvers to perform optimization of robotic systems. The package is interfaced with ADOLC for obtaining sparse derivatives by automatic differentiation and IPOPT for performing optimization. We demonstrate the effectiveness of our approach in terms of speed and flexibility. We provide several numerical examples for several robotic systems with collision avoidance as well as contact constraints represented using complementarity constraints. We provide comparisons with other open source optimization packages like CasADi and Pyomo .
Tactile-RL for Insertion: Generalization to Objects of Unknown Geometry
Apr 02, 2021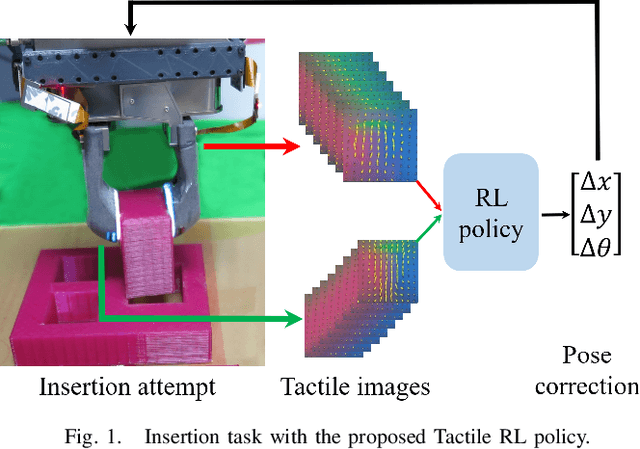
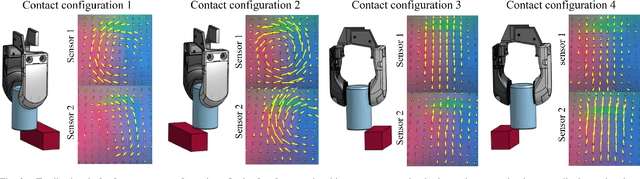
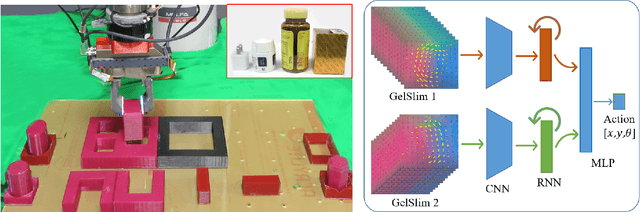
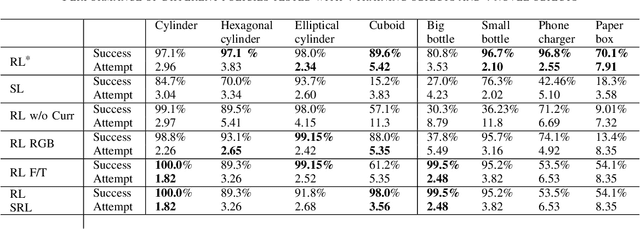
Object insertion is a classic contact-rich manipulation task. The task remains challenging, especially when considering general objects of unknown geometry, which significantly limits the ability to understand the contact configuration between the object and the environment. We study the problem of aligning the object and environment with a tactile-based feedback insertion policy. The insertion process is modeled as an episodic policy that iterates between insertion attempts followed by pose corrections. We explore different mechanisms to learn such a policy based on Reinforcement Learning. The key contribution of this paper is to demonstrate that it is possible to learn a tactile insertion policy that generalizes across different object geometries, and an ablation study of the key design choices for the learning agent: 1) the type of learning scheme: supervised vs. reinforcement learning; 2) the type of learning schedule: unguided vs. curriculum learning; 3) the type of sensing modality: force/torque (F/T) vs. tactile; and 4) the type of tactile representation: tactile RGB vs. tactile flow. We show that the optimal configuration of the learning agent (RL + curriculum + tactile flow) exposed to 4 training objects yields an insertion policy that inserts 4 novel objects with over 85.0% success rate and within 3~4 attempts. Comparisons between F/T and tactile sensing, shows that while an F/T-based policy learns more efficiently, a tactile-based policy provides better generalization.
Markov Modeling of Time-Series Data using Symbolic Analysis
Mar 23, 2021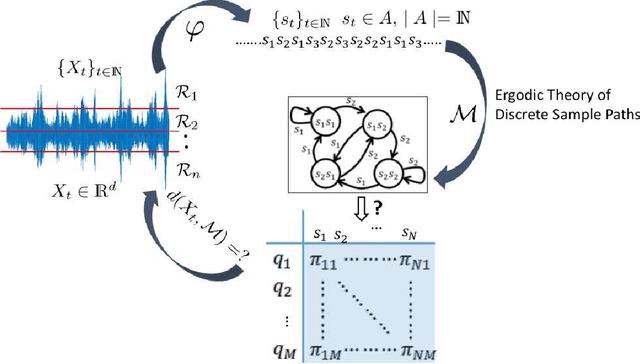

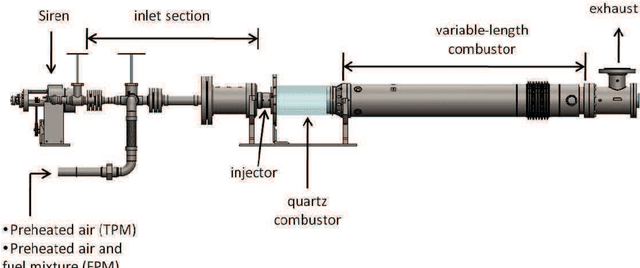
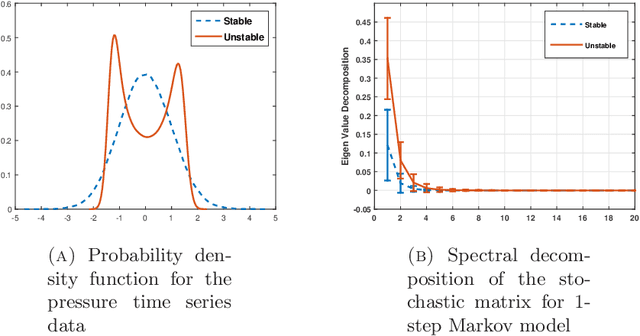
Markov models are often used to capture the temporal patterns of sequential data for statistical learning applications. While the Hidden Markov modeling-based learning mechanisms are well studied in literature, we analyze a symbolic-dynamics inspired approach. Under this umbrella, Markov modeling of time-series data consists of two major steps -- discretization of continuous attributes followed by estimating the size of temporal memory of the discretized sequence. These two steps are critical for the accurate and concise representation of time-series data in the discrete space. Discretization governs the information content of the resultant discretized sequence. On the other hand, memory estimation of the symbolic sequence helps to extract the predictive patterns in the discretized data. Clearly, the effectiveness of signal representation as a discrete Markov process depends on both these steps. In this paper, we will review the different techniques for discretization and memory estimation for discrete stochastic processes. In particular, we will focus on the individual problems of discretization and order estimation for discrete stochastic process. We will present some results from literature on partitioning from dynamical systems theory and order estimation using concepts of information theory and statistical learning. The paper also presents some related problem formulations which will be useful for machine learning and statistical learning application using the symbolic framework of data analysis. We present some results of statistical analysis of a complex thermoacoustic instability phenomenon during lean-premixed combustion in jet-turbine engines using the proposed Markov modeling method.
Training Larger Networks for Deep Reinforcement Learning
Feb 16, 2021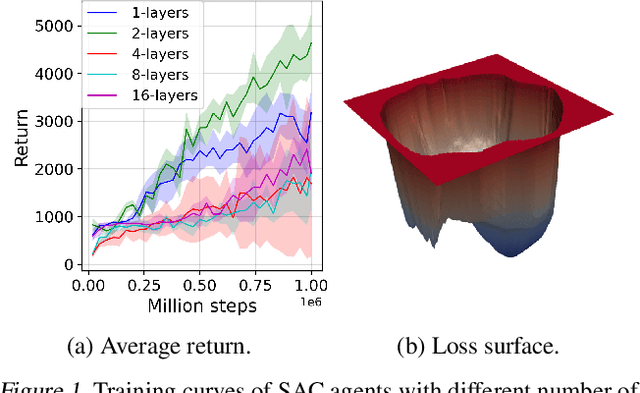

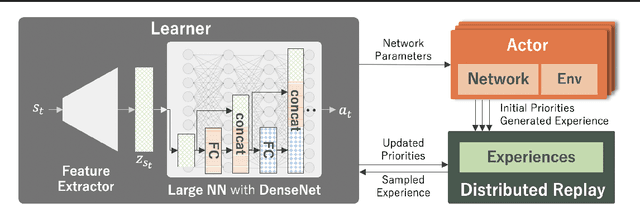
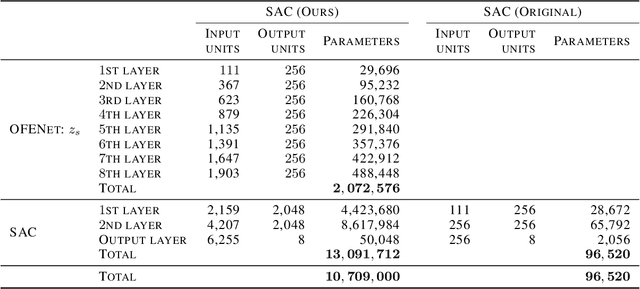
The success of deep learning in the computer vision and natural language processing communities can be attributed to training of very deep neural networks with millions or billions of parameters which can then be trained with massive amounts of data. However, similar trend has largely eluded training of deep reinforcement learning (RL) algorithms where larger networks do not lead to performance improvement. Previous work has shown that this is mostly due to instability during training of deep RL agents when using larger networks. In this paper, we make an attempt to understand and address training of larger networks for deep RL. We first show that naively increasing network capacity does not improve performance. Then, we propose a novel method that consists of 1) wider networks with DenseNet connection, 2) decoupling representation learning from training of RL, 3) a distributed training method to mitigate overfitting problems. Using this three-fold technique, we show that we can train very large networks that result in significant performance gains. We present several ablation studies to demonstrate the efficacy of the proposed method and some intuitive understanding of the reasons for performance gain. We show that our proposed method outperforms other baseline algorithms on several challenging locomotion tasks.
Towards Human-Level Learning of Complex Physical Puzzles
Nov 14, 2020
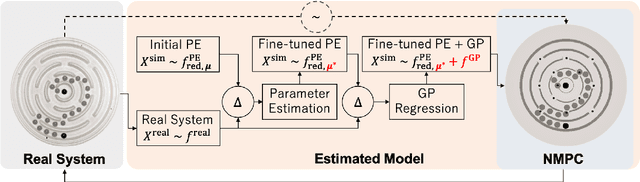
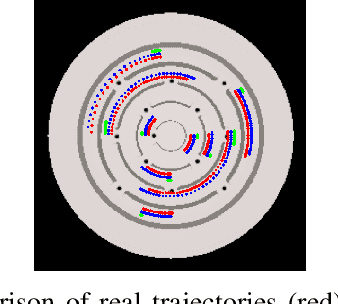
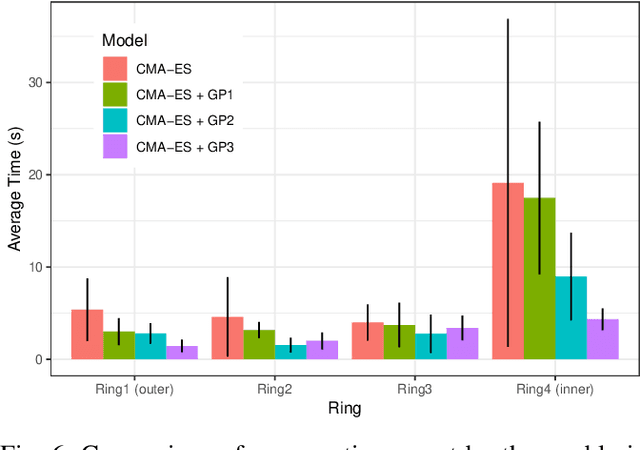
Humans quickly solve tasks in novel systems with complex dynamics, without requiring much interaction. While deep reinforcement learning algorithms have achieved tremendous success in many complex tasks, these algorithms need a large number of samples to learn meaningful policies. In this paper, we present a task for navigating a marble to the center of a circular maze. While this system is very intuitive and easy for humans to solve, it can be very difficult and inefficient for standard reinforcement learning algorithms to learn meaningful policies. We present a model that learns to move a marble in the complex environment within minutes of interacting with the real system. Learning consists of initializing a physics engine with parameters estimated using data from the real system. The error in the physics engine is then corrected using Gaussian process regression, which is used to model the residual between real observations and physics engine simulations. The physics engine equipped with the residual model is then used to control the marble in the maze environment using a model-predictive feedback over a receding horizon. We contrast the learning behavior against the time taken by humans to solve the problem to show comparable behavior. To the best of our knowledge, this is the first time that a hybrid model consisting of a full physics engine along with a statistical function approximator has been used to control a complex physical system in real-time using nonlinear model-predictive control (NMPC). Codes for the simulation environment can be downloaded here https://www.merl.com/research/license/CME . A video describing our method could be found here https://youtu.be/xaxNCXBovpc .
Deep Reactive Planning in Dynamic Environments
Nov 05, 2020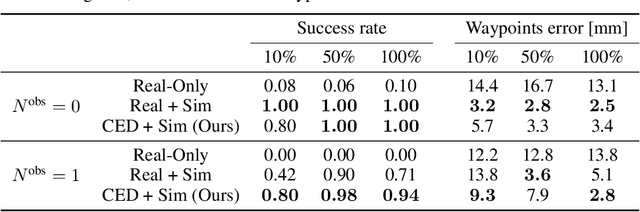
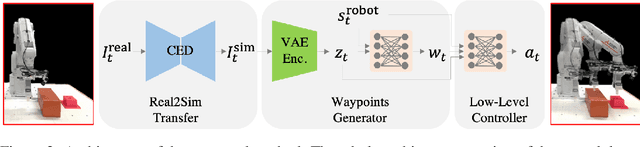


The main novelty of the proposed approach is that it allows a robot to learn an end-to-end policy which can adapt to changes in the environment during execution. While goal conditioning of policies has been studied in the RL literature, such approaches are not easily extended to cases where the robot's goal can change during execution. This is something that humans are naturally able to do. However, it is difficult for robots to learn such reflexes (i.e., to naturally respond to dynamic environments), especially when the goal location is not explicitly provided to the robot, and instead needs to be perceived through a vision sensor. In the current work, we present a method that can achieve such behavior by combining traditional kinematic planning, deep learning, and deep reinforcement learning in a synergistic fashion to generalize to arbitrary environments. We demonstrate the proposed approach for several reaching and pick-and-place tasks in simulation, as well as on a real system of a 6-DoF industrial manipulator. A video describing our work could be found \url{https://youtu.be/hE-Ew59GRPQ}.
Understanding Multi-Modal Perception Using Behavioral Cloning for Peg-In-a-Hole Insertion Tasks
Jul 22, 2020
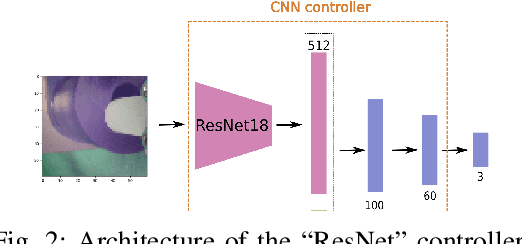
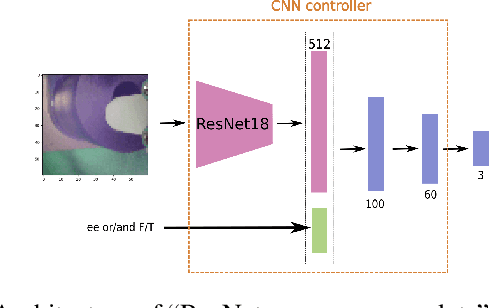
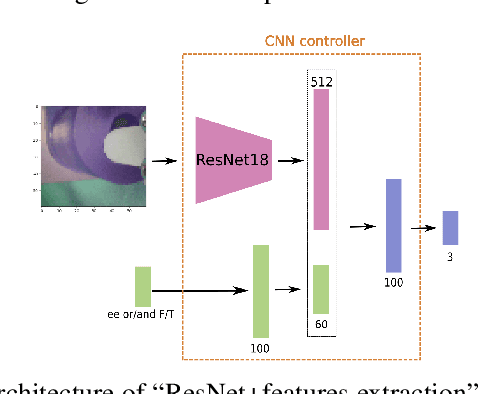
One of the main challenges in peg-in-a-hole (PiH) insertion tasks is in handling the uncertainty in the location of the target hole. In order to address it, high-dimensional sensor inputs from sensor modalities such as vision, force/torque sensing, and proprioception can be combined to learn control policies that are robust to this uncertainty in the target pose. Whereas deep learning has shown success in recognizing objects and making decisions with high-dimensional inputs, the learning procedure might damage the robot when applying directly trial- and-error algorithms on the real system. At the same time, learning from Demonstration (LfD) methods have been shown to achieve compelling performance in real robotic systems by leveraging demonstration data provided by experts. In this paper, we investigate the merits of multiple sensor modalities such as vision, force/torque sensors, and proprioception when combined to learn a controller for real world assembly operation tasks using LfD techniques. The study is limited to PiH insertions; we plan to extend the study to more experiments in the future. Additionally, we propose a multi-step-ahead loss function to improve the performance of the behavioral cloning method. Experimental results on a real manipulator support our findings, and show the effectiveness of the proposed loss function.
CAZSL: Zero-Shot Regression for Pushing Models by Generalizing Through Context
Mar 26, 2020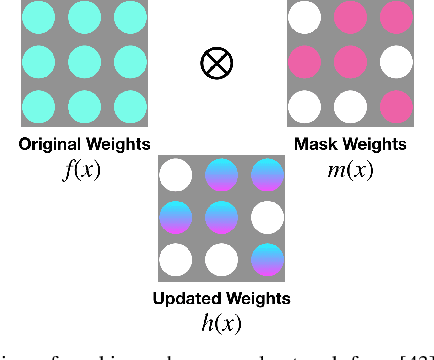
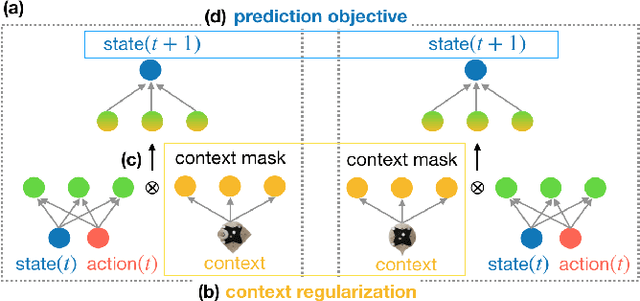

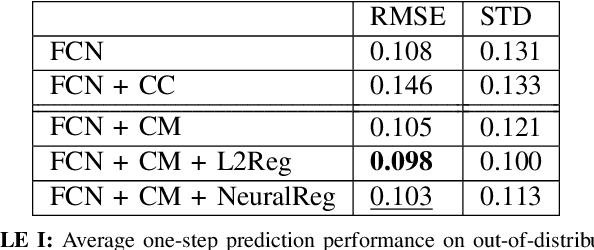
Learning accurate models of the physical world is required for a lot of robotic manipulation tasks. However, during manipulation, robots are expected to interact with unknown workpieces so that building predictive models which can generalize over a number of these objects is highly desirable. In this paper, we study the problem of designing learning agents which can generalize their models of the physical world by building context-aware learning models. The purpose of these agents is to quickly adapt and/or generalize their notion of physics of interaction in the real world based on certain features about the interacting objects that provide different contexts to the predictive models. With this motivation, we present context-aware zero shot learning (CAZSL, pronounced as 'casual') models, an approach utilizing a Siamese network architecture, embedding space masking and regularization based on context variables which allows us to learn a model that can generalize to different parameters or features of the interacting objects. We test our proposed learning algorithm on the recently released Omnipush datatset that allows testing of meta-learning capabilities using low-dimensional data.
Efficient Exploration in Constrained Environments with Goal-Oriented Reference Path
Mar 03, 2020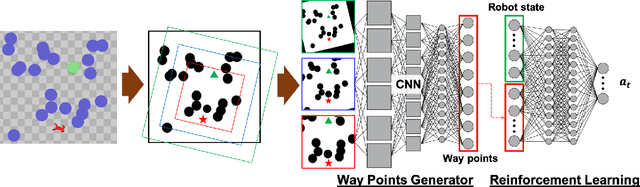
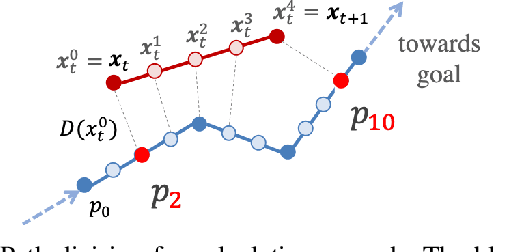
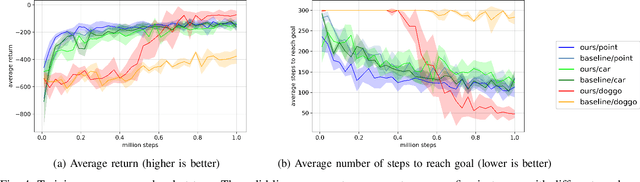
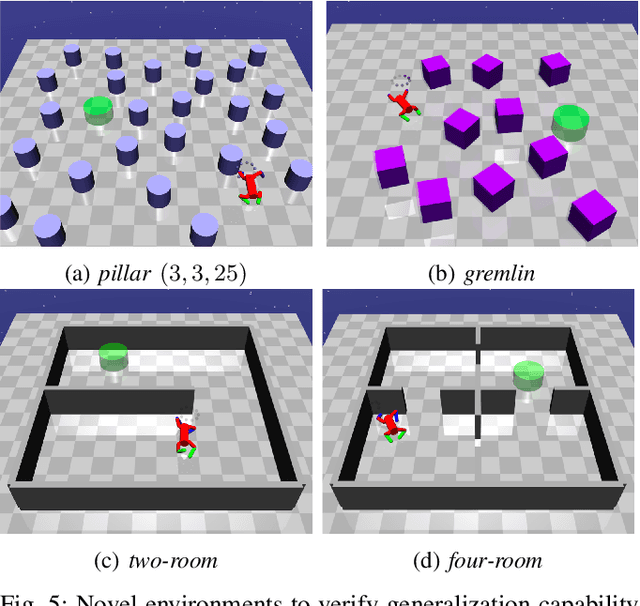
In this paper, we consider the problem of building learning agents that can efficiently learn to navigate in constrained environments. The main goal is to design agents that can efficiently learn to understand and generalize to different environments using high-dimensional inputs (a 2D map), while following feasible paths that avoid obstacles in obstacle-cluttered environment. To achieve this, we make use of traditional path planning algorithms, supervised learning, and reinforcement learning algorithms in a synergistic way. The key idea is to decouple the navigation problem into planning and control, the former of which is achieved by supervised learning whereas the latter is done by reinforcement learning. Specifically, we train a deep convolutional network that can predict collision-free paths based on a map of the environment-- this is then used by a reinforcement learning algorithm to learn to closely follow the path. This allows the trained agent to achieve good generalization while learning faster. We test our proposed method in the recently proposed Safety Gym suite that allows testing of safety-constraints during training of learning agents. We compare our proposed method with existing work and show that our method consistently improves the sample efficiency and generalization capability to novel environments.
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?
Mar 03, 2020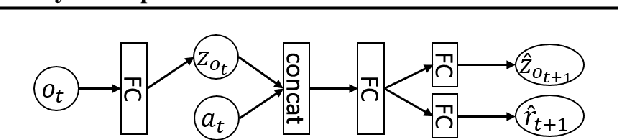

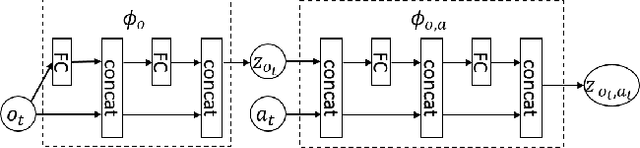
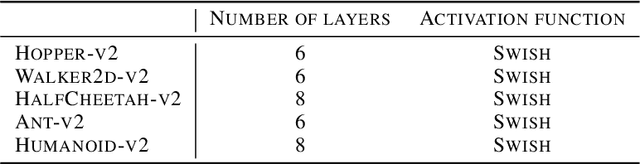
Deep reinforcement learning (RL) algorithms have recently achieved remarkable successes in various sequential decision making tasks, leveraging advances in methods for training large deep networks. However, these methods usually require large amounts of training data, which is often a big problem for real-world applications. One natural question to ask is whether learning good representations for states and using larger networks helps in learning better policies. In this paper, we try to study if increasing input dimensionality helps improve performance and sample efficiency of model-free deep RL algorithms. To do so, we propose an online feature extractor network (OFENet) that uses neural nets to produce good representations to be used as inputs to deep RL algorithms. Even though the high dimensionality of input is usually supposed to make learning of RL agents more difficult, we show that the RL agents in fact learn more efficiently with the high-dimensional representation than with the lower-dimensional state observations. We believe that stronger feature propagation together with larger networks (and thus larger search space) allows RL agents to learn more complex functions of states and thus improves the sample efficiency. Through numerical experiments, we show that the proposed method outperforms several other state-of-the-art algorithms in terms of both sample efficiency and performance.