 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRec-Distill: An Industrial Distillation Pipeline for Large-Scale Recommendation Models
May 28, 2026Large recommendation models have demonstrated substantial potential gains under scaling laws, yet these gains are difficult to realize in industrial recommendation systems because real-world deployment requires lightweight models with strict serving efficiency and latency guarantees. This creates a fundamental gap between offline model scaling and online deployment. In this work, we present Rec-Distill, an industrial distillation pipeline that transfers the performance gains of large-scale recommendation modeling to efficient serving models. Rec-Distill combines large-teacher scaling with student-side transfer optimization through decoupled training, black-box distillation, debiasing mechanism, and a hybrid batch-streaming pipeline for dynamic recommendation environments. Across multiple recommendation and advertising scenarios on real-world platforms, our framework scales teacher models up to 24B dense parameters and 20K behavior sequence length, while enabling lightweight students to recover a substantial portion of teacher gains, with distillation transferability exceeding 60% in the best setting. Extensive offline and online experiments further show that these transferred gains consistently translate into measurable business improvements under industrial constraints. These results demonstrate that Rec-Distill provides a practical framework for distilling large-scale recommendation models into deployable, cost-efficient serving systems, while also establishing a reliable path toward scaling recommendation models to even larger regimes in the future.
Compute Only Once: UG-Separation for Efficient Large Recommendation Models
Feb 11, 2026Driven by scaling laws, recommender systems increasingly rely on large-scale models to capture complex feature interactions and user behaviors, but this trend also leads to prohibitive training and inference costs. While long-sequence models(e.g., LONGER) can reuse user-side computation through KV caching, such reuse is difficult in dense feature interaction architectures(e.g., RankMixer), where user and group (candidate item) features are deeply entangled across layers. In this work, we propose User-Group Separation (UG-Sep), a novel framework that enables reusable user-side computation in dense interaction models for the first time. UG-Sep introduces a masking mechanism that explicitly disentangles user-side and item-side information flows within token-mixing layers, ensuring that a subset of tokens to preserve purely user-side representations across layers. This design enables corresponding token computations to be reused across multiple samples, significantly reducing redundant inference cost. To compensate for potential expressiveness loss induced by masking, we further propose an Information Compensation strategy that adaptively reconstructs suppressed user-item interactions. Moreover, as UG-Sep substantially reduces user-side FLOPs and exposes memory-bound components, we incorporate W8A16 (8-bit weight, 16-bit activation) weight-only quantization to alleviate memory bandwidth bottlenecks and achieve additional acceleration. We conduct extensive offline evaluations and large-scale online A/B experiments at ByteDance, demonstrating that UG-Sep reduces inference latency by up to 20 percent without degrading online user experience or commercial metrics across multiple business scenarios, including feed recommendation and advertising systems.
TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders
Feb 06, 2026In recent years, the study of scaling laws for large recommendation models has gradually gained attention. Works such as Wukong, HiFormer, and DHEN have attempted to increase the complexity of interaction structures in ranking models and validate scaling laws between performance and parameters/FLOPs by stacking multiple layers. However, their experimental scale remains relatively limited. Our previous work introduced the TokenMixer architecture, an efficient variant of the standard Transformer where the self-attention mechanism is replaced by a simple reshape operation, and the feed-forward network is adapted to a pertoken FFN. The effectiveness of this architecture was demonstrated in the ranking stage by the model presented in the RankMixer paper. However, this foundational TokenMixer architecture itself has several design limitations. In this paper, we propose TokenMixer-Large, which systematically addresses these core issues: sub-optimal residual design, insufficient gradient updates in deep models, incomplete MoE sparsification, and limited exploration of scalability. By leveraging a mixing-and-reverting operation, inter-layer residuals, the auxiliary loss and a novel Sparse-Pertoken MoE architecture, TokenMixer-Large successfully scales its parameters to 7-billion and 15-billion on online traffic and offline experiments, respectively. Currently deployed in multiple scenarios at ByteDance, TokenMixer -Large has achieved significant offline and online performance gains.
Large Memory Network for Recommendation
Feb 08, 2025



Modeling user behavior sequences in recommender systems is essential for understanding user preferences over time, enabling personalized and accurate recommendations for improving user retention and enhancing business values. Despite its significance, there are two challenges for current sequential modeling approaches. From the spatial dimension, it is difficult to mutually perceive similar users' interests for a generalized intention understanding; from the temporal dimension, current methods are generally prone to forgetting long-term interests due to the fixed-length input sequence. In this paper, we present Large Memory Network (LMN), providing a novel idea by compressing and storing user history behavior information in a large-scale memory block. With the elaborated online deployment strategy, the memory block can be easily scaled up to million-scale in the industry. Extensive offline comparison experiments, memory scaling up experiments, and online A/B test on Douyin E-Commerce Search (ECS) are performed, validating the superior performance of LMN. Currently, LMN has been fully deployed in Douyin ECS, serving millions of users each day.
Distributed Hierarchical GPU Parameter Server for Massive Scale Deep Learning Ads Systems
Mar 12, 2020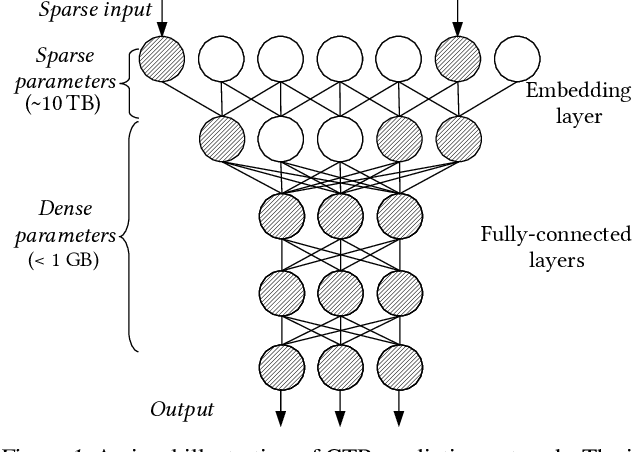
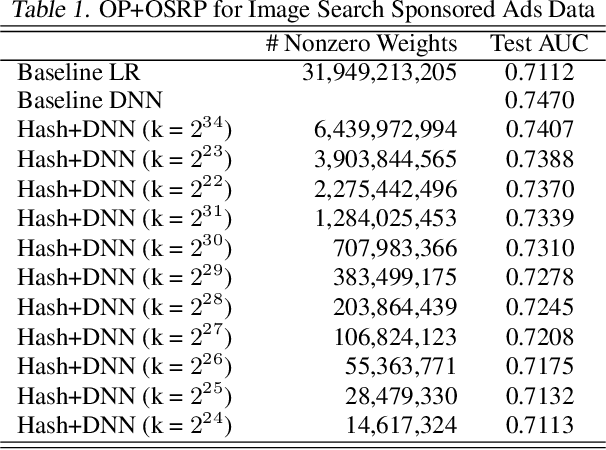
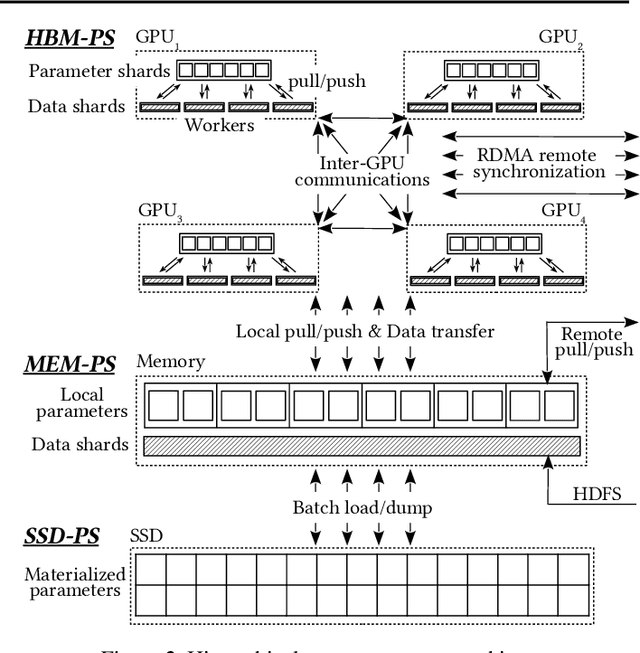
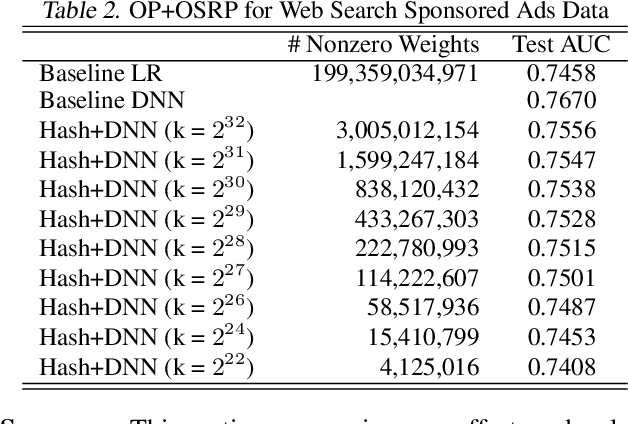
Neural networks of ads systems usually take input from multiple resources, e.g., query-ad relevance, ad features and user portraits. These inputs are encoded into one-hot or multi-hot binary features, with typically only a tiny fraction of nonzero feature values per example. Deep learning models in online advertising industries can have terabyte-scale parameters that do not fit in the GPU memory nor the CPU main memory on a computing node. For example, a sponsored online advertising system can contain more than $10^{11}$ sparse features, making the neural network a massive model with around 10 TB parameters. In this paper, we introduce a distributed GPU hierarchical parameter server for massive scale deep learning ads systems. We propose a hierarchical workflow that utilizes GPU High-Bandwidth Memory, CPU main memory and SSD as 3-layer hierarchical storage. All the neural network training computations are contained in GPUs. Extensive experiments on real-world data confirm the effectiveness and the scalability of the proposed system. A 4-node hierarchical GPU parameter server can train a model more than 2X faster than a 150-node in-memory distributed parameter server in an MPI cluster. In addition, the price-performance ratio of our proposed system is 4-9 times better than an MPI-cluster solution.