 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers on Multilingual Clause-Level Morphology
Nov 13, 2022This paper describes our winning systems in MRL: The 1st Shared Task on Multilingual Clause-level Morphology (EMNLP 2022 Workshop) designed by KUIS AI NLP team. We present our work for all three parts of the shared task: inflection, reinflection, and analysis. We mainly explore transformers with two approaches: (i) training models from scratch in combination with data augmentation, and (ii) transfer learning with prefix-tuning at multilingual morphological tasks. Data augmentation significantly improves performance for most languages in the inflection and reinflection tasks. On the other hand, Prefix-tuning on a pre-trained mGPT model helps us to adapt analysis tasks in low-data and multilingual settings. While transformer architectures with data augmentation achieved the most promising results for inflection and reinflection tasks, prefix-tuning on mGPT received the highest results for the analysis task. Our systems received 1st place in all three tasks in MRL 2022.
Self-Supervised Learning with an Information Maximization Criterion
Sep 16, 2022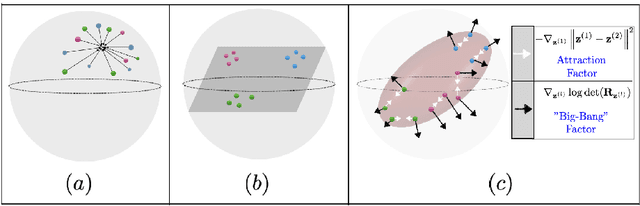
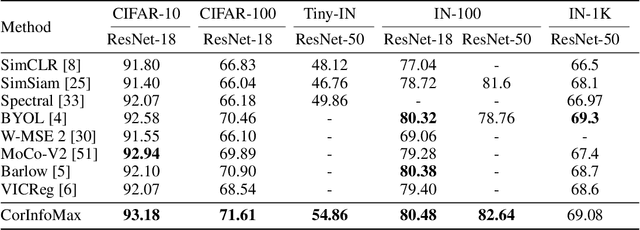
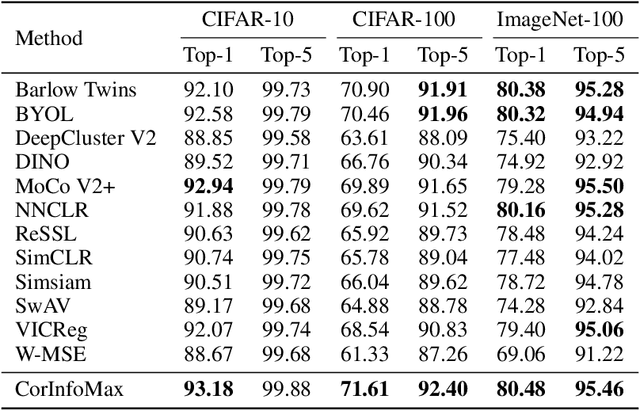
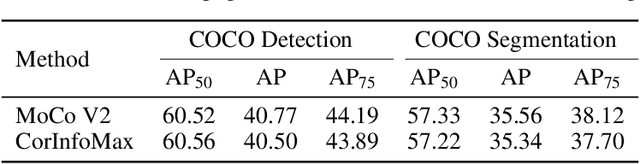
Self-supervised learning allows AI systems to learn effective representations from large amounts of data using tasks that do not require costly labeling. Mode collapse, i.e., the model producing identical representations for all inputs, is a central problem to many self-supervised learning approaches, making self-supervised tasks, such as matching distorted variants of the inputs, ineffective. In this article, we argue that a straightforward application of information maximization among alternative latent representations of the same input naturally solves the collapse problem and achieves competitive empirical results. We propose a self-supervised learning method, CorInfoMax, that uses a second-order statistics-based mutual information measure that reflects the level of correlation among its arguments. Maximizing this correlative information measure between alternative representations of the same input serves two purposes: (1) it avoids the collapse problem by generating feature vectors with non-degenerate covariances; (2) it establishes relevance among alternative representations by increasing the linear dependence among them. An approximation of the proposed information maximization objective simplifies to a Euclidean distance-based objective function regularized by the log-determinant of the feature covariance matrix. The regularization term acts as a natural barrier against feature space degeneracy. Consequently, beyond avoiding complete output collapse to a single point, the proposed approach also prevents dimensional collapse by encouraging the spread of information across the whole feature space. Numerical experiments demonstrate that CorInfoMax achieves better or competitive performance results relative to the state-of-the-art SSL approaches.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Mukayese: Turkish NLP Strikes Back
Mar 16, 2022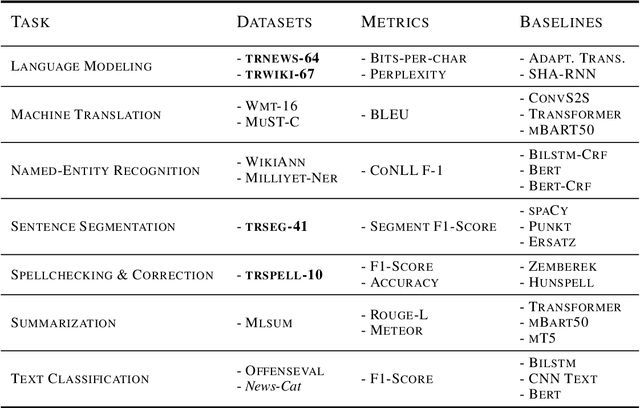
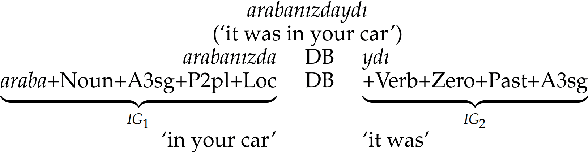
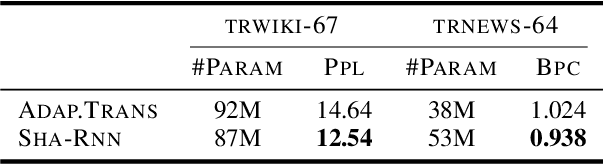
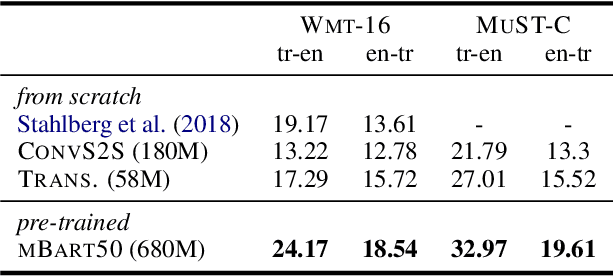
Having sufficient resources for language X lifts it from the under-resourced languages class, but not necessarily from the under-researched class. In this paper, we address the problem of the absence of organized benchmarks in the Turkish language. We demonstrate that languages such as Turkish are left behind the state-of-the-art in NLP applications. As a solution, we present Mukayese, a set of NLP benchmarks for the Turkish language that contains several NLP tasks. We work on one or more datasets for each benchmark and present two or more baselines. Moreover, we present four new benchmarking datasets in Turkish for language modeling, sentence segmentation, and spell checking. All datasets and baselines are available under: https://github.com/alisafaya/mukayese
CRAFT: A Benchmark for Causal Reasoning About Forces and inTeractions
Dec 08, 2020
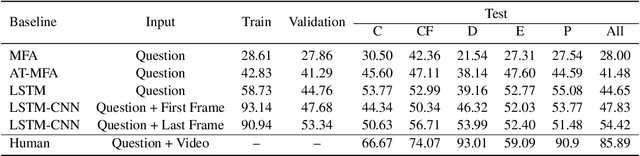
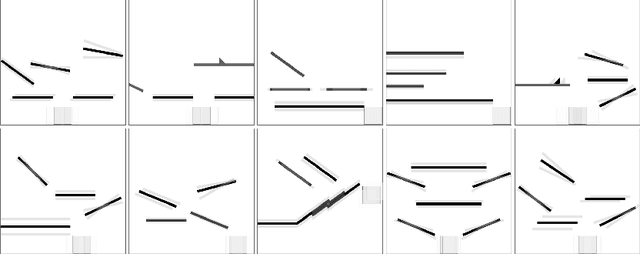
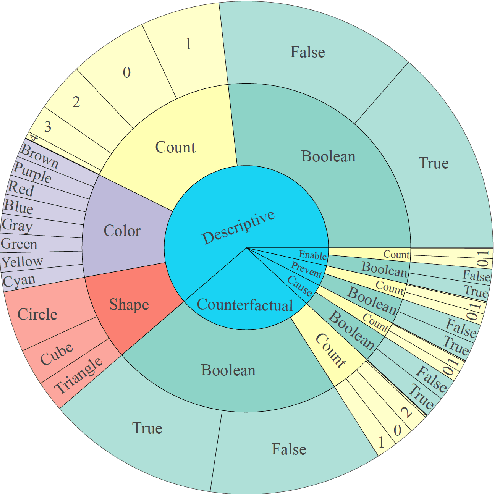
Recent advances in Artificial Intelligence and deep learning have revived the interest in studying the gap between the reasoning capabilities of humans and machines. In this ongoing work, we introduce CRAFT, a new visual question answering dataset that requires causal reasoning about physical forces and object interactions. It contains 38K video and question pairs that are generated from 3K videos from 10 different virtual environments, containing different number of objects in motion that interact with each other. Two question categories from CRAFT include previously studied descriptive and counterfactual questions. Besides, inspired by the theory of force dynamics from the field of human cognitive psychology, we introduce new question categories that involve understanding the intentions of objects through the notions of cause, enable, and prevent. Our preliminary results demonstrate that even though these tasks are very intuitive for humans, the implemented baselines could not cope with the underlying challenges.
KUISAIL at SemEval-2020 Task 12: BERT-CNN for Offensive Speech Identification in Social Media
Jul 26, 2020
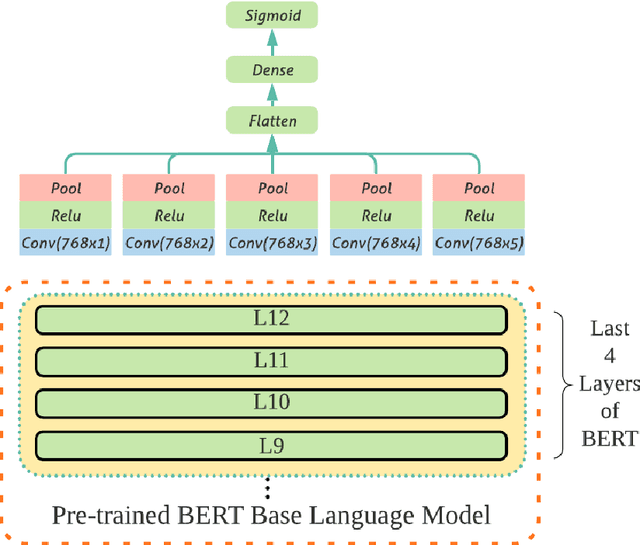
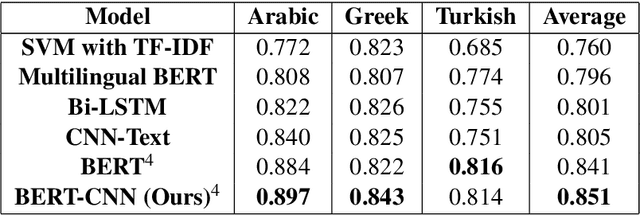
In this paper, we describe our approach to utilize pre-trained BERT models with Convolutional Neural Networks for sub-task A of the Multilingual Offensive Language Identification shared task (OffensEval 2020), which is a part of the SemEval 2020. We show that combining CNN with BERT is better than using BERT on its own, and we emphasize the importance of utilizing pre-trained language models for downstream tasks. Our system, ranked 4th with macro averaged F1-Score of 0.897 in Arabic, 4th with score of 0.843 in Greek, and 3rd with score of 0.814 in Turkish. Additionally, we present ArabicBERT, a set of pre-trained transformer language models for Arabic that we share with the community.
BiLingUNet: Image Segmentation by Modulating Top-Down and Bottom-Up Visual Processing with Referring Expressions
Mar 28, 2020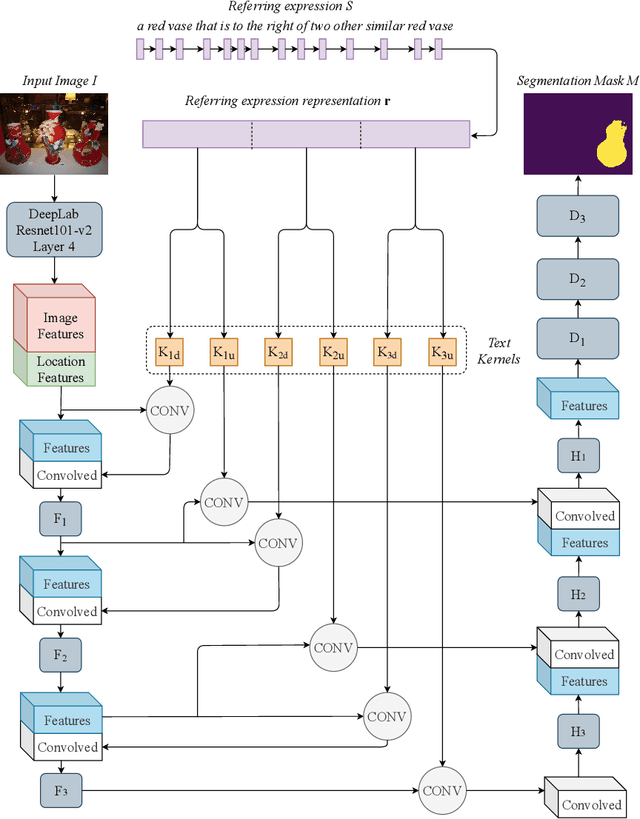
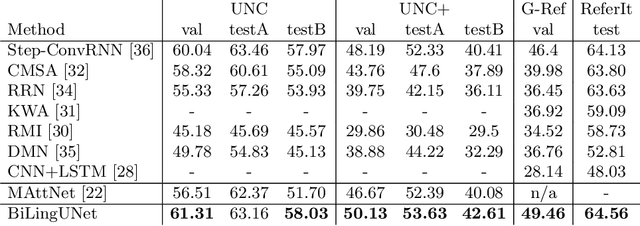
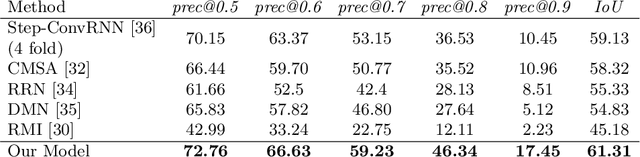

We present BiLingUNet, a state-of-the-art model for image segmentation using referring expressions. BiLingUNet uses language to customize visual filters and outperforms approaches that concatenate a linguistic representation to the visual input. We find that using language to modulate both bottom-up and top-down visual processing works better than just making the top-down processing language-conditional. We argue that common 1x1 language-conditional filters cannot represent relational concepts and experimentally demonstrate that wider filters work better. Our model achieves state-of-the-art performance on four referring expression datasets.
Learning from Implicit Information in Natural Language Instructions for Robotic Manipulations
Apr 30, 2019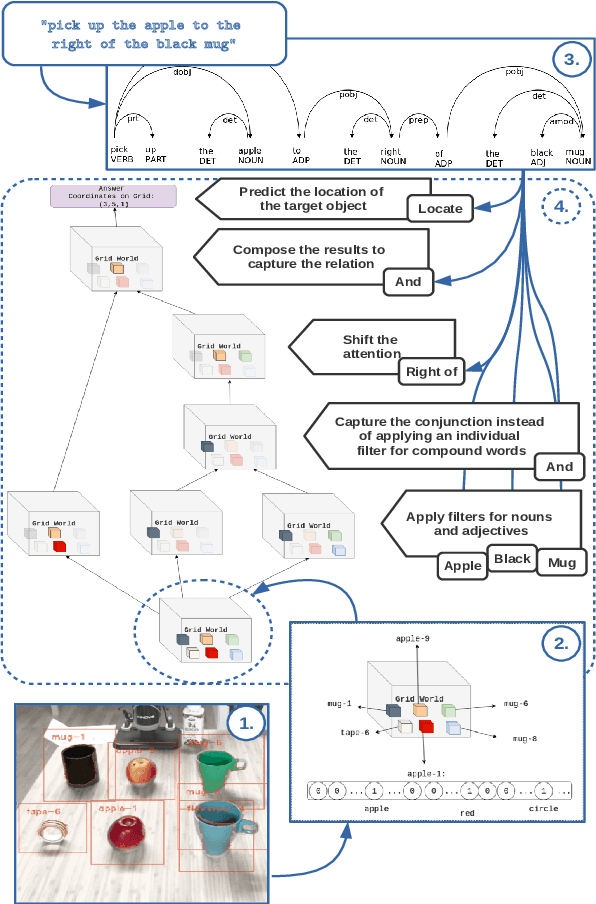
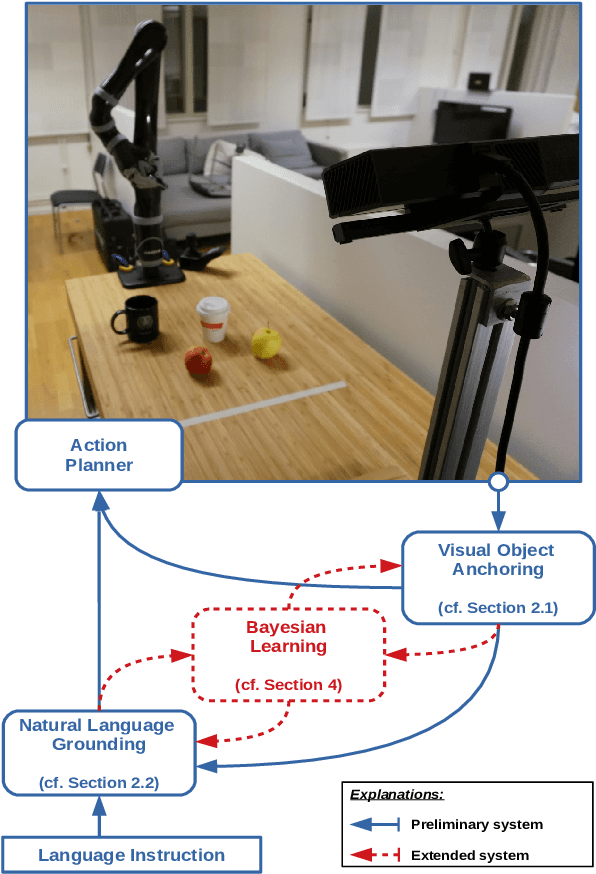
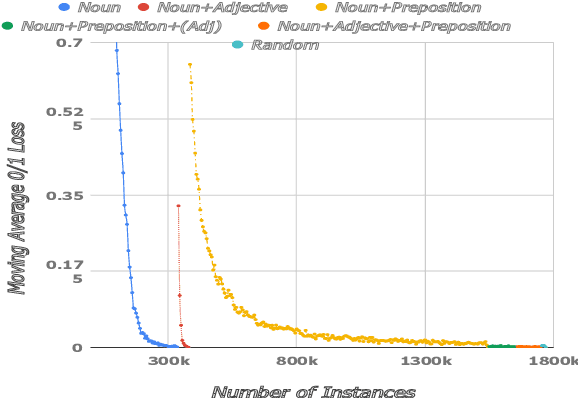

Human-robot interaction often occurs in the form of instructions given from a human to a robot. For a robot to successfully follow instructions, a common representation of the world and objects in it should be shared between humans and the robot so that the instructions can be grounded. Achieving this representation can be done via learning, where both the world representation and the language grounding are learned simultaneously. However, in robotics this can be a difficult task due to the cost and scarcity of data. In this paper, we tackle the problem by separately learning the world representation of the robot and the language grounding. While this approach can address the challenges in getting sufficient data, it may give rise to inconsistencies between both learned components. Therefore, we further propose Bayesian learning to resolve such inconsistencies between the natural language grounding and a robot's world representation by exploiting spatio-relational information that is implicitly present in instructions given by a human. Moreover, we demonstrate the feasibility of our approach on a scenario involving a robotic arm in the physical world.
A new dataset and model for learning to understand navigational instructions
May 21, 2018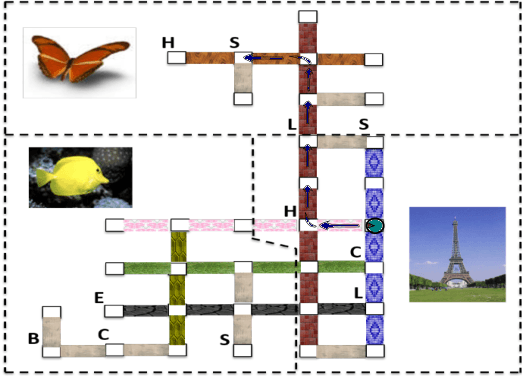
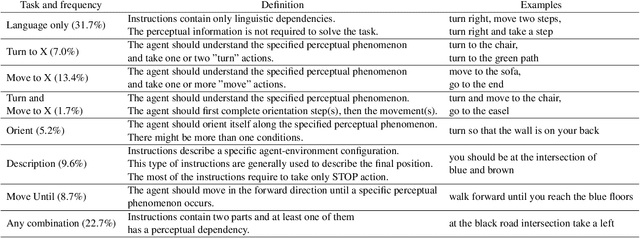
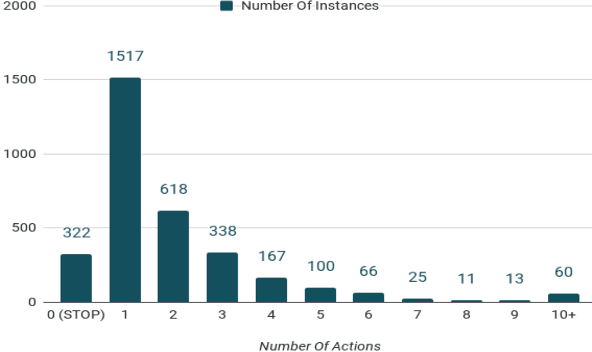
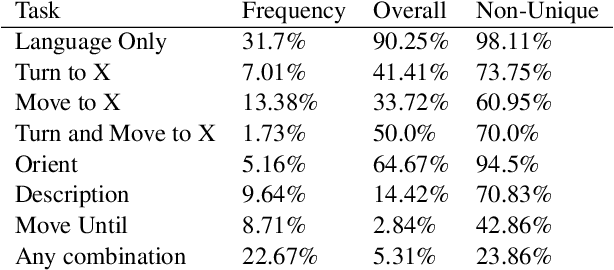
In this paper, we present a state-of-the-art model and introduce a new dataset for grounded language learning. Our goal is to develop a model that can learn to follow new instructions given prior instruction-perception-action examples. We based our work on the SAIL dataset which consists of navigational instructions and actions in a maze-like environment. The new model we propose achieves the best results to date on the SAIL dataset by using an improved perceptual component that can represent relative positions of objects. We also analyze the problems with the SAIL dataset regarding its size and balance. We argue that performance on a small, fixed-size dataset is no longer a good measure to differentiate state-of-the-art models. We introduce SAILx, a synthetic dataset generator, and perform experiments where the size and balance of the dataset are controlled.
MorphNet: A sequence-to-sequence model that combines morphological analysis and disambiguation
May 21, 2018
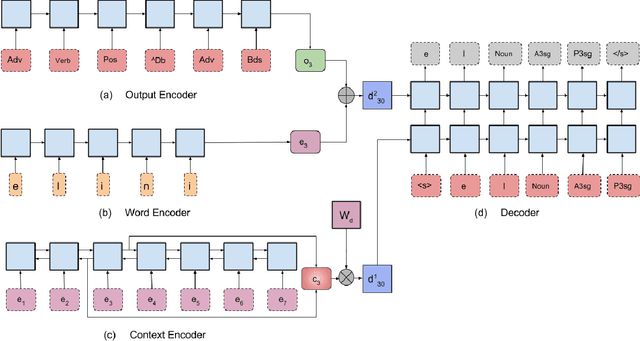
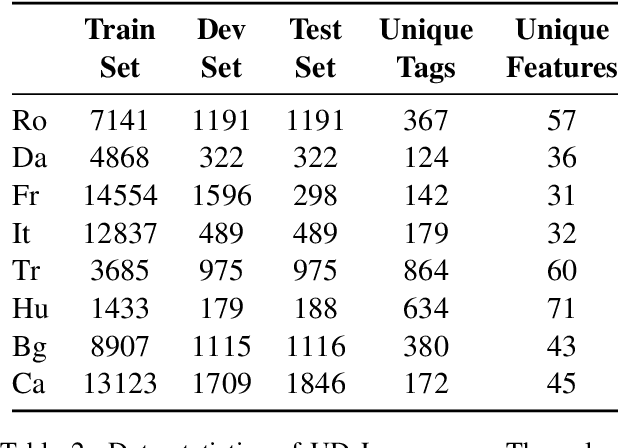
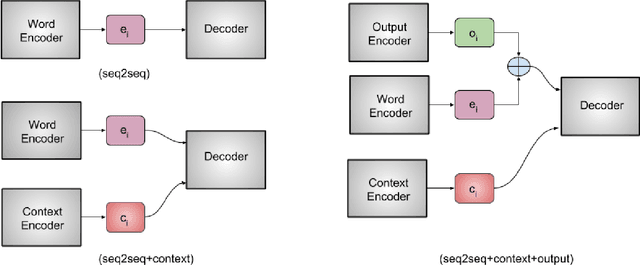
We introduce MorphNet, a single model that combines morphological analysis and disambiguation. Traditionally, analysis of morphologically complex languages has been performed in two stages: (i) A morphological analyzer based on finite-state transducers produces all possible morphological analyses of a word, (ii) A statistical disambiguation model picks the correct analysis based on the context for each word. MorphNet uses a sequence-to-sequence recurrent neural network to combine analysis and disambiguation. We show that when trained with text labeled with correct morphological analyses, MorphNet obtains state-of-the art or comparable results for nine different datasets in seven different languages.