 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHippocrates: An Open-Source Framework for Advancing Large Language Models in Healthcare
Apr 25, 2024



The integration of Large Language Models (LLMs) into healthcare promises to transform medical diagnostics, research, and patient care. Yet, the progression of medical LLMs faces obstacles such as complex training requirements, rigorous evaluation demands, and the dominance of proprietary models that restrict academic exploration. Transparent, comprehensive access to LLM resources is essential for advancing the field, fostering reproducibility, and encouraging innovation in healthcare AI. We present Hippocrates, an open-source LLM framework specifically developed for the medical domain. In stark contrast to previous efforts, it offers unrestricted access to its training datasets, codebase, checkpoints, and evaluation protocols. This open approach is designed to stimulate collaborative research, allowing the community to build upon, refine, and rigorously evaluate medical LLMs within a transparent ecosystem. Also, we introduce Hippo, a family of 7B models tailored for the medical domain, fine-tuned from Mistral and LLaMA2 through continual pre-training, instruction tuning, and reinforcement learning from human and AI feedback. Our models outperform existing open medical LLMs models by a large-margin, even surpassing models with 70B parameters. Through Hippocrates, we aspire to unlock the full potential of LLMs not just to advance medical knowledge and patient care but also to democratize the benefits of AI research in healthcare, making them available across the globe.
Detecting Euphemisms with Literal Descriptions and Visual Imagery
Nov 08, 2022

This paper describes our two-stage system for the Euphemism Detection shared task hosted by the 3rd Workshop on Figurative Language Processing in conjunction with EMNLP 2022. Euphemisms tone down expressions about sensitive or unpleasant issues like addiction and death. The ambiguous nature of euphemistic words or expressions makes it challenging to detect their actual meaning within a context. In the first stage, we seek to mitigate this ambiguity by incorporating literal descriptions into input text prompts to our baseline model. It turns out that this kind of direct supervision yields remarkable performance improvement. In the second stage, we integrate visual supervision into our system using visual imageries, two sets of images generated by a text-to-image model by taking terms and descriptions as input. Our experiments demonstrate that visual supervision also gives a statistically significant performance boost. Our system achieved the second place with an F1 score of 87.2%, only about 0.9% worse than the best submission.
BiLingUNet: Image Segmentation by Modulating Top-Down and Bottom-Up Visual Processing with Referring Expressions
Mar 28, 2020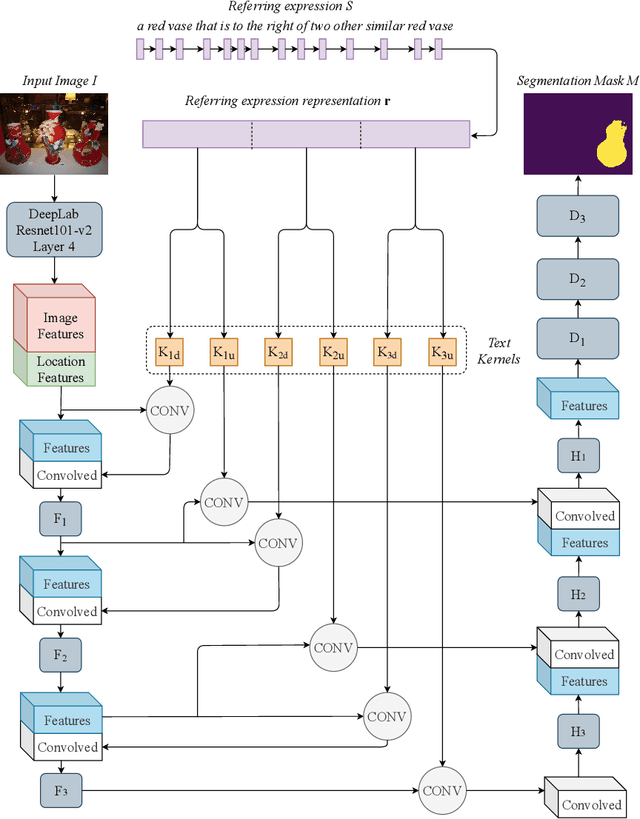
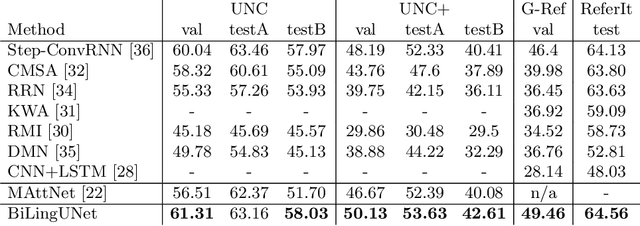
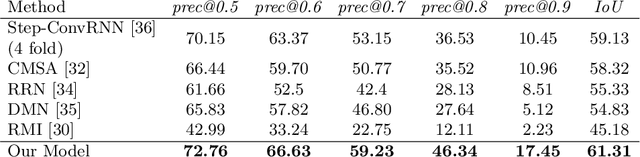

We present BiLingUNet, a state-of-the-art model for image segmentation using referring expressions. BiLingUNet uses language to customize visual filters and outperforms approaches that concatenate a linguistic representation to the visual input. We find that using language to modulate both bottom-up and top-down visual processing works better than just making the top-down processing language-conditional. We argue that common 1x1 language-conditional filters cannot represent relational concepts and experimentally demonstrate that wider filters work better. Our model achieves state-of-the-art performance on four referring expression datasets.