 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models
May 26, 2024



The availability of large-scale multimodal datasets and advancements in diffusion models have significantly accelerated progress in 4D content generation. Most prior approaches rely on multiple image or video diffusion models, utilizing score distillation sampling for optimization or generating pseudo novel views for direct supervision. However, these methods are hindered by slow optimization speeds and multi-view inconsistency issues. Spatial and temporal consistency in 4D geometry has been extensively explored respectively in 3D-aware diffusion models and traditional monocular video diffusion models. Building on this foundation, we propose a strategy to migrate the temporal consistency in video diffusion models to the spatial-temporal consistency required for 4D generation. Specifically, we present a novel framework, \textbf{Diffusion4D}, for efficient and scalable 4D content generation. Leveraging a meticulously curated dynamic 3D dataset, we develop a 4D-aware video diffusion model capable of synthesizing orbital views of dynamic 3D assets. To control the dynamic strength of these assets, we introduce a 3D-to-4D motion magnitude metric as guidance. Additionally, we propose a novel motion magnitude reconstruction loss and 3D-aware classifier-free guidance to refine the learning and generation of motion dynamics. After obtaining orbital views of the 4D asset, we perform explicit 4D construction with Gaussian splatting in a coarse-to-fine manner. The synthesized multi-view consistent 4D image set enables us to swiftly generate high-fidelity and diverse 4D assets within just several minutes. Extensive experiments demonstrate that our method surpasses prior state-of-the-art techniques in terms of generation efficiency and 4D geometry consistency across various prompt modalities.
OpenBias: Open-set Bias Detection in Text-to-Image Generative Models
Apr 11, 2024



Text-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments, it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However, existing works focus on detecting closed sets of biases defined a priori, limiting the studies to well-known concepts. In this paper, we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias, a new pipeline that identifies and quantifies the severity of biases agnostically, without access to any precompiled set. OpenBias has three stages. In the first phase, we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly, the target generative model produces images using the same set of captions. Lastly, a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5, 2, and XL emphasizing new biases, never investigated before. Via quantitative experiments, we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement.
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Apr 10, 2024

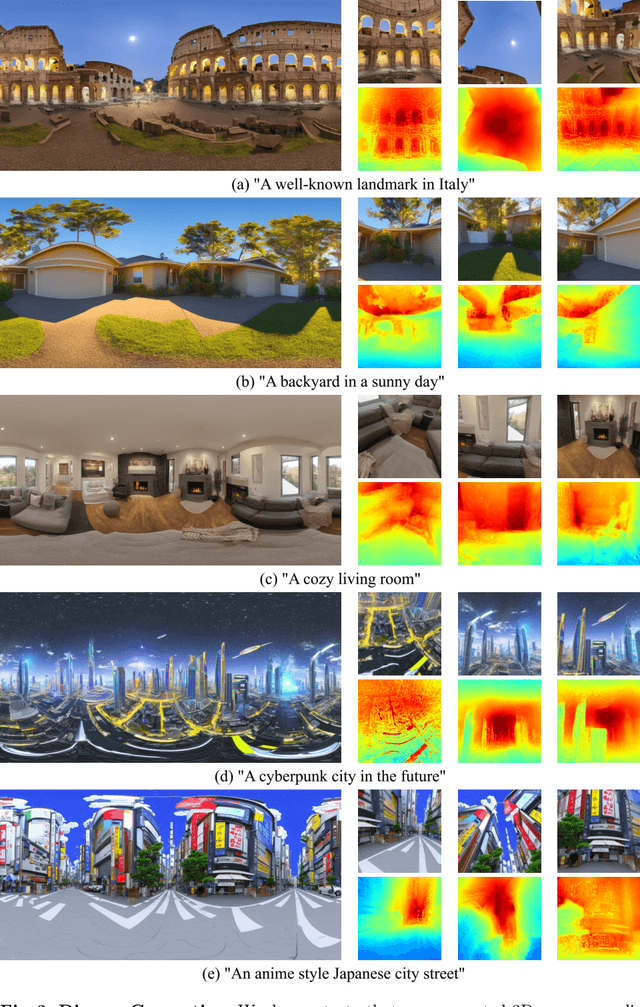

The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary "flat" (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
Comp4D: LLM-Guided Compositional 4D Scene Generation
Mar 25, 2024



Recent advancements in diffusion models for 2D and 3D content creation have sparked a surge of interest in generating 4D content. However, the scarcity of 3D scene datasets constrains current methodologies to primarily object-centric generation. To overcome this limitation, we present Comp4D, a novel framework for Compositional 4D Generation. Unlike conventional methods that generate a singular 4D representation of the entire scene, Comp4D innovatively constructs each 4D object within the scene separately. Utilizing Large Language Models (LLMs), the framework begins by decomposing an input text prompt into distinct entities and maps out their trajectories. It then constructs the compositional 4D scene by accurately positioning these objects along their designated paths. To refine the scene, our method employs a compositional score distillation technique guided by the pre-defined trajectories, utilizing pre-trained diffusion models across text-to-image, text-to-video, and text-to-3D domains. Extensive experiments demonstrate our outstanding 4D content creation capability compared to prior arts, showcasing superior visual quality, motion fidelity, and enhanced object interactions.
AGG: Amortized Generative 3D Gaussians for Single Image to 3D
Jan 08, 2024



Given the growing need for automatic 3D content creation pipelines, various 3D representations have been studied to generate 3D objects from a single image. Due to its superior rendering efficiency, 3D Gaussian splatting-based models have recently excelled in both 3D reconstruction and generation. 3D Gaussian splatting approaches for image to 3D generation are often optimization-based, requiring many computationally expensive score-distillation steps. To overcome these challenges, we introduce an Amortized Generative 3D Gaussian framework (AGG) that instantly produces 3D Gaussians from a single image, eliminating the need for per-instance optimization. Utilizing an intermediate hybrid representation, AGG decomposes the generation of 3D Gaussian locations and other appearance attributes for joint optimization. Moreover, we propose a cascaded pipeline that first generates a coarse representation of the 3D data and later upsamples it with a 3D Gaussian super-resolution module. Our method is evaluated against existing optimization-based 3D Gaussian frameworks and sampling-based pipelines utilizing other 3D representations, where AGG showcases competitive generation abilities both qualitatively and quantitatively while being several orders of magnitude faster. Project page: https://ir1d.github.io/AGG/
VASE: Object-Centric Appearance and Shape Manipulation of Real Videos
Jan 04, 2024Recently, several works tackled the video editing task fostered by the success of large-scale text-to-image generative models. However, most of these methods holistically edit the frame using the text, exploiting the prior given by foundation diffusion models and focusing on improving the temporal consistency across frames. In this work, we introduce a framework that is object-centric and is designed to control both the object's appearance and, notably, to execute precise and explicit structural modifications on the object. We build our framework on a pre-trained image-conditioned diffusion model, integrate layers to handle the temporal dimension, and propose training strategies and architectural modifications to enable shape control. We evaluate our method on the image-driven video editing task showing similar performance to the state-of-the-art, and showcasing novel shape-editing capabilities. Further details, code and examples are available on our project page: https://helia95.github.io/vase-website/
Taming Mode Collapse in Score Distillation for Text-to-3D Generation
Dec 31, 2023



Despite the remarkable performance of score distillation in text-to-3D generation, such techniques notoriously suffer from view inconsistency issues, also known as "Janus" artifact, where the generated objects fake each view with multiple front faces. Although empirically effective methods have approached this problem via score debiasing or prompt engineering, a more rigorous perspective to explain and tackle this problem remains elusive. In this paper, we reveal that the existing score distillation-based text-to-3D generation frameworks degenerate to maximal likelihood seeking on each view independently and thus suffer from the mode collapse problem, manifesting as the Janus artifact in practice. To tame mode collapse, we improve score distillation by re-establishing in entropy term in the corresponding variational objective, which is applied to the distribution of rendered images. Maximizing the entropy encourages diversity among different views in generated 3D assets, thereby mitigating the Janus problem. Based on this new objective, we derive a new update rule for 3D score distillation, dubbed Entropic Score Distillation (ESD). We theoretically reveal that ESD can be simplified and implemented by just adopting the classifier-free guidance trick upon variational score distillation. Although embarrassingly straightforward, our extensive experiments successfully demonstrate that ESD can be an effective treatment for Janus artifacts in score distillation.
SteinDreamer: Variance Reduction for Text-to-3D Score Distillation via Stein Identity
Dec 31, 2023



Score distillation has emerged as one of the most prevalent approaches for text-to-3D asset synthesis. Essentially, score distillation updates 3D parameters by lifting and back-propagating scores averaged over different views. In this paper, we reveal that the gradient estimation in score distillation is inherent to high variance. Through the lens of variance reduction, the effectiveness of SDS and VSD can be interpreted as applications of various control variates to the Monte Carlo estimator of the distilled score. Motivated by this rethinking and based on Stein's identity, we propose a more general solution to reduce variance for score distillation, termed Stein Score Distillation (SSD). SSD incorporates control variates constructed by Stein identity, allowing for arbitrary baseline functions. This enables us to include flexible guidance priors and network architectures to explicitly optimize for variance reduction. In our experiments, the overall pipeline, dubbed SteinDreamer, is implemented by instantiating the control variate with a monocular depth estimator. The results suggest that SSD can effectively reduce the distillation variance and consistently improve visual quality for both object- and scene-level generation. Moreover, we demonstrate that SteinDreamer achieves faster convergence than existing methods due to more stable gradient updates.
4DGen: Grounded 4D Content Generation with Spatial-temporal Consistency
Dec 28, 2023Aided by text-to-image and text-to-video diffusion models, existing 4D content creation pipelines utilize score distillation sampling to optimize the entire dynamic 3D scene. However, as these pipelines generate 4D content from text or image inputs, they incur significant time and effort in prompt engineering through trial and error. This work introduces 4DGen, a novel, holistic framework for grounded 4D content creation that decomposes the 4D generation task into multiple stages. We identify static 3D assets and monocular video sequences as key components in constructing the 4D content. Our pipeline facilitates conditional 4D generation, enabling users to specify geometry (3D assets) and motion (monocular videos), thus offering superior control over content creation. Furthermore, we construct our 4D representation using dynamic 3D Gaussians, which permits efficient, high-resolution supervision through rendering during training, thereby facilitating high-quality 4D generation. Additionally, we employ spatial-temporal pseudo labels on anchor frames, along with seamless consistency priors implemented through 3D-aware score distillation sampling and smoothness regularizations. Compared to existing baselines, our approach yields competitive results in faithfully reconstructing input signals and realistically inferring renderings from novel viewpoints and timesteps. Most importantly, our method supports grounded generation, offering users enhanced control, a feature difficult to achieve with previous methods. Project page: https://vita-group.github.io/4DGen/
LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS
Dec 07, 2023



Recent advancements in real-time neural rendering using point-based techniques have paved the way for the widespread adoption of 3D representations. However, foundational approaches like 3D Gaussian Splatting come with a substantial storage overhead caused by growing the SfM points to millions, often demanding gigabyte-level disk space for a single unbounded scene, posing significant scalability challenges and hindering the splatting efficiency. To address this challenge, we introduce LightGaussian, a novel method designed to transform 3D Gaussians into a more efficient and compact format. Drawing inspiration from the concept of Network Pruning, LightGaussian identifies Gaussians that are insignificant in contributing to the scene reconstruction and adopts a pruning and recovery process, effectively reducing redundancy in Gaussian counts while preserving visual effects. Additionally, LightGaussian employs distillation and pseudo-view augmentation to distill spherical harmonics to a lower degree, allowing knowledge transfer to more compact representations while maintaining reflectance. Furthermore, we propose a hybrid scheme, VecTree Quantization, to quantize all attributes, resulting in lower bitwidth representations with minimal accuracy losses. In summary, LightGaussian achieves an averaged compression rate over 15x while boosting the FPS from 139 to 215, enabling an efficient representation of complex scenes on Mip-NeRF 360, Tank and Temple datasets. Project website: https://lightgaussian.github.io/