 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Masking Generative Network: A Unified Framework for Background Restoration from Superimposed Images
Oct 09, 2020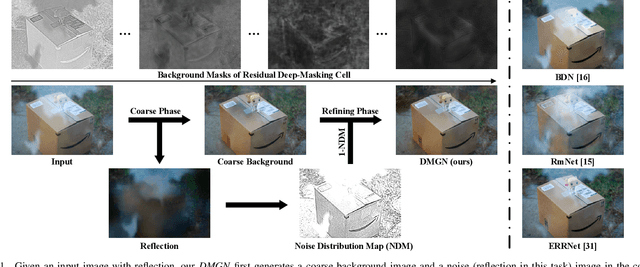


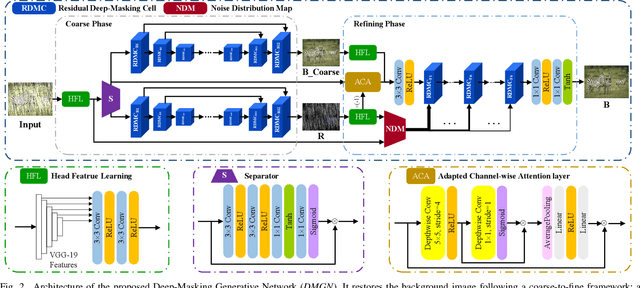
Restoring the clean background from the superimposed images containing a noisy layer is the common crux of a classical category of tasks on image restoration such as image reflection removal, image deraining and image dehazing. These tasks are typically formulated and tackled individually due to the diverse and complicated appearance patterns of noise layers within the image. In this work we present the Deep-Masking Generative Network (DMGN), which is a unified framework for background restoration from the superimposed images and is able to cope with different types of noise. Our proposed DMGN follows a coarse-to-fine generative process: a coarse background image and a noise image are first generated in parallel, then the noise image is further leveraged to refine the background image to achieve a higher-quality background image. In particular, we design the novel Residual Deep-Masking Cell as the core operating unit for our DMGN to enhance the effective information and suppress the negative information during image generation via learning a gating mask to control the information flow. By iteratively employing this Residual Deep-Masking Cell, our proposed DMGN is able to generate both high-quality background image and noisy image progressively. Furthermore, we propose a two-pronged strategy to effectively leverage the generated noise image as contrasting cues to facilitate the refinement of the background image. Extensive experiments across three typical tasks for image background restoration, including image reflection removal, image rain steak removal and image dehazing, show that our DMGN consistently outperforms state-of-the-art methods specifically designed for each single task.
Embedding-based Retrieval in Facebook Search
Jul 29, 2020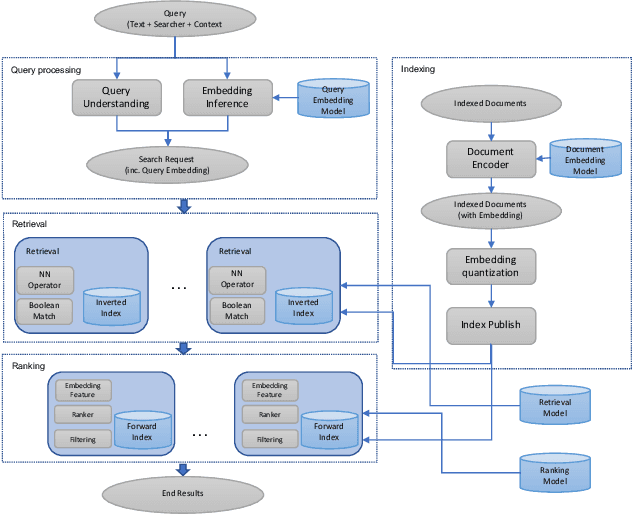

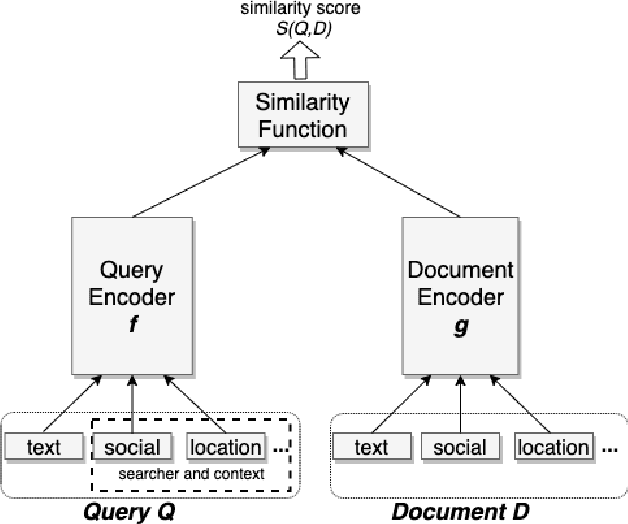
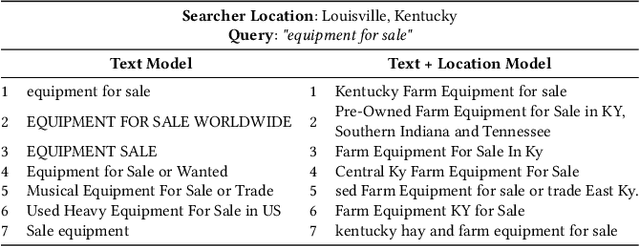
Search in social networks such as Facebook poses different challenges than in classical web search: besides the query text, it is important to take into account the searcher's context to provide relevant results. Their social graph is an integral part of this context and is a unique aspect of Facebook search. While embedding-based retrieval (EBR) has been applied in eb search engines for years, Facebook search was still mainly based on a Boolean matching model. In this paper, we discuss the techniques for applying EBR to a Facebook Search system. We introduce the unified embedding framework developed to model semantic embeddings for personalized search, and the system to serve embedding-based retrieval in a typical search system based on an inverted index. We discuss various tricks and experiences on end-to-end optimization of the whole system, including ANN parameter tuning and full-stack optimization. Finally, we present our progress on two selected advanced topics about modeling. We evaluated EBR on verticals for Facebook Search with significant metrics gains observed in online A/B experiments. We believe this paper will provide useful insights and experiences to help people on developing embedding-based retrieval systems in search engines.
Designing and Training of A Dual CNN for Image Denoising
Jul 08, 2020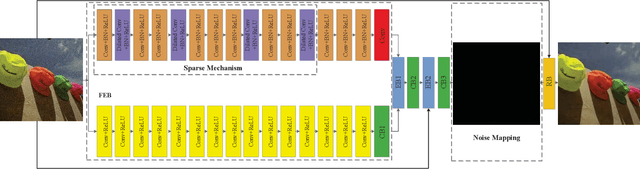



Deep convolutional neural networks (CNNs) for image denoising have recently attracted increasing research interest. However, plain networks cannot recover fine details for a complex task, such as real noisy images. In this paper, we propsoed a Dual denoising Network (DudeNet) to recover a clean image. Specifically, DudeNet consists of four modules: a feature extraction block, an enhancement block, a compression block, and a reconstruction block. The feature extraction block with a sparse machanism extracts global and local features via two sub-networks. The enhancement block gathers and fuses the global and local features to provide complementary information for the latter network. The compression block refines the extracted information and compresses the network. Finally, the reconstruction block is utilized to reconstruct a denoised image. The DudeNet has the following advantages: (1) The dual networks with a parse mechanism can extract complementary features to enhance the generalized ability of denoiser. (2) Fusing global and local features can extract salient features to recover fine details for complex noisy images. (3) A Small-size filter is used to reduce the complexity of denoiser. Extensive experiments demonstrate the superiority of DudeNet over existing current state-of-the-art denoising methods.
Learning Context-Based Non-local Entropy Modeling for Image Compression
May 10, 2020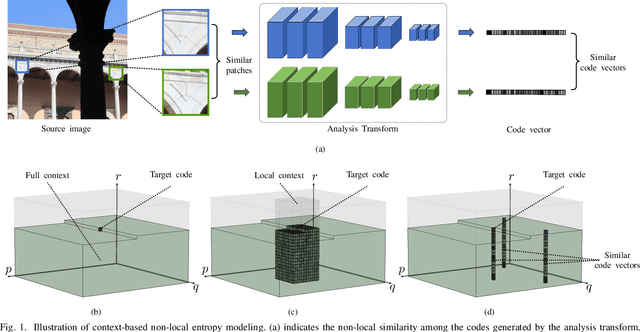
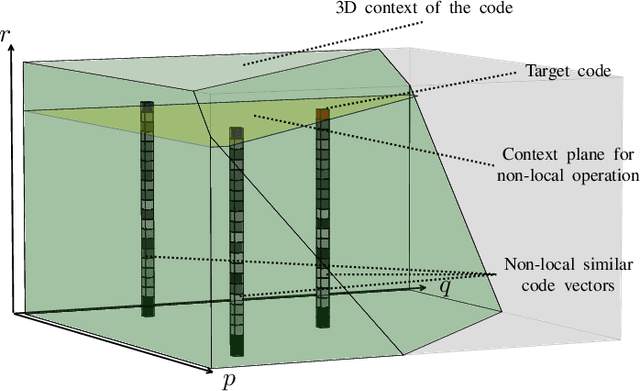
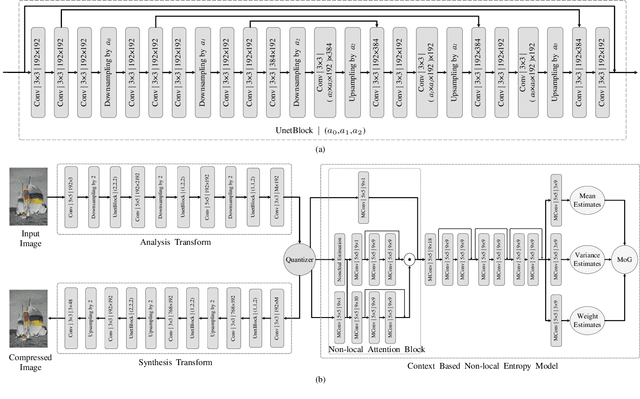
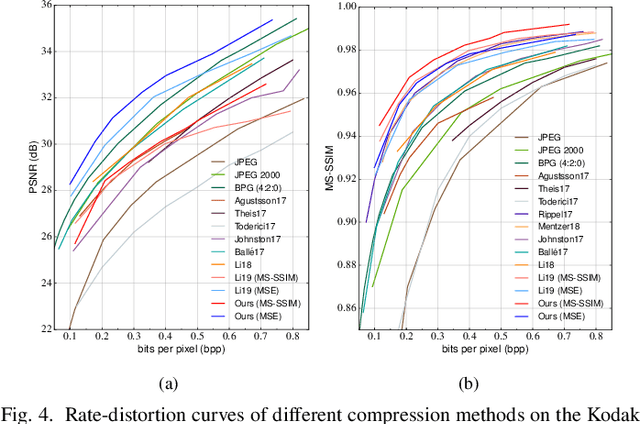
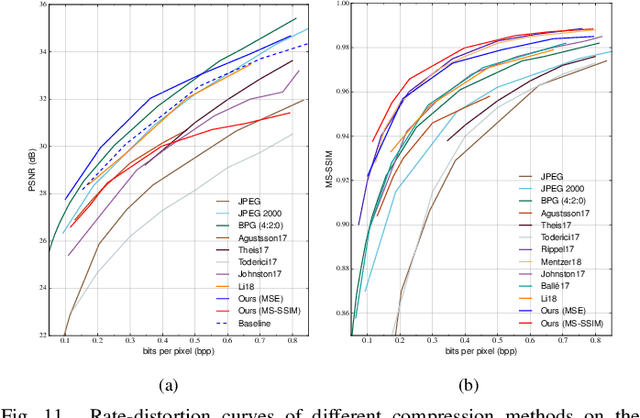
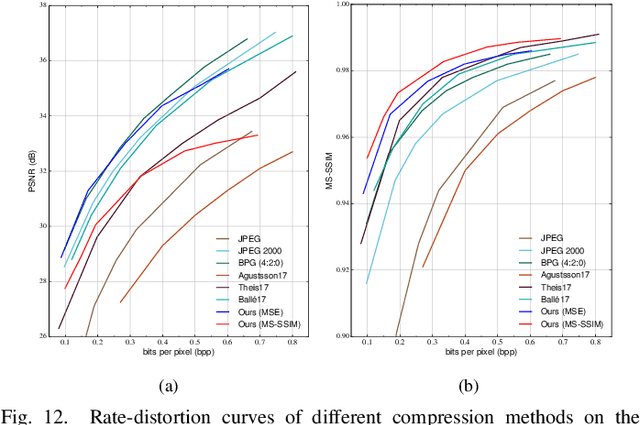
The entropy of the codes usually serves as the rate loss in the recent learned lossy image compression methods. Precise estimation of the probabilistic distribution of the codes plays a vital role in the performance. However, existing deep learning based entropy modeling methods generally assume the latent codes are statistically independent or depend on some side information or local context, which fails to take the global similarity within the context into account and thus hinder the accurate entropy estimation. To address this issue, we propose a non-local operation for context modeling by employing the global similarity within the context. Specifically, we first introduce the proxy similarity functions and spatial masks to handle the missing reference problem in context modeling. Then, we combine the local and the global context via a non-local attention block and employ it in masked convolutional networks for entropy modeling. The entropy model is further adopted as the rate loss in a joint rate-distortion optimization to guide the training of the analysis transform and the synthesis transform network in transforming coding framework. Considering that the width of the transforms is essential in training low distortion models, we finally produce a U-Net block in the transforms to increase the width with manageable memory consumption and time complexity. Experiments on Kodak and Tecnick datasets demonstrate the superiority of the proposed context-based non-local attention block in entropy modeling and the U-Net block in low distortion compression against the existing image compression standards and recent deep image compression models.
Biometric Recognition Using Deep Learning: A Survey
Nov 30, 2019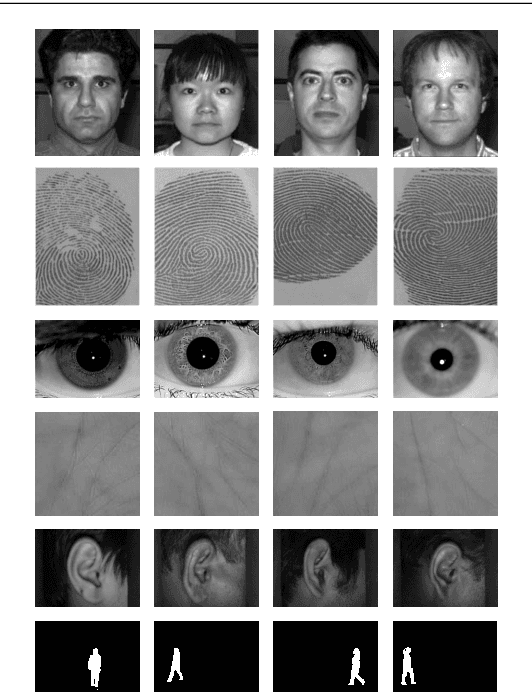
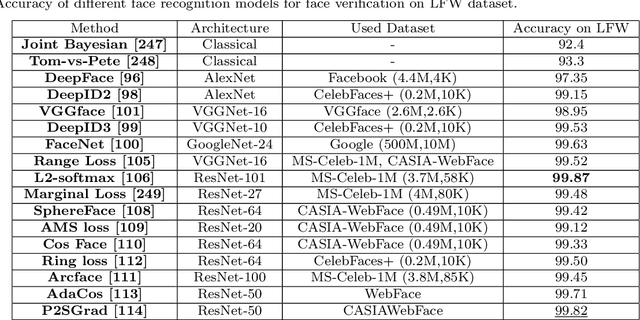
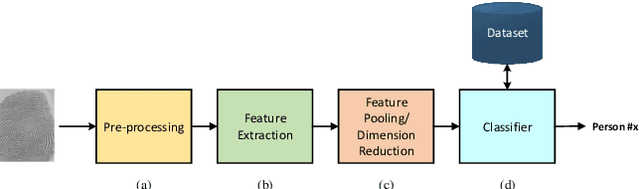
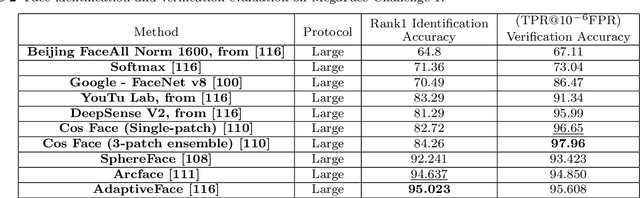
Deep learning-based models have been very successful in achieving state-of-the-art results in many of the computer vision, speech recognition, and natural language processing tasks in the last few years. These models seem a natural fit for handling the ever-increasing scale of biometric recognition problems, from cellphone authentication to airport security systems. Deep learning-based models have increasingly been leveraged to improve the accuracy of different biometric recognition systems in recent years. In this work, we provide a comprehensive survey of more than 120 promising works on biometric recognition (including face, fingerprint, iris, palmprint, ear, voice, signature, and gait recognition), which deploy deep learning models, and show their strengths and potentials in different applications. For each biometric, we first introduce the available datasets that are widely used in the literature and their characteristics. We will then talk about several promising deep learning works developed for that biometric, and show their performance on popular public benchmarks. We will also discuss some of the main challenges while using these models for biometric recognition, and possible future directions to which research in this area is headed.
Bit Efficient Quantization for Deep Neural Networks
Oct 07, 2019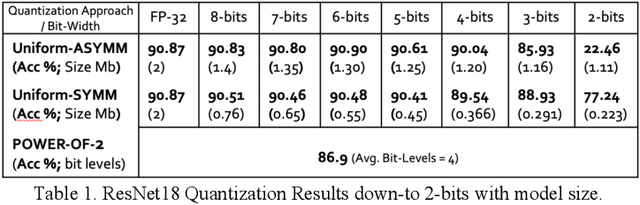
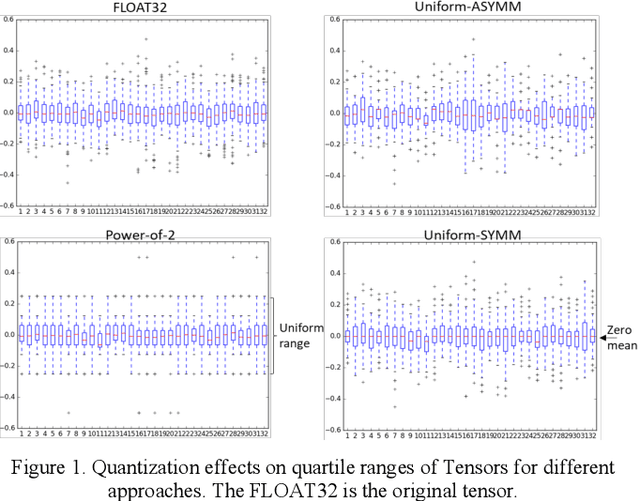
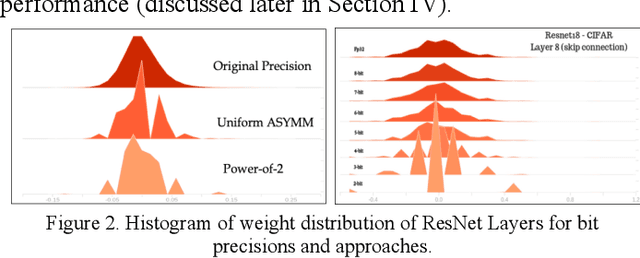

Quantization for deep neural networks have afforded models for edge devices that use less on-board memory and enable efficient low-power inference. In this paper, we present a comparison of model-parameter driven quantization approaches that can achieve as low as 3-bit precision without affecting accuracy. The post-training quantization approaches are data-free, and the resulting weight values are closely tied to the dataset distribution on which the model has converged to optimality. We show quantization results for a number of state-of-art deep neural networks (DNN) using large dataset like ImageNet. To better analyze quantization results, we describe the overall range and local sparsity of values afforded through various quantization schemes. We show the methods to lower bit-precision beyond quantization limits with object class clustering.
Non-negative Sparse and Collaborative Representation for Pattern Classification
Aug 29, 2019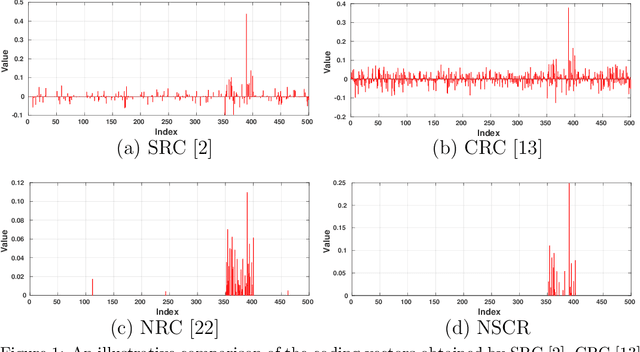


Sparse representation (SR) and collaborative representation (CR) have been successfully applied in many pattern classification tasks such as face recognition. In this paper, we propose a novel Non-negative Sparse and Collaborative Representation (NSCR) for pattern classification. The NSCR representation of each test sample is obtained by seeking a non-negative sparse and collaborative representation vector that represents the test sample as a linear combination of training samples. We observe that the non-negativity can make the SR and CR more discriminative and effective for pattern classification. Based on the proposed NSCR, we propose a NSCR based classifier for pattern classification. Extensive experiments on benchmark datasets demonstrate that the proposed NSCR based classifier outperforms the previous SR or CR based approach, as well as state-of-the-art deep approaches, on diverse challenging pattern classification tasks.
Efficient and Effective Context-Based Convolutional Entropy Modeling for Image Compression
Jun 24, 2019
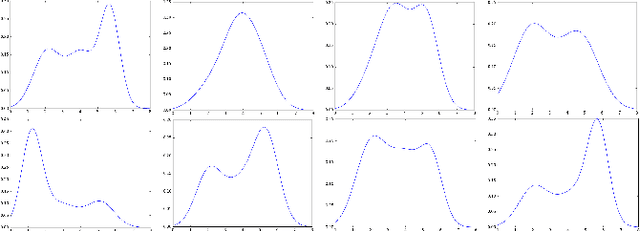
It has long been understood that precisely estimating the probabilistic structure of natural visual images is crucial for image compression. Despite the remarkable success of recent end-to-end optimized image compression, the latent code representation is assumed to be fully statistically factorized such that the entropy modeling is feasible. Here we describe context-based convolutional networks (CCNs) that exploit statistical redundancies in the codes for improved entropy modeling. We introduce a 3D zigzag coding order together with a 3D code dividing technique to define proper context and to achieve parallel entropy decoding, both of which boil down to place translation-invariant binary masks on convolution filters of CCNs. We demonstrate the power of CCNs for entropy modeling in both lossless and lossy image compression. For the former, we directly apply a CCN to binarized image planes for estimating the Bernoulli distribution of each code. For the latter, the categorical distribution of each code is represented by a discretized mixture of Gaussian distributions, whose parameters are estimated by three CCNs. We jointly optimize the CCN-based entropy model with analysis and synthesis transforms for rate-distortion performance. Experiments on two image datasets show that the proposed lossless and lossy image compression methods based on CCNs generally exhibit better compression performance than existing methods with manageable computational complexity.
Remove Cosine Window from Correlation Filter-based Visual Trackers: When and How
May 16, 2019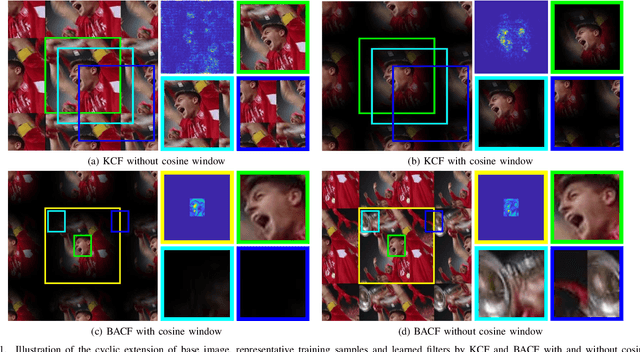
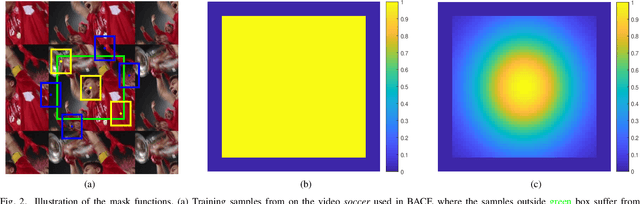
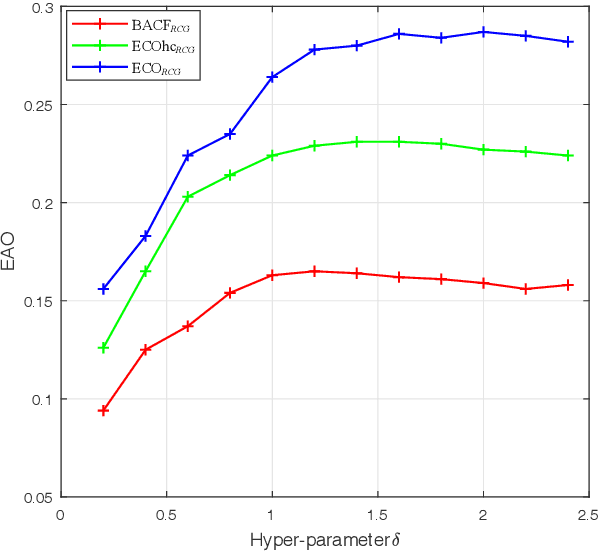
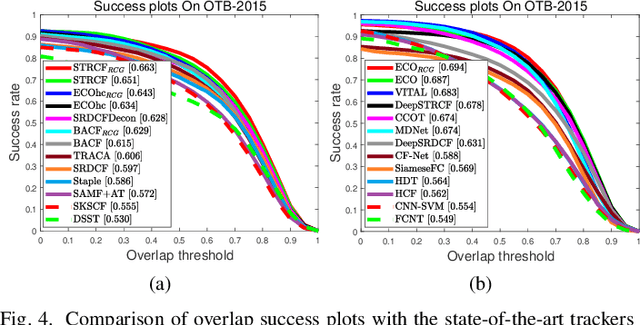
Correlation filters (CFs) have been continuously advancing the state-of-the-art tracking performance and have been extensively studied in the recent few years. Most of the existing CF trackers adopt a cosine window to spatially reweight base image to alleviate boundary discontinuity. However, cosine window emphasizes more on the central region of base image and has the risk of contaminating negative training samples during model learning. On the other hand, spatial regularization deployed in many recent CF trackers plays a similar role as cosine window by enforcing spatial penalty on CF coefficients. Therefore, we in this paper investigate the feasibility to remove cosine window from CF trackers with spatial regularization. When simply removing cosine window, CF with spatial regularization still suffers from small degree of boundary discontinuity. To tackle this issue, binary and Gaussian shaped mask functions are further introduced for eliminating boundary discontinuity while reweighting the estimation error of each training sample, and can be incorporated with multiple CF trackers with spatial regularization. In comparison to the counterparts with cosine window, our methods are effective in handling boundary discontinuity and sample contamination, thereby benefiting tracking performance. Extensive experiments on three benchmarks show that our methods perform favorably against the state-of-the-art trackers using either handcrafted or deep CNN features. The code is publicly available at https://github.com/lifeng9472/Removing_cosine_window_from_CF_trackers.
Learning Content-Weighted Deep Image Compression
Apr 01, 2019
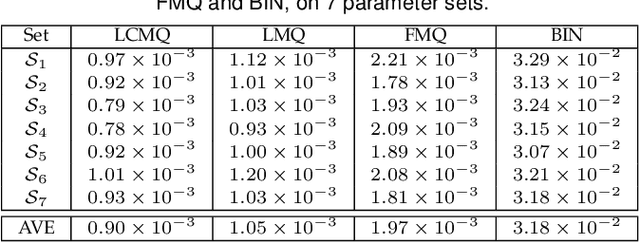
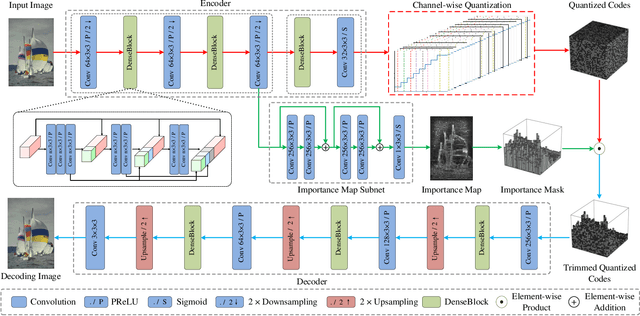
Learning-based lossy image compression usually involves the joint optimization of rate-distortion performance. Most existing methods adopt spatially invariant bit length allocation and incorporate discrete entropy approximation to constrain compression rate. Nonetheless, the information content is spatially variant, where the regions with complex and salient structures generally are more essential to image compression. Taking the spatial variation of image content into account, this paper presents a content-weighted encoder-decoder model, which involves an importance map subnet to produce the importance mask for locally adaptive bit rate allocation. Consequently, the summation of importance mask can thus be utilized as an alternative of entropy estimation for compression rate control. Furthermore, the quantized representations of the learned code and importance map are still spatially dependent, which can be losslessly compressed using arithmetic coding. To compress the codes effectively and efficiently, we propose a trimmed convolutional network to predict the conditional probability of quantized codes. Experiments show that the proposed method can produce visually much better results, and performs favorably in comparison with deep and traditional lossy image compression approaches.