 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization in Task-oriented Dialogues with Workflows and Action Plans
Jun 02, 2023



Task-oriented dialogue is difficult in part because it involves understanding user intent, collecting information from the user, executing API calls, and generating helpful and fluent responses. However, for complex tasks one must also correctly do all of these things over multiple steps, and in a specific order. While large pre-trained language models can be fine-tuned end-to-end to create multi-step task-oriented dialogue agents that generate fluent text, our experiments confirm that this approach alone cannot reliably perform new multi-step tasks that are unseen during training. To address these limitations, we augment the dialogue contexts given to \textmd{text2text} transformers with known \textit{valid workflow names} and \textit{action plans}. Action plans consist of sequences of actions required to accomplish a task, and are encoded as simple sequences of keywords (e.g. verify-identity, pull-up-account, reset-password, etc.). We perform extensive experiments on the Action-Based Conversations Dataset (ABCD) with T5-small, base and large models, and show that such models: a) are able to more readily generalize to unseen workflows by following the provided plan, and b) are able to generalize to executing unseen actions if they are provided in the plan. In contrast, models are unable to fully accomplish new multi-step tasks when they are not provided action plan information, even when given new valid workflow names.
Long-Context Language Decision Transformers and Exponential Tilt for Interactive Text Environments
Feb 10, 2023



Text-based game environments are challenging because agents must deal with long sequences of text, execute compositional actions using text and learn from sparse rewards. We address these challenges by proposing Long-Context Language Decision Transformers (LLDTs), a framework that is based on long transformer language models and decision transformers (DTs). LLDTs extend DTs with 3 components: (1) exponential tilt to guide the agent towards high obtainable goals, (2) novel goal conditioning methods yielding significantly better results than the traditional return-to-go (sum of all future rewards), and (3) a model of future observations. Our ablation results show that predicting future observations improves agent performance. To the best of our knowledge, LLDTs are the first to address offline RL with DTs on these challenging games. Our experiments show that LLDTs achieve the highest scores among many different types of agents on some of the most challenging Jericho games, such as Enchanter.
3rd Continual Learning Workshop Challenge on Egocentric Category and Instance Level Object Understanding
Dec 13, 2022



Continual Learning, also known as Lifelong or Incremental Learning, has recently gained renewed interest among the Artificial Intelligence research community. Recent research efforts have quickly led to the design of novel algorithms able to reduce the impact of the catastrophic forgetting phenomenon in deep neural networks. Due to this surge of interest in the field, many competitions have been held in recent years, as they are an excellent opportunity to stimulate research in promising directions. This paper summarizes the ideas, design choices, rules, and results of the challenge held at the 3rd Continual Learning in Computer Vision (CLVision) Workshop at CVPR 2022. The focus of this competition is the complex continual object detection task, which is still underexplored in literature compared to classification tasks. The challenge is based on the challenge version of the novel EgoObjects dataset, a large-scale egocentric object dataset explicitly designed to benchmark continual learning algorithms for egocentric category-/instance-level object understanding, which covers more than 1k unique main objects and 250+ categories in around 100k video frames.
Towards good validation metrics for generative models in offline model-based optimisation
Nov 19, 2022In this work we propose a principled evaluation framework for model-based optimisation to measure how well a generative model can extrapolate. We achieve this by interpreting the training and validation splits as draws from their respective `truncated' ground truth distributions, where examples in the validation set contain scores much larger than those in the training set. Model selection is performed on the validation set for some prescribed validation metric. A major research question however is in determining what validation metric correlates best with the expected value of generated candidates with respect to the ground truth oracle; work towards answering this question can translate to large economic gains since it is expensive to evaluate the ground truth oracle in the real world. We compare various validation metrics for generative adversarial networks using our framework. We also discuss limitations with our framework with respect to existing datasets and how progress can be made to mitigate them.
Flaky Performances when Pretraining on Relational Databases
Nov 09, 2022We explore the downstream task performances for graph neural network (GNN) self-supervised learning (SSL) methods trained on subgraphs extracted from relational databases (RDBs). Intuitively, this joint use of SSL and GNNs should allow to leverage more of the available data, which could translate to better results. However, we found that naively porting contrastive SSL techniques can cause ``negative transfer'': linear evaluation on fixed representations from a pretrained model performs worse than on representations from the randomly-initialized model. Based on the conjecture that contrastive SSL conflicts with the message passing layers of the GNN, we propose InfoNode: a contrastive loss aiming to maximize the mutual information between a node's initial- and final-layer representation. The primary empirical results support our conjecture and the effectiveness of InfoNode.
OCR-VQGAN: Taming Text-within-Image Generation
Oct 19, 2022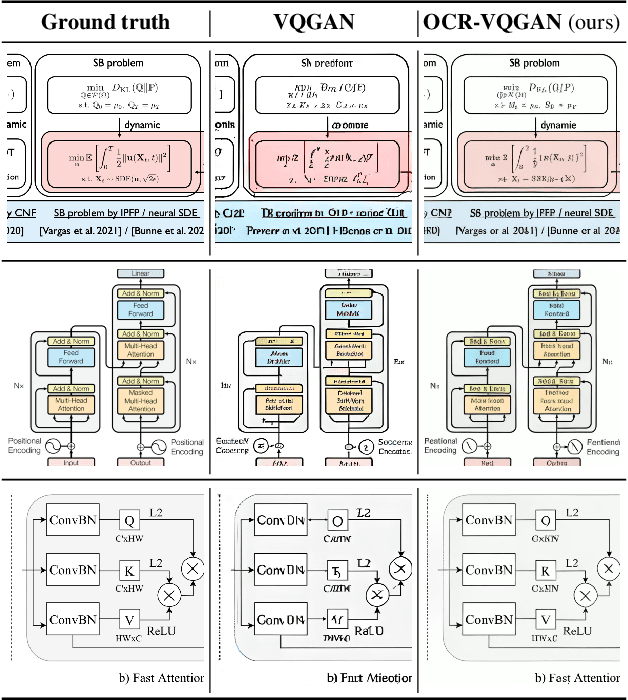
Synthetic image generation has recently experienced significant improvements in domains such as natural image or art generation. However, the problem of figure and diagram generation remains unexplored. A challenging aspect of generating figures and diagrams is effectively rendering readable texts within the images. To alleviate this problem, we present OCR-VQGAN, an image encoder, and decoder that leverages OCR pre-trained features to optimize a text perceptual loss, encouraging the architecture to preserve high-fidelity text and diagram structure. To explore our approach, we introduce the Paper2Fig100k dataset, with over 100k images of figures and texts from research papers. The figures show architecture diagrams and methodologies of articles available at arXiv.org from fields like artificial intelligence and computer vision. Figures usually include text and discrete objects, e.g., boxes in a diagram, with lines and arrows that connect them. We demonstrate the effectiveness of OCR-VQGAN by conducting several experiments on the task of figure reconstruction. Additionally, we explore the qualitative and quantitative impact of weighting different perceptual metrics in the overall loss function. We release code, models, and dataset at https://github.com/joanrod/ocr-vqgan.
CADet: Fully Self-Supervised Anomaly Detection With Contrastive Learning
Oct 04, 2022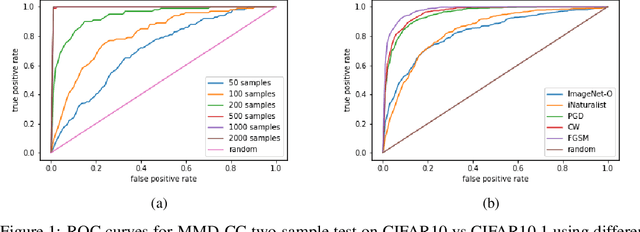
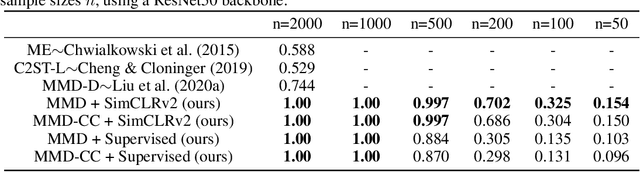

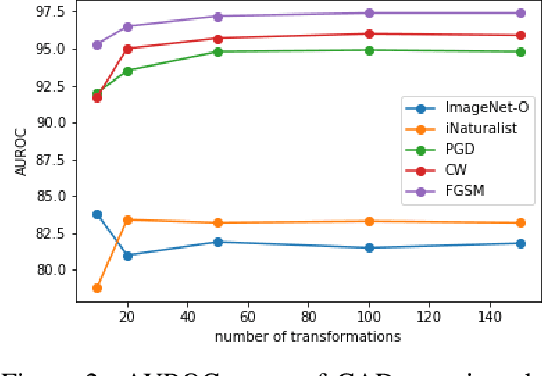
Handling out-of-distribution (OOD) samples has become a major stake in the real-world deployment of machine learning systems. This work explores the application of self-supervised contrastive learning to the simultaneous detection of two types of OOD samples: unseen classes and adversarial perturbations. Since in practice the distribution of such samples is not known in advance, we do not assume access to OOD examples. We show that similarity functions trained with contrastive learning can be leveraged with the maximum mean discrepancy (MMD) two-sample test to verify whether two independent sets of samples are drawn from the same distribution. Inspired by this approach, we introduce CADet (Contrastive Anomaly Detection), a method based on image augmentations to perform anomaly detection on single samples. CADet compares favorably to adversarial detection methods to detect adversarially perturbed samples on ImageNet. Simultaneously, it achieves comparable performance to unseen label detection methods on two challenging benchmarks: ImageNet-O and iNaturalist. CADet is fully self-supervised and requires neither labels for in-distribution samples nor access to OOD examples.
Constraining Representations Yields Models That Know What They Don't Know
Aug 30, 2022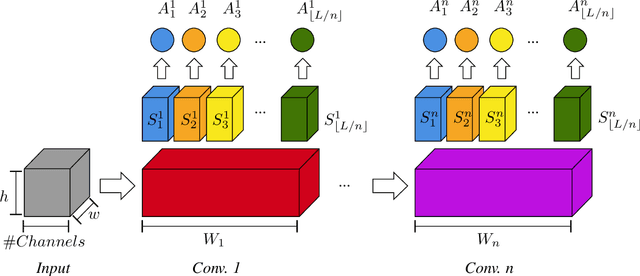

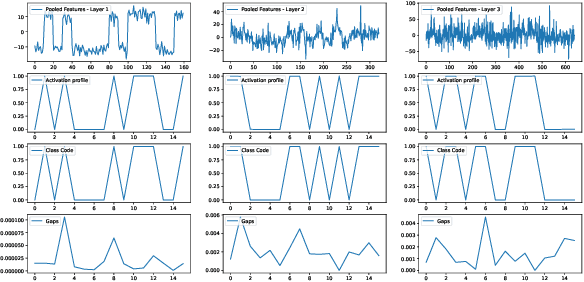
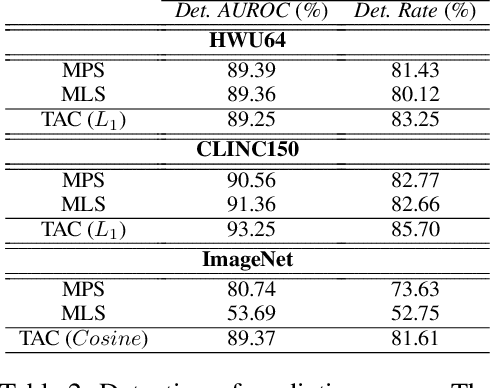
A well-known failure mode of neural networks corresponds to high confidence erroneous predictions, especially for data that somehow differs from the training distribution. Such an unsafe behaviour limits their applicability. To counter that, we show that models offering accurate confidence levels can be defined via adding constraints in their internal representations. That is, we encode class labels as fixed unique binary vectors, or class codes, and use those to enforce class-dependent activation patterns throughout the model. Resulting predictors are dubbed Total Activation Classifiers (TAC), and TAC is used as an additional component to a base classifier to indicate how reliable a prediction is. Given a data instance, TAC slices intermediate representations into disjoint sets and reduces such slices into scalars, yielding activation profiles. During training, activation profiles are pushed towards the code assigned to a given training instance. At testing time, one can predict the class corresponding to the code that best matches the activation profile of an example. Empirically, we observe that the resemblance between activation patterns and their corresponding codes results in an inexpensive unsupervised approach for inducing discriminative confidence scores. Namely, we show that TAC is at least as good as state-of-the-art confidence scores extracted from existing models, while strictly improving the model's value on the rejection setting. TAC was also observed to work well on multiple types of architectures and data modalities.
Workflow Discovery from Dialogues in the Low Data Regime
May 24, 2022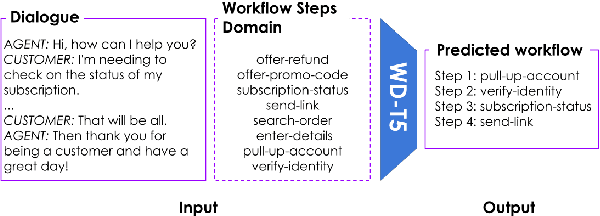

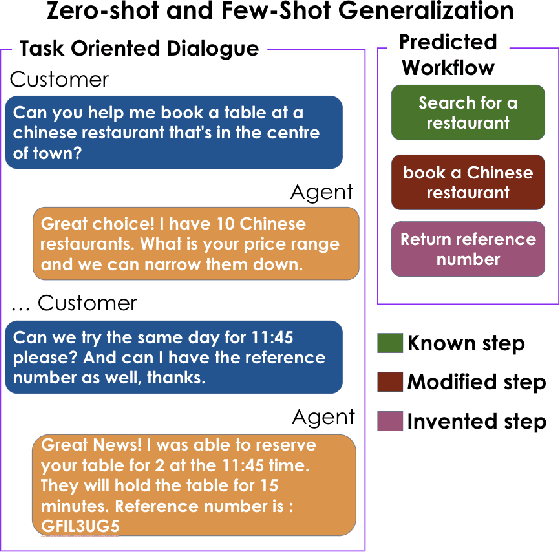

Text-based dialogues are now widely used to solve real-world problems. In cases where solution strategies are already known, they can sometimes be codified into workflows and used to guide humans or artificial agents through the task of helping clients. We are interested in the situation where a formal workflow may not yet exist, but we wish to discover the steps of actions that have been taken to resolve problems. We examine a novel transformer-based approach for this situation and we present experiments where we summarize dialogues in the Action-Based Conversations Dataset (ABCD) with workflows. Since the ABCD dialogues were generated using known workflows to guide agents we can evaluate our ability to extract such workflows using ground truth sequences of action steps, organized as workflows. We propose and evaluate an approach that conditions models on the set of allowable action steps and we show that using this strategy we can improve workflow discovery (WD) performance. Our conditioning approach also improves zero-shot and few-shot WD performance when transferring learned models to entirely new domains (i.e. the MultiWOZ setting). Further, a modified variant of our architecture achieves state-of-the-art performance on the related but different problems of Action State Tracking (AST) and Cascading Dialogue Success (CDS) on the ABCD.
Data Augmentation for Intent Classification with Off-the-shelf Large Language Models
Apr 05, 2022
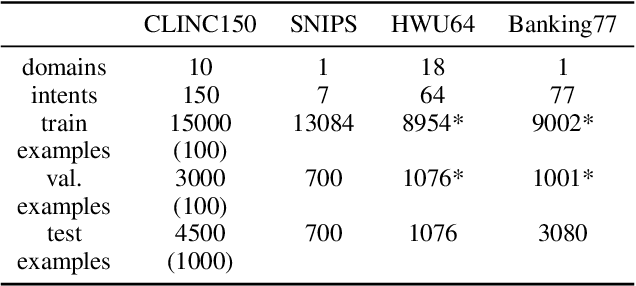
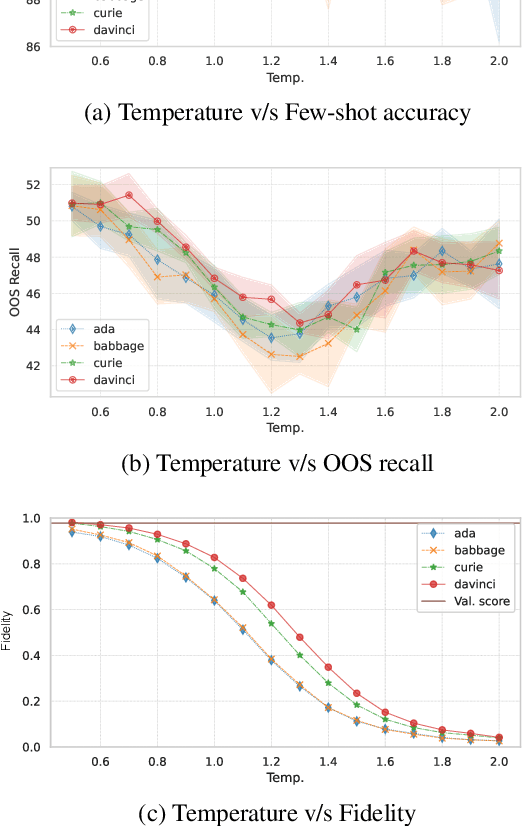
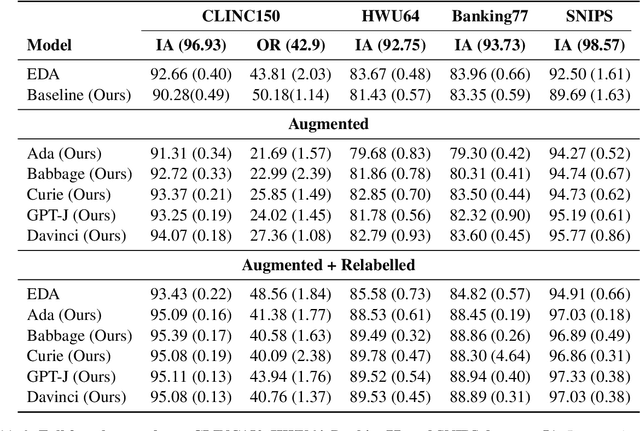
Data augmentation is a widely employed technique to alleviate the problem of data scarcity. In this work, we propose a prompting-based approach to generate labelled training data for intent classification with off-the-shelf language models (LMs) such as GPT-3. An advantage of this method is that no task-specific LM-fine-tuning for data generation is required; hence the method requires no hyper-parameter tuning and is applicable even when the available training data is very scarce. We evaluate the proposed method in a few-shot setting on four diverse intent classification tasks. We find that GPT-generated data significantly boosts the performance of intent classifiers when intents in consideration are sufficiently distinct from each other. In tasks with semantically close intents, we observe that the generated data is less helpful. Our analysis shows that this is because GPT often generates utterances that belong to a closely-related intent instead of the desired one. We present preliminary evidence that a prompting-based GPT classifier could be helpful in filtering the generated data to enhance its quality.