 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Diffusion Models
Apr 07, 2022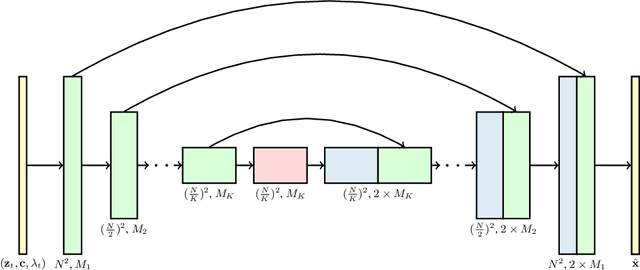
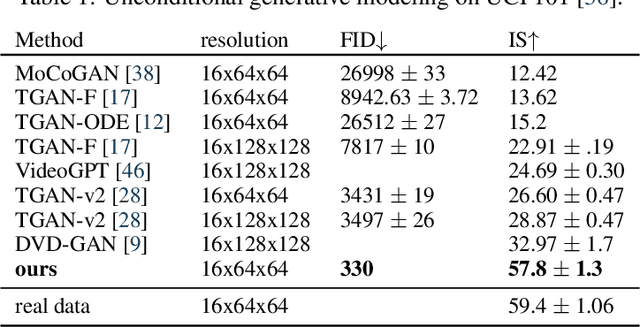


Generating temporally coherent high fidelity video is an important milestone in generative modeling research. We make progress towards this milestone by proposing a diffusion model for video generation that shows very promising initial results. Our model is a natural extension of the standard image diffusion architecture, and it enables jointly training from image and video data, which we find to reduce the variance of minibatch gradients and speed up optimization. To generate long and higher resolution videos we introduce a new conditional sampling technique for spatial and temporal video extension that performs better than previously proposed methods. We present the first results on a large text-conditioned video generation task, as well as state-of-the-art results on an established unconditional video generation benchmark. Supplementary material is available at https://video-diffusion.github.io/
Kubric: A scalable dataset generator
Mar 07, 2022

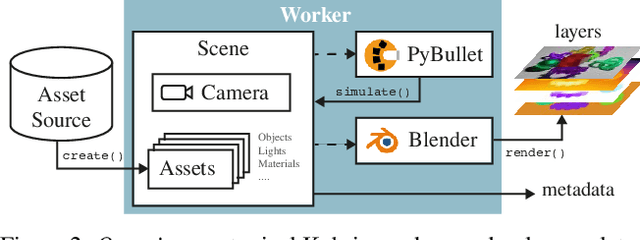
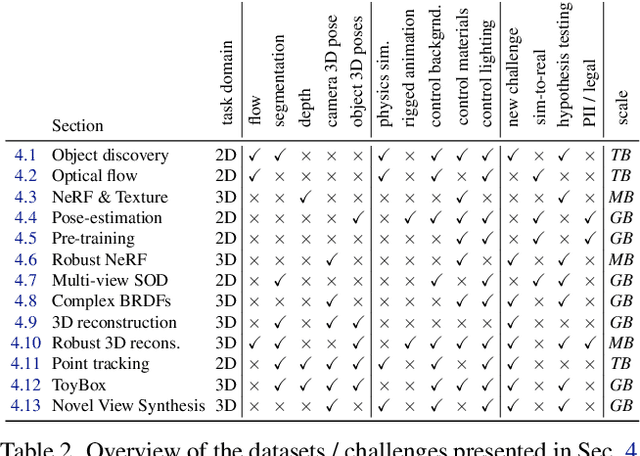
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Palette: Image-to-Image Diffusion Models
Nov 10, 2021
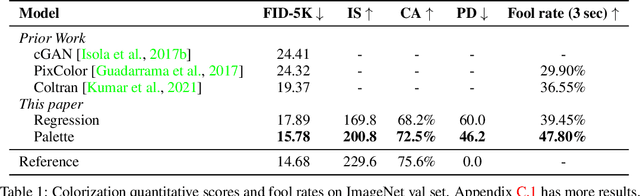

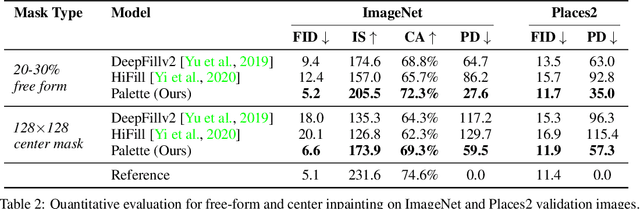
We introduce Palette, a simple and general framework for image-to-image translation using conditional diffusion models. On four challenging image-to-image translation tasks (colorization, inpainting, uncropping, and JPEG decompression), Palette outperforms strong GAN and regression baselines, and establishes a new state of the art. This is accomplished without task-specific hyper-parameter tuning, architecture customization, or any auxiliary loss, demonstrating a desirable degree of generality and flexibility. We uncover the impact of using $L_2$ vs. $L_1$ loss in the denoising diffusion objective on sample diversity, and demonstrate the importance of self-attention through empirical architecture studies. Importantly, we advocate a unified evaluation protocol based on ImageNet, and report several sample quality scores including FID, Inception Score, Classification Accuracy of a pre-trained ResNet-50, and Perceptual Distance against reference images for various baselines. We expect this standardized evaluation protocol to play a critical role in advancing image-to-image translation research. Finally, we show that a single generalist Palette model trained on 3 tasks (colorization, inpainting, JPEG decompression) performs as well or better than task-specific specialist counterparts.
Pix2seq: A Language Modeling Framework for Object Detection
Sep 22, 2021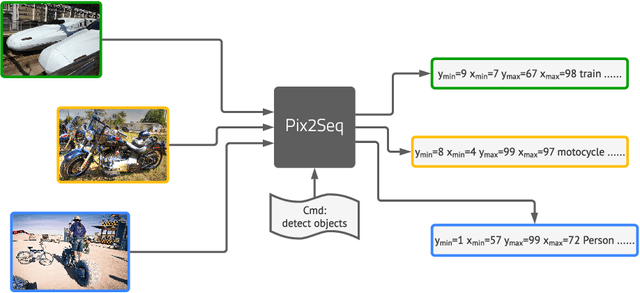
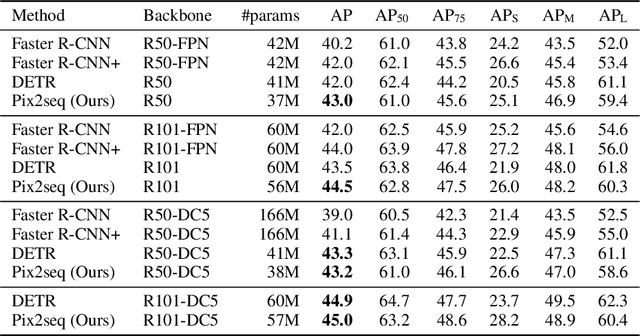
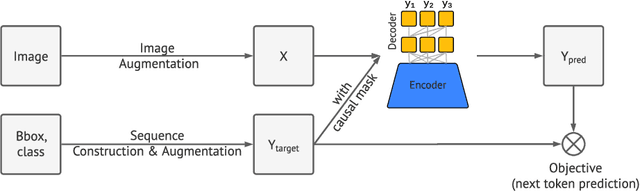
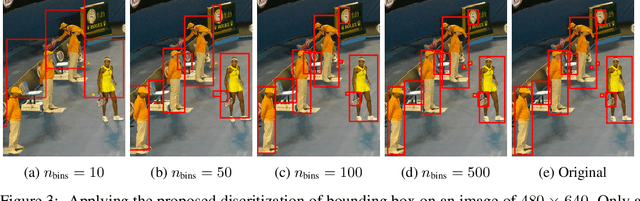
This paper presents Pix2Seq, a simple and generic framework for object detection. Unlike existing approaches that explicitly integrate prior knowledge about the task, we simply cast object detection as a language modeling task conditioned on the observed pixel inputs. Object descriptions (e.g., bounding boxes and class labels) are expressed as sequences of discrete tokens, and we train a neural net to perceive the image and generate the desired sequence. Our approach is based mainly on the intuition that if a neural net knows about where and what the objects are, we just need to teach it how to read them out. Beyond the use of task-specific data augmentations, our approach makes minimal assumptions about the task, yet it achieves competitive results on the challenging COCO dataset, compared to highly specialized and well optimized detection algorithms.
Image Super-Resolution via Iterative Refinement
Apr 15, 2021
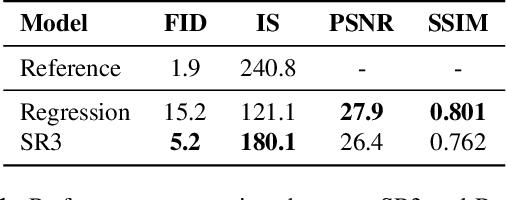
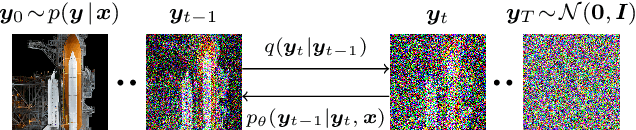

We present SR3, an approach to image Super-Resolution via Repeated Refinement. SR3 adapts denoising diffusion probabilistic models to conditional image generation and performs super-resolution through a stochastic denoising process. Inference starts with pure Gaussian noise and iteratively refines the noisy output using a U-Net model trained on denoising at various noise levels. SR3 exhibits strong performance on super-resolution tasks at different magnification factors, on faces and natural images. We conduct human evaluation on a standard 8X face super-resolution task on CelebA-HQ, comparing with SOTA GAN methods. SR3 achieves a fool rate close to 50%, suggesting photo-realistic outputs, while GANs do not exceed a fool rate of 34%. We further show the effectiveness of SR3 in cascaded image generation, where generative models are chained with super-resolution models, yielding a competitive FID score of 11.3 on ImageNet.
Bridging the Gap Between Adversarial Robustness and Optimization Bias
Feb 17, 2021
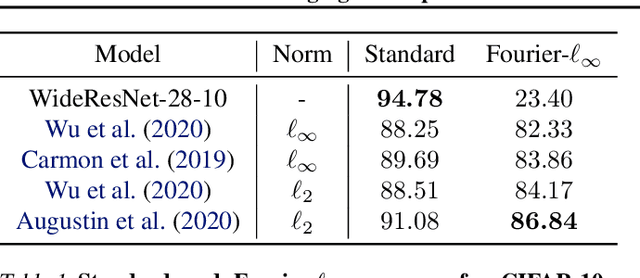
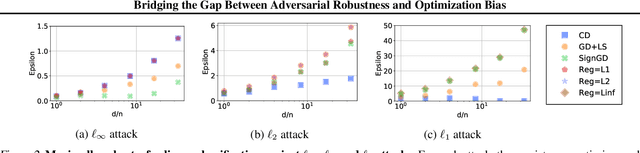

Adversarial robustness is an open challenge in deep learning, most often tackled using adversarial training. Adversarial training is computationally costly, involving alternated optimization with a trade-off between standard generalization and adversarial robustness. We explore training robust models without adversarial training by revisiting a known result linking maximally robust classifiers and minimum norm solutions, and combining it with recent results on the implicit bias of optimizers. First, we show that, under certain conditions, it is possible to achieve both perfect standard accuracy and a certain degree of robustness without a trade-off, simply by training an overparameterized model using the implicit bias of the optimization. In that regime, there is a direct relationship between the type of the optimizer and the attack to which the model is robust. Second, we investigate the role of the architecture in designing robust models. In particular, we characterize the robustness of linear convolutional models, showing that they resist attacks subject to a constraint on the Fourier-$\ell_\infty$ norm. This result explains the property of $\ell_p$-bounded adversarial perturbations that tend to be concentrated in the Fourier domain. This leads us to a novel attack in the Fourier domain that is inspired by the well-known frequency-dependent sensitivity of human perception. We evaluate Fourier-$\ell_\infty$ robustness of recent CIFAR-10 models with robust training and visualize adversarial perturbations.
Unsupervised part representation by Flow Capsules
Nov 27, 2020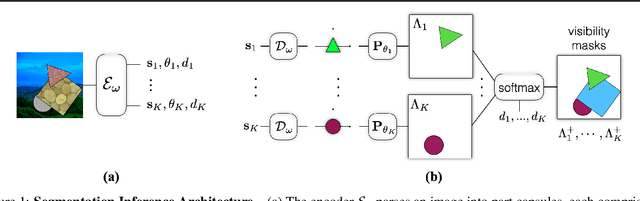
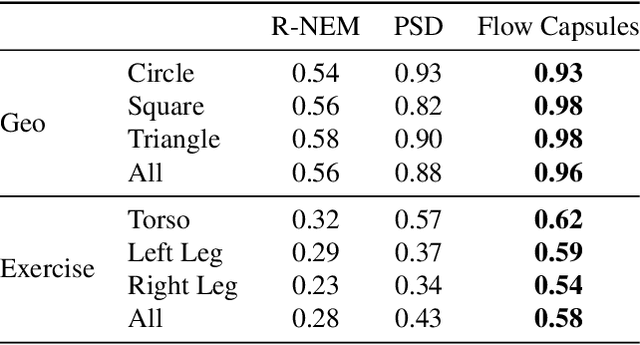
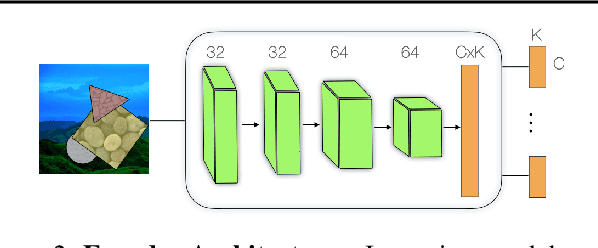

Capsule networks are designed to parse an image into a hierarchy of objects, parts and relations. While promising, they remain limited by an inability to learn effective low level part descriptions. To address this issue we propose a novel self-supervised method for learning part descriptors of an image. During training, we exploit motion as a powerful perceptual cue for part definition, using an expressive decoder for part generation and layered image formation with occlusion. Experiments demonstrate robust part discovery in the presence of multiple objects, cluttered backgrounds, and significant occlusion. The resulting part descriptors, a.k.a. part capsules, are decoded into shape masks, filling in occluded pixels, along with relative depth on single images. We also report unsupervised object classification using our capsule parts in a stacked capsule autoencoder.
A Study of Gradient Variance in Deep Learning
Jul 09, 2020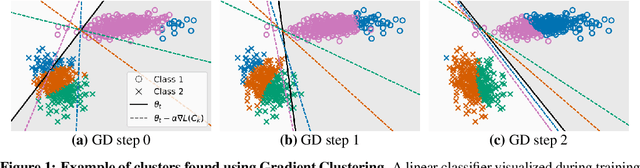


The impact of gradient noise on training deep models is widely acknowledged but not well understood. In this context, we study the distribution of gradients during training. We introduce a method, Gradient Clustering, to minimize the variance of average mini-batch gradient with stratified sampling. We prove that the variance of average mini-batch gradient is minimized if the elements are sampled from a weighted clustering in the gradient space. We measure the gradient variance on common deep learning benchmarks and observe that, contrary to common assumptions, gradient variance increases during training, and smaller learning rates coincide with higher variance. In addition, we introduce normalized gradient variance as a statistic that better correlates with the speed of convergence compared to gradient variance.
Exemplar VAEs for Exemplar based Generation and Data Augmentation
Apr 09, 2020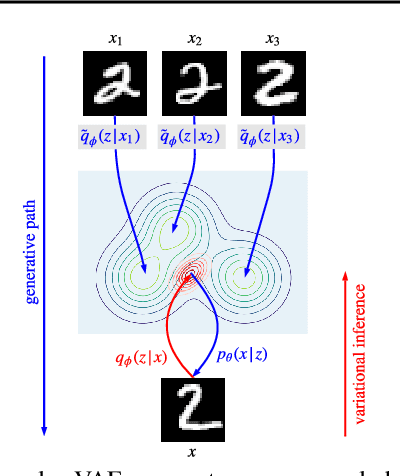

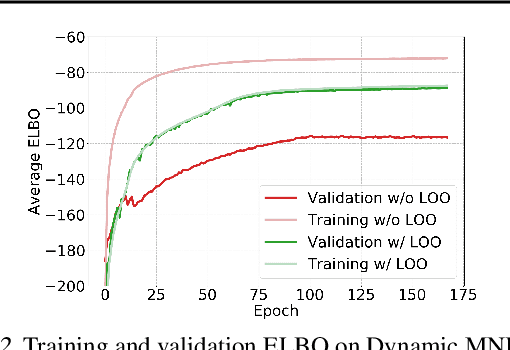
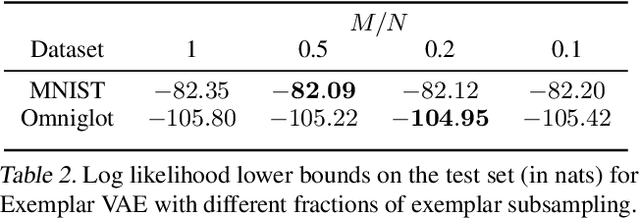
This paper presents a framework for exemplar based generative modeling, featuring Exemplar VAEs. To generate a sample from the Exemplar VAE, one first draws a random exemplar from a training dataset, and then stochastically transforms that exemplar into a latent code, which is then used to generate a new observation. We show that the Exemplar VAE can be interpreted as a VAE with a mixture of Gaussians prior in the latent space, with Gaussian means defined by the latent encoding of the exemplars. To enable optimization and avoid overfitting, Exemplar VAE's parameters are learned using leave-one-out and exemplar subsampling, where, for the generation of each data point, we build a prior based on a random subset of the remaining data points. To accelerate learning, which requires finding the exemplars that exert the greatest influence on the generation of each data point, we use approximate nearest neighbor search in the latent space, yielding a lower bound on the log marginal likelihood. Experiments demonstrate the effectiveness of Exemplar VAEs in density estimation, representation learning, and generative data augmentation for supervised learning.
SentenceMIM: A Latent Variable Language Model
Mar 06, 2020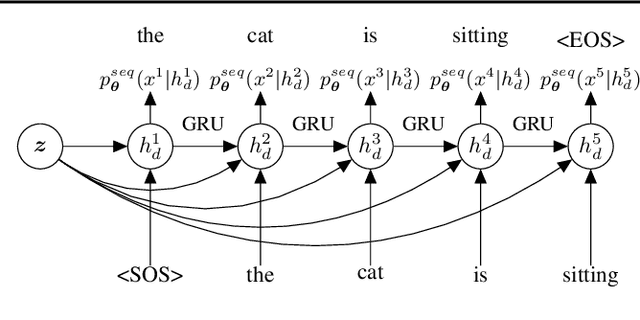
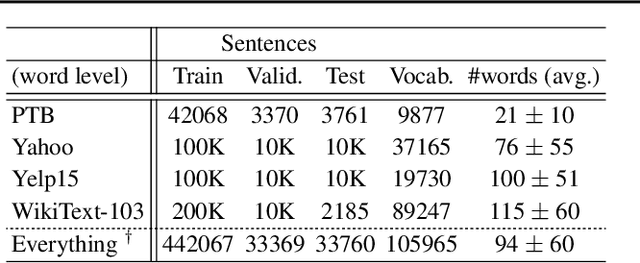

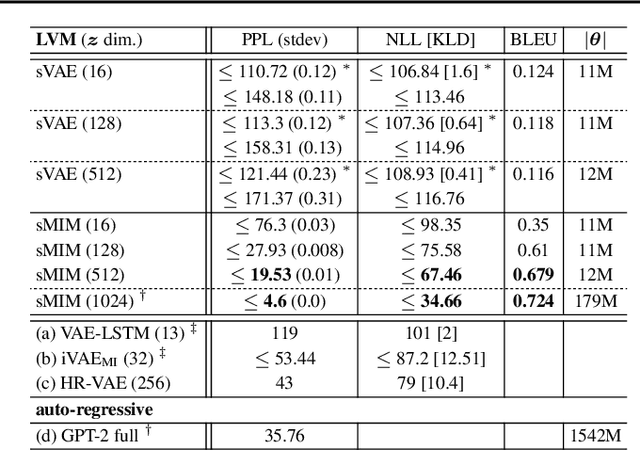
We introduce sentenceMIM, a probabilistic auto-encoder for language modelling, trained with Mutual Information Machine (MIM) learning. Previous attempts to learn variational auto-encoders for language data have had mixed success, with empirical performance well below state-of-the-art auto-regressive models, a key barrier being the occurrence of posterior collapse with VAEs. The recently proposed MIM framework encourages high mutual information between observations and latent variables, and is more robust against posterior collapse. This paper formulates a MIM model for text data, along with a corresponding learning algorithm. We demonstrate excellent perplexity (PPL) results on several datasets, and show that the framework learns a rich latent space, allowing for interpolation between sentences of different lengths with a fixed-dimensional latent representation. We also demonstrate the versatility of sentenceMIM by utilizing a trained model for question-answering, a transfer learning task, without fine-tuning. To the best of our knowledge, this is the first latent variable model (LVM) for text modelling that achieves competitive performance with non-LVM models.