 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulated Object Interaction in Unknown Scenes with Whole-Body Mobile Manipulation
Mar 18, 2021
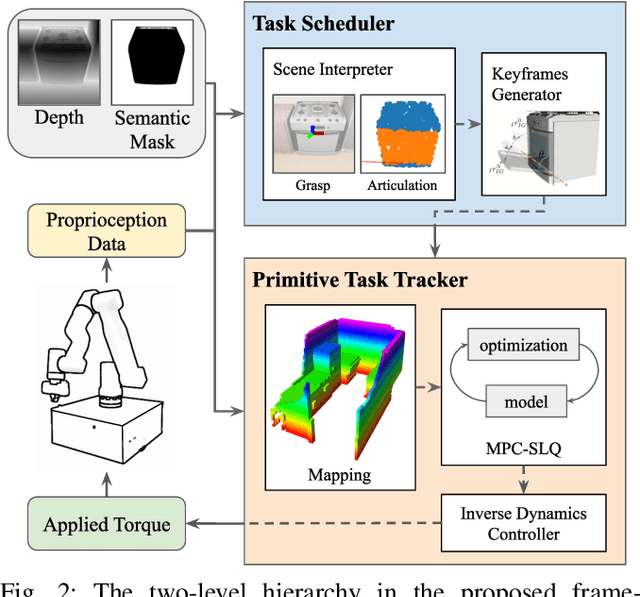

A kitchen assistant needs to operate human-scale objects, such as cabinets and ovens, in unmapped environments with dynamic obstacles. Autonomous interactions in such real-world environments require integrating dexterous manipulation and fluid mobility. While mobile manipulators in different form-factors provide an extended workspace, their real-world adoption has been limited. This limitation is in part due to two main reasons: 1) inability to interact with unknown human-scale objects such as cabinets and ovens, and 2) inefficient coordination between the arm and the mobile base. Executing a high-level task for general objects requires a perceptual understanding of the object as well as adaptive whole-body control among dynamic obstacles. In this paper, we propose a two-stage architecture for autonomous interaction with large articulated objects in unknown environments. The first stage uses a learned model to estimate the articulated model of a target object from an RGB-D input and predicts an action-conditional sequence of states for interaction. The second stage comprises of a whole-body motion controller to manipulate the object along the generated kinematic plan. We show that our proposed pipeline can handle complicated static and dynamic kitchen settings. Moreover, we demonstrate that the proposed approach achieves better performance than commonly used control methods in mobile manipulation. For additional material, please check: https://www.pair.toronto.edu/articulated-mm/ .
Learning a State Representation and Navigation in Cluttered and Dynamic Environments
Mar 07, 2021
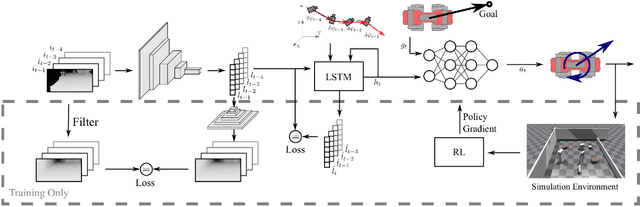

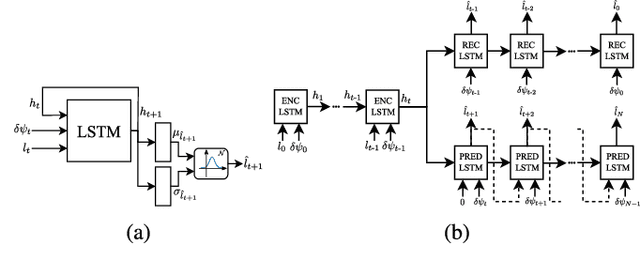
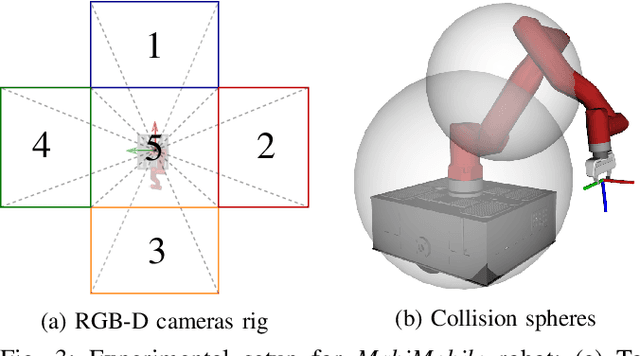
In this work, we present a learning-based pipeline to realise local navigation with a quadrupedal robot in cluttered environments with static and dynamic obstacles. Given high-level navigation commands, the robot is able to safely locomote to a target location based on frames from a depth camera without any explicit mapping of the environment. First, the sequence of images and the current trajectory of the camera are fused to form a model of the world using state representation learning. The output of this lightweight module is then directly fed into a target-reaching and obstacle-avoiding policy trained with reinforcement learning. We show that decoupling the pipeline into these components results in a sample efficient policy learning stage that can be fully trained in simulation in just a dozen minutes. The key part is the state representation, which is trained to not only estimate the hidden state of the world in an unsupervised fashion, but also helps bridging the reality gap, enabling successful sim-to-real transfer. In our experiments with the quadrupedal robot ANYmal in simulation and in reality, we show that our system can handle noisy depth images, avoid dynamic obstacles unseen during training, and is endowed with local spatial awareness.
* 8 pages, 8 figures, 2 tables
Joint Space Control via Deep Reinforcement Learning
Nov 12, 2020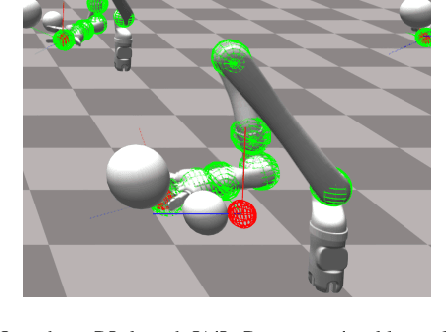
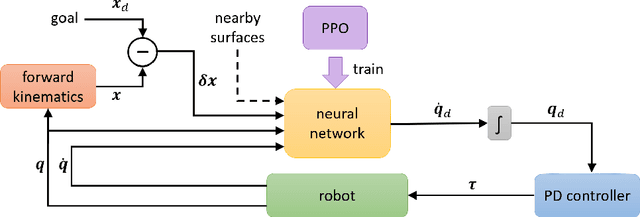

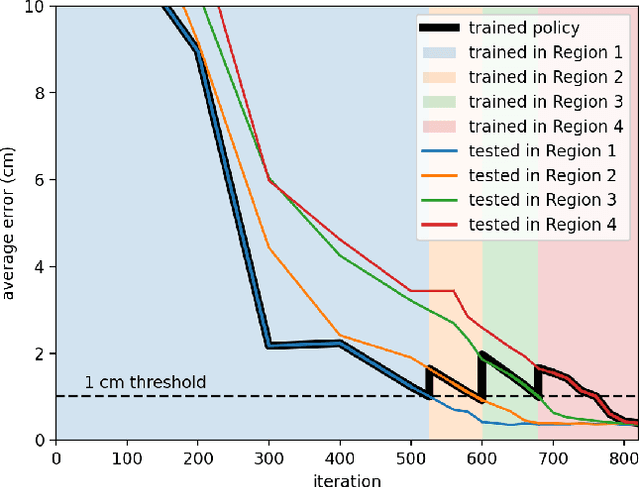
The dominant way to control a robot manipulator uses hand-crafted differential equations leveraging some form of inverse kinematics / dynamics. We propose a simple, versatile joint-level controller that dispenses with differential equations entirely. A deep neural network, trained via model-free reinforcement learning, is used to map from task space to joint space. Experiments show the method capable of achieving similar error to traditional methods, while greatly simplifying the process by automatically handling redundancy, joint limits, and acceleration / deceleration profiles. The basic technique is extended to avoid obstacles by augmenting the input to the network with information about the nearest obstacles. Results are shown both in simulation and on a real robot via sim-to-real transfer of the learned policy. We show that it is possible to achieve sub-centimeter accuracy, both in simulation and the real world, with a moderate amount of training.
Learning a Contact-Adaptive Controller for Robust, Efficient Legged Locomotion
Oct 05, 2020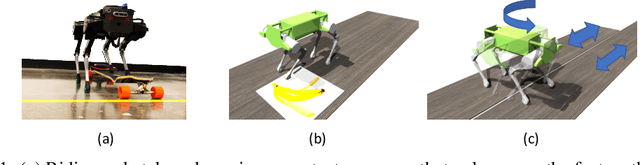
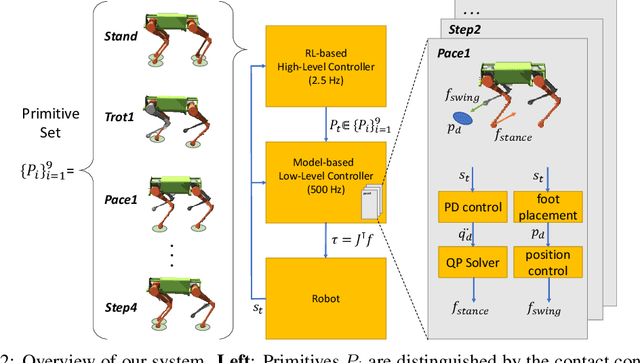

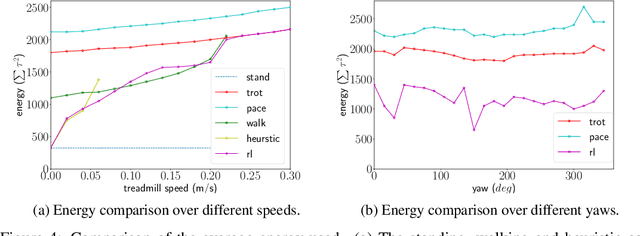
We present a hierarchical framework that combines model-based control and reinforcement learning (RL) to synthesize robust controllers for a quadruped (the Unitree Laikago). The system consists of a high-level controller that learns to choose from a set of primitives in response to changes in the environment and a low-level controller that utilizes an established control method to robustly execute the primitives. Our framework learns a controller that can adapt to challenging environmental changes on the fly, including novel scenarios not seen during training. The learned controller is up to 85~percent more energy efficient and is more robust compared to baseline methods. We also deploy the controller on a physical robot without any randomization or adaptation scheme.
Practical Reinforcement Learning For MPC: Learning from sparse objectives in under an hour on a real robot
Mar 06, 2020
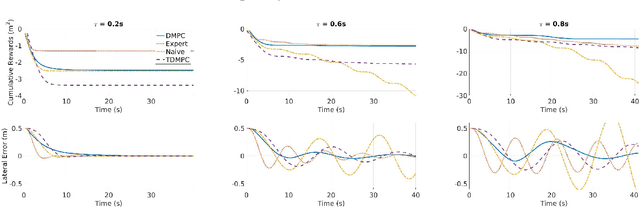
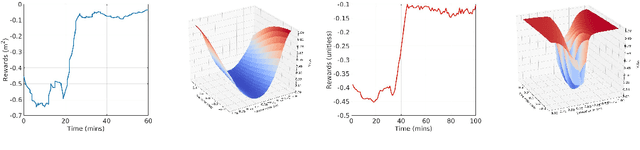
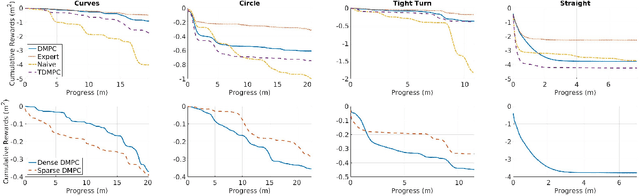
Model Predictive Control (MPC) is a powerful control technique that handles constraints, takes the system's dynamics into account, and optimizes for a given cost function. In practice, however, it often requires an expert to craft and tune this cost function and find trade-offs between different state penalties to satisfy simple high level objectives. In this paper, we use Reinforcement Learning and in particular value learning to approximate the value function given only high level objectives, which can be sparse and binary. Building upon previous works, we present improvements that allowed us to successfully deploy the method on a real world unmanned ground vehicle. Our experiments show that our method can learn the cost function from scratch and without human intervention, while reaching a performance level similar to that of an expert-tuned MPC. We perform a quantitative comparison of these methods with standard MPC approaches both in simulation and on the real robot.
Deep Value Model Predictive Control
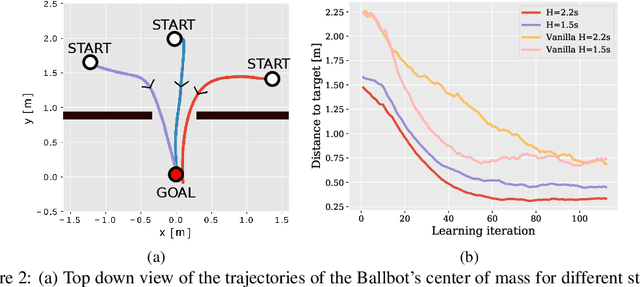
Oct 08, 2019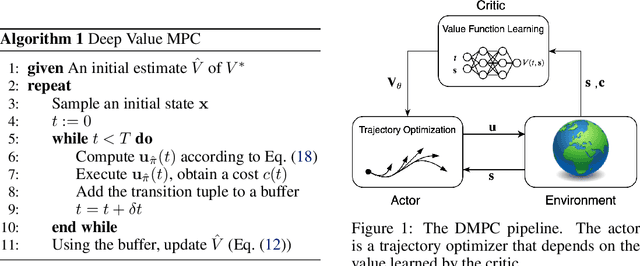


In this paper, we introduce an actor-critic algorithm called Deep Value Model Predictive Control (DMPC), which combines model-based trajectory optimization with value function estimation. The DMPC actor is a Model Predictive Control (MPC) optimizer with an objective function defined in terms of a value function estimated by the critic. We show that our MPC actor is an importance sampler, which minimizes an upper bound of the cross-entropy to the state distribution of the optimal sampling policy. In our experiments with a Ballbot system, we show that our algorithm can work with sparse and binary reward signals to efficiently solve obstacle avoidance and target reaching tasks. Compared to previous work, we show that including the value function in the running cost of the trajectory optimizer speeds up the convergence. We also discuss the necessary strategies to robustify the algorithm in practice.