 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Gradient Variance in Deep Learning
Jul 09, 2020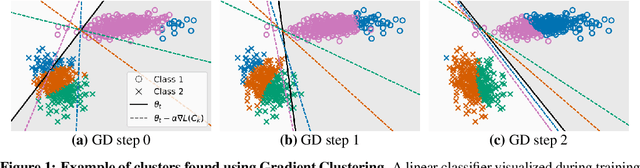


The impact of gradient noise on training deep models is widely acknowledged but not well understood. In this context, we study the distribution of gradients during training. We introduce a method, Gradient Clustering, to minimize the variance of average mini-batch gradient with stratified sampling. We prove that the variance of average mini-batch gradient is minimized if the elements are sampled from a weighted clustering in the gradient space. We measure the gradient variance on common deep learning benchmarks and observe that, contrary to common assumptions, gradient variance increases during training, and smaller learning rates coincide with higher variance. In addition, we introduce normalized gradient variance as a statistic that better correlates with the speed of convergence compared to gradient variance.
Learning Differential Equations that are Easy to Solve
Jul 09, 2020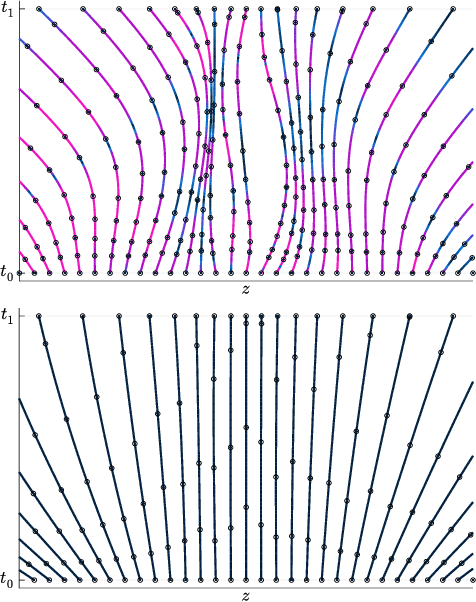

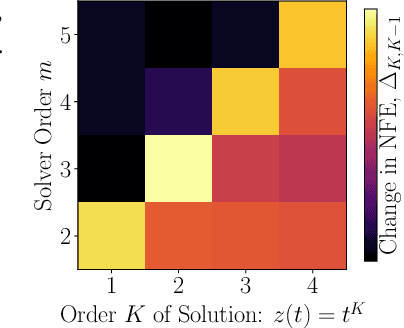
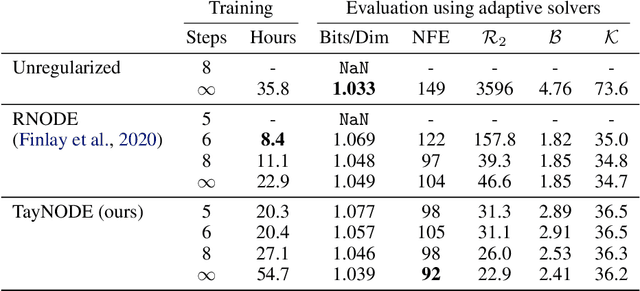
Differential equations parameterized by neural networks become expensive to solve numerically as training progresses. We propose a remedy that encourages learned dynamics to be easier to solve. Specifically, we introduce a differentiable surrogate for the time cost of standard numerical solvers, using higher-order derivatives of solution trajectories. These derivatives are efficient to compute with Taylor-mode automatic differentiation. Optimizing this additional objective trades model performance against the time cost of solving the learned dynamics. We demonstrate our approach by training substantially faster, while nearly as accurate, models in supervised classification, density estimation, and time-series modelling tasks.
SUMO: Unbiased Estimation of Log Marginal Probability for Latent Variable Models
Apr 01, 2020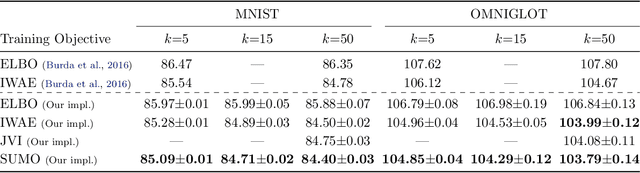

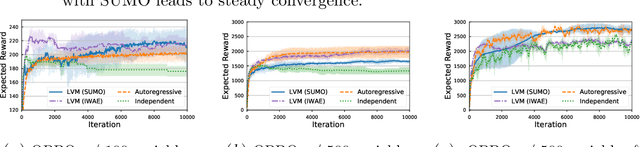
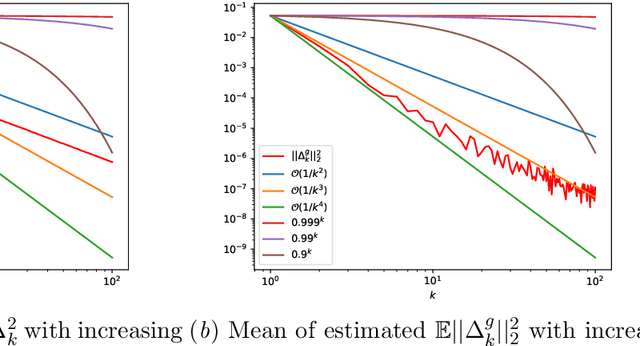
Standard variational lower bounds used to train latent variable models produce biased estimates of most quantities of interest. We introduce an unbiased estimator of the log marginal likelihood and its gradients for latent variable models based on randomized truncation of infinite series. If parameterized by an encoder-decoder architecture, the parameters of the encoder can be optimized to minimize its variance of this estimator. We show that models trained using our estimator give better test-set likelihoods than a standard importance-sampling based approach for the same average computational cost. This estimator also allows use of latent variable models for tasks where unbiased estimators, rather than marginal likelihood lower bounds, are preferred, such as minimizing reverse KL divergences and estimating score functions.
What went wrong and when? Instance-wise Feature Importance for Time-series Models
Mar 05, 2020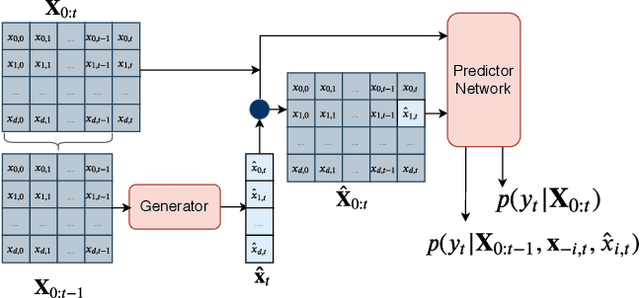
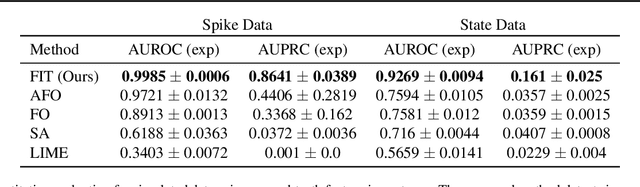
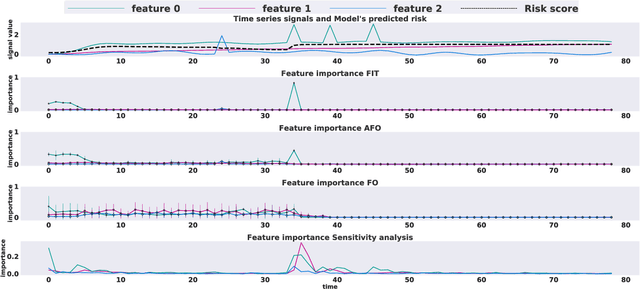
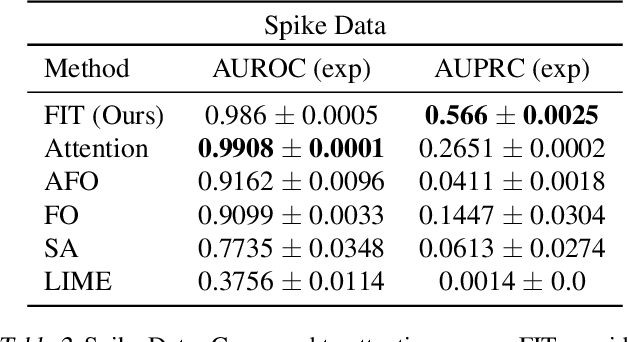
Multivariate time series models are poised to be used for decision support in high-stakes applications, such as healthcare. In these contexts, it is important to know which features at which times most influenced a prediction. We demonstrate a general approach for assigning importance to observations in multivariate time series, based on their counterfactual influence on future predictions. Specifically, we define the importance of an observation as the change in the predictive distribution, had the observation not been seen. We integrate over plausible counterfactuals by sampling from the corresponding conditional distributions of generative time series models. We compare our importance metric to gradient-based explanations, attention mechanisms, and other baselines in simulated and clinical ICU data, and show that our approach generates the most precise explanations. Our method is inexpensive, model agnostic, and can be used with arbitrarily complex time series models and predictors.
Scalable Gradients for Stochastic Differential Equations
Feb 24, 2020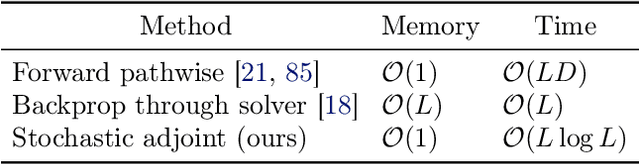

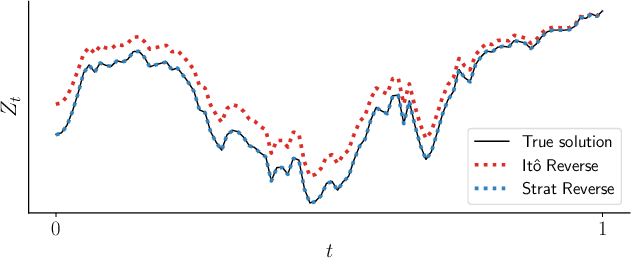

The adjoint sensitivity method scalably computes gradients of solutions to ordinary differential equations. We generalize this method to stochastic differential equations, allowing time-efficient and constant-memory computation of gradients with high-order adaptive solvers. Specifically, we derive a stochastic differential equation whose solution is the gradient, a memory-efficient algorithm for caching noise, and conditions under which numerical solutions converge. In addition, we combine our method with gradient-based stochastic variational inference for latent stochastic differential equations. We use our method to fit stochastic dynamics defined by neural networks, achieving competitive performance on a 50-dimensional motion capture dataset.
Cutting out the Middle-Man: Training and Evaluating Energy-Based Models without Sampling
Feb 14, 2020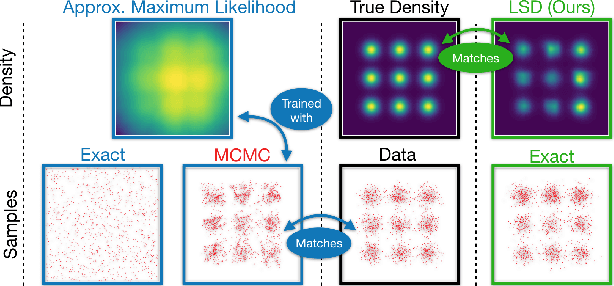
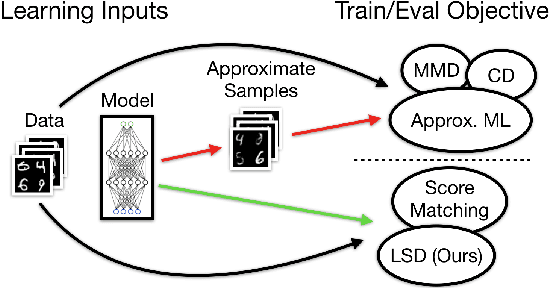
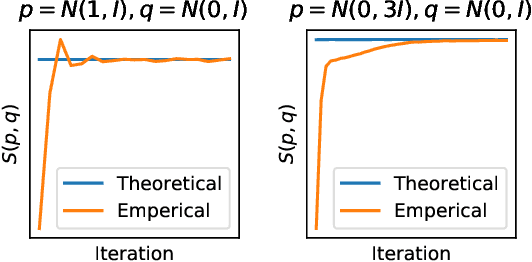
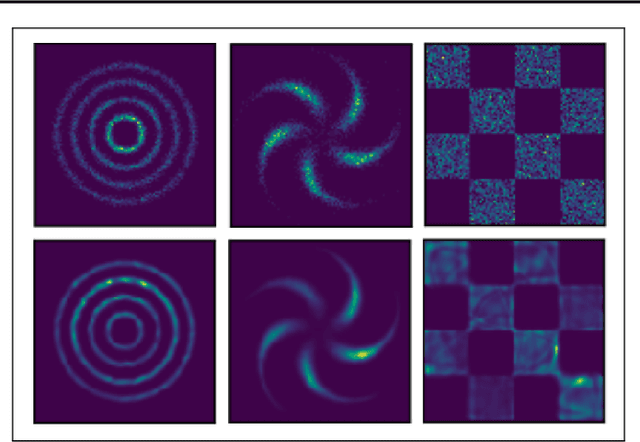
We present a new method for evaluating and training unnormalized density models. Our approach only requires access to the gradient of the unnormalized model's log-density. We estimate the Stein discrepancy between the data density p(x) and the model density q(x) defined by a vector function of the data. We parameterize this function with a neural network and fit its parameters to maximize the discrepancy. This yields a novel goodness-of-fit test which outperforms existing methods on high dimensional data. Furthermore, optimizing $q(x)$ to minimize this discrepancy produces a novel method for training unnormalized models which scales more gracefully than existing methods. The ability to both learn and compare models is a unique feature of the proposed method.
Your Classifier is Secretly an Energy Based Model and You Should Treat it Like One
Dec 11, 2019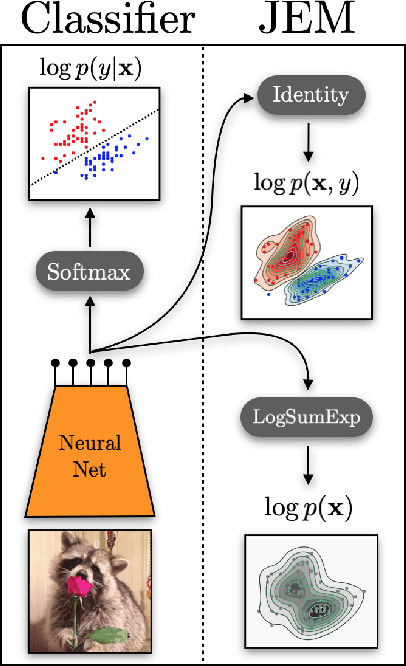
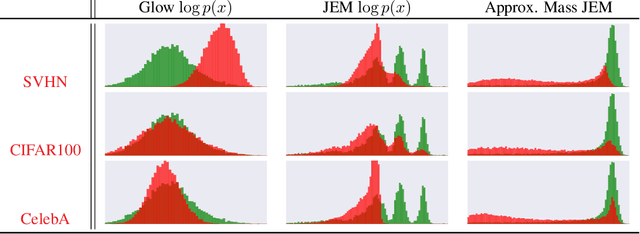

We propose to reinterpret a standard discriminative classifier of p(y|x) as an energy based model for the joint distribution p(x,y). In this setting, the standard class probabilities can be easily computed as well as unnormalized values of p(x) and p(x|y). Within this framework, standard discriminative architectures may beused and the model can also be trained on unlabeled data. We demonstrate that energy based training of the joint distribution improves calibration, robustness, andout-of-distribution detection while also enabling our models to generate samplesrivaling the quality of recent GAN approaches. We improve upon recently proposed techniques for scaling up the training of energy based models and presentan approach which adds little overhead compared to standard classification training. Our approach is the first to achieve performance rivaling the state-of-the-artin both generative and discriminative learning within one hybrid model.
Neural Networks with Cheap Differential Operators
Dec 08, 2019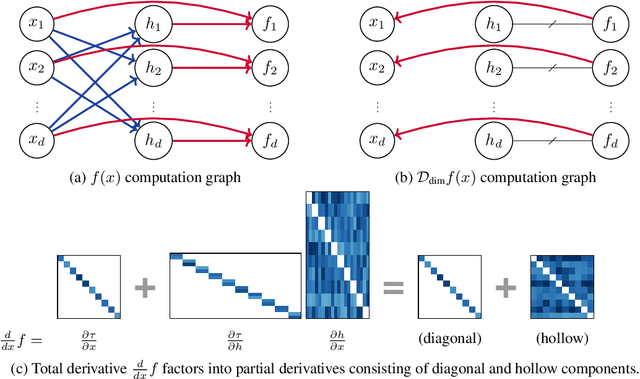
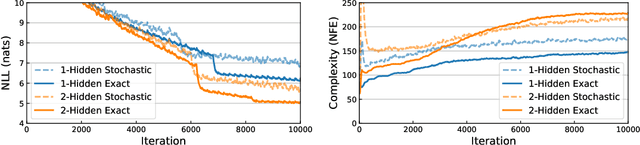
Gradients of neural networks can be computed efficiently for any architecture, but some applications require differential operators with higher time complexity. We describe a family of restricted neural network architectures that allow efficient computation of a family of differential operators involving dimension-wise derivatives, used in cases such as computing the divergence. Our proposed architecture has a Jacobian matrix composed of diagonal and hollow (non-diagonal) components. We can then modify the backward computation graph to extract dimension-wise derivatives efficiently with automatic differentiation. We demonstrate these cheap differential operators for solving root-finding subproblems in implicit ODE solvers, exact density evaluation for continuous normalizing flows, and evaluating the Fokker--Planck equation for training stochastic differential equation models.
Optimizing Millions of Hyperparameters by Implicit Differentiation
Nov 06, 2019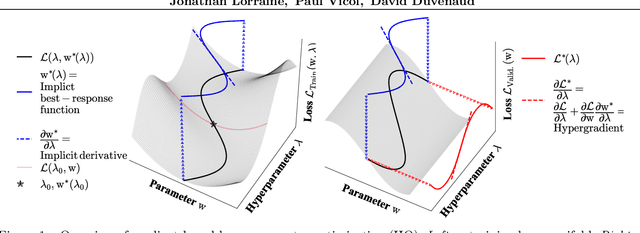
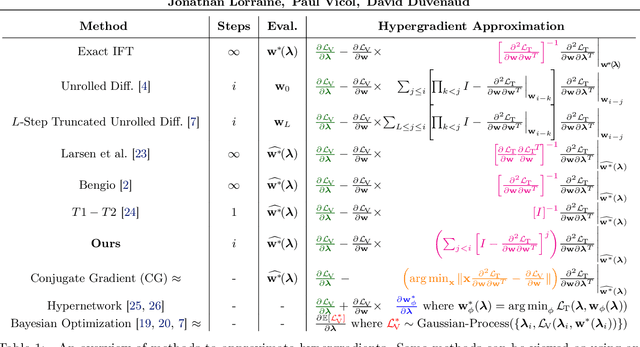
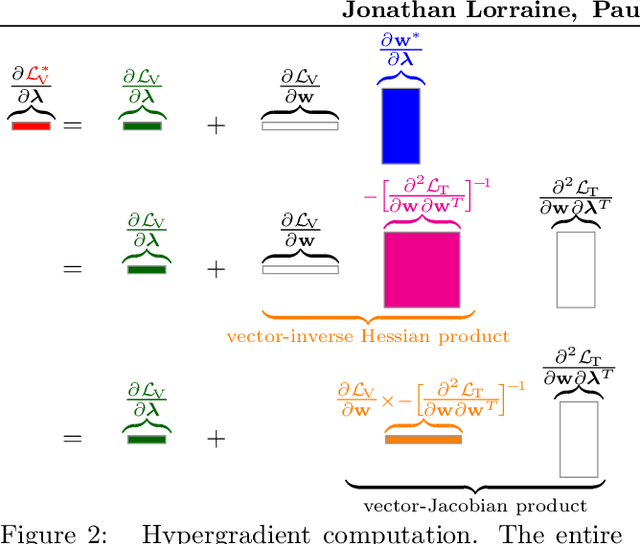
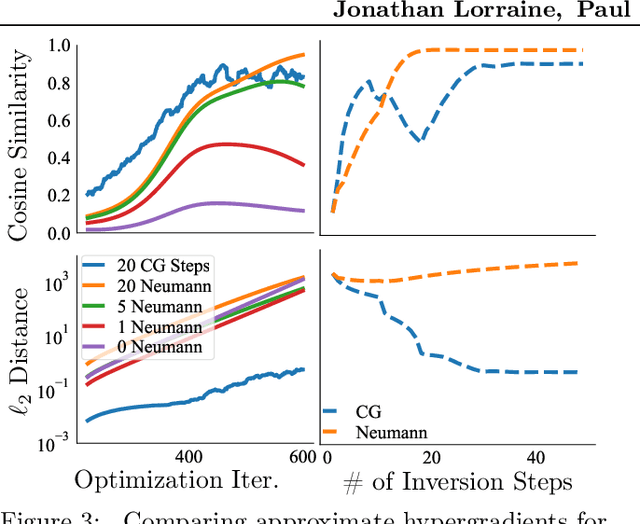
We propose an algorithm for inexpensive gradient-based hyperparameter optimization that combines the implicit function theorem (IFT) with efficient inverse Hessian approximations. We present results about the relationship between the IFT and differentiating through optimization, motivating our algorithm. We use the proposed approach to train modern network architectures with millions of weights and millions of hyper-parameters. For example, we learn a data-augmentation network - where every weight is a hyperparameter tuned for validation performance - outputting augmented training examples. Jointly tuning weights and hyperparameters with our approach is only a few times more costly in memory and compute than standard training.
Efficient Graph Generation with Graph Recurrent Attention Networks
Oct 02, 2019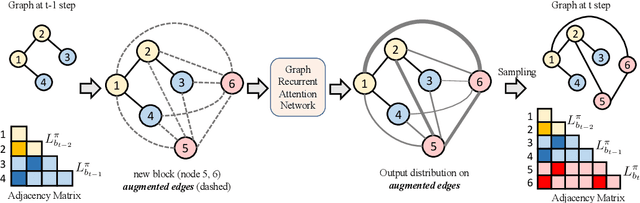
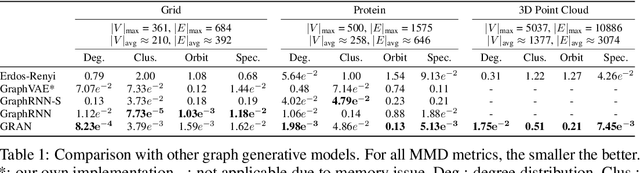
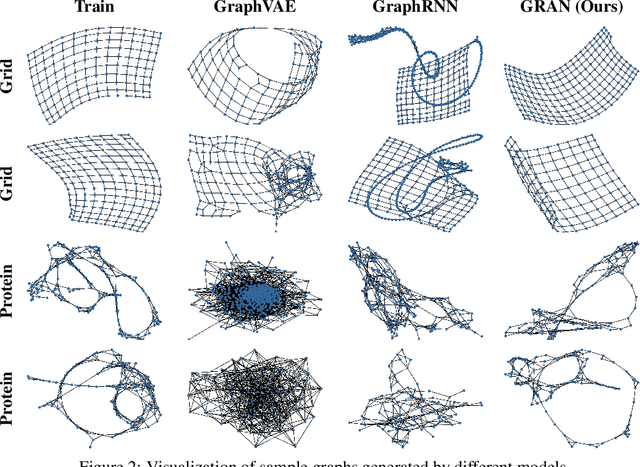
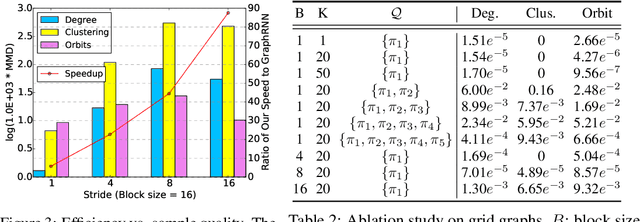
We propose a new family of efficient and expressive deep generative models of graphs, called Graph Recurrent Attention Networks (GRANs). Our model generates graphs one block of nodes and associated edges at a time. The block size and sampling stride allow us to trade off sample quality for efficiency. Compared to previous RNN-based graph generative models, our framework better captures the auto-regressive conditioning between the already-generated and to-be-generated parts of the graph using Graph Neural Networks (GNNs) with attention. This not only reduces the dependency on node ordering but also bypasses the long-term bottleneck caused by the sequential nature of RNNs. Moreover, we parameterize the output distribution per block using a mixture of Bernoulli, which captures the correlations among generated edges within the block. Finally, we propose to handle node orderings in generation by marginalizing over a family of canonical orderings. On standard benchmarks, we achieve state-of-the-art time efficiency and sample quality compared to previous models. Additionally, we show our model is capable of generating large graphs of up to 5K nodes with good quality. To the best of our knowledge, GRAN is the first deep graph generative model that can scale to this size. Our code is released at: https://github.com/lrjconan/GRAN.