 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaDen : Sparse and Dense Keypoint Estimation for Real-World Chart Understanding
Aug 03, 2023



We introduce a novel bottom-up approach for the extraction of chart data. Our model utilizes images of charts as inputs and learns to detect keypoints (KP), which are used to reconstruct the components within the plot area. Our novelty lies in detecting a fusion of continuous and discrete KP as predicted heatmaps. A combination of sparse and dense per-pixel objectives coupled with a uni-modal self-attention-based feature-fusion layer is applied to learn KP embeddings. Further leveraging deep metric learning for unsupervised clustering, allows us to segment the chart plot area into various objects. By further matching the chart components to the legend, we are able to obtain the data series names. A post-processing threshold is applied to the KP embeddings to refine the object reconstructions and improve accuracy. Our extensive experiments include an evaluation of different modules for KP estimation and the combination of deep layer aggregation and corner pooling approaches. The results of our experiments provide extensive evaluation for the task of real-world chart data extraction.
Filter Pruning for Efficient CNNs via Knowledge-driven Differential Filter Sampler
Jul 01, 2023



Filter pruning simultaneously accelerates the computation and reduces the memory overhead of CNNs, which can be effectively applied to edge devices and cloud services. In this paper, we propose a novel Knowledge-driven Differential Filter Sampler~(KDFS) with Masked Filter Modeling~(MFM) framework for filter pruning, which globally prunes the redundant filters based on the prior knowledge of a pre-trained model in a differential and non-alternative optimization. Specifically, we design a differential sampler with learnable sampling parameters to build a binary mask vector for each layer, determining whether the corresponding filters are redundant. To learn the mask, we introduce masked filter modeling to construct PCA-like knowledge by aligning the intermediate features from the pre-trained teacher model and the outputs of the student decoder taking sampling features as the input. The mask and sampler are directly optimized by the Gumbel-Softmax Straight-Through Gradient Estimator in an end-to-end manner in combination with global pruning constraint, MFM reconstruction error, and dark knowledge. Extensive experiments demonstrate the proposed KDFS's effectiveness in compressing the base models on various datasets. For instance, the pruned ResNet-50 on ImageNet achieves $55.36\%$ computation reduction, and $42.86\%$ parameter reduction, while only dropping $0.35\%$ Top-1 accuracy, significantly outperforming the state-of-the-art methods. The code is available at \url{https://github.com/Osilly/KDFS}.
Context-Aware Chart Element Detection
May 07, 2023As a prerequisite of chart data extraction, the accurate detection of chart basic elements is essential and mandatory. In contrast to object detection in the general image domain, chart element detection relies heavily on context information as charts are highly structured data visualization formats. To address this, we propose a novel method CACHED, which stands for Context-Aware Chart Element Detection, by integrating a local-global context fusion module consisting of visual context enhancement and positional context encoding with the Cascade R-CNN framework. To improve the generalization of our method for broader applicability, we refine the existing chart element categorization and standardized 18 classes for chart basic elements, excluding plot elements. Our CACHED method, with the updated category of chart elements, achieves state-of-the-art performance in our experiments, underscoring the importance of context in chart element detection. Extending our method to the bar plot detection task, we obtain the best result on the PMC test dataset.
LineFormer: Rethinking Line Chart Data Extraction as Instance Segmentation
May 03, 2023



Data extraction from line-chart images is an essential component of the automated document understanding process, as line charts are a ubiquitous data visualization format. However, the amount of visual and structural variations in multi-line graphs makes them particularly challenging for automated parsing. Existing works, however, are not robust to all these variations, either taking an all-chart unified approach or relying on auxiliary information such as legends for line data extraction. In this work, we propose LineFormer, a robust approach to line data extraction using instance segmentation. We achieve state-of-the-art performance on several benchmark synthetic and real chart datasets. Our implementation is available at https://github.com/TheJaeLal/LineFormer .
Progressive Multi-view Human Mesh Recovery with Self-Supervision
Dec 10, 2022



To date, little attention has been given to multi-view 3D human mesh estimation, despite real-life applicability (e.g., motion capture, sport analysis) and robustness to single-view ambiguities. Existing solutions typically suffer from poor generalization performance to new settings, largely due to the limited diversity of image-mesh pairs in multi-view training data. To address this shortcoming, people have explored the use of synthetic images. But besides the usual impact of visual gap between rendered and target data, synthetic-data-driven multi-view estimators also suffer from overfitting to the camera viewpoint distribution sampled during training which usually differs from real-world distributions. Tackling both challenges, we propose a novel simulation-based training pipeline for multi-view human mesh recovery, which (a) relies on intermediate 2D representations which are more robust to synthetic-to-real domain gap; (b) leverages learnable calibration and triangulation to adapt to more diversified camera setups; and (c) progressively aggregates multi-view information in a canonical 3D space to remove ambiguities in 2D representations. Through extensive benchmarking, we demonstrate the superiority of the proposed solution especially for unseen in-the-wild scenarios.
Federated Learning with Privacy-Preserving Ensemble Attention Distillation
Oct 16, 2022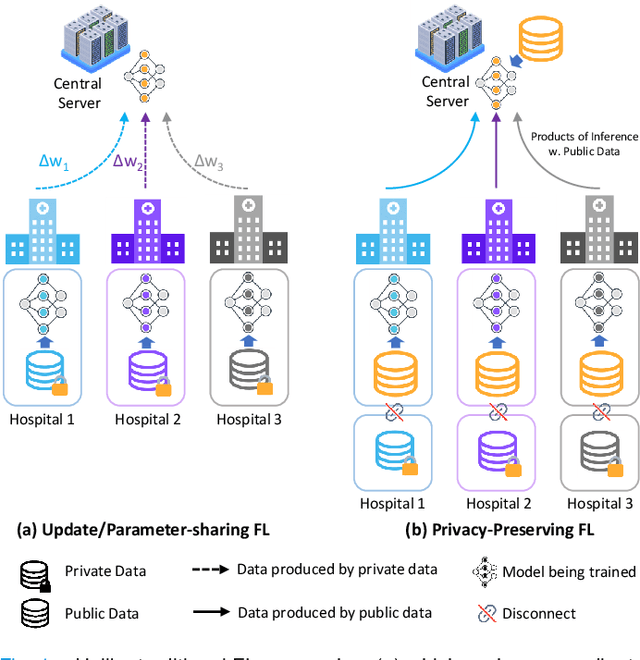
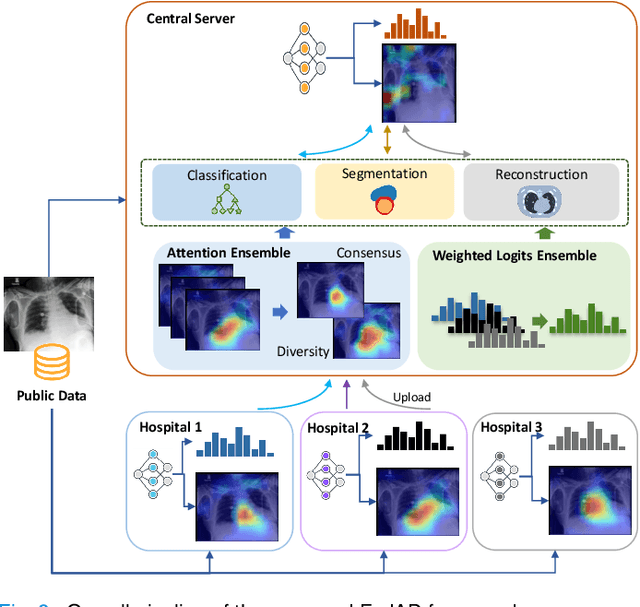
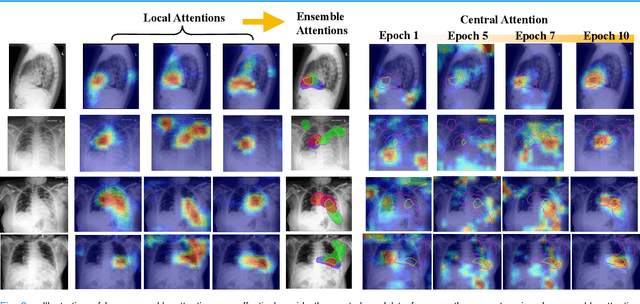
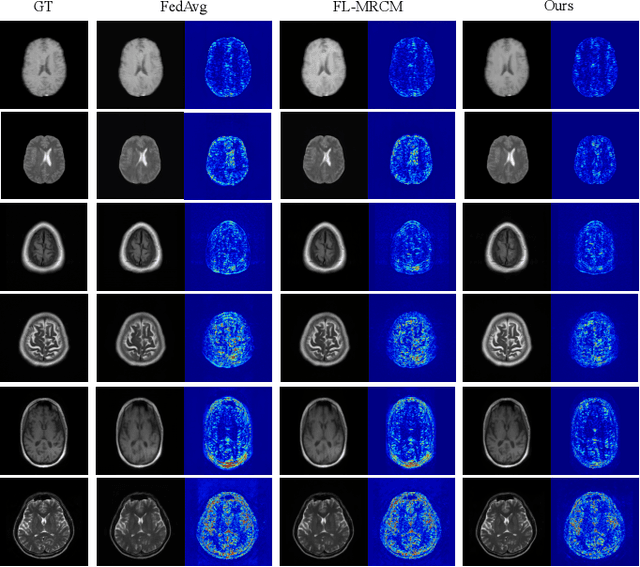
Federated Learning (FL) is a machine learning paradigm where many local nodes collaboratively train a central model while keeping the training data decentralized. This is particularly relevant for clinical applications since patient data are usually not allowed to be transferred out of medical facilities, leading to the need for FL. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they also require numerous rounds of synchronized communication and, more importantly, suffer from a privacy leakage risk. We propose a privacy-preserving FL framework leveraging unlabeled public data for one-way offline knowledge distillation in this work. The central model is learned from local knowledge via ensemble attention distillation. Our technique uses decentralized and heterogeneous local data like existing FL approaches, but more importantly, it significantly reduces the risk of privacy leakage. We demonstrate that our method achieves very competitive performance with more robust privacy preservation based on extensive experiments on image classification, segmentation, and reconstruction tasks.
PREF: Predictability Regularized Neural Motion Fields
Sep 21, 2022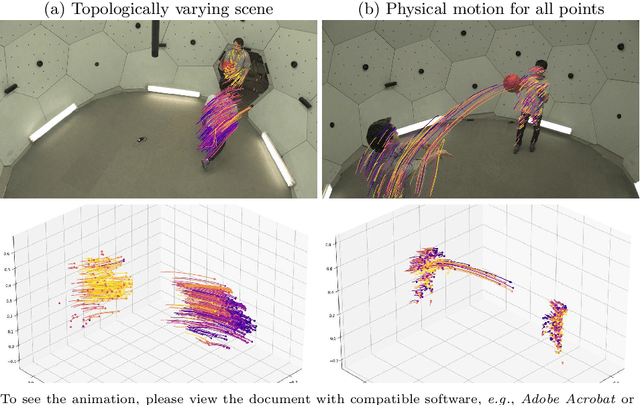
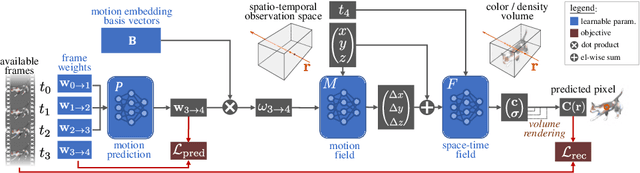
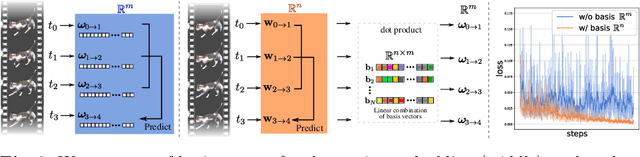
Knowing the 3D motions in a dynamic scene is essential to many vision applications. Recent progress is mainly focused on estimating the activity of some specific elements like humans. In this paper, we leverage a neural motion field for estimating the motion of all points in a multiview setting. Modeling the motion from a dynamic scene with multiview data is challenging due to the ambiguities in points of similar color and points with time-varying color. We propose to regularize the estimated motion to be predictable. If the motion from previous frames is known, then the motion in the near future should be predictable. Therefore, we introduce a predictability regularization by first conditioning the estimated motion on latent embeddings, then by adopting a predictor network to enforce predictability on the embeddings. The proposed framework PREF (Predictability REgularized Fields) achieves on par or better results than state-of-the-art neural motion field-based dynamic scene representation methods, while requiring no prior knowledge of the scene.
Preserving Privacy in Federated Learning with Ensemble Cross-Domain Knowledge Distillation
Sep 10, 2022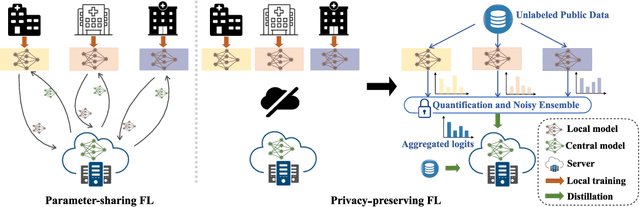
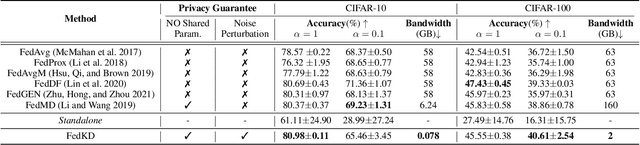
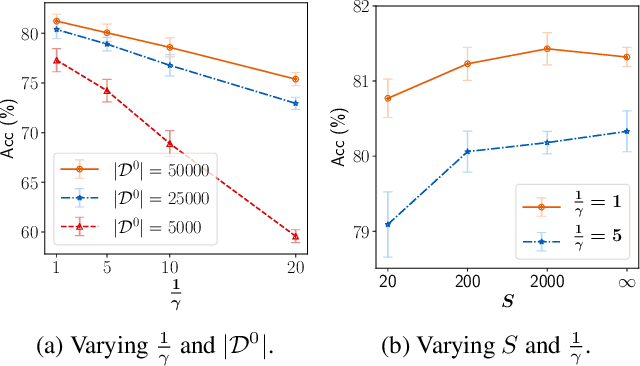
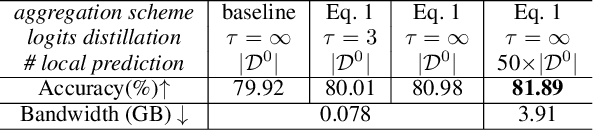
Federated Learning (FL) is a machine learning paradigm where local nodes collaboratively train a central model while the training data remains decentralized. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they suffer from communication bottlenecks. More importantly, they risk privacy leakage. In this work, we develop a privacy preserving and communication efficient method in a FL framework with one-shot offline knowledge distillation using unlabeled, cross-domain public data. We propose a quantized and noisy ensemble of local predictions from completely trained local models for stronger privacy guarantees without sacrificing accuracy. Based on extensive experiments on image classification and text classification tasks, we show that our privacy-preserving method outperforms baseline FL algorithms with superior performance in both accuracy and communication efficiency.
Self-supervised Human Mesh Recovery with Cross-Representation Alignment
Sep 10, 2022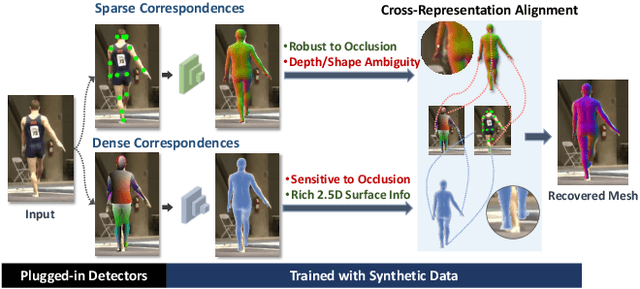
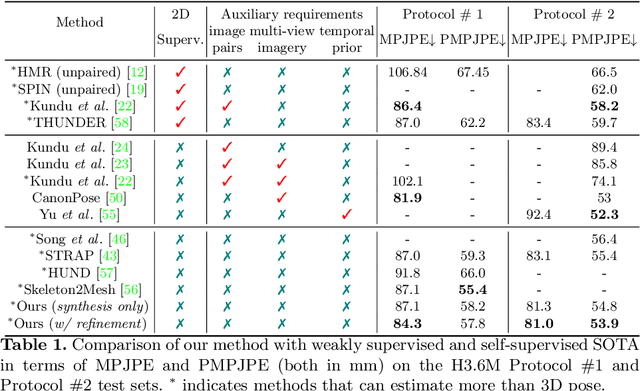
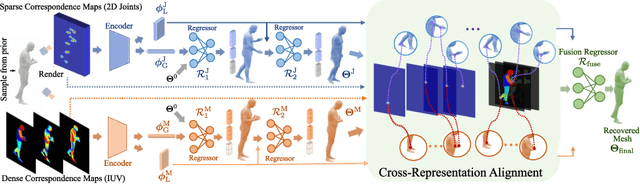
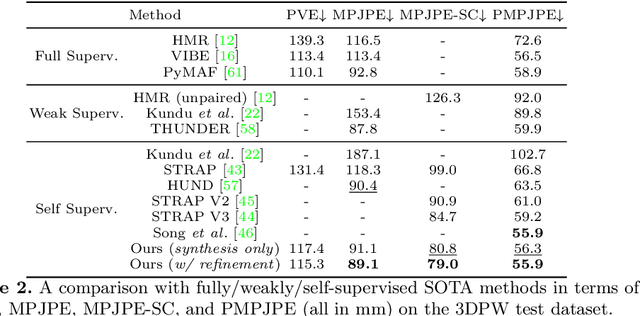
Fully supervised human mesh recovery methods are data-hungry and have poor generalizability due to the limited availability and diversity of 3D-annotated benchmark datasets. Recent progress in self-supervised human mesh recovery has been made using synthetic-data-driven training paradigms where the model is trained from synthetic paired 2D representation (e.g., 2D keypoints and segmentation masks) and 3D mesh. However, on synthetic dense correspondence maps (i.e., IUV) few have been explored since the domain gap between synthetic training data and real testing data is hard to address for 2D dense representation. To alleviate this domain gap on IUV, we propose cross-representation alignment utilizing the complementary information from the robust but sparse representation (2D keypoints). Specifically, the alignment errors between initial mesh estimation and both 2D representations are forwarded into regressor and dynamically corrected in the following mesh regression. This adaptive cross-representation alignment explicitly learns from the deviations and captures complementary information: robustness from sparse representation and richness from dense representation. We conduct extensive experiments on multiple standard benchmark datasets and demonstrate competitive results, helping take a step towards reducing the annotation effort needed to produce state-of-the-art models in human mesh estimation.
Confidence Dimension for Deep Learning based on Hoeffding Inequality and Relative Evaluation
Mar 17, 2022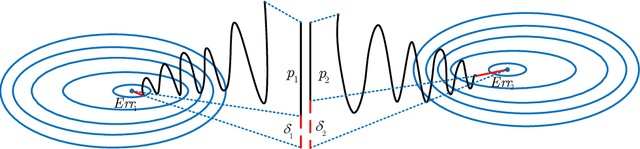
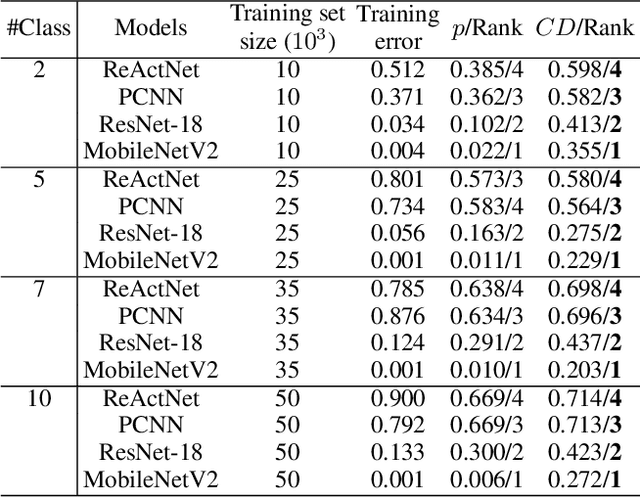
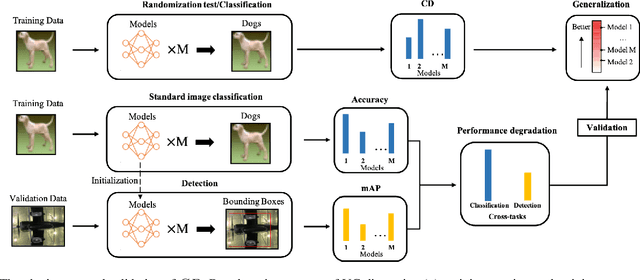
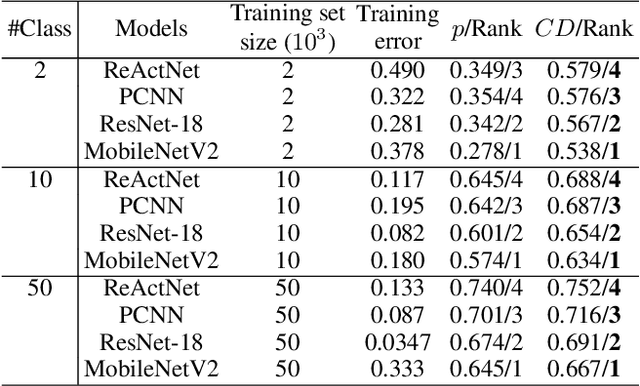
Research on the generalization ability of deep neural networks (DNNs) has recently attracted a great deal of attention. However, due to their complex architectures and large numbers of parameters, measuring the generalization ability of specific DNN models remains an open challenge. In this paper, we propose to use multiple factors to measure and rank the relative generalization of DNNs based on a new concept of confidence dimension (CD). Furthermore, we provide a feasible framework in our CD to theoretically calculate the upper bound of generalization based on the conventional Vapnik-Chervonenk dimension (VC-dimension) and Hoeffding's inequality. Experimental results on image classification and object detection demonstrate that our CD can reflect the relative generalization ability for different DNNs. In addition to full-precision DNNs, we also analyze the generalization ability of binary neural networks (BNNs), whose generalization ability remains an unsolved problem. Our CD yields a consistent and reliable measure and ranking for both full-precision DNNs and BNNs on all the tasks.