 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS 2020 Competition: Predicting Generalization in Deep Learning
Dec 14, 2020
Understanding generalization in deep learning is arguably one of the most important questions in deep learning. Deep learning has been successfully adopted to a large number of problems ranging from pattern recognition to complex decision making, but many recent researchers have raised many concerns about deep learning, among which the most important is generalization. Despite numerous attempts, conventional statistical learning approaches have yet been able to provide a satisfactory explanation on why deep learning works. A recent line of works aims to address the problem by trying to predict the generalization performance through complexity measures. In this competition, we invite the community to propose complexity measures that can accurately predict generalization of models. A robust and general complexity measure would potentially lead to a better understanding of deep learning's underlying mechanism and behavior of deep models on unseen data, or shed light on better generalization bounds. All these outcomes will be important for making deep learning more robust and reliable.
On the Information Complexity of Proper Learners for VC Classes in the Realizable Case
Nov 05, 2020We provide a negative resolution to a conjecture of Steinke and Zakynthinou (2020a), by showing that their bound on the conditional mutual information (CMI) of proper learners of Vapnik--Chervonenkis (VC) classes cannot be improved from $d \log n +2$ to $O(d)$, where $n$ is the number of i.i.d. training examples. In fact, we exhibit VC classes for which the CMI of any proper learner cannot be bounded by any real-valued function of the VC dimension only.
Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the Neural Tangent Kernel
Oct 28, 2020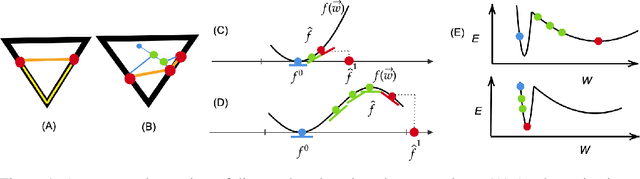
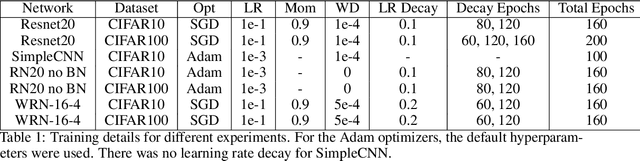
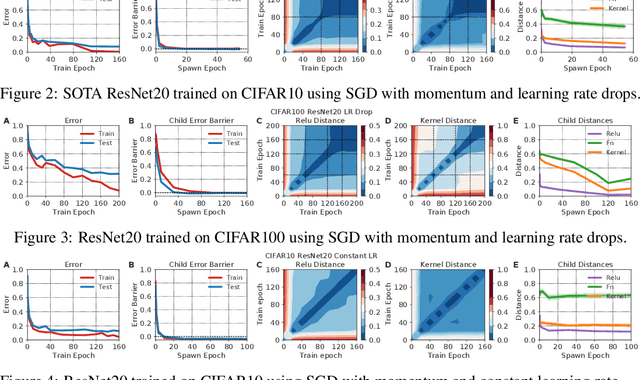
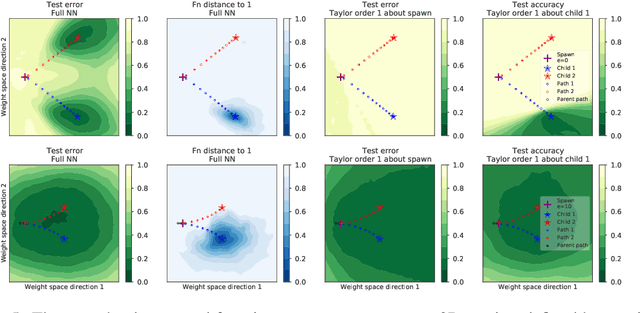
In suitably initialized wide networks, small learning rates transform deep neural networks (DNNs) into neural tangent kernel (NTK) machines, whose training dynamics is well-approximated by a linear weight expansion of the network at initialization. Standard training, however, diverges from its linearization in ways that are poorly understood. We study the relationship between the training dynamics of nonlinear deep networks, the geometry of the loss landscape, and the time evolution of a data-dependent NTK. We do so through a large-scale phenomenological analysis of training, synthesizing diverse measures characterizing loss landscape geometry and NTK dynamics. In multiple neural architectures and datasets, we find these diverse measures evolve in a highly correlated manner, revealing a universal picture of the deep learning process. In this picture, deep network training exhibits a highly chaotic rapid initial transient that within 2 to 3 epochs determines the final linearly connected basin of low loss containing the end point of training. During this chaotic transient, the NTK changes rapidly, learning useful features from the training data that enables it to outperform the standard initial NTK by a factor of 3 in less than 3 to 4 epochs. After this rapid chaotic transient, the NTK changes at constant velocity, and its performance matches that of full network training in 15% to 45% of training time. Overall, our analysis reveals a striking correlation between a diverse set of metrics over training time, governed by a rapid chaotic to stable transition in the first few epochs, that together poses challenges and opportunities for the development of more accurate theories of deep learning.
Enforcing Interpretability and its Statistical Impacts: Trade-offs between Accuracy and Interpretability
Oct 28, 2020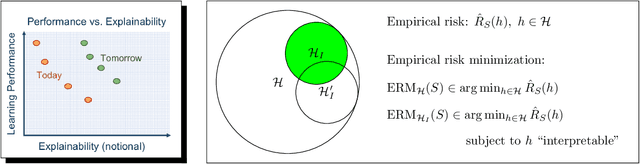
To date, there has been no formal study of the statistical cost of interpretability in machine learning. As such, the discourse around potential trade-offs is often informal and misconceptions abound. In this work, we aim to initiate a formal study of these trade-offs. A seemingly insurmountable roadblock is the lack of any agreed upon definition of interpretability. Instead, we propose a shift in perspective. Rather than attempt to define interpretability, we propose to model the \emph{act} of \emph{enforcing} interpretability. As a starting point, we focus on the setting of empirical risk minimization for binary classification, and view interpretability as a constraint placed on learning. That is, we assume we are given a subset of hypothesis that are deemed to be interpretable, possibly depending on the data distribution and other aspects of the context. We then model the act of enforcing interpretability as that of performing empirical risk minimization over the set of interpretable hypotheses. This model allows us to reason about the statistical implications of enforcing interpretability, using known results in statistical learning theory. Focusing on accuracy, we perform a case analysis, explaining why one may or may not observe a trade-off between accuracy and interpretability when the restriction to interpretable classifiers does or does not come at the cost of some excess statistical risk. We close with some worked examples and some open problems, which we hope will spur further theoretical development around the tradeoffs involved in interpretability.
In Search of Robust Measures of Generalization
Oct 22, 2020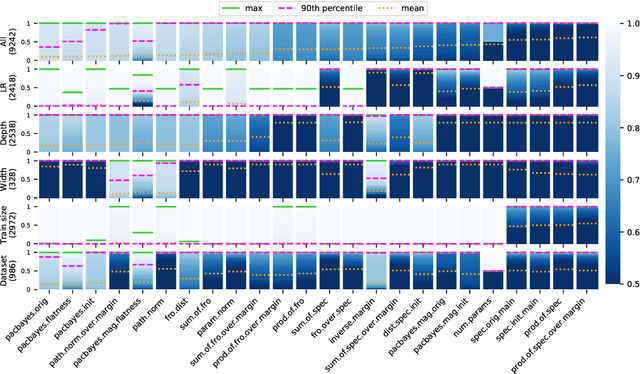
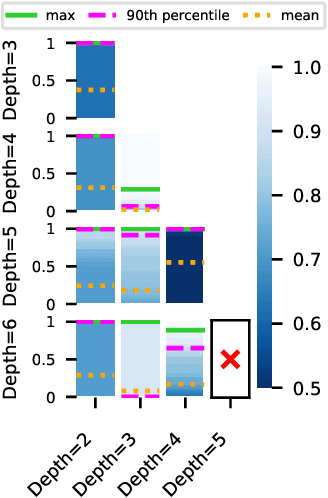
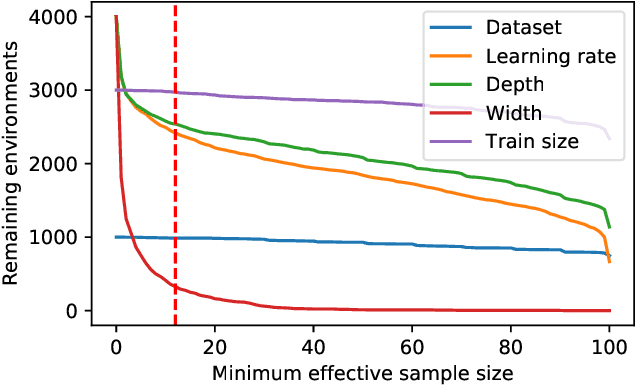
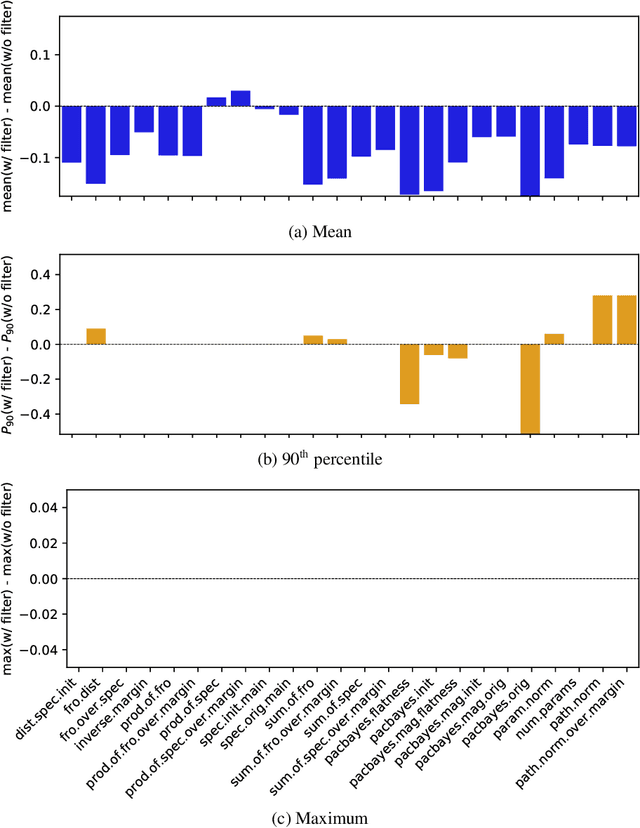
One of the principal scientific challenges in deep learning is explaining generalization, i.e., why the particular way the community now trains networks to achieve small training error also leads to small error on held-out data from the same population. It is widely appreciated that some worst-case theories -- such as those based on the VC dimension of the class of predictors induced by modern neural network architectures -- are unable to explain empirical performance. A large volume of work aims to close this gap, primarily by developing bounds on generalization error, optimization error, and excess risk. When evaluated empirically, however, most of these bounds are numerically vacuous. Focusing on generalization bounds, this work addresses the question of how to evaluate such bounds empirically. Jiang et al. (2020) recently described a large-scale empirical study aimed at uncovering potential causal relationships between bounds/measures and generalization. Building on their study, we highlight where their proposed methods can obscure failures and successes of generalization measures in explaining generalization. We argue that generalization measures should instead be evaluated within the framework of distributional robustness.
Pruning Neural Networks at Initialization: Why are We Missing the Mark?
Sep 18, 2020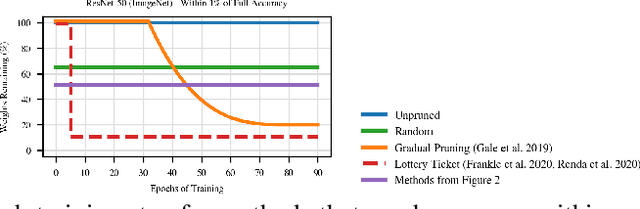

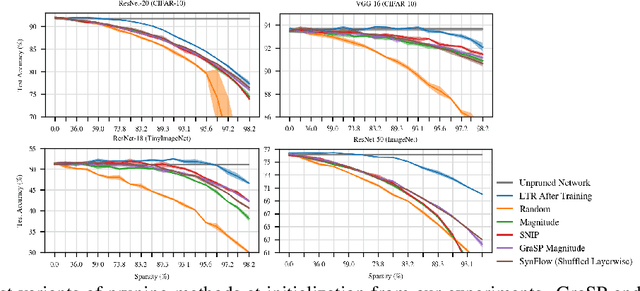
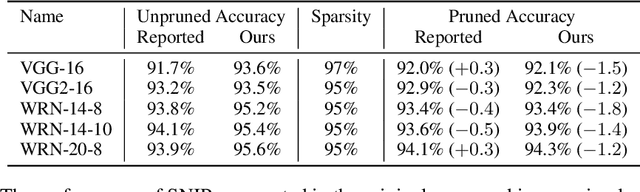
Recent work has explored the possibility of pruning neural networks at initialization. We assess proposals for doing so: SNIP (Lee et al., 2019), GraSP (Wang et al., 2020), SynFlow (Tanaka et al., 2020), and magnitude pruning. Although these methods surpass the trivial baseline of random pruning, they remain below the accuracy of magnitude pruning after training, and we endeavor to understand why. We show that, unlike pruning after training, accuracy is the same or higher when randomly shuffling which weights these methods prune within each layer or sampling new initial values. As such, the per-weight pruning decisions made by these methods can be replaced by a per-layer choice of the fraction of weights to prune. This property undermines the claimed justifications for these methods and suggests broader challenges with the underlying pruning heuristics, the desire to prune at initialization, or both.
Relaxing the I.I.D. Assumption: Adaptive Minimax Optimal Sequential Prediction with Expert Advice
Jul 13, 2020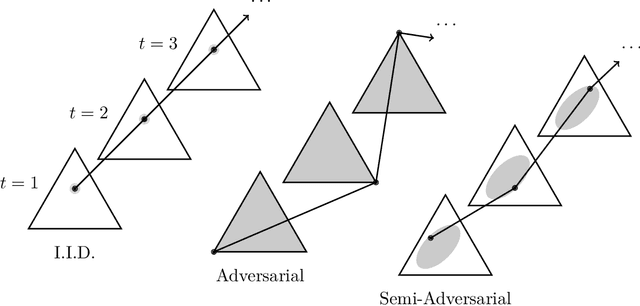
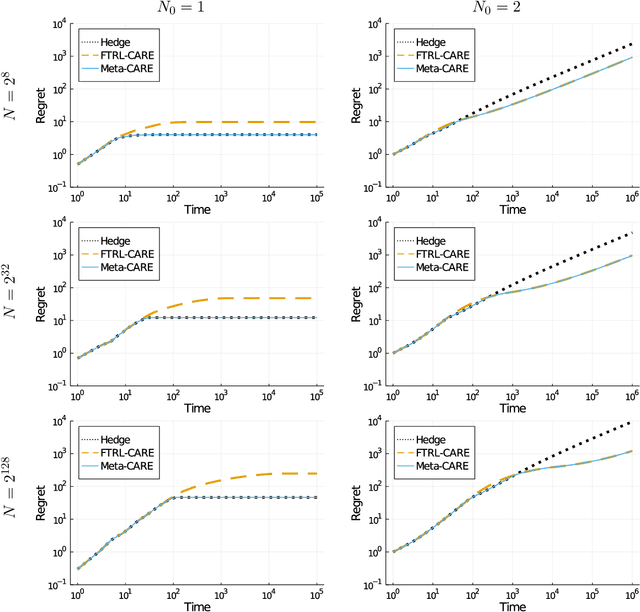
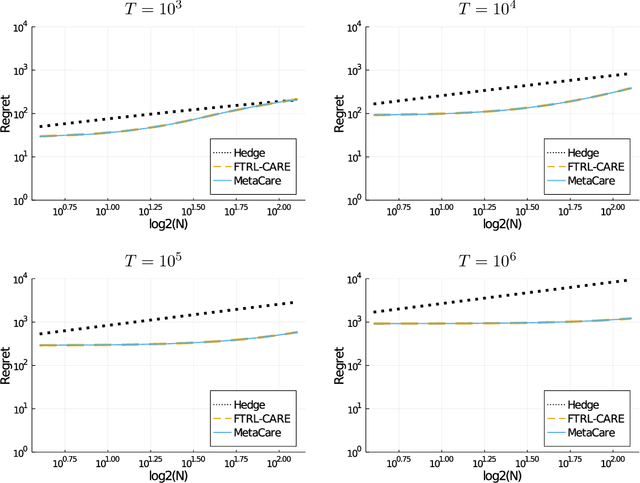
We consider sequential prediction with expert advice when the data are generated stochastically, but the distributions generating the data may vary arbitrarily among some constraint set. We quantify relaxations of the classical I.I.D. assumption in terms of possible constraint sets, with I.I.D. at one extreme, and an adversarial mechanism at the other. The Hedge algorithm, long known to be minimax optimal in the adversarial regime, has recently been shown to also be minimax optimal in the I.I.D. setting. We show that Hedge is suboptimal between these extremes, and present a new algorithm that is adaptively minimax optimal with respect to our relaxations of the I.I.D. assumption, without knowledge of which setting prevails.
Improved Bounds on Minimax Regret under Logarithmic Loss via Self-Concordance
Jul 02, 2020We consider the classical problem of sequential probability assignment under logarithmic loss while competing against an arbitrary, potentially nonparametric class of experts. We obtain improved bounds on the minimax regret via a new approach that exploits the self-concordance property of the logarithmic loss. We show that for any expert class with (sequential) metric entropy $\mathcal{O}(\gamma^{-p})$ at scale $\gamma$, the minimax regret is $\mathcal{O}(n^{\frac{p}{p+1}})$, and that this rate cannot be improved without additional assumptions on the expert class under consideration. As an application of our techniques, we resolve the minimax regret for nonparametric Lipschitz classes of experts.
On the role of data in PAC-Bayes bounds
Jun 19, 2020



The dominant term in PAC-Bayes bounds is often the Kullback--Leibler divergence between the posterior and prior. For so-called linear PAC-Bayes risk bounds based on the empirical risk of a fixed posterior kernel, it is possible to minimize the expected value of the bound by choosing the prior to be the expected posterior, which we call the oracle prior on the account that it is distribution dependent. In this work, we show that the bound based on the oracle prior can be suboptimal: In some cases, a stronger bound is obtained by using a data-dependent oracle prior, i.e., a conditional expectation of the posterior, given a subset of the training data that is then excluded from the empirical risk term. While using data to learn a prior is a known heuristic, its essential role in optimal bounds is new. In fact, we show that using data can mean the difference between vacuous and nonvacuous bounds. We apply this new principle in the setting of nonconvex learning, simulating data-dependent oracle priors on MNIST and Fashion MNIST with and without held-out data, and demonstrating new nonvacuous bounds in both cases.
Sharpened Generalization Bounds based on Conditional Mutual Information and an Application to Noisy, Iterative Algorithms
Apr 27, 2020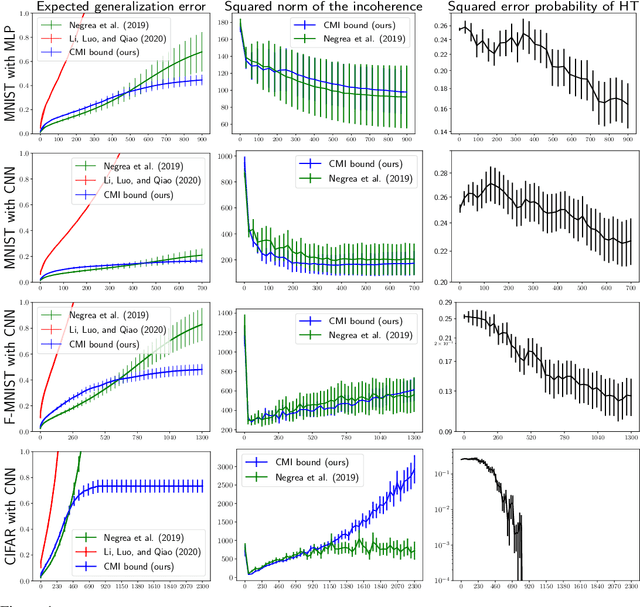
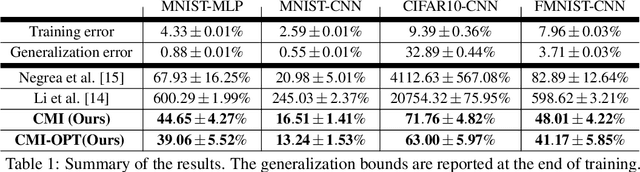
The information-theoretic framework of Russo and J. Zou (2016) and Xu and Raginsky (2017) provides bounds on the generalization error of a learning algorithm in terms of the mutual information between the algorithm's output and the training sample. In this work, we study the proposal, by Steinke and Zakynthinou (2020), to reason about the generalization error of a learning algorithm by introducing a super sample that contains the training sample as a random subset and computing mutual information conditional on the super sample. We first show that these new bounds based on the conditional mutual information are tighter than those based on the unconditional mutual information. We then introduce yet tighter bounds, building on the "individual sample" idea of Bu, S. Zou, and Veeravalli (2019) and the "data dependent" ideas of Negrea et al. (2019), using disintegrated mutual information. Finally, we apply these bounds to the study of Langevin dynamics algorithm, showing that conditioning on the super sample allows us to exploit information in the optimization trajectory to obtain tighter bounds based on hypothesis tests.