 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimitations of Information-Theoretic Generalization Bounds for Gradient Descent Methods in Stochastic Convex Optimization
Dec 27, 2022To date, no "information-theoretic" frameworks for reasoning about generalization error have been shown to establish minimax rates for gradient descent in the setting of stochastic convex optimization. In this work, we consider the prospect of establishing such rates via several existing information-theoretic frameworks: input-output mutual information bounds, conditional mutual information bounds and variants, PAC-Bayes bounds, and recent conditional variants thereof. We prove that none of these bounds are able to establish minimax rates. We then consider a common tactic employed in studying gradient methods, whereby the final iterate is corrupted by Gaussian noise, producing a noisy "surrogate" algorithm. We prove that minimax rates cannot be established via the analysis of such surrogates. Our results suggest that new ideas are required to analyze gradient descent using information-theoretic techniques.
Pruning's Effect on Generalization Through the Lens of Training and Regularization
Oct 25, 2022



Practitioners frequently observe that pruning improves model generalization. A long-standing hypothesis based on bias-variance trade-off attributes this generalization improvement to model size reduction. However, recent studies on over-parameterization characterize a new model size regime, in which larger models achieve better generalization. Pruning models in this over-parameterized regime leads to a contradiction -- while theory predicts that reducing model size harms generalization, pruning to a range of sparsities nonetheless improves it. Motivated by this contradiction, we re-examine pruning's effect on generalization empirically. We show that size reduction cannot fully account for the generalization-improving effect of standard pruning algorithms. Instead, we find that pruning leads to better training at specific sparsities, improving the training loss over the dense model. We find that pruning also leads to additional regularization at other sparsities, reducing the accuracy degradation due to noisy examples over the dense model. Pruning extends model training time and reduces model size. These two factors improve training and add regularization respectively. We empirically demonstrate that both factors are essential to fully explaining pruning's impact on generalization.
* 49 pages, 20 figures
Statistical Inference with Stochastic Gradient Algorithms
Jul 25, 2022
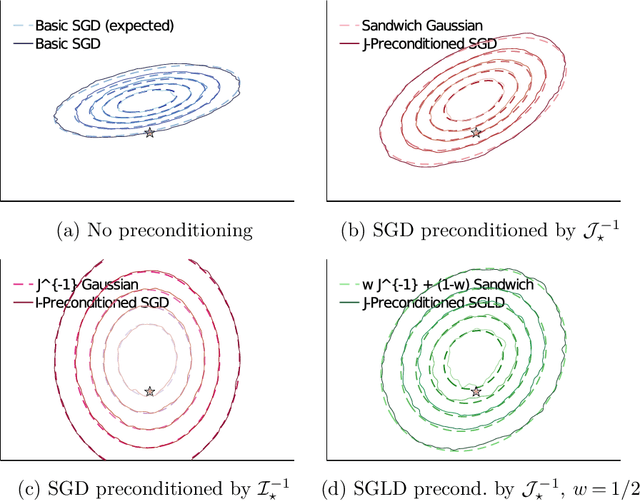
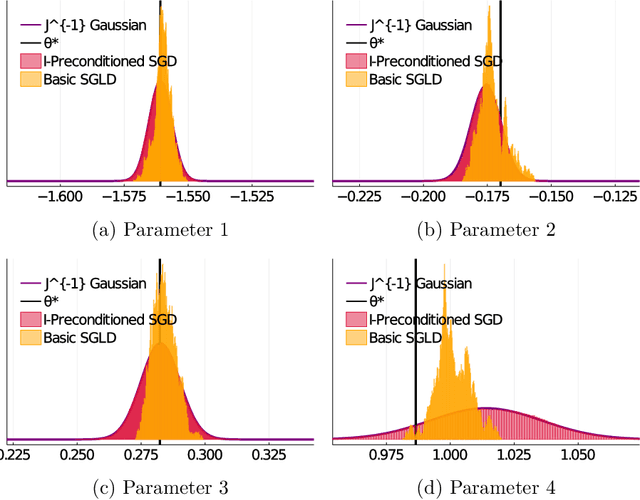
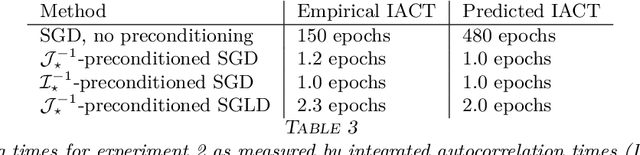
Stochastic gradient algorithms are widely used for both optimization and sampling in large-scale learning and inference problems. However, in practice, tuning these algorithms is typically done using heuristics and trial-and-error rather than rigorous, generalizable theory. To address this gap between theory and practice, we novel insights into the effect of tuning parameters by characterizing the large-sample behavior of iterates of a very general class of preconditioned stochastic gradient algorithms with fixed step size. In the optimization setting, our results show that iterate averaging with a large fixed step size can result in statistically efficient approximation of the (local) M-estimator. In the sampling context, our results show that with appropriate choices of tuning parameters, the limiting stationary covariance can match either the Bernstein--von Mises limit of the posterior, adjustments to the posterior for model misspecification, or the asymptotic distribution of the MLE; and that with a naive tuning the limit corresponds to none of these. Moreover, we argue that an essentially independent sample from the stationary distribution can be obtained after a fixed number of passes over the dataset. We validate our asymptotic results in realistic finite-sample regimes via several experiments using simulated and real data. Overall, we demonstrate that properly tuned stochastic gradient algorithms with constant step size offer a computationally efficient and statistically robust approach to obtaining point estimates or posterior-like samples.
Understanding Generalization via Leave-One-Out Conditional Mutual Information
Jun 29, 2022
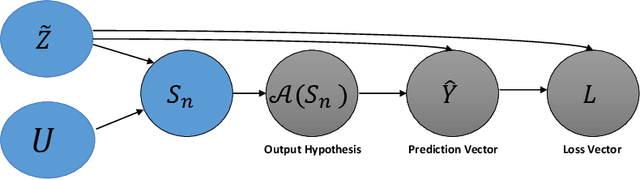
We study the mutual information between (certain summaries of) the output of a learning algorithm and its $n$ training data, conditional on a supersample of $n+1$ i.i.d. data from which the training data is chosen at random without replacement. These leave-one-out variants of the conditional mutual information (CMI) of an algorithm (Steinke and Zakynthinou, 2020) are also seen to control the mean generalization error of learning algorithms with bounded loss functions. For learning algorithms achieving zero empirical risk under 0-1 loss (i.e., interpolating algorithms), we provide an explicit connection between leave-one-out CMI and the classical leave-one-out error estimate of the risk. Using this connection, we obtain upper and lower bounds on risk in terms of the (evaluated) leave-one-out CMI. When the limiting risk is constant or decays polynomially, the bounds converge to within a constant factor of two. As an application, we analyze the population risk of the one-inclusion graph algorithm, a general-purpose transductive learning algorithm for VC classes in the realizable setting. Using leave-one-out CMI, we match the optimal bound for learning VC classes in the realizable setting, answering an open challenge raised by Steinke and Zakynthinou (2020). Finally, in order to understand the role of leave-one-out CMI in studying generalization, we place leave-one-out CMI in a hierarchy of measures, with a novel unconditional mutual information at the root. For 0-1 loss and interpolating learning algorithms, this mutual information is observed to be precisely the risk.
The Neural Covariance SDE: Shaped Infinite Depth-and-Width Networks at Initialization
Jun 06, 2022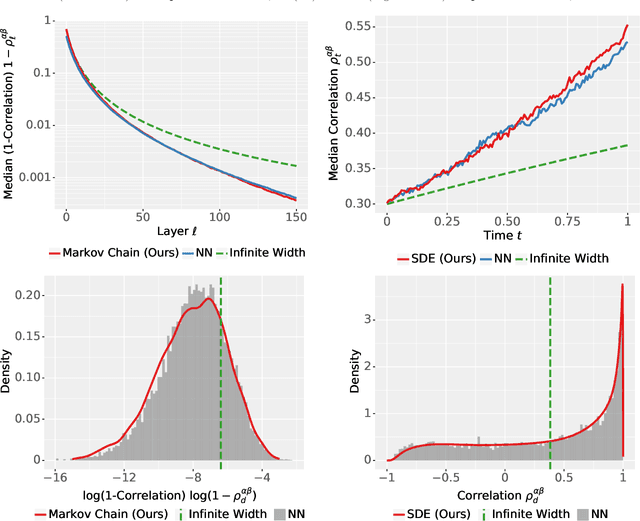

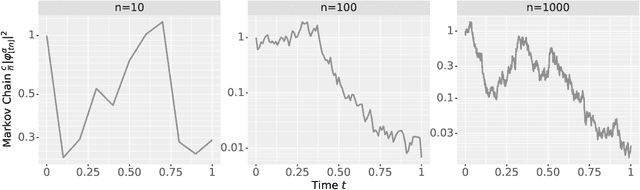
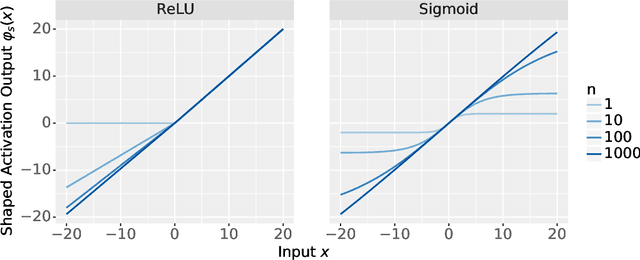
The logit outputs of a feedforward neural network at initialization are conditionally Gaussian, given a random covariance matrix defined by the penultimate layer. In this work, we study the distribution of this random matrix. Recent work has shown that shaping the activation function as network depth grows large is necessary for this covariance matrix to be non-degenerate. However, the current infinite-width-style understanding of this shaping method is unsatisfactory for large depth: infinite-width analyses ignore the microscopic fluctuations from layer to layer, but these fluctuations accumulate over many layers. To overcome this shortcoming, we study the random covariance matrix in the shaped infinite-depth-and-width limit. We identify the precise scaling of the activation function necessary to arrive at a non-trivial limit, and show that the random covariance matrix is governed by a stochastic differential equation (SDE) that we call the Neural Covariance SDE. Using simulations, we show that the SDE closely matches the distribution of the random covariance matrix of finite networks. Additionally, we recover an if-and-only-if condition for exploding and vanishing norms of large shaped networks based on the activation function.
Adaptively Exploiting d-Separators with Causal Bandits
Feb 10, 2022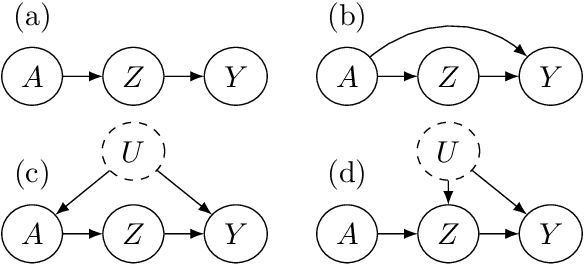
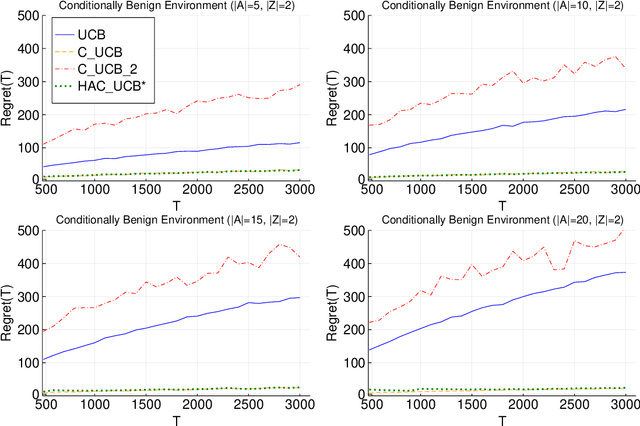
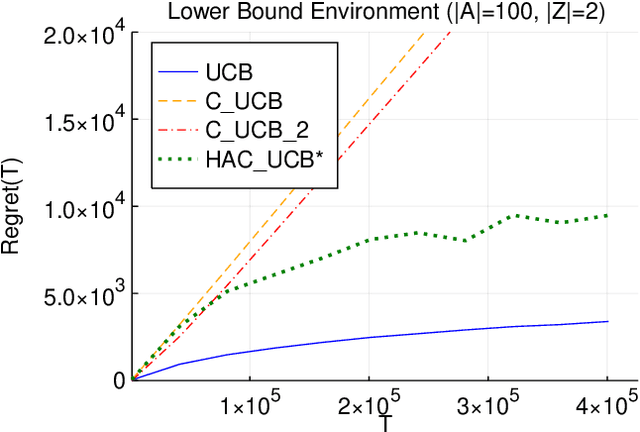
Multi-armed bandit problems provide a framework to identify the optimal intervention over a sequence of repeated experiments. Without additional assumptions, minimax optimal performance (measured by cumulative regret) is well-understood. With access to additional observed variables that d-separate the intervention from the outcome (i.e., they are a d-separator), recent causal bandit algorithms provably incur less regret. However, in practice it is desirable to be agnostic to whether observed variables are a d-separator. Ideally, an algorithm should be adaptive; that is, perform nearly as well as an algorithm with oracle knowledge of the presence or absence of a d-separator. In this work, we formalize and study this notion of adaptivity, and provide a novel algorithm that simultaneously achieves (a) optimal regret when a d-separator is observed, improving on classical minimax algorithms, and (b) significantly smaller regret than recent causal bandit algorithms when the observed variables are not a d-separator. Crucially, our algorithm does not require any oracle knowledge of whether a d-separator is observed. We also generalize this adaptivity to other conditions, such as the front-door criterion.
Towards a Unified Information-Theoretic Framework for Generalization
Nov 17, 2021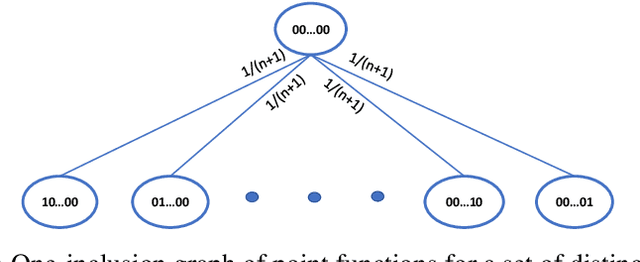
In this work, we investigate the expressiveness of the "conditional mutual information" (CMI) framework of Steinke and Zakynthinou (2020) and the prospect of using it to provide a unified framework for proving generalization bounds in the realizable setting. We first demonstrate that one can use this framework to express non-trivial (but sub-optimal) bounds for any learning algorithm that outputs hypotheses from a class of bounded VC dimension. We prove that the CMI framework yields the optimal bound on the expected risk of Support Vector Machines (SVMs) for learning halfspaces. This result is an application of our general result showing that stable compression schemes Bousquet al. (2020) of size $k$ have uniformly bounded CMI of order $O(k)$. We further show that an inherent limitation of proper learning of VC classes contradicts the existence of a proper learner with constant CMI, and it implies a negative resolution to an open problem of Steinke and Zakynthinou (2020). We further study the CMI of empirical risk minimizers (ERMs) of class $H$ and show that it is possible to output all consistent classifiers (version space) with bounded CMI if and only if $H$ has a bounded star number (Hanneke and Yang (2015)). Moreover, we prove a general reduction showing that "leave-one-out" analysis is expressible via the CMI framework. As a corollary we investigate the CMI of the one-inclusion-graph algorithm proposed by Haussler et al. (1994). More generally, we show that the CMI framework is universal in the sense that for every consistent algorithm and data distribution, the expected risk vanishes as the number of samples diverges if and only if its evaluated CMI has sublinear growth with the number of samples.
Minimax Optimal Quantile and Semi-Adversarial Regret via Root-Logarithmic Regularizers
Nov 07, 2021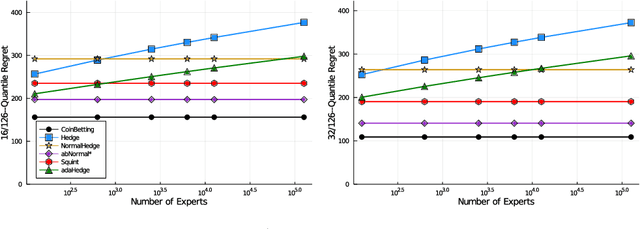
Quantile (and, more generally, KL) regret bounds, such as those achieved by NormalHedge (Chaudhuri, Freund, and Hsu 2009) and its variants, relax the goal of competing against the best individual expert to only competing against a majority of experts on adversarial data. More recently, the semi-adversarial paradigm (Bilodeau, Negrea, and Roy 2020) provides an alternative relaxation of adversarial online learning by considering data that may be neither fully adversarial nor stochastic (i.i.d.). We achieve the minimax optimal regret in both paradigms using FTRL with separate, novel, root-logarithmic regularizers, both of which can be interpreted as yielding variants of NormalHedge. We extend existing KL regret upper bounds, which hold uniformly over target distributions, to possibly uncountable expert classes with arbitrary priors; provide the first full-information lower bounds for quantile regret on finite expert classes (which are tight); and provide an adaptively minimax optimal algorithm for the semi-adversarial paradigm that adapts to the true, unknown constraint faster, leading to uniformly improved regret bounds over existing methods.
* 30 pages, 2 figures. Jeffrey Negrea and Blair Bilodeau are equal-contribution authors. Updated citations
The Future is Log-Gaussian: ResNets and Their Infinite-Depth-and-Width Limit at Initialization
Jun 07, 2021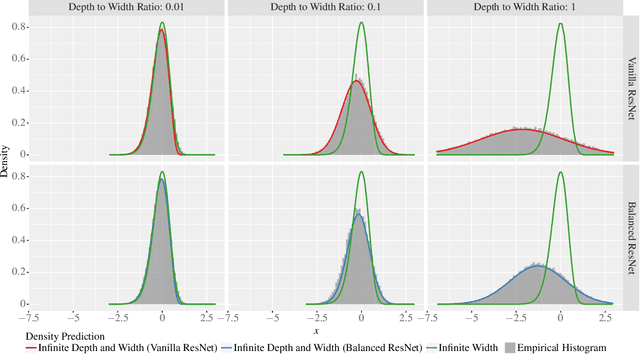

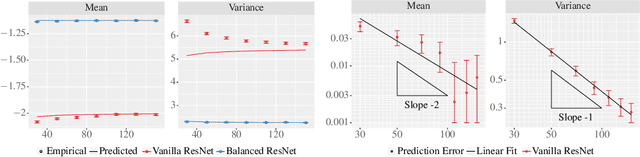
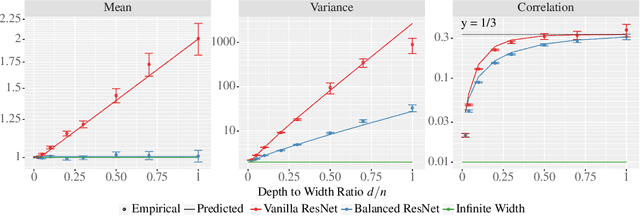
Theoretical results show that neural networks can be approximated by Gaussian processes in the infinite-width limit. However, for fully connected networks, it has been previously shown that for any fixed network width, $n$, the Gaussian approximation gets worse as the network depth, $d$, increases. Given that modern networks are deep, this raises the question of how well modern architectures, like ResNets, are captured by the infinite-width limit. To provide a better approximation, we study ReLU ResNets in the infinite-depth-and-width limit, where both depth and width tend to infinity as their ratio, $d/n$, remains constant. In contrast to the Gaussian infinite-width limit, we show theoretically that the network exhibits log-Gaussian behaviour at initialization in the infinite-depth-and-width limit, with parameters depending on the ratio $d/n$. Using Monte Carlo simulations, we demonstrate that even basic properties of standard ResNet architectures are poorly captured by the Gaussian limit, but remarkably well captured by our log-Gaussian limit. Moreover, our analysis reveals that ReLU ResNets at initialization are hypoactivated: fewer than half of the ReLUs are activated. Additionally, we calculate the interlayer correlations, which have the effect of exponentially increasing the variance of the network output. Based on our analysis, we introduce Balanced ResNets, a simple architecture modification, which eliminates hypoactivation and interlayer correlations and is more amenable to theoretical analysis.
NUQSGD: Provably Communication-efficient Data-parallel SGD via Nonuniform Quantization
May 01, 2021

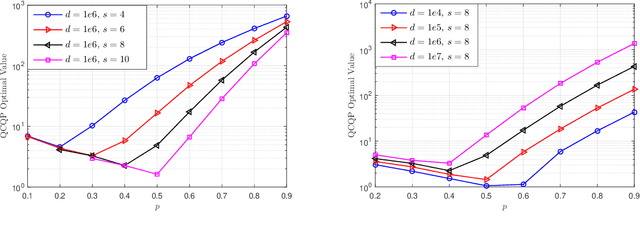
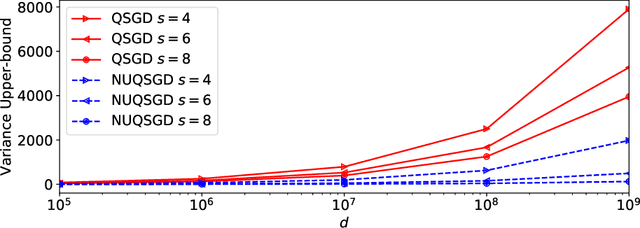
As the size and complexity of models and datasets grow, so does the need for communication-efficient variants of stochastic gradient descent that can be deployed to perform parallel model training. One popular communication-compression method for data-parallel SGD is QSGD (Alistarh et al., 2017), which quantizes and encodes gradients to reduce communication costs. The baseline variant of QSGD provides strong theoretical guarantees, however, for practical purposes, the authors proposed a heuristic variant which we call QSGDinf, which demonstrated impressive empirical gains for distributed training of large neural networks. In this paper, we build on this work to propose a new gradient quantization scheme, and show that it has both stronger theoretical guarantees than QSGD, and matches and exceeds the empirical performance of the QSGDinf heuristic and of other compression methods.